目录
1、nn.Sequential()
一个序列容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中。除此之外,一个包含神经网络模块的OrderedDict也可以被传入nn.Sequential()容器中。利用nn.Sequential()搭建好模型架构,模型前向传播时调用forward()方法,模型接收的输入首先被传入nn.Sequential()包含的第一个网络模块中。然后,第一个网络模块的输出传入第二个网络模块作为输入,按照顺序依次计算并传播,直到nn.Sequential()里的最后一个模块输出结果。
nn.Sequential()的本质作用:
按照上边的说法,与一层一层的单独调用模块组成序列相比,nn.Sequential() 可以允许将整个容器视为单个模块(即相当于把多个模块封装成一个模块),forward()方法接收输入之后,nn.Sequential()按照内部模块的顺序自动依次计算并输出结果。
这就意味着我们可以利用nn.Sequential() 自定义自己的网络层。
参考引用链接:https://blog.csdn.net/Just_do_myself/article/details/124195393
2、super().init()
说白了就是一种继承方法,主要继承初始化阶段的参数或者函数类的数据结构等方法。而super().init()继承的是一种父类的属性,因为父类的这样的情况是可以正常的继承的,我们可以通过一个例子来说明方法:
测试1:
在此之前,python的调用是这样的:经过实验验证,可以看到此时父类的方法继承成功,可以使用,但是父类的属性却未继承,并不能用
class Root(object):
def __init__(self):
self.x= '这是属性'
def fun(self):
#print(self.x)
print('这是方法')
class A(Root):
def __init__(self):
print('实例化时执行')
test = A() #实例化类
test.fun() #调用方法
test.x #调用属性
参考来自:https://www.jb51.net/article/231139.htm
输出结果:
Traceback (most recent call last):
实例化时执行
这是方法
File "/hom/PycharmProjects/untitled/super.py", line 17, in <module>
test.x # 调用属性
AttributeError: 'A' object has no attribute 'x'
测试2:尝试下面代码,没有super(A,self).init()时调用A的父类Root的属性和方法(方法里对Root数据进行二次操作)
class Root(object):
def __init__(self):
self.x= '这是属性'
def fun(self):
print(self.x)
print('这是方法')
class A(Root):
def __init__(self):
print('实例化时执行')
test = A() #实例化类
test.fun() #调用方法
test.x #调用属性
输出结果:
Traceback (most recent call last):
File "/home/PycharmProjects/untitled/super.py", line 16, in <module>
test.fun() # 调用方法
File "/home/PycharmProjects/untitled/super.py", line 6, in fun
print(self.x)
AttributeError: 'A' object has no attribute 'x'
可以看到此时报错和测试一相似,果然,还是不能用父类的属性
测试3:加入super(A, self).init()时调用A的父类Root的属性和方法(方法里对Root数据进行二次操作)
class Root(object):
def __init__(self):
self.x = '这是属性'
def fun(self):
print(self.x)
print('这是方法')
class A(Root):
def __init__(self):
super(A,self).__init__()
print('实例化时执行')
test = A() # 实例化类
test.fun() # 调用方法
test.x # 调用属性
输出结果:
实例化时执行
这是属性
这是方法
此时A已经成功继承了父类的属性,所以super().init()的作用也就显而易见了,就是执行父类的构造函数,使得我们能够调用父类的属性。
换句话说,因为类A(Root)里面继承了Root类作为参数,所有自然就去调用父类里面的函数或者属性了。
3、model.train()和model.eval()
model.train()和model.eval()主要是针对网络中存在BN层(Batch Normalization)和Dropout,在训练模型前添加model.train(),在测试模型前添加model.eval()。
针对BN层:
model.train():是保证BN层用每一批数据的均值和方差,即针对每个mini-batch的 ;
model.eval():是保证BN用全部训练数据的均值和方差,即针对单张图片的;
针对Dropout层:
model.train():随机取一部分网络连接来训练更新参数;
model.eval():利用到了所有网络连接;
为什么有时测试时使用model.eval()会使得准确率降低?
主要是由于batch size设置较小,如1,2,训练时针对BN层计算的均值和方差只使用很小的mini batch数据,而测试中因为加入model.eval()使用的是单张图片的均值和方差,训练时的BN层学习的参数经过eval()的固定,对测试时的单张图片的均值和方差适应性较差,就会导致准确率下降。
问题解决:
如何解决model.eval()可能导致的准确率下降问题?
1.尽量将batch size设置大一些(2的整数次幂),32,64,128,256,能多大就多大,但是一般不要超过512.
2.如果设备受限,导致batch size只能设置很小(1,2),那测试时可以把eval()去掉,前提是网络结构中并没有dropout层。
参考链接:https://blog.csdn.net/weixin_44479045/article/details/124307200
4、call、forward、backward前后传播函数
原理是python中的__call__语法。例如:
class Module():
def __call__(self, data):
print('传入的参数为->', data)
module = Module()
module(1)
在pytorch中,使用torch.nn包来构建神经网络,我们定义的网络继承自nn.Module类。而一个nn.Module包含神经网络的各个层(放在__init__里面)和前向传播方式(放在forward里面),例如:
class Module(nn.Module):
# 网络结构
def __init__(self):
super(Module, self).__init__()
# ......
# 前向传播
def forward(self, x):
# ......
return x
#输入数据
data = .....
# 实例化网络
module = Module()
# 前向传播
module(data)
# 而不是使用下面的
# module.forward(data)
可以发现,我们在编写代码的时候并不会显式地去调用forward方法。原因在于:
事实上,传入的参数data就是x,因为module对象调用的forward(self, x)。
module(data)
实际上就等价于
module.forward(data)
原理分析:
首先明确为什么module是一个对象,却可以像一个方法一样传入data进行调用
module(data)
前向传播
再说一下前向传播函数forward:神经网络的典型处理如下所示:
前向传播的思想比较简单:举个例子,假设上一层结点i,j,k,…等一些结点与本层的结点w有连接,那么结点w的值怎么算呢?就是通过上一层的i,j,k等结点以及对应的连接权值进行加权和运算,最终结果再加上一个偏置项,最后在通过一个非线性函数(即激活函数),如ReLu,sigmoid等函数,最后得到的结果就是本层结点w的输出。最终不断的通过这种方法一层层的运算,得到输出层结果。
- 定义可学习参数的网络结构(堆叠各层和层的设计);
- 数据集输入;
- 对输入进行处理(由定义的网络层进行处理),主要体现在网络的前向传播;
- 计算loss ,由Loss层计算;
- 反向传播求梯度;
- 根据梯度改变参数值,最简单的实现方式(SGD)为:
weight = weight - learning_rate * gradient
后向传播
首先来一个反向传播算法的定义(转自维基百科):反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)
参考链接:https://blog.csdn.net/ft_sunshine/article/details/90221691
https://blog.csdn.net/qq_41033011/article/details/109325070
BackPropagation算法是多层神经网络的训练中举足轻重的算法。简单的理解,它的确就是复合函数的链式法则,但其在实际运算中的意义比链式法则要大的多。要回答题主这个问题“如何直观的解释back propagation算法?” 需要先直观理解多层神经网络的训练。
机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系.
深度学习同样也是为了这个目的,只不过此时,样本点不再限定为(x, y)点对,而可以是由向量、矩阵等等组成的广义点对(X,Y)。而此时,(X,Y)之间的关系也变得十分复杂,不太可能用一个简单函数表示。然而,人们发现可以用多层神经网络来表示这样的关系,而多层神经网络的本质就是一个多层复合的函数。借用网上找到的一幅图[1],来直观描绘一下这种复合关系。
具体实现torch.Tensor.backward():
backward(gradient=None, retain_graph=None, create_graph=False)
函数的作用:
获取计算图中某个tensor的叶子节点的梯度(无法获取非叶子节点的梯度)
计算图:一个函数构成了一个计算图,计算图的根节点是函数的输出,叶子节点是函数的输入
叶子节点:图结构中没有子节点的节点
代码案例:
定义了一个复合函数:对x1和x2 求导,依据链式求导法则,可以求得两者梯度分别为2和3,与输出一致。值得注意,y1和y2是函数z的中间变量(非叶子节点),因此其导数值为None
x1 = 1, x2 = 2
y1 = x1 + 1, y2 = x2 + 1
z = 0.5 * (y1^2 + y2^2)
z.backward()表示对z的叶子节点求导,也就是:

参考来自:https://blog.csdn.net/weixin_42075898/article/details/103377850
模型案例: loss.backward()就是对梯度函数求导
#参考:https://mp.weixin.qq.com/s/GVdmWokPutC86ZQgSr6TJw
for epoch in range(2):
running_loss =0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if i% 2000 ==1999:
print("[%d, %5d] loss: %.3f" %(epoch +1, i+1, running_loss/2000))
running_loss = 0.0
print("Finished Training")
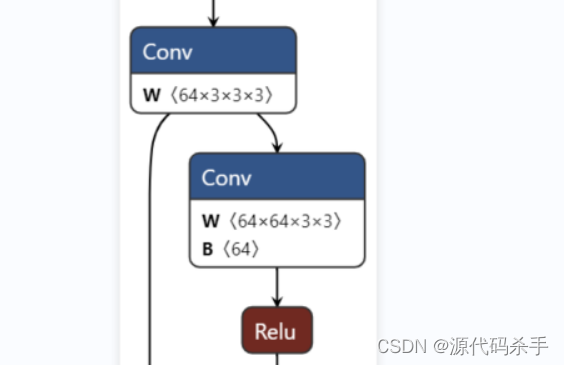
5、模型案例分析
至于如何使用super().init(),方法同上。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.onnx
import netron
class model(nn.Module):
def __init__(self):
super(model, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(64, 64, 3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 32, 1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, 3, padding=1, bias=False),
nn.BatchNorm2d(64)
)
self.conv1 = nn.Conv2d(3, 64, 3, padding=1, bias=False)
self.output = nn.Sequential(
nn.Conv2d(64, 1, 3, padding=1, bias=True),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
identity = x
x = F.relu(self.block1(x) + identity)
x = self.output(x)
# print("x:", x.shape) # 在不知道torch.rand(1, 3, 416, 416)的情况下可以使用这个命令来查找
return x
print(model())
d = torch.rand(1, 3, 416, 416)
# print(len(d[0][1]))
# print(d[0])
m = model()
o = m(d)
onnx_path = "onnx_model_name.onnx"
torch.onnx.export(m, d, onnx_path)
netron.start(onnx_path)
参考资料
https://blog.csdn.net/weixin_41194129/article/details/125660420?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_34775330/article/details/121343443
https://blog.csdn.net/u011501388/article/details/84062483