上一篇博客介绍了如何通过以下方式自动OCR和扫描收据:
- 检测输入图像中的接收
- 应用透视变换以获得收据的自顶向下视图
- 利用Tesseract对收据上的文本进行OCR
- 使用正则表达式提取价格数据
这篇博客将介绍如何使用Python对名片进行OCR,从名片中提取姓名、职务、电话号码和电子邮件地址。是收据扫描仪OCR的扩展,但具有不同的正则表达式和文本定位策略。
优化:可以利用更先进的文本后处理技术,例如真正的自然语言处理(NLP natural language processing)算法,而不是正则表达式。 正则表达式可以很好地用于电子邮件地址和电话号码,但可能无法获得高精度的姓名和职务。
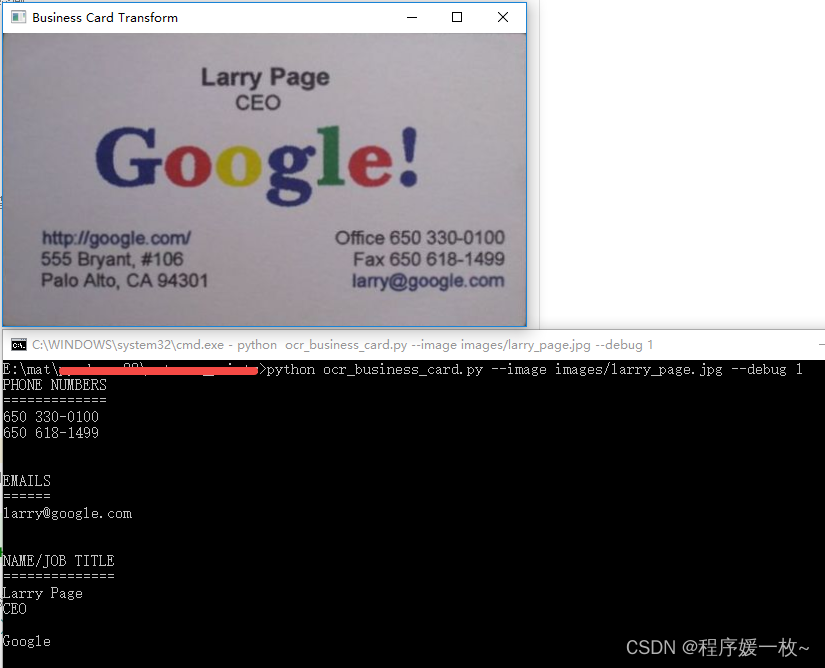
1. 效果图
原始图 VS 名片轮廓绘制绿色 效果图如下:

名片四点透视变换鸟瞰图及识别效果图如下:
可以看到电话、姓名、邮箱、职务均被正确的识别到。
2. 原理
pip install opencv-contrib-python
- 了解如何检测图像中的名片
- 将OCR应用于名片图像
- 利用正则表达式提取:名称、职位名称、电话号码、电子邮件地址
3. 源码
# 加载示例名片图像(即larry_page.png和tony_stark.png),对其进行OCR,然后从名片中输出姓名、职务、电话号码和电子邮件地址。
# USAGE
# python ocr_business_card.py --image images/mht.jpg --debug 1
import argparse
import re # Python的正则表达式库re,它将允许解析名片上的姓名、职务、电子邮件地址和电话号码
import cv2
import imutils
import numpy as np
import pytesseract # pytesseract包用于与Tesseract OCR引擎接口
# 导入必要的包
from imutils.perspective import four_point_transform # 四点变换函数来获得名片的自顶向下的鸟瞰图。获得该视图通常会产生更高的OCR精度。
# 构建命令行参数及解析
# --image 要ocr的名片图片,假设该图像包含一张前景和背景之间具有足够对比度的名片,确保可以成功地应用边缘检测和轮廓处理来提取名片。
# --debug 可选,是否查看处理的每一步可视化
# --min--conf 可选 过滤文本弱检测的置信度阈值
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--debug", type=int, default=-1,
help="whether or not we are visualizing each step of the pipeline")
ap.add_argument("-c", "--min-conf", type=int, default=0,
help="minimum confidence value to filter weak text detection")
args = vars(ap.parse_args())
# 从磁盘加载图像,保持宽高比的缩放
# 克隆图像,在轮廓处理后提取名片的原始高分辨率版本
# 然后计算新宽度与旧宽度的比率(这是想要获得原始高分辨率名片的自顶向下视图时的要求)
orig = cv2.imread(args["image"])
image = orig.copy()
image = imutils.resize(image, width=500)
cv2.imshow("origin", image)
cv2.waitKey(0)
ratio = orig.shape[1] / float(image.shape[1])
# 转换图像为灰度图,高斯平滑,应用边缘检测以使名片的外轮廓线显现出来
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 30, 150)
# 在边缘图上进行轮廓检测,按面积进行倒序排列,获取最大的轮廓即名片
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
# 初始化轮廓与名片外轮廓线对应
cardCnt = None
# 遍历轮廓
for c in cnts:
# 轮廓近似
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 如果轮廓有4个顶点,则近似认为它是名片轮廓
if len(approx) == 4:
cardCnt = approx
break
# 如果未找到名片轮廓,则抛出异常
if cardCnt is None:
raise Exception(("Could not find receipt outline. "
"Try debugging your edge detection and contour steps."))
# 检查是否显示名片轮廓检测过程图
# 检查是否处于调试模式,如果是在输出图像上绘制名片的轮廓
if args["debug"] > 0:
output = image.copy()
cv2.drawContours(output, [cardCnt], -1, (0, 255, 0), 2)
cv2.imshow("origin VS Business Card Outline", np.hstack([image, output]))
cv2.waitKey(0)
# 应用4点透视变换获取原始名片自顶向下的鸟瞰图
# 将cardCnt乘以计算出的比率,因为cardCnt是为减少的图像维数计算的。乘以比率将cardCnt缩放回原始图像的尺寸。
card = four_point_transform(orig, cardCnt.reshape(4, 2) * ratio)
# 展示转换后的图像
cv2.imshow("Business Card Transform", card)
# 转换名片从BGR到RGB通道,并ocr
rgb = cv2.cvtColor(card, cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(rgb)
# print('ocr: ', text)
# 使用正则表达式(regular expressions)解析电话号码和邮箱
# 正则表达式可以用于匹配文本中的特定模式
phoneNums = re.findall(r'[\+\(]?[1-9][0-9 .\-\(\)]{8,}[0-9]', text)
emails = re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", text)
# 尝试使用正则表达式(regular expressions)获取名称/标题,不一定可靠
nameExp = r"^[\w'\-,.][^0-9_!¡?÷?¿/\\+=@#$%ˆ&*(){}|~<>;:[\]]{2,}"
names = re.findall(nameExp, text)
# 显示电话号码
print("PHONE NUMBERS")
print("=============")
# 遍历检测到的号码并输出
for num in phoneNums:
print(num.strip())
# 显示邮箱地址头
print("\n")
print("EMAILS")
print("======")
# 遍历检测到的email地址
for email in emails:
print(email.strip())
# 展示姓名/职务
print("\n")
print("NAME/JOB TITLE")
print("==============")
# 遍历姓名/职务并显示在屏幕上
for name in names:
print(name.strip())
cv2.waitKey(0)
cv2.destroyAllWindows()
参考
- https://pyimagesearch.com/2021/11/03/ocring-business-cards/
- 名片图来源: http://www.cn5135.com/News/28126/%B9%C8%B8%E8%C1%AA%BA%CF%B4%B4%CA%BC%C8%CB%C0%AD%C0%EF%A1%A4%C5%E5%C6%E6%BD%AB%B3%F6%C8%CECEO.html