@Service
// Spring中InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,
// 凡是继承该接口的类,在初始化bean的时候会执行该方法。
public class SensitiveService implements InitializingBean {
private static final Logger logger = LoggerFactory.getLogger(SensitiveService.class);
@Override
public void afterPropertiesSet() throws Exception {
try {
InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream("SensitiveWords.txt");
InputStreamReader reader = new InputStreamReader(is);
BufferedReader bufferedReader = new BufferedReader(reader);
String lineTxt;
while ((lineTxt = bufferedReader.readLine()) != null) {
addWord(lineTxt.trim());
}
reader.close();
} catch (Exception e) {
logger.error("读取敏感词文件失败" + e.getMessage());
}
}
private void addWord(String lineTxt) {
TrieNode tempNode = rootNode;
for (int i = 0; i < lineTxt.length(); i++) {
Character c = lineTxt.charAt(i);
if (isSymbol(c)) {
continue;
}
TrieNode node = tempNode.getSubNode(c);
if (node == null) {
node = new TrieNode();
tempNode.addSubNodes(c, node);
}
tempNode = node;
if (i == lineTxt.length() -1) {
tempNode.setKeyWordEnd(true);
}
}
}
private boolean isSymbol(char c) {
int ic = (int)c;
return !CharUtils.isAsciiAlphanumeric(c) && (ic < 0x2E80 || ic > 0x9FFF);
}
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return text;
}
String replacement = "***";
StringBuilder result = new StringBuilder();
TrieNode tempNode = rootNode;
int begin = 0;
int position = 0;
while (position < text.length()) {
char c = text.charAt(position);
if (isSymbol(c)) {
if (tempNode == rootNode) {
result.append(c);
begin++;
}
position++;
continue;
}
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
result.append(text.charAt(begin));
position = begin + 1;
begin = position;
tempNode = rootNode;
} else if (tempNode.isKeyWordEnd()) {
result.append(replacement);
position = position + 1;
begin = position;
tempNode = rootNode;
} else {
position++;
}
}
return result.toString();
}
private class TrieNode {
private boolean end = false;
private Map<Character, TrieNode> subNodes = new HashMap<>();
public void addSubNodes(Character key, TrieNode node) {
subNodes.put(key, node);
}
TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
boolean isKeyWordEnd() {
return end;
}
void setKeyWordEnd(boolean end) {
this.end = end;
}
}
private TrieNode rootNode = new TrieNode();
/* public static void main(String[] args) {
SensitiveService s = new SensitiveService();
s.addWord("色情");
s.addWord("赌博");
System.out.println(s.filter(" 你 好色 情"));
}*/
}
首先介绍内部类TrieNode,前缀树(字典树)节点,subNodes存的是所有子节点。
private class TrieNode {
//判断是否为叶结点
private boolean end = false;
//子节点集合
private Map<Character, TrieNode> subNodes = new HashMap<>();
//加入子节点
public void addSubNodes(Character key, TrieNode node) {
subNodes.put(key, node);
}
//获得子节点
TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
boolean isKeyWordEnd() {
return end;
}
void setKeyWordEnd(boolean end) {
this.end = end;
}
}
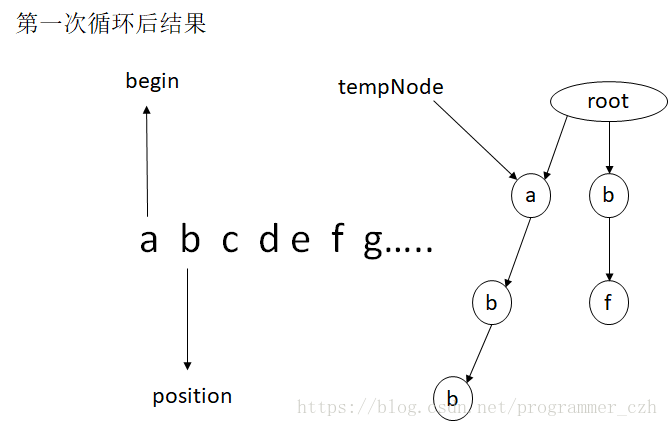
初始化前缀树时需要addWord方法,假如把abc作为敏感词加入前缀树中,即add("abc"),i = 0时,运行到第8行,rootNode没有以a为key的子节点,node为空,则将a作为rootNode的子节点,然后tempNode指向a-Node,a-Node没有以b为key的子节点,node为空,将b作为a-Node的子节点,然后tempNode指向b-Node,b-Node没有以c为key的子节点,node为空,将c作为b-Node的子节点,然后tempNode指向c-Node,而c为最后一个字符,所以将其end属性设为true。
private void addWord(String lineTxt) {
TrieNode tempNode = rootNode;
for (int i = 0; i < lineTxt.length(); i++) {
Character c = lineTxt.charAt(i);
if (isSymbol(c)) {
continue;
}
TrieNode node = tempNode.getSubNode(c);
if (node == null) {
node = new TrieNode();
tempNode.addSubNodes(c, node);
}
tempNode = node;
if (i == lineTxt.length() -1) {
tempNode.setKeyWordEnd(true);
}
}
}
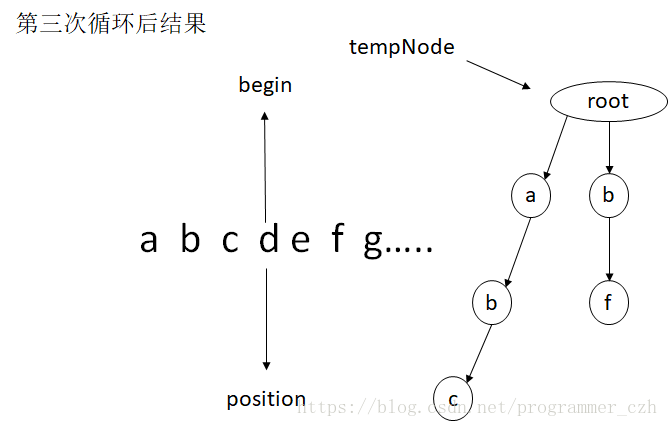
核心方法,过滤filter(),tempNode是指向前缀树的当前节点,begin为每次的最前面的一个元素,position为每次的当前位置。
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return text;
}
String replacement = "***";
StringBuilder result = new StringBuilder();
TrieNode tempNode = rootNode;
int begin = 0;
int position = 0;
while (position < text.length()) {
char c = text.charAt(position);
if (isSymbol(c)) {
if (tempNode == rootNode) {
result.append(c);
begin++;
}
position++;
continue;
}
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
result.append(text.charAt(begin));
position = begin + 1;
begin = position;
tempNode = rootNode;
} else if (tempNode.isKeyWordEnd()) {
result.append(replacement);
position = position + 1;
begin = position;
tempNode = rootNode;
} else {
position++;
}
}
return result.toString();
}
private boolean isSymbol(char c) {
int ic = (int)c;
//东亚文字0x2E80-0x9FFF,既不是英文也不是东亚文字,返回true。
return !CharUtils.isAsciiAlphanumeric(c) && (ic < 0x2E80 || ic > 0x9FFF);
}
其中isSymbol的作用是防止敏感词字符之间插入特殊符号来避开过滤,比如色*情,此时我们需要把这样的符号直接跳过,加强过滤的效果。
过滤的模拟过程图 ,abc为敏感词,abcdefg...为需要过滤的字符串。