小科普:
什么是同构异IP数据源? 指的是库表结构一致、IP不同的多个 数据源;
同构异IP数据源的数据特征:数据源类型相同、IP不同、库表名称符合特定规律、表结构一致。
由于使用场景、业务形态、技术选型、开发架构的差异,在企业中往往存在多套不同的软硬件平台上的信息系统。这些不同来源的数据之间彼此独立、相互封闭,使得数据难以在业务系统间进行互联互通和信息共享,从而形成了信息孤岛。然而,随着信息化应用的不断深入,企业内部、企业与外部信息互通的需求日益强烈,亟需联通信息孤岛,实现数据的互通和共享。由此,数据传输产品应运而生,用于实现多种异构数据源之间的数据交换,帮助数据从业务系统同步进入数据仓库。

数据传输产品致力于提供丰富异构数据源之间数据交换的能力,采用分布式的架构,可实现各部门业务数据在应用层面的互联互通和信息共享,可以从容应对大数据量的数据传输需求。本文主要围绕同构异IP数据源批量抽取的业务场景,针对目前存在的业务痛点,结合实践案例介绍数据传输产品的产品解决方案。

1
业务场景
(1)随着业务的飞速发展,业务系统的数据量也在高速增长,需要系统具备灵活的扩展能力和高并发大数据量的处理能力。针对这个业务应用场景,业内部分的数据库系统如MySQL等提供了分布式分库分表的方案,通过减小单表的数据量来解决这个问题。分库分表的数据特征为:表结构一致,复杂场景下会分布存储在跨IP的多个库的多张表中。数据开发需要把分库分表的数据定期抽取到数仓Hive表。
(2)很多大型企业通常会在不同的地域设立分公司。各分公司的业务数据会按照公司的统一格式存储在各自的业务系统,各分公司的业务数据库的数据特征为:数据源类型相同、IP不同、库表名称符合特定规律、表结构一致。数据开发需要把分散在各个业务系统的数据定期抽取到总公司指定的数据库表用于后续经营分析。
2
业务痛点及产品解决方案
痛点1:创建任务操作繁琐
如果每个任务仅支持抽取单表,需要创建大量任务,任务维护极其困难。进一步来讲,即便已支持在同一任务中手工添加多个分库分表,但每次创建任务时,仍需要数据开发手工一个一个反复添加数据源,效率低,而且容易出错。
解决方案:支持登记逻辑数据源,一个逻辑数据源可以关联多个物理数据源,可以选择基于逻辑数据源创建传输任务,每次创建任务,只需要选择一个逻辑数据源即可。
痛点2:扩展性问题
如果分库分表下的数据源或库表增加时,每一个任务都需要去调整并重新提交上线,效率低,极易产生事故。
解决方案:每次扩展数据源,只需要在逻辑数据源下新增物理数据源即可,不需要修改任务。任务上支持通过库/表的正则表达式的方式,自动匹配对应的库表。
3
实践案例
3.1 需求场景
业务数据按分库分表分布在400张表中,具体来说:4个同构异ip数据源中,每个数据源下分别有10个库,每个库下分别有10张表,每张表中有100条记录。
库名和表名的命名特征如下:设m∈{1,2,3,4},n∈{0,1,2,3,4,5,6,7,8,9},l∈{0,1,2,3,4,5,6,7,8,9}
数据源名称为:physical_mysqlm
库名为:ndi_m_n
表名为:t_sharding_m_n_l
需要每天读取4个MySQL数据源下所有分库分表的全量数据,并覆盖写入Hive表。数据源名称、数据库名称库、表名称示例如下:

表结构如下:

3.2 实践操作步骤

3.2.1 登记逻辑数据源
登记MySQL逻辑数据源,逻辑数据源名称:logic_distmysql。
在该逻辑数据源下,添加已登记的4个物理数据源:physical_mysql_1、physical_mysql_2、physical_mysql_3、physical_mysql_4。




保存成功后,可在数据源列表页查看逻辑数据源详情,确认无误后请前往数据传输。

3.2.2 创建数据传输任务

3.2.2.1 选择数据来源与去向
数据来源与去向配置如下:

step1:选择数据来源
(1)点击切换按钮切换为逻辑数据源模式,选择数据源类型:MySQL,并选择已登记的逻辑数据源:logic_distmysql。
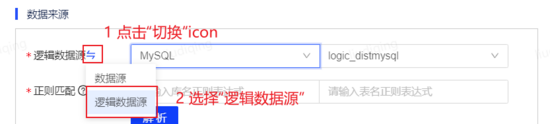
(2)填写库名的正则表达式:ndi_\d+_\d,填写表名的正则表达式:t_sharding_\d+_\d+_\d。

正则匹配的结果预览如下:

step2:选择数据去向
-
选择数据源类型:Hive,数据源名称:poc-建德十 Hive数据源
-
选择库名:demo,表名:logicdist
-
选择写入规则:insert overwrite

3.2.2.2 配置字段映射
字段映射默认为同名映射,配置如下:

3.2.2.3 保存任务
成功保存任务后,即可在任务列表查看任务。目前传输任务默认按照最近修改时间降序排序,如果创建任务后未找到创建的任务,可以输入任务名称搜索。

3.2.3 试运行任务,试运行成功后创建离线开发任务
3.2.3.1 试运行任务



3.2.3.2 运行成功后前往自助分析验证写入结果
前往自助分析验证结果,Hive表中的remark字段内容为来源表表名。输入SQL语句:
select count(id),remark from demo.logicdistgroup by remark

3.2.3.3 自助分析结果验证无误后,创建离线开发任务

3.2.4 离线开发任务提交调度

离线开发任务提交上线并配置调度后,每次任务执行时,将对当前逻辑数据源下所有数据源的所有库表进行正则匹配,读取库名和表名均符合正则表达式的所有表。
3.2.5 扩展处理:分库分表扩展时,需要怎么处理?
(1)如果物理数据源下新增库或新增表,无需额外处理
每次任务运行时,会按照库表名称的正则表达式,对逻辑数据源下所有物理数据源的库表(含新增库表)进行正则匹配。
(2)如果新增物理数据源,需在已登记的逻辑数据源下新增物理数据源
如果登记的逻辑数据源下新增物理数据源,需在已登记的逻辑数据源下新增物理数据源,无需修改数据传输任务。任务运行时会对逻辑数据源下所有物理数据源(含新增物理数据源)的库表进行正则匹配。


好啦,以上就是本次的产品实践案例,希望对你在工作中能有所帮助。如有疑问,欢迎评论区留言~