目录
哈希函数
定义
哈希函数:是一公开函数。用于将任意长的消息M映射为较短的、固定长度的值H(M),又称为散列函数、杂凑函数。我们称函数值H(M)为哈希值、杂凑值、杂凑码、信息摘要。
杂凑值是信息中所有比特的函数,因此提供了一种错误检测能力,即改变信息中任何一个比特或几个比特都会使杂凑值改变

性质
前三条实用性要求,后三条安全性要求
- H 可以作用于任意一个长度的数据块(实际上不是任意的,比如SHA-1要求不超过2^64)
- H 产生一个固定长度的输出(比如SHA-1的输出是160比特,SHA-256的输出是256比特)
- 对任意给定的x,H(x)计算相对容易,无论是软件还是硬件实现
- 单向性(抗原像)(one-way):对于任意给定的消息,计算其哈希值容易。但是,对于给定的哈希值H,要找到M使得H(M)=H在计算上是不可行的。即给定消息可以产生一个哈希值,而给定哈希值不可能产生对应的消息;否则, 设传送数据 C =< M,H(M||K)>,K是密钥。攻击者可以截获C,求出哈希函数的逆,从而得出H^-1(C),然后从M 和M‖K即可得出K
- 弱抗碰撞(抗二次原像)(Weakly Collision-Free):对于给定的消息x,要发现另一个消息y,满足H(x)=H(y)在计算上是不可行的。是保证一个给定的消息的哈希值不能找到与之相同的另外的消息,即防止伪造。否则,攻击者可以劫获报文M及其哈希值H(M),并找出另一报文M',使得H(M)=H(M')。这样攻击者可以用M'去冒充M。
- 强抗碰撞(Strongly Collision-Free):找任意一对不同的消息x、y,使H(x)=H(y)在计算上是不可行的。是对已知的生日攻击方法的防御能力,强抗碰撞自然包含弱抗碰撞。(?)
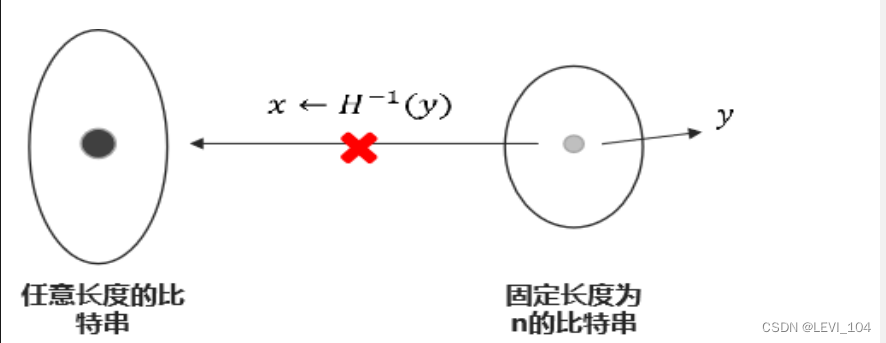
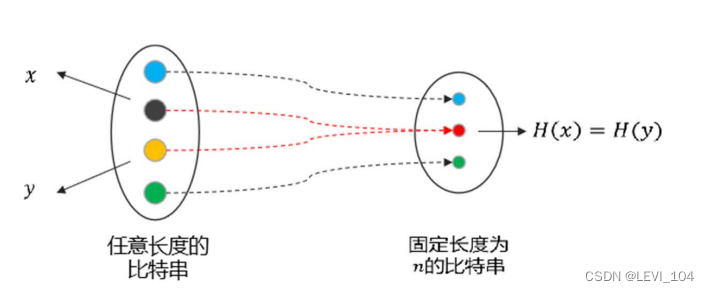
图:哈希函数强碰撞性示意图
发展
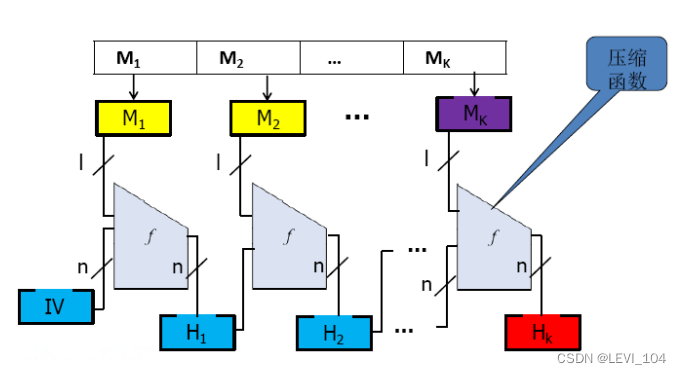
图:哈希函数结构示意图
- 1978年,Merkle和Damagad设计MD迭代结构
- 1993年,来学嘉和Messay改进加强MD结构;
- 在90年代初 MIT Laboratory for Computer Science和RSA数据安全公司的Rivest设计了散列算法MD族,MD代表消息摘要.
- MD族中的MD2、MD4和MD5都产生一个 128位的信息摘要
- MD2(1989年)
- MD4(1990年)
- MD5(1991年):由美国密码学家罗纳德ꞏ李维斯特(Ronald Linn Rivest)设计,经MD2、MD3和 MD4发展而来,输出的是128位固定长度的字符串.
- RIPEMD-128/160/320:国际著名密码学家Hans Dobbertin的在1996年攻破了MD4算法的同时, 也对MD5的安全性产生了质疑,从而促使他设计了一个类MD5的RIPEMD-160. 在结构上, RIPEMD-160可以视为两个并行的类MD5算法,这使得RIPEMD-160的安全性大大提高.
- 值得注意得是,MD4, MD5已经在2004年8月Crypto2004 上,被我国密码学者王小云等破 译,即在有效的时间内找到了它们的大量碰撞
- SHA-0:正式称作为SHA,这个版本在发行后不久被指出存在弱点
- SHA-1:是NIS于1994年发布的,它于MD4与MD5算法非常相似,被认为是MD4和MD5的后继者
- SHA-2:实际上分为SHA-224、SHA-256、SHA384、SHA-512算法
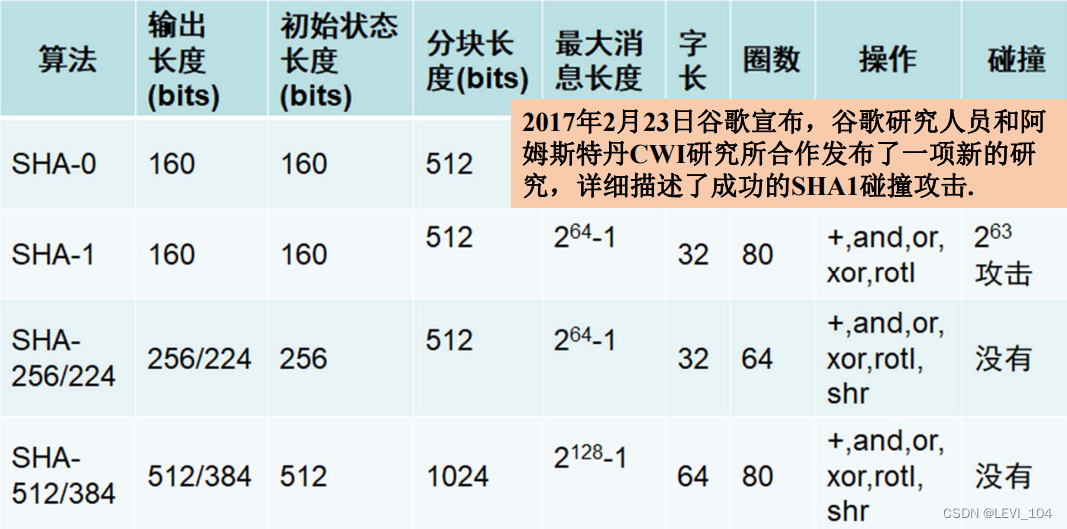
图:SHA系列哈希函数相关参数比较

图:哈希函数碰撞攻击复杂度示意图(单位:年)
常见攻击方法
1.穷举攻击
(a)原像攻击和第二原像攻击(Preimage or Second Preimage attack)
- 对于给定的哈希值h,试图找到满足H(x)=h的x
- 对于m位的哈希值,穷举规模大约是2^m
(b)碰撞攻击(Collision Resistance)
- 找到两个信息x不等于y,满足H(x) = H(y)
- 对于m位的哈希值,平均预计在2^m/2次尝试后就找到两个具有相同哈希值的数据
(c)因此对于m位的哈希值,抗穷举攻击的强度为2^m/2:
- 目前128比特已经不够,需要160比特甚至更多
2.生日攻击
情景:考虑教室有30位同学,定义函数 H: {张三,李四,ꞏꞏꞏꞏꞏꞏ|在教室里的同学}→{1,2, ꞏꞏꞏꞏꞏꞏ,365}, 如果有两个同学的生日相同,则称为一个“碰撞”. 直观看来,产生碰撞的可能性较小. 但是, 对于30个人的人群,这个事情发生的可能性大约为1/2.当人数增加时,这个可能性就增大. 这 个事实与我们的直观相悖, 称为”生日悖论”.
生日悖论是指在不少于 23 个人中至少有两人生日相同的概率大于 50%。例如在一个 30 人的小学班级中,存在两人生日相同的概率为 70%。对于 60 人的大班,这种概率要大于 99%。从引起逻辑矛盾的角度来说,生日悖论是一种 “佯谬”。但这个数学事实十分反直觉,故称之为一个悖论。生日悖论的数学理论被应用于设计密码学攻击方法——生日攻击。
生日悖论普遍的应用于检测哈希函数:N 位长度的哈希表可能发生碰撞测试次数不是 2N 次而是只有 2N/2 次。这一结论被应用到破解密码哈希函数 (cryptographic hash function) 的 “生日攻击” 中。
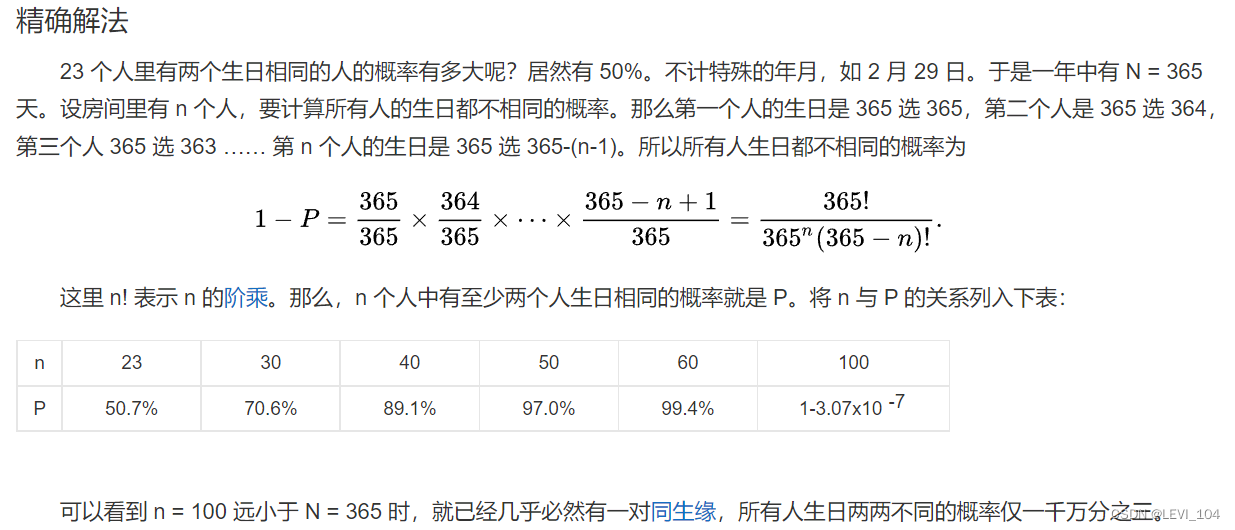
总结:对于n位的哈希值,只要尝试2^n/2次,就至少存在一对x和x',使得H(x)和H(x')相同
3.其他攻击
- 利用算法的某种特性进行攻击
- 哈希函数的迭代结构:将消息分组后分别进行处理
- 密码分析的攻击集中于压缩函数 f 的碰撞
构造方法
1.利用对称密码体制来设计哈希函数
分组密码的工作模式是:根据不同的数据格式和安全性要求, 以一个具体的分组密码算 法为基础构造一个分组密码系统的方法.基于分组的对称密码算法比如DES/AES算法只是描述 如何根据秘钥对一段固定长度(分组块)的数据进行加密,对于比较长的数据,分组密码工作模 式描述了如何重复应用某种算法安全地转换大于块的数据量.
简单的说就是,DES/AES算法描述怎么加密一个数据块,分组密码工作模式描述了如果 重复加密比较长的多个数据块. 常见的分组密码工作模式有五种:电码本( Electronic Code Book, ECB)模式、密文分组链接(Cipher Block Chaining,CBC)模式、密文反馈(Cipher Feed Back , CFB)模式、输出反馈(Output Feed Back ,OFB)模式和计数器(Counter, CTR)模式
(1)ECB工作模式
加密:输入的是当前明文分组
解密:每一个密文分组分别解密
公式:,

(2)CBC工作模式
加密:输入是当前铭文分组和前一次密文分组的异或
解密:每一个密文分组被解密后,再与前一个密文分组异或得明文
公式: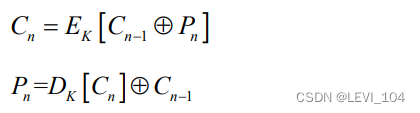
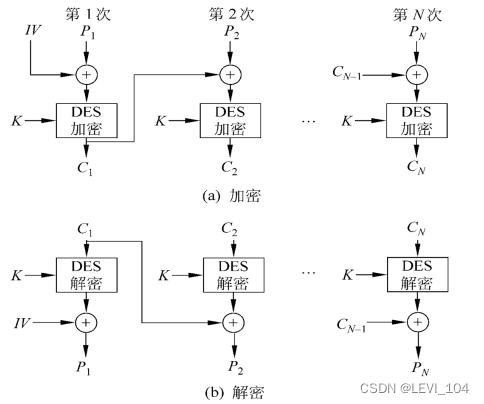
(3)CFB工作模式
- 加密算法的输入是64比特移位寄存器,其 初值为某个初始向量IV.
- 加密算法输出的最左(最高有效位)j比特与 明文的第一个单元P1进行异或,产生出密 文的第1个单元C1,并传送该单元.
- 然后将移位寄存器的内容左移j位并将C1送 入移位寄存器最右边(最低有效位)j位.
- 这一过程继续到明文的所有单元都被加密 为止.
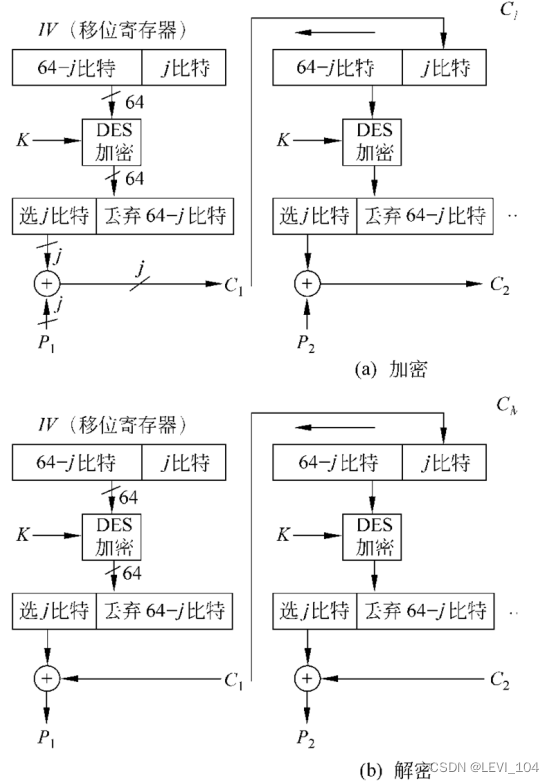
(4)OFB工作模式
- 工作模式类似CFB
- 不同:OFB模式是将加密算法的输出反馈到移位寄存器;CFB模式中是将密文单元反馈到移位寄存器
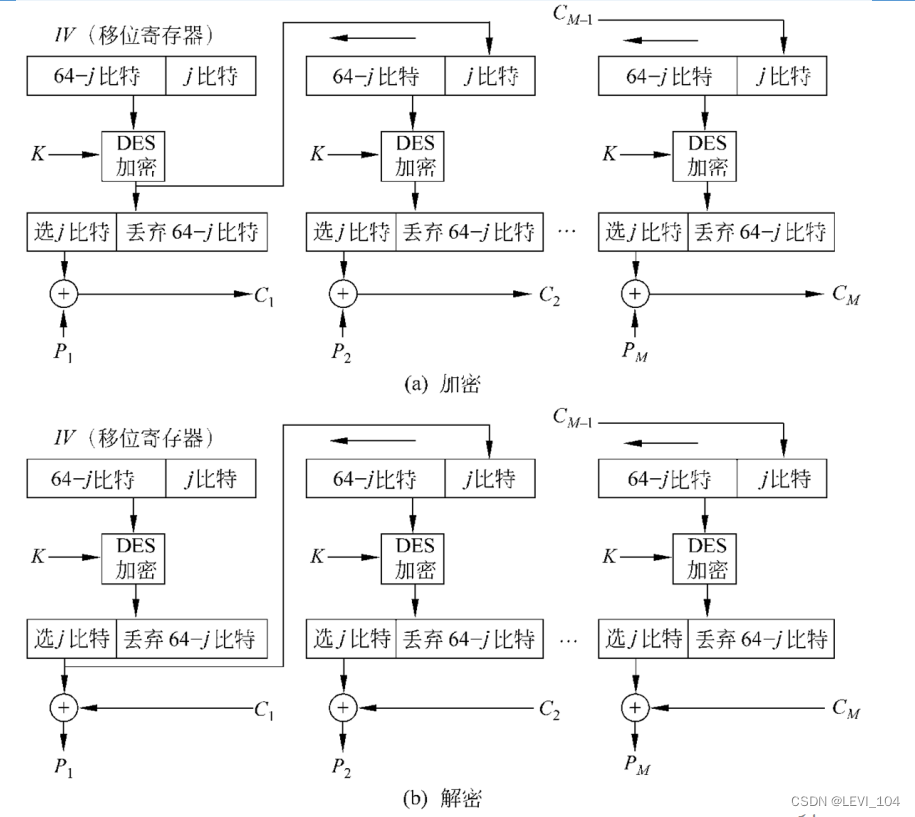
(5)CTR工作模式
加密:输入是当前明文分组和计数器密文分组的异或
解密:每一个密文分组被解密后,再与计数器密文分组异或得到明文
公式: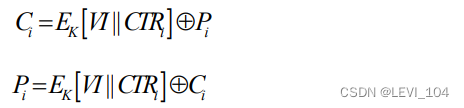
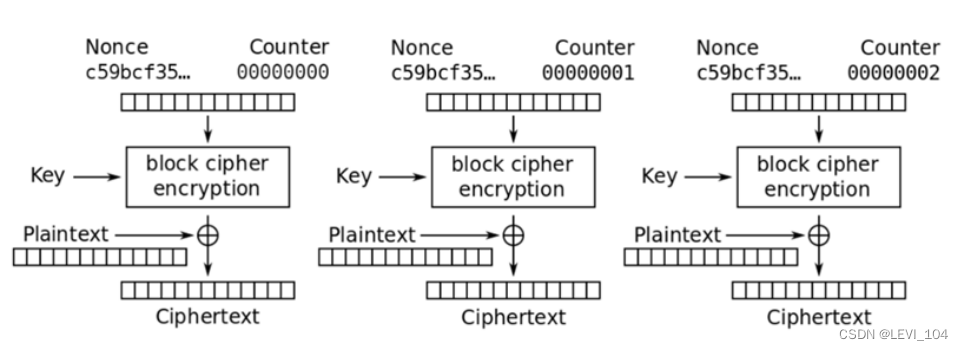
5种工作模式的比较
- ECB模式,简单、高速,但最弱、易受重发攻击,一般不推荐.
- CBC模式适用于文件加密,比ECB模式慢.安全性加强. 当有少量错误时,不会造成同步错误.
- OFB模式和CFB模式较CBC模式慢许多. 每次迭代只有少数比特完成加密. 若可以容忍少量错 误扩展,则可换来恢复同步能力,此时用CFB或OFB模式. 在字符为单元的流密码中多选 CFB模式.
- CTR模式用于高速同步系统,不容忍差错传播.
下面利用对称密码来构造哈希函数,我们规定:

1.1基于分组密码的CBC工作模式杂凑函数
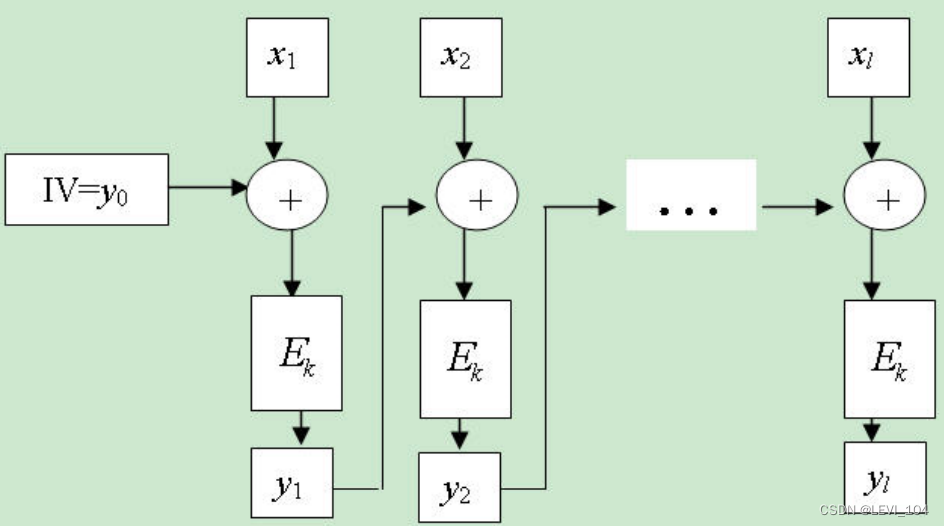
1.2基于分组密码的CFB工作模式杂凑函数

总结:上述两种基于分组密码的杂凑函数中,K可以公开,称为不带密钥的哈希函数;k也可以不公开,称为带密钥的哈希函数(MAC)。在K公开的情况下,上述两种构造杂凑函数的方法是不安全的,容易找到碰撞。这是为什么呢?
2.直接设计哈希函数
- Merkle在1989年提出迭代型哈希函数的一般结构;(另外一个工作是默克尔哈希树)
- Ron Rivest在1990年利用这种结构提出MD4;(另外一个工作是RSA算法)
- 这种结构在几乎所有的哈希函数中使用,具体做法为:
- 把所有消息M分成一些固定长度的 块Yi;
- 最后一块padding并使其包含消息 M的长度;
- 设定初始值CV0;
- 循环执行压缩函数f,CVi=f(CVi - 1||Yi -1);
- 最后一个CVi为哈希值
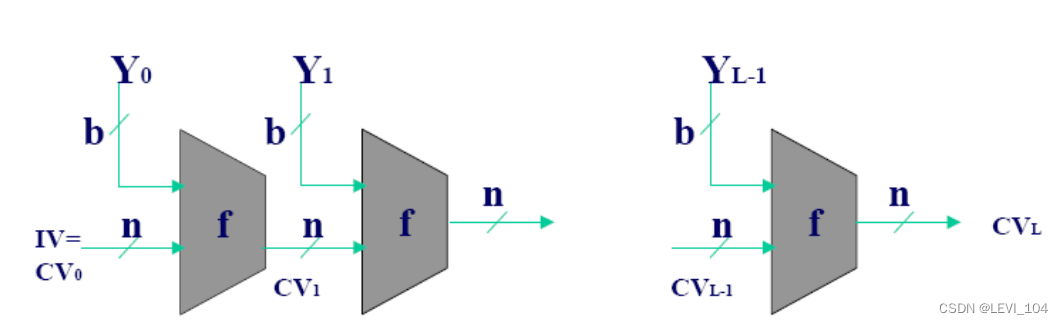
- 算法中重复使用一个压缩函数f ;
- f 的输入有两项,一项是上一轮输出的n比特值CVi-1,称为链接变量,另一项是算法在本轮 的b比特输入分组Yi-1 ;
- f 的输出为n比特值CVi,CVi又作为下一轮的输入;
- 算法开始时还需对链接变量指定一个初值IV,最后一轮输出的链接变量CVL即为最终产生的 杂凑值;
- 通常有b>n,因此称函数f为压缩函数.
- 算法可表达如下:CV0=IV= n比特长的初值;
- CVi=f(CVi-1,Yi-1);1≤i≤L;
- H(M)=CVL
- 算法的核心技术是设计难以找到碰撞的压缩函数f,而敌手对算法的攻击重点是f 的内部结构;
- f 和分组密码一样是由若干轮处理过程组成;
- 对f 的分析需要找出f 的碰撞.由于f 是压缩函数,其碰撞是不可避免的,因此在设计f 时就应 保证找出其碰撞在计算上是困难的
常用哈希函数简介
1.SHA-256算法
概况
- SHA系列标准哈希函数是由美国标准与技术研究所(National Institute of Standards and Technology,NIST)组织制定的.
- 1993年公布了SHA-0 (FIPS PUB 180),后发现不安全.
- 1995年又公布了SHA-1(FIPS PUB 180--1).
- 2002年又公布了SHA-2( FIPS PUB 180--2),包括 3种算法:SHA-256, SHA-384, SHA-512.
- 2005年王小云院士给出一种攻击SHA-1的方法,用 2^69操作找到一个强碰撞,以前认为是 2^80.
- 2017 年 2 月23日,谷歌宣布找到SHA-1碰撞的算法,需要耗费110 块GPU一年的运算量

图:SHA系列哈希函数的参数比较
注意:所有的长度以比特为单位;安全性是指对输出长度为n比特哈希函数的生日攻击产生碰撞的工作量大约为2^n/2
算法描述
- 输入数据长度为k比特,1 <= k <= (2^64) -1
- 输出哈希值的长度为256比特
(1)常量与函数:SHA-256算法使用以下常数与函数:
①常量 初始值IV = 0x6a09e667 bb67ae85 3c6ef372 a54ff53a 510e527f 9b05688c 1f83d9ab 5be0cd19,这 些初值是对自然数中前 8个质数(2,3,5,7,11,13,17,19)的平方根的小数部分取前32比特而来.
举个例子来说, 2小数部分约为0.414213562373095048,而0.414213562373095048 ≈ 6 ∗16−1 +a ∗16−2+0 ∗16−3 +9 ∗16−4 +...于是,质数 2 的平方根的小数部分取前32比特就对应出0x6a09e667. 另外,SHA-256还用到了64个常数: K0, K1, …, K63 =

和 8个初始值类似,这些常量是对自然数中前64个质数(2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97…) 的立方根的小数部分取前32比特而来
②函数 SHA-256用到了以下函数:

其中: ∧表示按位“与”; ¬ 表示按位“补”;⊕表示按位“异或”; ROTR i (x )表示循环右移 i比特; SHR i (x )表示右移 i比特;
(2) 算法描述 ①填充
- 对数据填充的目的是使填充后的数据长度为512的整数倍.因为迭代压缩是对512位数据块进 行的,如果数据的长度不是512的整数倍,最后一块数据将是短块,这将无法处理.
- 设消息 m长度为 l比特.首先将比特“1”添加到 m的末尾,再添加 k个“0”,其中, k是满足下式 的最小非负整数 l +1+ k = 448 mod 512
- 然后再添加一个64位比特串,该比特串是长度 l的二进制表示.填充后的消息 m 的比特长度一 定为512的倍数.
以信息“abc”为例显示补位的过程.a, b, c对应的ASCII码分别是97, 98, 99;于是原始信息 的二进制编码为:01100001 01100010 01100011.
① 补一个“1” : 0110000101100010 01100011 1
② 补423个“0”:01100001 01100010 01100011 10000000 00000000 … 00000000
③ 补比特长度24 (64位表示 ),得到512比特的数据:
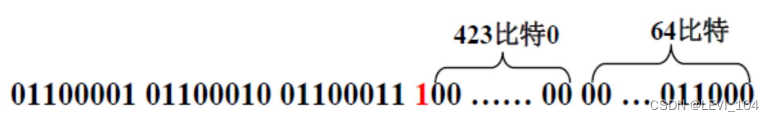
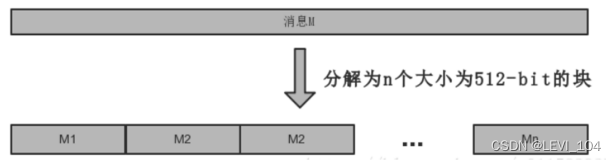
②消息分块 将填充后的消息 m′按512比特分成 n组: m′= M(0)||M(1)|| ꞏ ꞏ ꞏ || M(n-1),其中: n = ( l+ k+65)/512.
③消息扩展
- 对一个消息分组M(t) 迭代压缩之前,首先进行消息扩展
- 将16个字的消息分组 M t 扩展生成如下的64个字,供压缩函数使用 W0,W1,…,W63;
- 消息扩展把原消息位打乱,隐蔽原消息位之间的关联,增强了安全性;
- 消息扩展的步骤如下:
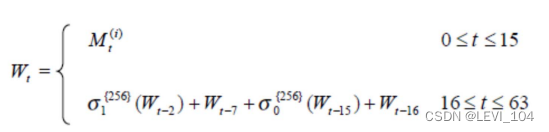
④压缩函数
- 压缩函数是SHA-256的核心
- 令 a, b, c, d, e, f, g, h为字寄存器, T1, T2为中间变量.
- 压缩函数: V(t+1)= CF( V(t) ,M(t)), 0 ≤ t ≤ n -1.
- 压缩函数CF的压缩处理:内层迭代
- ① FOR t = 0 TO 63
- ② CF= F( T1 , T2 , a, b, c, d, e, f, g, h,M(t) )
- ③ END FOR
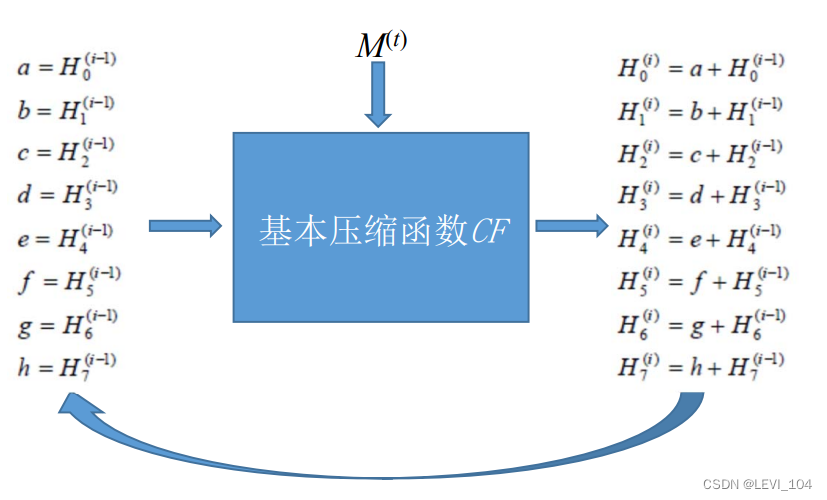
图:SHA-256算法的压缩函数工作流程示意图
⑤基本压缩函数
基本压缩函数的流程如右边公式所述.
说明:
- a, b, c, d, e, f, g, h为字寄存器, T1, T2为中间 变量;
- +运算为mod 232 算术加运算;
- 字的存储为大端(big-endian)格式.即,左边为 高有效位,右边为低有效位
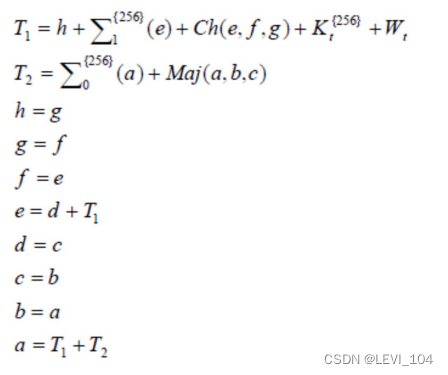
下图是SHA-256算法的基本压缩函数示意图

⑥SHA-256工作全过程
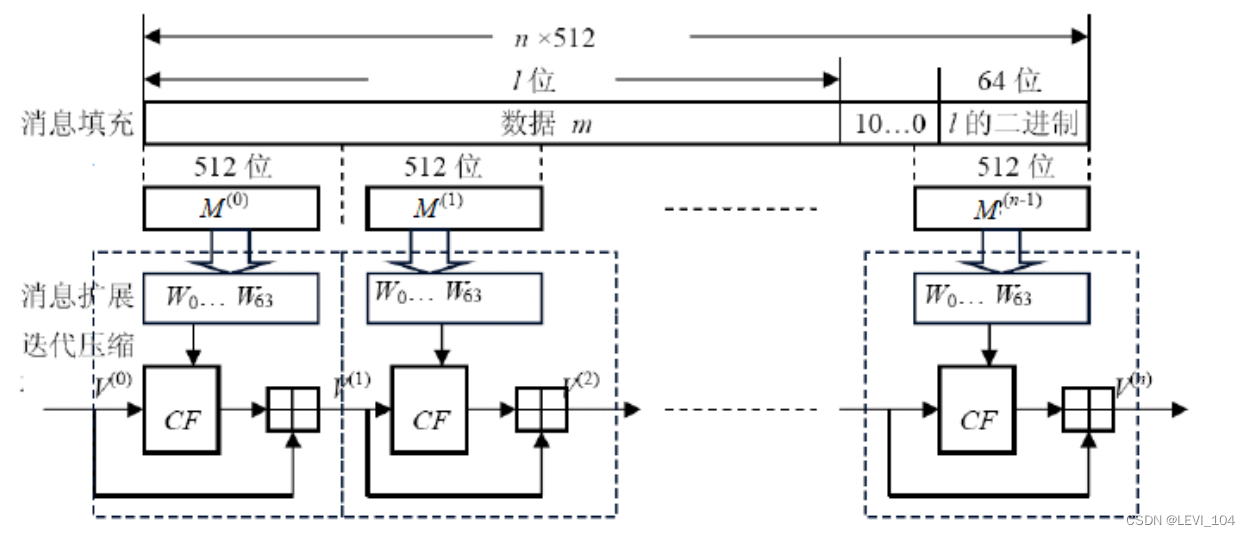
安全性
- 专业机构设计,经过充分测试和论证;
- 安全性可满足应用的安全需求;
- 学者已开展对SHA-256的安全分析 (如缩减轮的分析 ),尚未发现本质的缺陷
程序设计
- typedef.h:定义数据类型;
- sha256.h:定义SHA-256算法相 关功能函数、数据接口声明;
- sha256.c:实现SHA-256算法相 关功能函数;
- sha256_test.h:定义测试函数、 数据接口声明;
- Sha256_test.c:实现测试功能函 数;
- main.c:实现main函数,测试程 序的正确性、性能等.
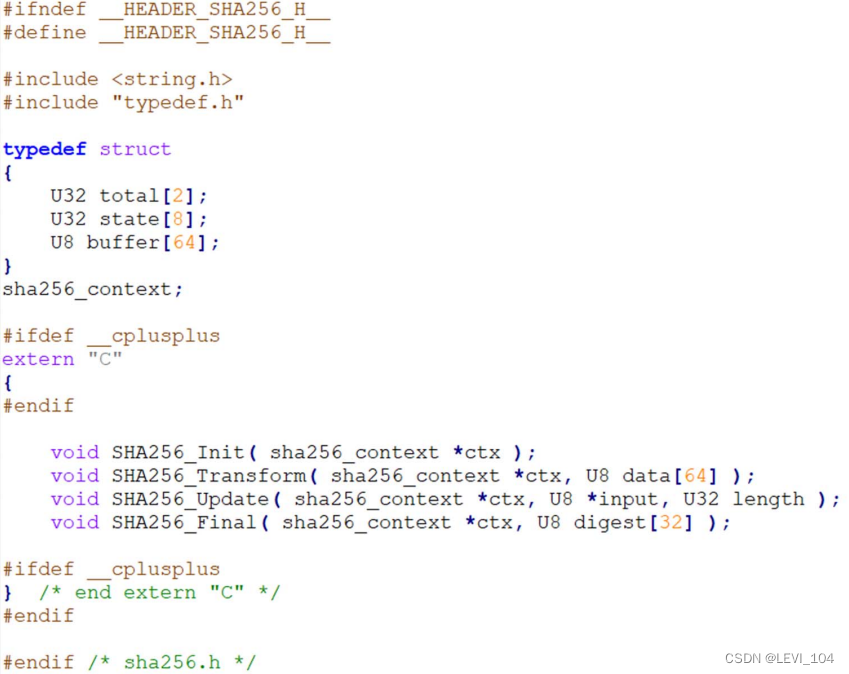
2.Keccak算法
概况
- 能够直接替代SHA-2.这要求SHA--3必须也能够产生224,256,384,512比特的哈希值.
- 保持SHA-2的在线处理能力. 这要求SHA-33必须能处理小的数据块 ( 如512 或1024比特).
- 安全性:能够抵抗原像和碰撞攻击的能力,能够抵抗已有的或潜在的对于SHA-2的攻击.
- 效率:可在各种硬件平台上的实现,且是高效的和存储节省的.
- 灵活性:可设置可选参数以提供安全性与效率折中的选择,便于并行计算等
- 2008 年10 月有64 个算法正式向NIST提交了方案,经过初步评价,共有51个算法进入第 一轮评估,主要对算法的安全性、消耗、和实现特点等进行分析;
- 2009 年 7 月24日宣布,其中14个算法通过第一轮评审进入第二轮;
- 2010 年12 月 9日宣布,其中 5个算法(JH、Grstl、Blake、Keccak 和Skein)通过第二轮评审进 入第三轮.
- 2012 年10 月 2 日NIST公布了最终的优胜者.它就是由意法半导体公司 的Guido Bertoai Bertoai、 Jean Daemen Daemen、Gilles Van Assche Assche 与恩智半导体公司 的Micha Michaëël Peeters 联合设计的Keccak算法.
- SHA-3成为NIST的新哈希函数标准算法(FIPS PUB 180--5).
- Keccak算法的分析与实现详见:https://keccak.team/index.html
- SHA-3的结构仍属于Merkle提出的迭代型哈希函数结构.
- 最大的创新点是采用了一种被称为海绵结构的新的迭代结构. 海绵结构又称为海绵函数.
- 在海绵函数中,输入数据被分为固定长度的数据分组.每个分组逐次作为迭代的输入,同时 上轮迭代的输出也反馈至下轮的迭代中,最终产生输出哈希值.
- 海绵函数允许输入长度和输出长度都可变,具有灵活的性.
- 海绵函数能够用于设计哈希函数 (固定输出长度 )、伪随机数发生器,以及其他密码函数.
Keccak算法描述
- 输入数据没有长度限制;
- 输出哈希值的比特长度分为:224,256,384,512.
(1) 符号与函数 Keccak算法使用以下符号与函数:
①符号
- r:比特率 (比特 rate),其值为每个输入块的长度.
- c:容量(capacity),其长度为输出长度的两倍.
- b:向量的长度, b = r + c,而 b的值依赖于指数 I,即 b=25 * 2^l
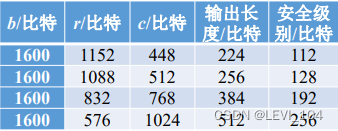
图:Keccak算法的参数定义
②函数 Keccak算法用到了以下 5个函数: θ(theta)、ρ(rho)、π(pi)、χ(chi)、ι(iota)
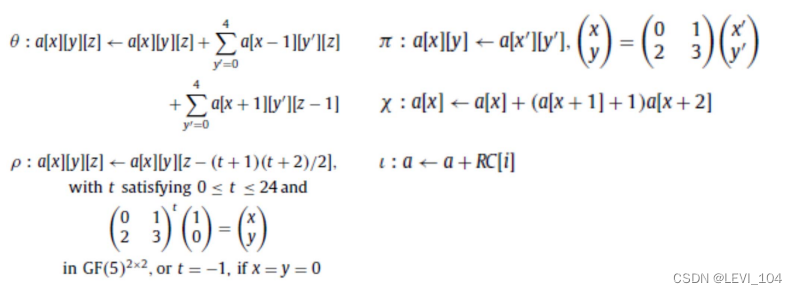
(2) 算法描述
Keccak算法 对数据进行填充,然后迭代压缩生成哈希值.
①填充
对数据填充的目的是使填充后的数据长度为 r的整数倍.因为迭代压缩是对 r位数据块进行 的,如果数据的长度不是 r的整数倍,最后一块数据将是短块,这将无法处理.
- 设消息 m长度为 l比特.首先将比特“1”添加到 m的末尾,再添加 k个“0”,其中, k是满足下式 的最小非负整数: l +1+ k = r-1 mod r ;
- 然后再添加比特“1”添加到末尾. 填充后的消息 m 的比特长度一定为 r的倍数
以算法Keccak-256,信息“abc”为例显示补位的过程. a, b, c对应的ASCII码分别是97, 98, 99;于是原始信息的二进制编码为:01100001 01100010 01100011.此时 r = 1088.
- 补一个“1” : 0110000101100010 01100011 1
- 补1062个“0”:01100001 01100010 01100011 10000000 00000000 … 00000000
- 补一个“1” ,得到1088比特的数据
②整体描述
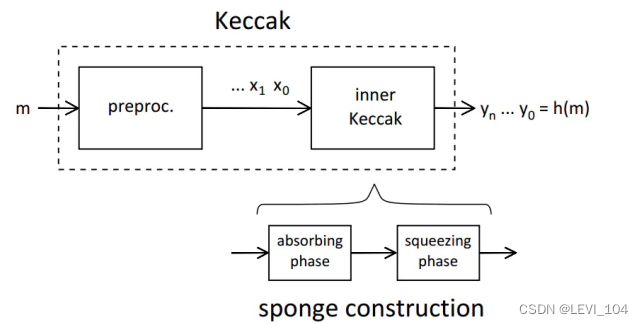
Keccak算法采用海绵结构(Sponge Construction),在预处理(padding并分成大小相同的块 ) 后,海绵结构主要分成两部分:
- 吸入阶段(Absorbing Phase):将块 xi传入算法并处理.
- 挤出阶段(Squeezing Phase):产生一个固定长度的输出.
Keccak算法的整体运算结构如下图
③吸入与挤出阶段
给定输入串 x ,首先对 x 做padding,使其长度能被 r整除,将padding后分割成长度为 r的块, 即 x =x 0|| x1|| x 2||...|| xt-1 .然后执行以下吸入阶段和挤出阶段:
- 初始化一个长度为 r + c 比特的全零向量.
- 输入块 xi,将 xi和向量的前 r个比特做异或运算,然后输入到 f 函数中处理.
- 重复上一步,直至处理完 x中的每个块.
- 输出长为 r的块作为y 0,并将向量输入到 f 函数中处理,输出 y1,以此类推.得到的哈希序列 即为y = y 0 || y1|| y 2 ||...|| y u .在Keccak-224/256/384/512中,只需要在y 0中取出 前224/ 256/ 384/ 512位即可
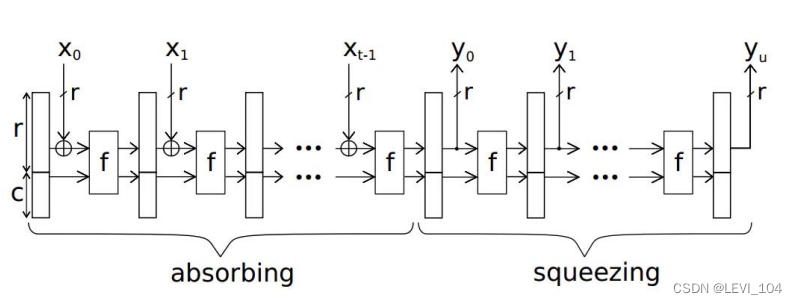
图:Kecca算法的吸入阶段和挤出阶段示意图
④压缩函数
- 压缩函数 f 是Keccak算法的核心,它包含 nr轮.
- nr的取值与我们之前计算 b时用到的指数 I ( b=25 * 25^l)有关, 具体地, nr =12+2* I.Keccak-224/256/384/512中,取 I=6, 因此 nr =24.
- 在每一轮中,要以此执行五步,即 θ(theta)、ρ(rho)、π(pi)、 χ(chi)、ι(iota).
- 在处理过程中,我们把 b=1600个比特排列成一个5*5* w 的三维数组,其中 w=2^I=64比特,如图所示:
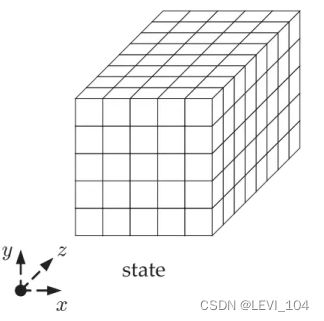
图:Kecca算法的三维数组示意图

图:Kecca算法的压缩函数结构示意图
(3) 安全性与性能
- 安全性
- 可以抵御对哈希函数的所有现有攻击.
- 到目前为止,没有发现它有严重的安全弱点.
- 灵活性:可选参数配置,能够适应哈希函数的各种应用.
- 高效性:设计简单,软硬件实现方便.在效率方面,它是高效的.
- 尚未广泛应用,需要经过实践检验
3.SM3算法
概况
- SM3是我国商用密码管理局颁布的商用密码哈希函数
- 用途广泛:
- 商用密码应用中的辅助数字签名和验证
- 消息认证码的生成与验证
- 随机数的生成
- SM3在结构上属于基本压缩函数迭代型的哈希函数.
SM3算法描述
- 输入数据长度为 l比特,1≤ l ≤264-1;
- 输出哈希值的长度为256比特.
(1) 常量与函数:SHA-256算法使用以下常数与函数:
①常量 初始值IV=7380166f 4914b2b9 172442d7 da8a0600 a96f30bc 163138aa e38dee4d b0fb0e4e.
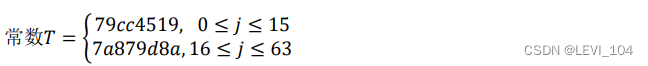
②函数
布尔函数

置换函数

其中: ∧表示按位“与”; ∨表示按位“或” ; ¬ 表示按位“补”;⊕表示按位“异或”; <<<表示循环左移
(2) 算法描述
①填充
- 对数据填充的目的是使填充后的数据长度为512的整数倍.因为迭代压缩是对512位数据块进 行的,如果数据的长度不是512的整数倍,最后一块数据将是短块,这将无法处理.
- 设消息 m长度为 l比特.首先将比特“1”添加到 m的末尾,再添加 k个“0”,其中, k是满足下式 的最小非负整数.l +1+ k = 448 mod 512
- 然后再添加一个64位比特串,该比特串是长度 l的二进制表示.填充后的消息 m 的比特长度一 定为512的倍数
以信息“abc”为例显示补位的过程.a, b, c对应的ASCII码分别是97, 98, 99;于是原始信息 的二进制编码为:01100001 01100010 01100011.
- 补一个“1” : 0110000101100010 01100011 1
- 补423个“0”:01100001 01100010 01100011 10000000 00000000 … 00000000
- 补比特长度24 (64位表示 ),得到512比特的数据
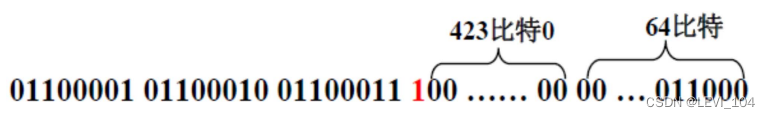
②消息扩展
- 对一个消息分组 B(i)迭代压缩之前,首先进行消息扩展
- 将16个字的消息分组 B(i)扩展生成如下的132个字,供压缩函数CF使用 W0,W1,…,W67,W′ 0, W′ 1,…,W′63
- 消息扩展把原消息位打乱,隐蔽原消息位之间的关联,增强了安全性
- 消息扩展的步骤如下:

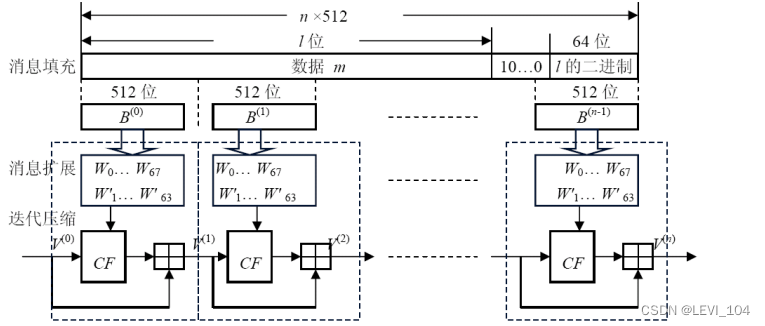
③迭代压缩处理
- 将填充后的消息 m′按512比特分组: m′= B^(0) B^(1) … B^(n−1),其中: n = ( l+ k+65)/512.
- 对 m′按下列方式迭代压缩://外层迭代
- FOR i = 0 TO n-1
- V ^(i+1)= CF^( V(i) ,B^(i) )
- ENDFOR
- 其中CF是压缩函数, V ^(0) 为256比特初始值IV,B^(i)为填充后的消息分组,
- 迭代压缩的结果为 V^(n),它为消息 m的哈希值
④压缩函数
- 压缩函数是SM3的核心
- 令A, B, C, D, E, F, G, H为字寄存器,SS1, SS2, TT1, TT2为中间变量.
- 压缩函数: V^( i+1) = CF( V^(i) ,B^(i)), 0 ≤i ≤ n -1. 压缩函数CF的压缩处理://内层迭代
- FOR j=0 TO 63
- CF= F(SS1, SS2, TT1, TT2 , A, B, C, D, E, F, G, H ,Wj ,W′ j ) //基本压缩函数
- ENDFOR
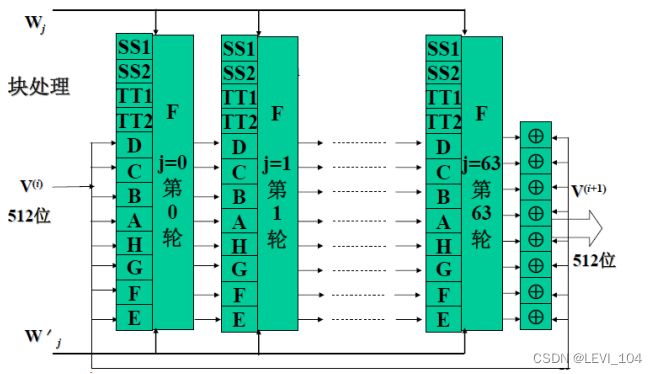
图:SM3算法的迭代压缩流程示意图
⑤基本压缩函数 F
- SS1 ←((A <<< 12) + E + ( Tj<<< j)) <<< 7
- SS2 ←SS1 ⊕(A <<< 12)
- TT1 ←FFj (A,B,C) + D + SS2 + Wj ’
- TT2 ←GGj (E,F,G ) + H + SS1 + Wj 5. D ← C
- C ← B <<< 9
- B ←A
- A ←TT1
- H ← G
- G ← F <<<19
- F ← E
- E ←P0( TT2
注意:
- A, B, C, D, E, F, G, H为字寄存器,SS1, SS2, TT1, TT2为中间变量;
- +运算为mod 232 算术加运算;
- 字的存储为大端(big-endian)格式.即, 左边为高有效位,右边为低有效位

图:SM3算法的基本压缩函数示意图
⑥SM3工作全过程
⑦压缩函数的作用
- 压缩函数是SM3安全的关键
- 第一个作用是数据压缩.SM3的压缩函数CF把每一个512位的消息分组 B(i)压缩成256 位.经过各 数据分组之间的迭代处理后把l位的消息压缩成256位的哈希值.
- 第二个作用是提供安全性.在SM3的压缩函数CF中,布尔函数FFj (X,Y,Z) 和GGj (X,Y,Z)是非线 性函数,经过循环迭代后提供混淆作 用.置换函数P0(X) 和P1(X)是线性函数,经过循环迭代 后提供扩散作用.加上压缩函数CF中的其它运算的共同作用,压缩函数CF具有很高的安全性, 从而确保SM3具有很高的安全性
⑶安全性
- 专业机构设计,经过充分测试和论证;
- 安全性可满足上述应用的安全需求;
- 学者已开展对SM3的安全分析 (如缩减轮的分析 ),尚未发现本质的缺陷
哈希函数在区块链中的应用
1.以太坊用户地址的生成
第一步:生成私钥 (private key)
产生的 256比特随机数做为私钥(256比特 16进制 32字节 ): 18e14a7b 6a307f42 6a94f811 4701e7c8 e774e7f9 a47e2c20 35db29a2 06321725
第二步:生成公钥 (public key)
- 利用将私钥(32字节)和椭圆曲线ECDSA-secp256k1计算公钥(65字节)(前缀04||X公钥||Y公钥): 04 ||50863ad6 4a87ae8a 2fe83c1a f1a8403c b53f53e4 86d8511d ad8a0488 7e5b2352 || 2cd47024 3453a299 fa9e7723 7716103a bc11a1df 38855ed6 f2ee187e 9c582ba6
- 利用Keccak-256算法计算公钥的 哈希值(32bytes): fc12ad81 4631ba68 9f7abe67 1016f75c 54c607f0 82ae6b08 81fac0ab eda21781
- 取上一步结果取后20bytes即以太坊地址: 1016f75c54c607f082ae6b0881fac0abeda21781
第三步:输地址 (address):0x1016f75c54c607f082ae6b0881fac0abeda21781
2.默克尔哈希树
3. 挖矿难度的设置
比特币难度是对挖矿困难程度的度量,即指:计算符合给定目标的一个哈希值的困难程度.
difficulty = difficulty_1_target / current_target difficulty_1_target
的长度为256比特, 前32位为0, 后面全部为1 ,一般显示为哈希值,
0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF difficulty_1_target表示btc网络最初的目标哈希. current_target是当前块的目标哈希,先经 过压缩然后存储在区块中,区块的哈希值必须小于给定的目标哈希值, 表示挖矿成功
4. 数字签名
比特币需要利用公钥进行加锁,利用私钥签名进行解锁,从而实现数字货币的交易. 解锁过程实 际上是利用ECDSA算法的产生数字签名. 给定交易信息 m,签名过程如下:
- 选择一个随机数 k;
- 计算点 R = k*G= (xR, yR ) ,计算 r = xR mod n;
- 利用私钥 d计算 s = k-1 * (( H( m) - d * r)) mod n;
- 输入签名 ( r, s)
5. 软件发布

图:挖矿软件发布信息示意图