打印某行到某行之间的内容
编辑test.txt如需要打印下划线之间的内容,而上面和下面分别有未知数行,可以使用命令:
sed -n '/\[telescope\]/, /\[hefty]\/p' test.txt (原型为sed -n '/ /, / /p' filename,此处需要注意转义符的使用)
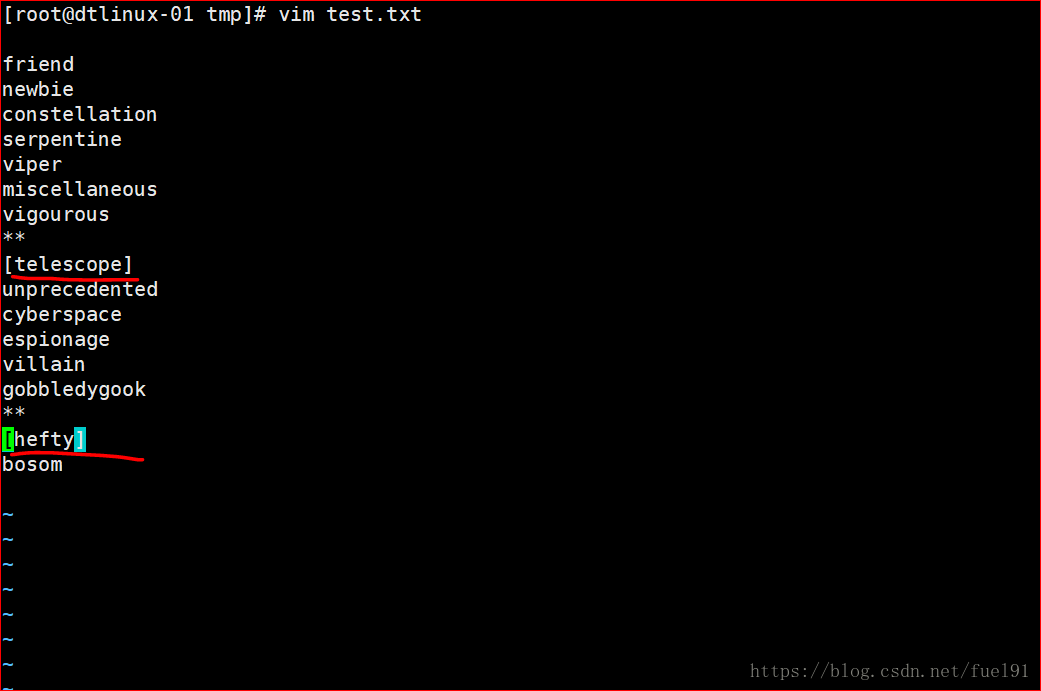
输出结果如下图所示:
sed 如何转换大小写字母
sed中\u表示大写,\l表示小写,\b表示边界,&表示前面输出的代入
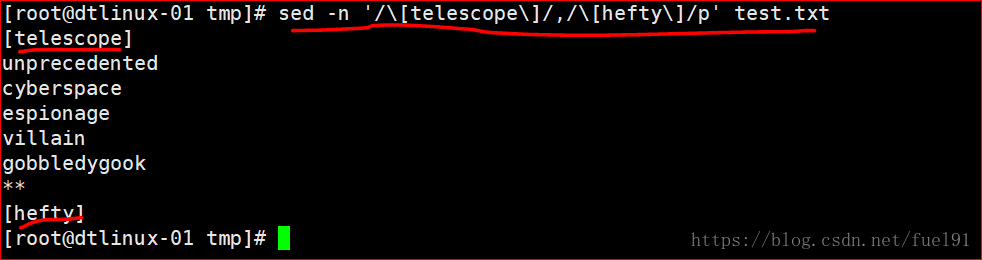
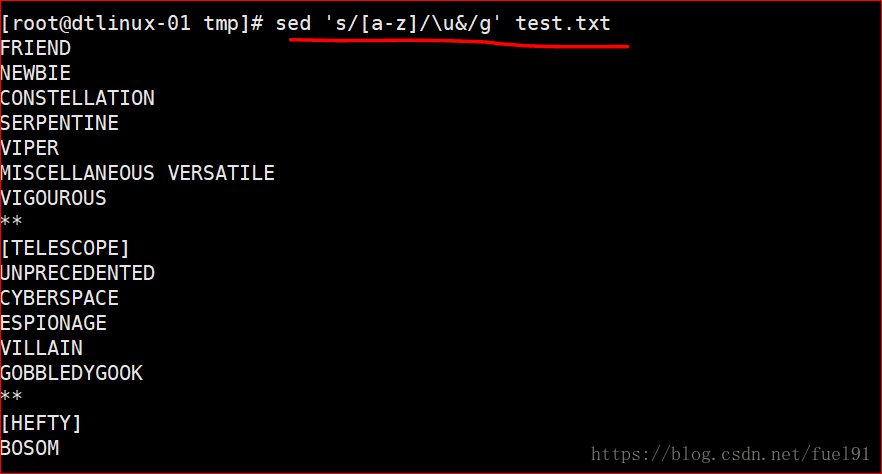
①把每个单词的第一个小写字母变大写:
sed 's/\b[a-z]/\u&/g' filename
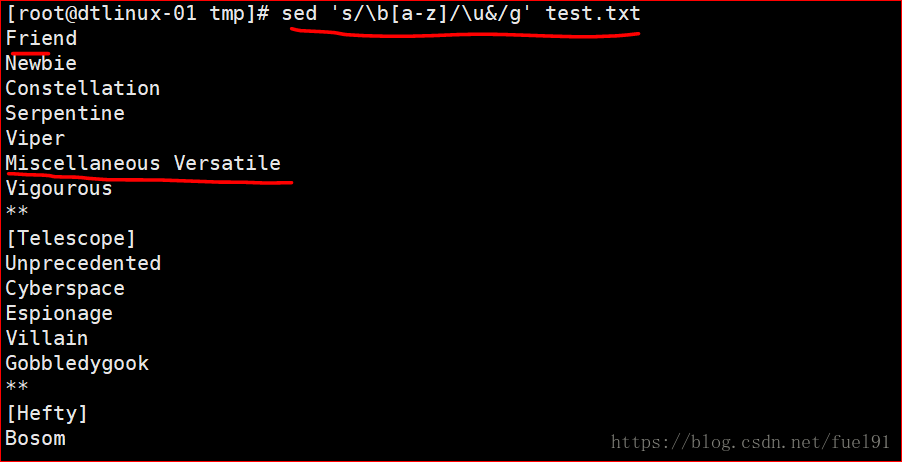
②把所有小写变成大写
sed 's/[a-z]/[A-Z]/g' filename (错误,这样的输出等于是把前面的主体全部替换成字符串[A-Z])
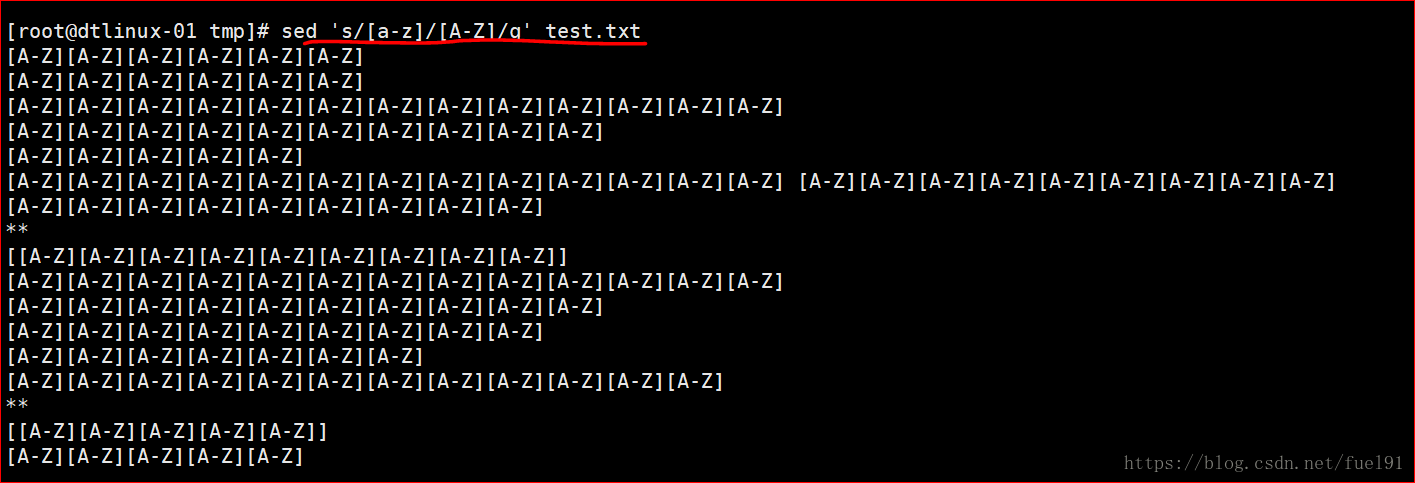
sed 's/[a-z]/\u&/g' filename(和第一种相比只是把边界符\b去掉,全部改成大写)
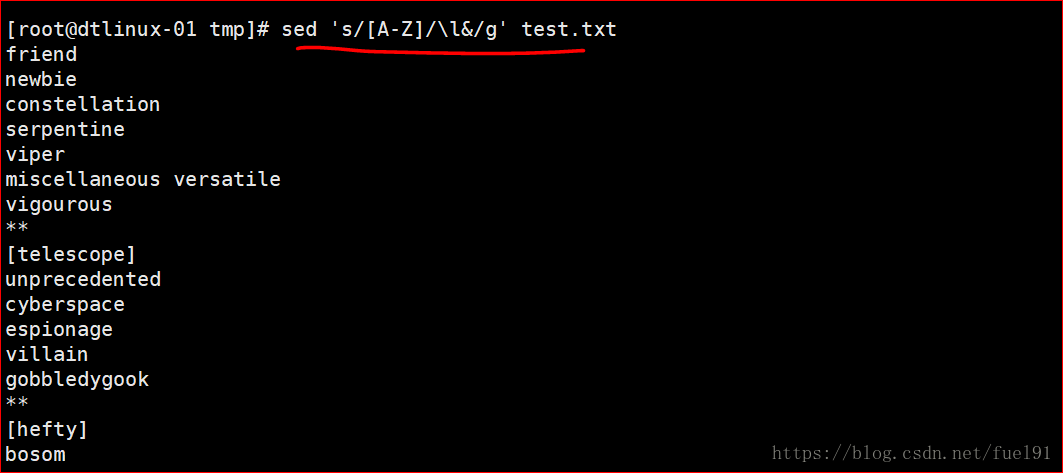
③同理,大写变小写为:
sed 's/[A-Z]/\l&/g' filename
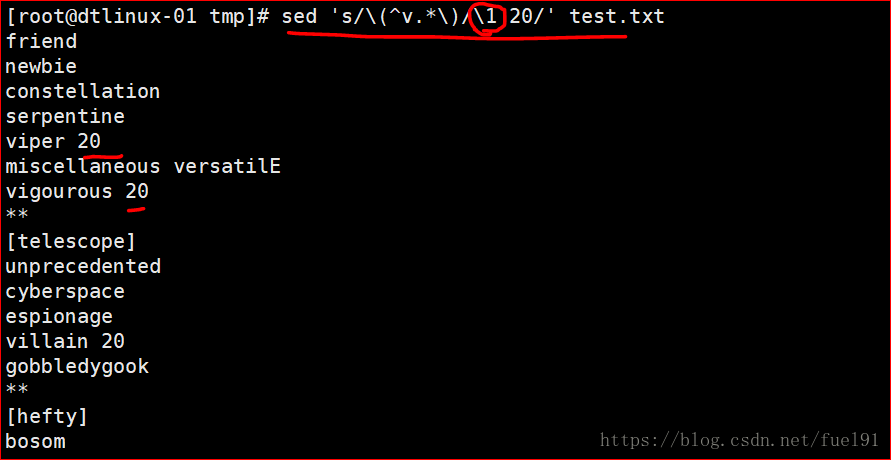
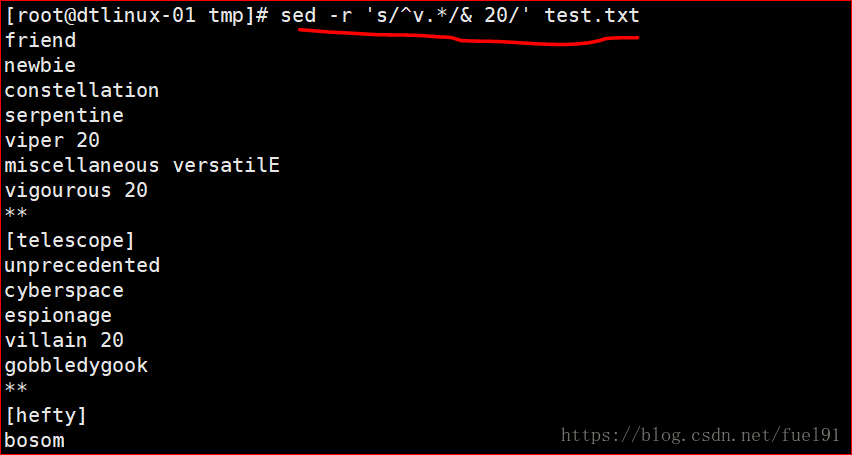
sed 's/\(^a.*\)/\1 20/' test.txt (主体是以字母a开头,贪婪匹配后任意字符结尾,替换体是数字20 )(当前面的主体只有一个括号时&==\1)
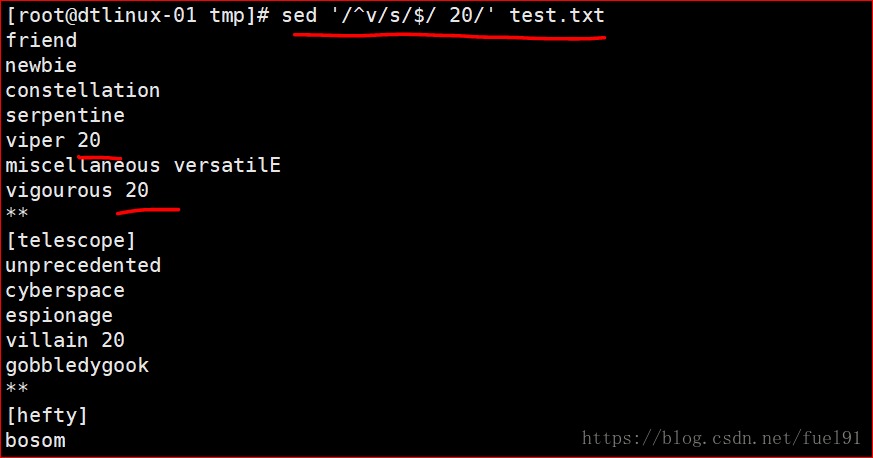
或者先匹配带有某字符串的行再行尾进行替换添加:(此处以v为例)
sed '/^v/s/$/ 20/' filename
sed -r可以不需要加转义符
删除某行到最后一行
[root@test200 ~]# cat test
a
b
c
d
e
f
[root@test200 ~]# sed '/c/{p;:a;N;$!ba;d}' test
a
b
c
定义一个标签a,匹配c,然后N把下一行加到模式空间里,匹配最后一行时,才退出标签循环,然后命令d,把这个模式空间里的内容全部清除。
if 匹配"c"
:a
追加下一行
if 不匹配"$"
goto a
最后退出循环,d命令删除。
扩展:
保持和获取:h命令和G命令
在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。
sed -e '/test/h' -e '$G' file
在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
打印奇数行或偶数行
方法1:
sed -n 'p;n' test.txt #奇数行 sed -n 'n;p' test.txt #偶数行
方法2:
sed -n '1~2p' test.txt #奇数行 sed -n '2~2p' test.txt #偶数行
打印匹配字符串的下一行
grep -A 1 SCC URFILE sed -n '/SCC/{n;p}' URFILE awk '/SCC/{getline; print}' URFILE
如何使用sed打印1到100行包含某个字符串的行
sed '1,100{/xxxx/p}' test.txt 此处以"vi"为例
