
话不说多,我们直接来看看我大天朝人民有多高兴!

我们以围脖为例
首先我们打开评论,点击右键选择检查或者按F12,打开开发者工具。

选择network ,但是这时候咱们是没有数据的,所以需要刷新一下。
然后点击 fetch/XHR ,点击第四个链接

点击右侧 preview ,依次展开,就可以看到评论/ID/账号昵称等等信息。

点击headers ,request url的链接,就是本次咱们要获取数据的链接,先复制上。

那咱们开始写代码
首先导入数据请求模块
import requests
然后将url 粘贴进来
url = 'https://m.weibo.cn/comments/hotflow?id=4788920581098454&mid=4788920581098454&max_id_type=0'
加上headers伪装一下请求头,防止反爬,这里是没做翻页,所以只需要加User-Agent就行了。

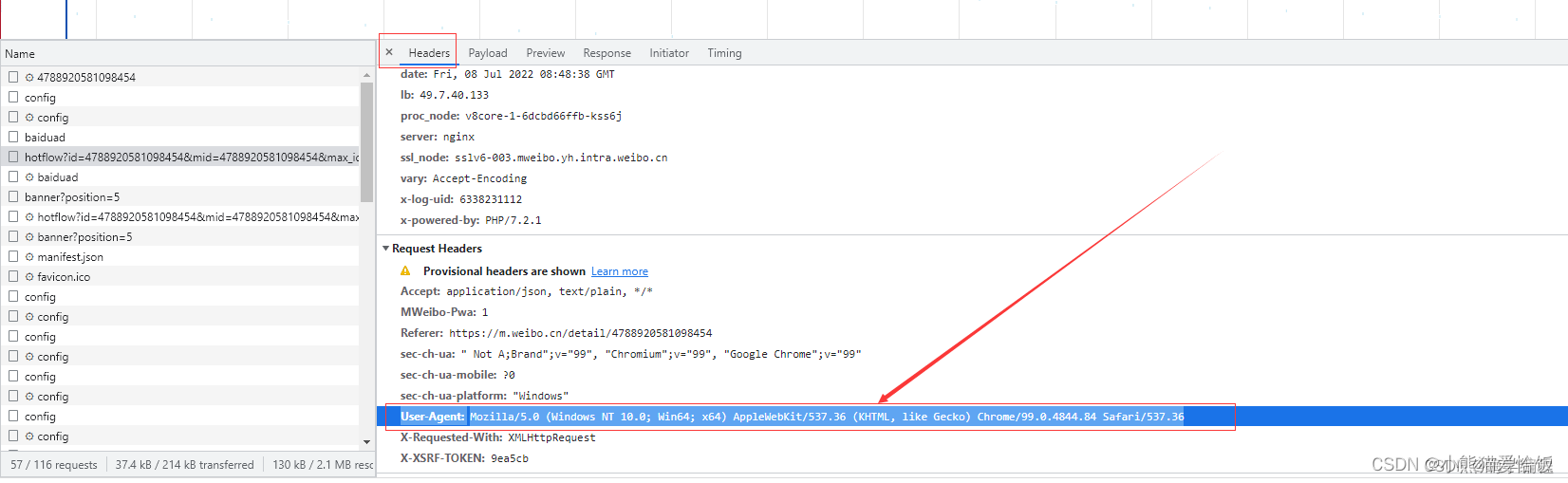
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
发送请求
response = requests.get(url=url, headers=headers)
获取一下数据
import requests
url = 'https://m.weibo.cn/comments/hotflow?id=4788920581098454&mid=4788920581098454&max_id_type=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.json())

但是现在的数据看起来有点不好看,而且我是获取了整页的,如果只获取单条数据的话,直接点左上角的搜索,把评论复制进去,后面的步骤就一样了。
获取下来了,咱们直接根据键值对提取相应的数据就好了。
首先咱们把data 全部取出来
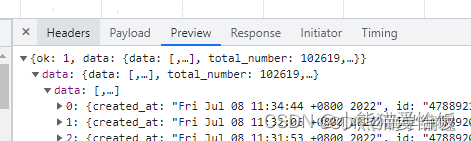
然后遍历出来
for index in response.json()['data']['data']:
也就是键值对取值,根据冒号左边的内容,提取冒号右边的内容。
首先取的是第一个data

返回的是第二个data的内容,再取第二个data ,返回的就是下面的数据了。
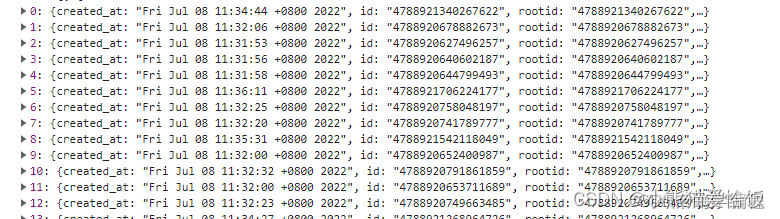
把它遍历出来,使用pprint这个模块打印出来。
import requests
import pprint
url = 'https://m.weibo.cn/comments/hotflow?id=4788920581098454&mid=4788920581098454&max_id_type=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.json())
for index in response.json()['data']['data']:
pprint.pprint(index)
break
打印结果
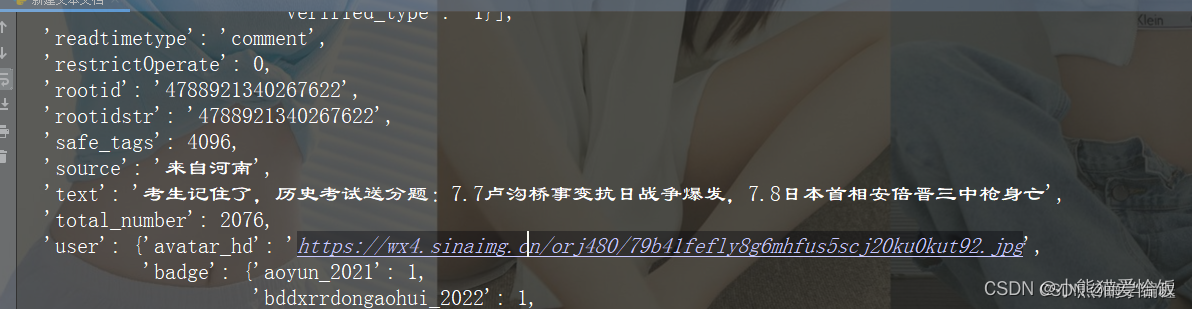
用字典接收一下
dit = {
'用户': index['user']['screen_name'],
'地区': index['source'].replace('来自', ''),
'评论': content,
'日期': index['created_at']
}
但是我们只要中文就可以了,所以用正则去匹配出来。
先用index取txt的内容
然后通过正则取它里面所有的文字数据
re.findall('[]',index['text'])
不会写正则的话,可以百度在线正则表达式匹配,把需要匹配的数据复制进去,点匹配中文字符,就全部匹配出来了。

在正则后面加个 + 就会匹配成多个字段

直接把正则复制过来
re.findall('[\u4e00-\u9fa5]+',index['text'])
匹配出来后返回的是列表,那么直接用join 把内容放进去。
content = ''.join(re.findall('[\u4e00-\u9fa5]+', index['text']))
再运行一下
import requests
import pprint
url = 'https://m.weibo.cn/comments/hotflow?id=4788920581098454&mid=4788920581098454&max_id_type=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
for index in response.json()['data']['data']:
content = ''.join(re.findall('[\u4e00-\u9fa5]+', index['text']))
dit = {
'用户': index['user']['screen_name'],
'地区': index['source'].replace('来自', ''),
'评论': content,
'日期': index['created_at']
}
print(dit)
这效果,duang的一下就出来了

数据得到后,我们再保存在CSV里面去。
这有两种方式
1、第一种 CSV
导入模块
import CSV
CSV 保存
f = open('微博评论.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'用户',
'地区',
'评论',
'日期',
])
csv_writer.writeheader()
2、第二种 pandas 也可以保存
导入模块
import pandas as pd
在response下面加上一个空列表
lis = []
然后把数据内容添加到空列表里面
lis.append(dit)
pandas 保存
pd_data = pd.DataFrame(lis)
pd_data.to_excel('微博评论.xlsx')
实现效果

我这里只爬了一页,所以只有19条数据。

这一条微博下面是有十万条评论的,我就不一一去演示了,大家可以自己去试试。
有什么python相关报错解答自己不会的、或者源码资料/模块安装/
女装大佬精通技巧都可以来这里:(https://jq.qq.com/?_wv=1027&k=2Q3YTfym)或者文末私号问我
兄弟们,来都来了,点个关注呗!
