
文 | jxyxiangyu
在写了一周的业务代码后,沏一杯绿茶,总算可以有时间看看鸽了一个月的素材了。

好的,小伙伴们,废话不多说,今天我们将跟随 Boris Dayma 大佬,看看他在训练 DALLE-Mega 时遇到的一系列问题。
据这位老哥说,为了训练这个 3B 大小的模型,使用了一个 TPU v3 pod-256(=256 块 TPU v3)。
在写惯了业务代码,用多了 0.1B 的 bert-base 的我们,今天也来瞧瞧这些神仙大模型的训练方式。
DALL·E
DALL·E 是 OpenAi 去年推出的图像生成模型,它可以根据一句文本(caption)生成现实世界中不存在的图像。
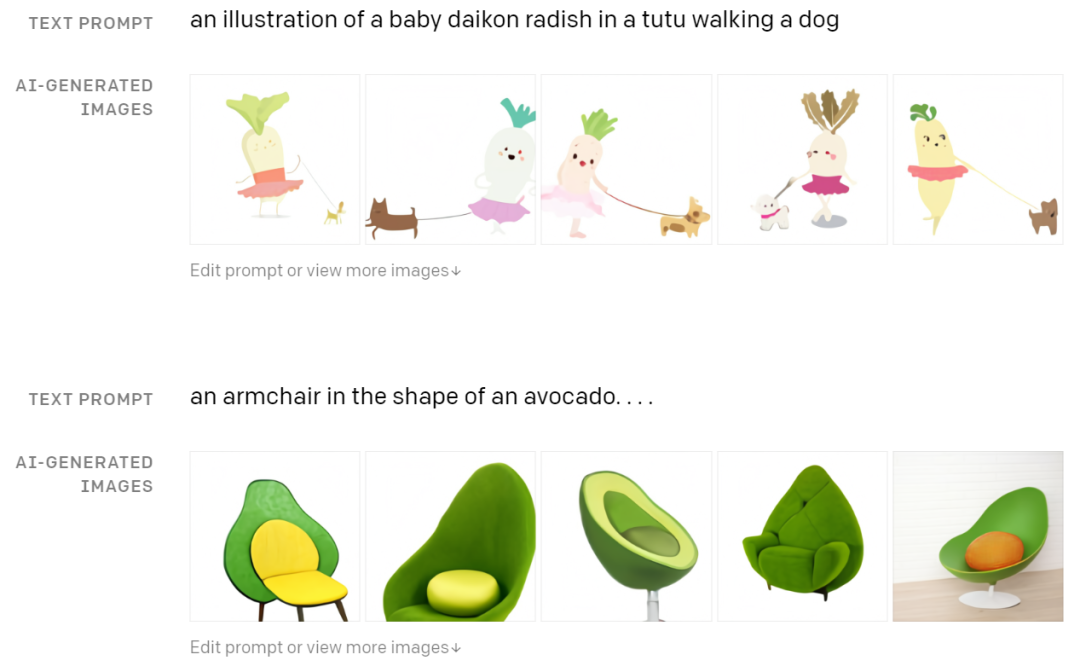
比如牛油果形状的扶手椅、穿着芭蕾舞短裙遛狗的萝卜等。
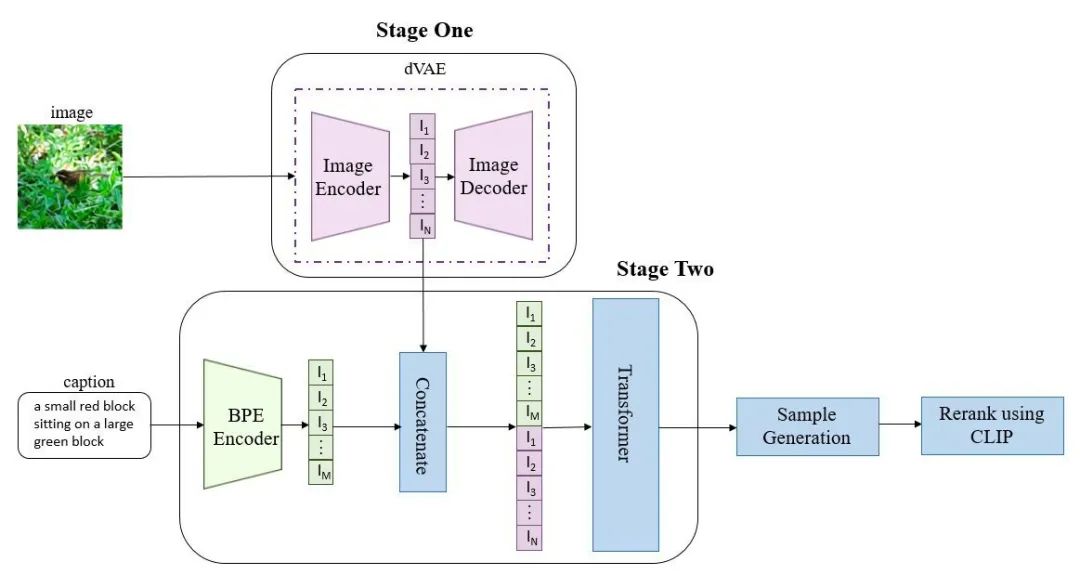
如上图所示,DALL·E 的训练过程可以分为两步:
为减小高分辨率图片()的计算量,将图片经过一个自编码模型 dVAE ,压缩得到 的图片,我们取 dVAE 的 encoder 的输出隐向量()作为压缩的图片 token;
将文本经过编码器编码后的文本 token 和图片 token 拼接,送入 transformer 进行自回归训练。
这里需要独自训练两个模型 dVAE 和 transformer 。

在推理阶段,需要向 transformer 输入一段文本 caption ,模型以滑动窗口的方式依次预测出下一个图片 token ,这里得到的图片 token 用 dVAE 的 decoder 解码回高分辨率的图片,最后用 CLIP 对得到的图片打分重排序。
更详细的过程解读可以参考 《DALL·E—从文本到图像,超现实主义的图像生成器》[1]、《如何评价DALL-E模型的实现?》[2]
DALL·E Mega 的训练之路
DALL·E Mega 是 Hugging Face 和谷歌云团队基于自己的理解实现的 DALL·E mini 的 Mega 版本,这一次,我们将跟随 Boris Dayma 的脚步,了解他在训练大模型时背后的故事。
和 DALL·E mini 相比,作者做了很多优化,使得 DALL·E Mega 在训练初期能够顺利一些,验证集的 loss 下降速度很快。
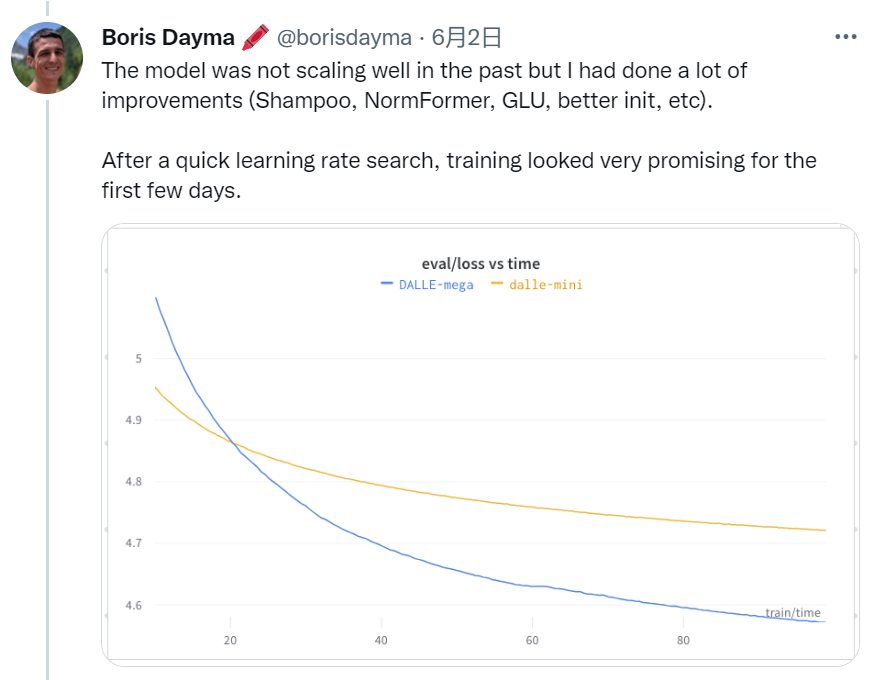
当然,随着进一步的训练,验证集的 loss 会逐渐增大,这就意味着需要减小学习率了。如下图所示,可以看到作者还应用了 warm up。
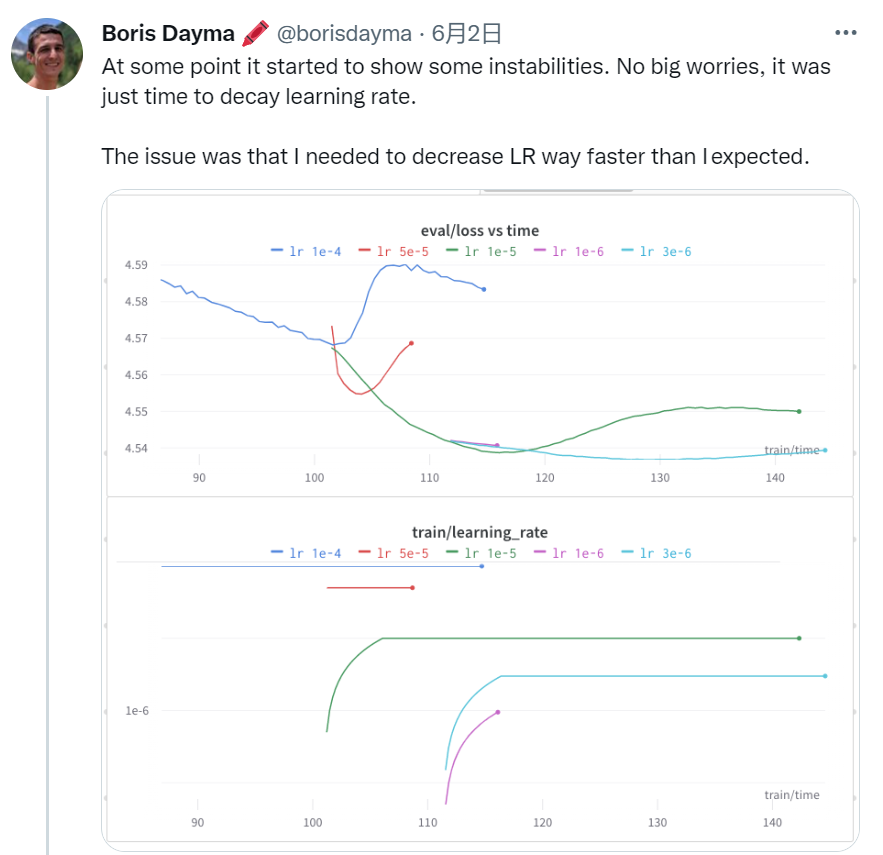

由于效果不佳,作者接着尝试了增大梯度累积以及 dropout ,不过验证集的 loss 依旧没有减小。
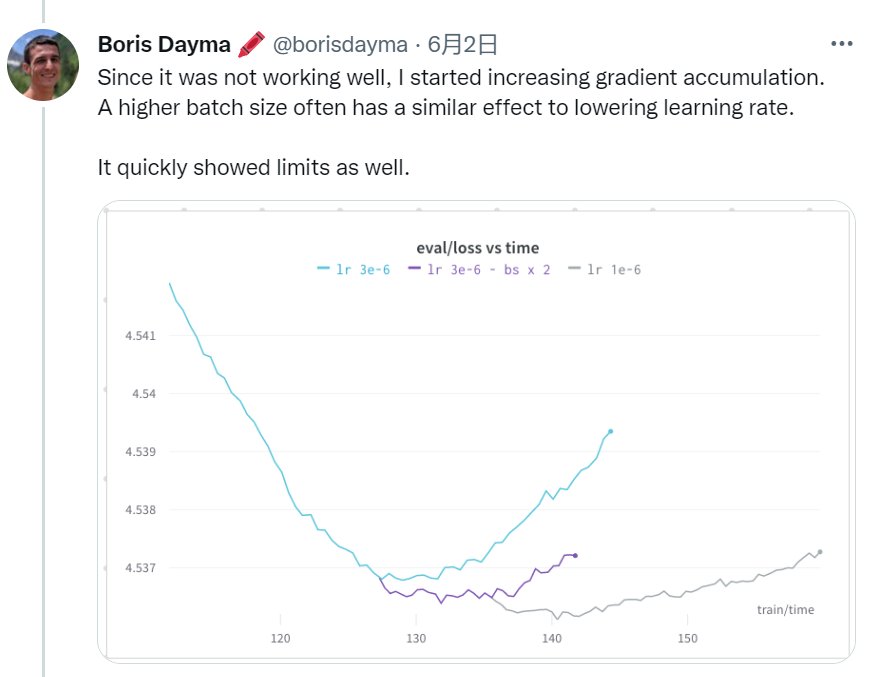

不过,令人感到意外的是,即便验证集的 loss 在增加,但预测结果却在不断变好?!对此,作者开始怀疑训练集和验证集的数据分布不一致。

随后,作者决定从训练集中切分出一个子集作为验证集,而对于原本的验证集,作者将其作为训练数据一起用于模型的训练。


不过 loss 依旧在增加,后来,采用全精度训练以及更新 动量后,loss终于开始下降了!!
虽然,验证集的 loss 在不断下降,但不知道小伙伴们有没有注意到,所有的图片都是唯一的,只有在原本的训练集中存在相同的图片(但caption不同),而在作者将训练集的子集作为新的验证集后,训练结果变好会不会是因为训练时,模型只记住了图片?

不过,这些都是后话了,训练已经接近尾声,重新训练太费时间精力(还有钱)了。Boris 小哥就没再仔细深挖这个问题了(好真实...)。

现在模型已经上线到 Hugging Face 上,小伙伴们可以下载使用,对详细的训练过程感兴趣的也可以访问官网的训练日志:
https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mega-Training-Journal--VmlldzoxODMxMDI2
总结
时隔一年, Boris Dayma 在原作的基础上,又推出了 DALL·E mini 的 Mega 版本,这一次, Boris Dayma 为我们复盘了他在训练 DALL·E mini Mega 时的心路历程以及一些失误。
诚然,我们中的大部分人都不会有机会训练如此庞大的模型,但能够跟随大神一起了解训练过程中遇到的问题以及解决方法,又何尝不是一种进步和学习呢?

萌屋作者:jxyxiangyu
人工智障、bug制造者、平平无奇的独臂侠、在某厂工作的初级程序员,从事对话交互方向,坚持每天写一点bug,时常徘徊在人工智能统治未来和if-else才是真正的AI的虚拟和现实之间,希望有朝一日学术界的研究成果可以真正在工业界实现落地。
作品推荐
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群

[1] DALL·E—从文本到图像,超现实主义的图像生成器:https://zhuanlan.zhihu.com/p/394467135
[2] 如何评价DALL-E模型的实现?:https://www.zhihu.com/question/447757686