本文主要大体谈谈视频编码压缩的原理。视频原始数据是非常大的,如果不进行编码压缩的话,不管是存储还是传输都将非常的麻烦。因此为了解决这个问题,就出现非常多的编码压缩方法和格式,H264、H265、VP8、VP9 和 AV1等等都是市面上常见的编码标准。不过编码压缩的核心原理和准则是大同小异的。
一、视频图像存在的冗余
视频是一帧帧图像组成的,图像一般是有数据冗余的,主要包括以下 4 种:
1、空间冗余。比如说将一帧图像划分成一个个 16x16 的块之后,相邻的块很多时候都有比较明显的相似性,这种就叫空间冗余。
2、时间冗余。一个帧率为 25fps 的视频中前后两帧图像相差只有 40ms,两张图像的变化是比较小的,相似性很高,这种叫做时间冗余。
3、视觉冗余。我们的眼睛是有视觉灵敏度这个东西的。人的眼睛对于图像中高频信息的敏感度是小于低频信息的。有的时候去除图像中的一些高频信息,人眼看起来跟不去除高频信息差别不大,这种叫做视觉冗余。
4、信息熵冗余。我们一般会使用 Zip 等压缩工具去压缩文件,将文件大小减小,这个对于图像来说也是可以做的,这种冗余叫做信息熵冗余。可以理解为为了表达同样的内容,所用的表达方式是否啰嗦,比如对于一串字符串aaabbbb,如果采用3a4b来表达,就简略了一些。
视频编码就是通过减少上述 4 种冗余来达到压缩视频的目的。
二、编码压缩的核心准则和思路
对于一个 YUV 图像,我们把它划分成一个个 16x16 的宏块(以 H264 为例),Y、U、V 分量的大小分别是 16x16、8x8、8x8。这里我们只对 Y 分量进行分析(U、V 分量同理)。假设 Y 分量这 16x16 个像素就是一个个数字,我们从左上角开始之字形扫描每一个像素值,则可以得到一个“像素串”。如下图所示:
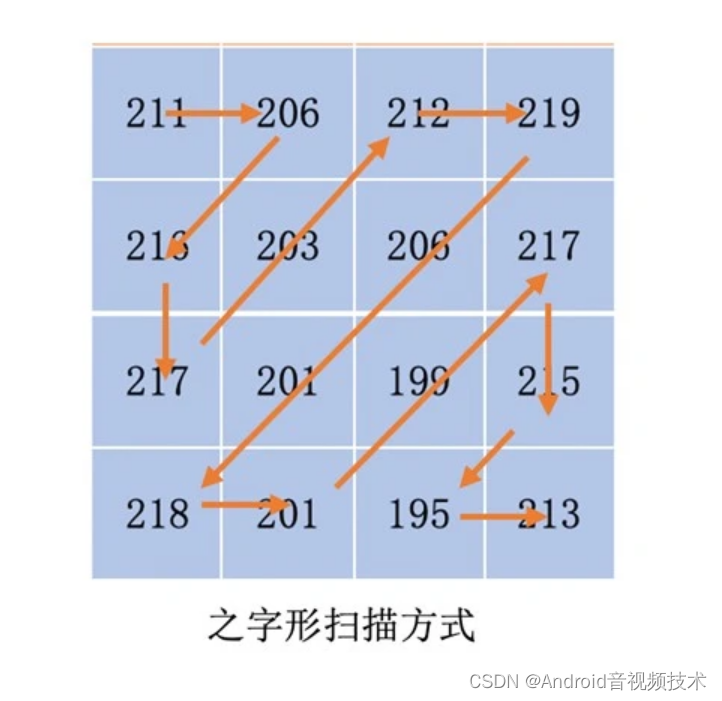
有一种编码方式叫做行程编码,就是将类似 “bbbaaaaddddd” 压缩成 “3b4a5d”,字符串由 12 个字符压缩到 6 个字符。如果我们对图像宏块扫描出来的这个“像素串”做同样的行程编码操作,是不是也有可能减小图像块呢?答案是肯定的。但是这里有个问题是如果字符串是交替出现,比如adcdcabdc这种,没有多少连续的字符的话,那么压缩就没有意义了。所以,最好是有很多连续的字符,这样压缩才有意义。而且如果连续的这个字符是个占用空间很小的字符那就更好了。比如0,因为0在二进制中只占1个位。
所以,编码压缩的核心准则就是,尽可能地使得像素值串出现很多的字节占用空间较小的连续的像素值,这样就可以方便压缩,且压缩效果较好。
那么如何做到呢?下面继续:
三、减少图像的空间冗余和时间冗余
上面我们也说到,图像内部相邻宏块之间有很多相似性,并且两张图像之间也有很多相似性。因此,根据图像的这个特点,我们可以在编码的时候进行帧内预测和帧间预测。
帧内预测就是在当前编码图像内部已经编码完成的块中找到与将要编码的块相邻的块。一般就是即将编码块的左边块、上边块、左上角块和右上角块,通过将这些块与编码块相邻的像素经过多种不同的算法得到多个不同的预测块。
然后我们再用编码块减去每一个预测块得到一个个残差块。最后,我们取这些算法得到的残差块中像素的绝对值加起来最小的块为预测块。而得到这个预测块的算法为帧内预测模式。
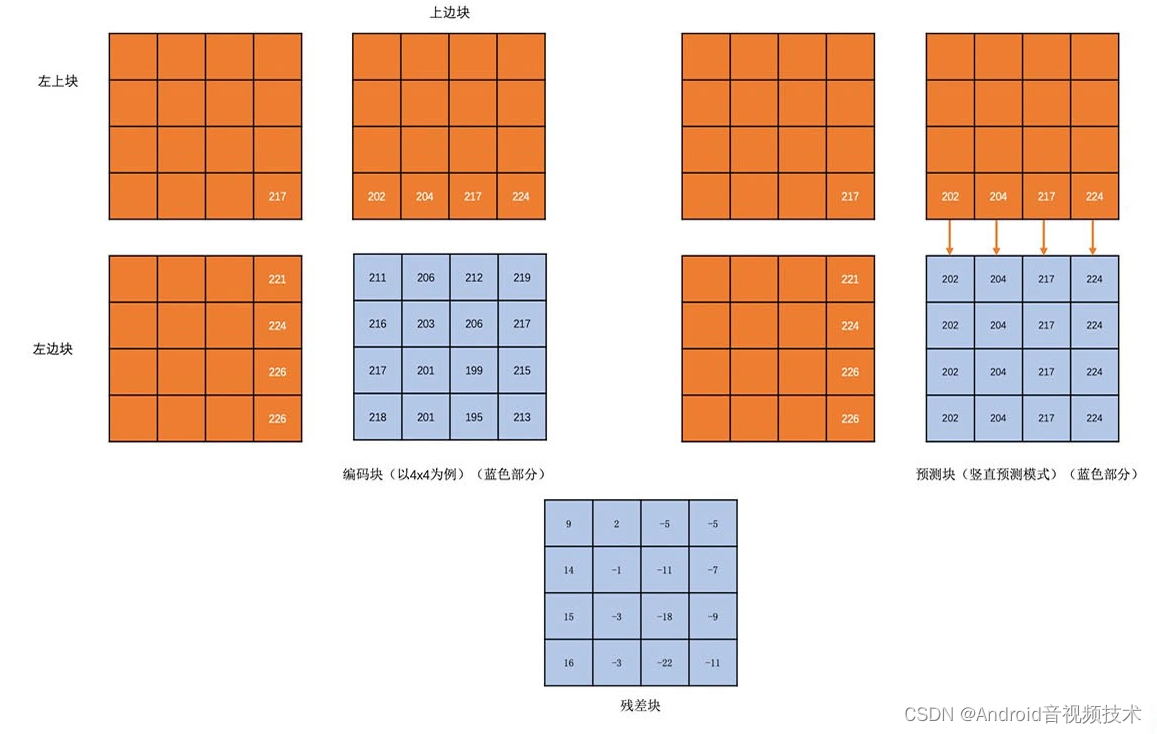
由于这个残差块中像素的绝对值之和最小,这个残差块的像素值经过扫描之后的“像素串”就比直接扫描编码块的“像素串”中的像素值更接近 0 了。
同理,帧间预测也是一样的。我们在前面已经编码完成的图像中,循环遍历每一个块,将它作为预测块,用当前的编码块与这个块做差值,得到残差块,取残差块中像素值的绝对值加起来最小的块为预测块,预测块所在的已经编码的图像称为参考帧。
预测块在参考帧中的坐标值 (x0, y0) 与编码块在编码帧中的坐标值 (x1, y1) 的差值 (x0 - x1, y0 - y1) 称之为运动矢量。而在参考帧中去寻找预测块的过程称之为运动搜索。事实上编码过程中真正的运动搜索不是一个个块去遍历寻找的,而是有快速的运动搜索算法的。这个算法在这里就不展开阐述。
总之,通过预测得到的残差块的像素值相比编码块的像素值,去除了大部分空间冗余信息和时间冗余信息,这样得到的像素值更小。如果把这个残差块做扫描得到的像素串送去做行程编码,这样相比直接拿编码块的像素串去做编码更有可能得到更大的压缩率。
但是我们的目标不只是将像素值变小,而是希望能出现连续的,该如何去做呢?下面继续:
四、DCT变化和量化
这个主要是利用我们人眼的视觉敏感性的特点。我们上面讲到人眼对高频信息不太敏感。因为人眼看到的效果可能差别不大,所以我们可以去除一些高频信息。
为了分离图像块的高频和低频信息,我们需要将图像块变换到频域。常用的变换是 DCT 变换。DCT 变换又叫离散余弦变换。在 H264 里面,如果一个块大小是 16x16 的,我们一般会划分成 16 个 4x4 的块(当然也有划分成 8x8 做变换的,我们这里以 4x4 为例)。然后对每个 4x4 的块做 DCT 变换得到相应的 4x4 的变换块。
变换块的每一个“像素值”我们称为系数。变换块左上角的系数值就是图像的低频信息,其余的就是图像的高频信息,并且高频信息占大部分。低频信息表示的是一张图的总体样貌。一般低频系数的值也比较大。而高频信息主要表示的是图像中人物或物体的轮廓边缘等变化剧烈的地方。高频系数的数量多,但高频系数的值一般比较小(注意不是所有的高频系数都一定小于低频,只是大多数高频系数比较小)。如下图所示(黄色为低频,绿色为高频):
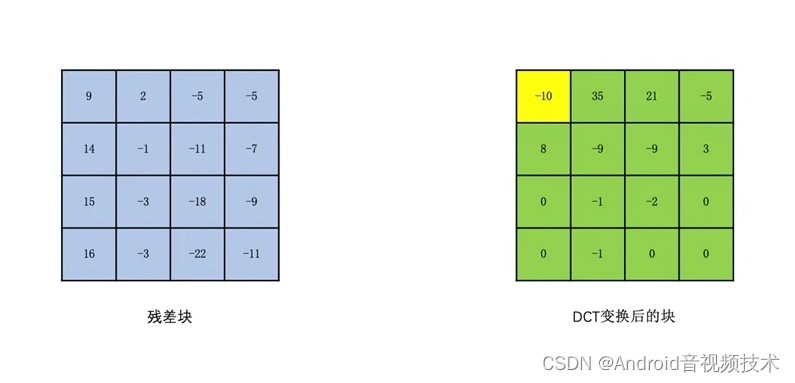
这样做完了 DCT 变换之后,低频和高频信息就分离开来了。由于低频信息在左上角,其余的都是高频信息。那么如果我们对变换块的像素值进行“之字形”扫描,这样得到的像素串,前面的就是数值比较大的低频系数,后面就是数值比较小的高频部分。
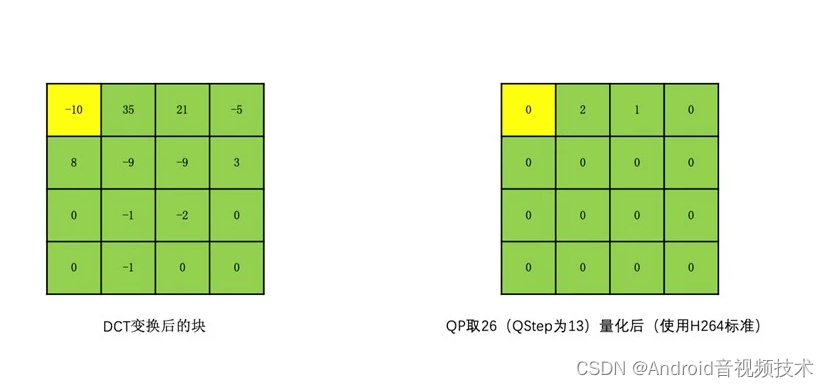
由于人眼对高频信息不太敏感,如果我们通过一种手段去除掉大部分高频信息,也就是将大部分高频信息置为 0,但又不太影响人的观感,是不是就可以达到我们最初的目标,即可以得到有一连串 0 的像素串?这就涉及到量化操作了。
我们让变换块的系数都同时除以一个值,这个值我们称之为量化步长,也就是 QStep(QStep 是编码器内部的概念,用户一般使用量化参数 QP 这个值,QP 和 QStep 一一对应,你可以自行去网上查询一下转换表),得到的结果就是量化后的系数。QStep 越大,得到量化后的系数就会越小。同时,相同的 QStep 值,高频系数值相比低频系数值更小,量化后就更容易变成 0。这样一来,我们就可以将大部分高频系数变成 0。如下图所示:
解码的时候,我们会将 QStep 乘以量化后的系数得到变换系数,很明显这个变换系数和原始没有量化的变换系数是不一样的,这个就是我们常说的有损编码。而到底损失多少呢?
这由 QStep 来控制,QStep 越大,损失就越大。QStep 跟 QP 一一对应,也就是说确定了一个 QP 值,就确定了一个 QStep。所以从编码器应用角度来看,QP 值越大,损失就越大,从而画面的清晰度就会越低。同时,QP 值越大系数被量化成 0 的概率就越大,这样编码之后码流大小就会越小,压缩就会越高。
五、熵编码
这是视频编码压缩的最后一步,也是真正实现“压缩”的一步,前面的几步是一个预热,是为了最后一步的压缩能达到最大效益的一个预处理。这一步主要是去除信息熵冗余,就比如在上面所讲的行程编码,就是一种简单的熵编码,上面的例子让需要12个字符才能表达的内容用6个字符就表达完了。
熵编码有很多,且有分为可变长编码,如哈夫曼编码、香农-费诺编码编码、指数哥伦布编码等;以及算术编码,如CAVLA、CABAC、指数编码。这些熵编码的目的都是一样,就是去除信息熵冗余,达到压缩的目的,就如简单的行程编码类似。
熵编码的方法很多,这里不再一一阐述,本文的核心主要是集中在原理,和大体的思路。
总结:
至此,视频编码的原理和思路就如上所述了。总结下来可以理解为几步:
1、预测(帧内预测,帧间预测):为了去除空间冗余和时间冗余;
2、DCT变化和量化:为了去除视觉冗余;
3、熵编码:为了去除信息熵冗余。