一、二分查找的实现
对于给定的已经有序的数列,我们需要在该数列中查找是否存在某个元素。
每次都与数列最中间的元素进行比较,可以缩小一半的查找区间,直至找到目标元素或者区间被缩小为0,元素不存在。比如下面的数列中,我们想要查找元素19,那么大致的过程就是这样的:
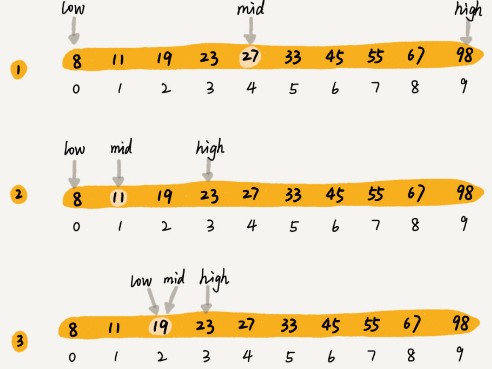
二分查找过程示意图
使用代码实现如下:
public static void main(String[] args) {
int[] data = {
8, 11, 19, 23, 27, 33, 45, 55, 67, 98};
int result = binarySearch(data, data.length, 19);
log.info("查找元素19的位置是:{}", result);
}
public static int binarySearch(int[] data, int size, int target) {
int low = 0;
int high = size - 1;
while (low <= high) {
int middle = (low + high) / 2;
if (data[middle] == target) {
return middle;
} else if (data[middle] < target) {
low = middle + 1;
} else {
high = middle - 1;
}
}
log.info("元素{}查找不存在!", target);
return -1;
}
二分查找的时间复杂度是O(logn),对数阶时间复杂度的算法效率非常高。
二、二分查找的特点及使用场景
二分查找必须依赖以下条件才能发挥作用:
- 数据结构一定要是顺序表,比如数组。如果是不支持随机访问的数据结构,那么二分查找就无法使用;
- 待查找的数列一定要是有序的。如果给定的数列是无序的,那么我们就必须先使用排序算法将数列进行排序,否则也无法使用二分查找;
- 不适合频繁插入和删除的数列;因为数列需要保持有序,要么在插入和删除的时候保证有序,要么在插入数列后使用排序算法进行排序,这些都是时间开销;
- 不适合数据量太小的数列;数列太小,直接顺序遍历说不定更快,也更简单;但是有一种场景除外,就是每次元素与元素的比较是比较耗时的,这个比较操作耗时占整个遍历算法时间的大部分,那么使用二分查找就能有效减少元素比较的次数,从而节约时间;
- 不适合数据量太大的数列;二分查找作用的数据结构是顺序表,也就是数组,数组是需要连续的内存空间的,系统并不一定有这么大的连续内存空间可以使用;
三、二分查找相关的变体
-
查找第一个等于给定值的元素
public static void main(String[] args) { int[] data = { 8, 11, 19, 19, 19, 33, 45, 55, 67, 98}; int result = binarySearch1(data, data.length, 19); log.info("查找元素19的位置是:{}", result); } public static int binarySearch1(int[] data, int size, int target) { int low = 0; int high = size - 1; while(low <= high){ int middle = (low + high) / 2; if(data[middle] > target){ high = middle - 1; } else if(data[middle] < target){ low = middle + 1; } else { // 当前元素等于目标元素,但是不一定是第一个等于目标元素的 if((middle == 0) || (data[middle-1] != target)){ // 说明当前middle是第一个等于目标元素的 return middle; } else { // 继续在middle的前半区间进行查找 high = middle - 1; } } } return -1; } -
查找最后一个等于给定值的元素
else { // 当前元素等于目标元素,但是不一定是最后一个等于目标元素的 if((middle == size-1) || (data[middle+1] != target)){ // 说明当前middle是最后一个等于目标元素的 return middle; } else { // 继续在middle的后半区间进行查找 low = middle + 1; } } -
查找第一个大于等于给定值的元素
public static int binarySearch3(int[] data, int size, int target) { int low = 0; int high = size - 1; while(low <= high){ int middle = (low + high) / 2; if(data[middle] >= target){ if(middle == 0 || data[middle-1] < target){ // 是第一个大于等于target的位置 return middle; } else { // 继续往middle的前半部分去找 high = middle - 1; } } else { // 继续往middle的后半部分去找 low = middle + 1; } } return -1; } -
查找最后一个小于等于给定值的元素
public static int binarySearch4(int[] data, int size, int target) { int low = 0; int high = size - 1; while(low <= high){ int middle = (low + high) / 2; if(data[middle] <= target){ if(middle == (size-1) || data[middle+1] > target){ return middle; } else { low = middle + 1; } } else { high = middle - 1; } } return -1; }
四、总结
在实际的查找业务场景中,凡是可以使用二分查找的问题都可以使用散列表和二叉查找树来完成,而且后面两者的使用频率要更高。
什么情况下才使用二分查找呢?用于求解近似查找的问题上,比如上面描述的四种二分查找变体问题,而这类问题使用散列表、二叉查找树或者别的数据结构和算法就不太好实现。