资源下载地址:https://download.csdn.net/download/sheziqiong/85824573
资源下载地址:https://download.csdn.net/download/sheziqiong/85824573
词法分析程序的编写
设计内容
处理 pl0 语言的源程序,过滤掉一些无用符号,如换行符,制表符,回车符,判断源程序中单词的合法性,分解出正确的单词,以一种二元式的形式(单词种别,单词自身的值)存储在文件中。
单词符号可以分为5种类别:基本字、标识符、常数、运算符、界符。
对于 pl0 语言:
- 基本字:
begin,end,if,then,while,do,const,var,call,procedure,odd。 - 标识符:以字母开头,后面跟上字母或数字。
- 常数:数字的正闭包。
- 运算符:
+,-,*,/,:=,<,<=,>,>=,<>,=,#。 - 界符:
,,.,;,(,)。
词法分析程序应该完成以下的功能:滤空格、识别保留字、识别标识符、拼数、拼复合词。
首先对程序中出现的单词符号做一个编码
| 单词符号 | 种别码 |
|---|---|
begin |
1 |
end |
2 |
if |
3 |
then |
4 |
while |
5 |
do |
6 |
const |
7 |
var |
8 |
call |
9 |
procedure |
10 |
odd |
11 |
| `letter(letter | digit)*` |
digitdigit* |
13 |
+ |
14 |
- |
15 |
* |
16 |
/ |
17 |
:= |
18 |
< |
19 |
<= |
20 |
> |
21 |
>= |
22 |
<> |
23 |
= |
24 |
# |
25 |
, |
26 |
; |
27 |
( |
28 |
) |
29 |
: |
30 |
. |
0 |
读入源程序
char[] source = new char[8000];
// 开启文件流,读入文件
try(BufferedReader reader = new BufferedReader(new FileReader("./src/source.txt"));){
reader.read(source);
} catch(IOException e){
e.printStackTrace();
}
对源程序做预处理,去除掉注释、换行符等
对源程序做一个总体的扫描,当扫描到\,可能是单行注释,也可能是除号;扫描到(时,可能是括号,也可能是多行注释;当扫描到\n,\t,\r这些无用符号时,略过。
// 首先,对输入源程序做预处理,处理掉注释、换行符、制表符等等
public char[] preProcess(char[] source) throws IllegalArgumentException{
// 构造一个临时数组存储预处理后的源程序
char[] temp = new char[8000];
int count = 0;
// 逐个扫描源程序中的字符
outLoop: for (int i=0; i<source.length; i++){
switch (source[i]){
// 去除单行注释
case '/':
if (source[i+1] == '/'){
// 跳过单行注释
i = i+2;
// 跳过这一行,直到遇到回车换行
while (source[i] != '\n'){
i++;
}
} else{
temp[count++] = source[i];
}
break;
// 去除多行注释
case '(':
if (source[i+1] == '*'){
// 跳过多行注释符号
i = i+2;
// 当不满足匹配多行注释的时候,跳过
while (!(source[i] == '*' && source[i+1] == ')')){
i++;
// 检查有没有到程序的末尾
if (i >= source.length -2){
throw new IllegalArgumentException("源程序的注释不匹配!");
}
}
// 跳过多行注释符号
i = i+2;
} else{
temp[count++] = source[i];
}
case '\n':
case '\t':
case '\r':
i++;
break;
// 程序结束标志
case '.':
temp[count++] = source[i];
break outLoop;
default:
temp[count++] = source[i];
}
}
// 设置源程序的长度为count
this.length = count;
return temp;
}
下面就可以开始进行单词符号的识别了。
构造编码表
使用map映射来构造一个单词的编码表:
keyWords = new HashMap<>();
keyWords.put("begin", 1);
keyWords.put("end", 2);
...
keyWords.put(")", 29);
keyWords.put(":", 30);
单词识别
首先要去除掉空格,主要分为三种情况:首字符为字母,首字符为数字,首字符为其他符号。
- 首字符为字母:判断是否全为字母,如果全为字母,就是保留字,否则就是标识符。
- 首字符为数字:判断是否全为数字,如果是,就是常数,否则就是非法单词。
- 首字符为其他:使用switch语句判断。
这里函数的参数为待分析代码的字符数组,分析的开始位置,Token为自定义的类,有String类型的值和int类型的值两个属性,标识识别出单词的值和种别码。
// 识别单词符号
public Token scanner(char[] code, int begin){
// 我们知道,要识别的PL/0语言中的单词符号有这几个类别:
// 保留字、标识符、常数、运算符和界符
// 可以进一步粗分为3类,字母开头(保留字和标识符)数字开头(常数)其他
// 存储当前识别的单词符号
char[] token = new char[20];
// 指向程序的索引
int index1 = begin;
// 指向存储单词的数组的索引
int index2 = 0;
// 除去单词前的空格
while (code[index1] == ' '){
index1++;
}
// 如果单词的首字符为字母
if (Character.isLetter(code[index1])){
// 当后续为字母或数字时存入
while (Character.isLetter(code[index1]) || Character.isDigit(code[index1])){
token[index2++] = code[index1++];
}
// 在map中查找,如果能查找到说明是保留字
// 否则说明是标识符
// 每次返回都要维护下index1
this.setBegin(index1);
return new Token(String.valueOf(token).trim(), this.keyWords.getOrDefault(String.valueOf(token).trim(), 12));
} else if (Character.isDigit(code[index1])){
// 如果首字符是数字
while (Character.isDigit(code[index1])){
token[index2++] = code[index1++];
}
this.setBegin(index1);
return new Token(String.valueOf(token).trim(), 13);
} else {
switch (code[index1]){
case ':':
if (code[index1 + 1] == '='){
this.setBegin(index1+2);
return new Token(":=", this.keyWords.get(":="));
} else {
this.setBegin(index1+1);
return new Token(":", this.keyWords.get(":"));
}
case '<':
if (code[index1 + 1] == '='){
this.setBegin(index1+2);
return new Token("<=", this.keyWords.get("<="));
} else if(code[index1 + 1] == '>') {
this.setBegin(index1+2);
return new Token("<>", this.keyWords.get("<>"));
} else{
this.setBegin(index1+1);
return new Token("<", this.keyWords.get("<"));
}
case '>':
if (code[index1 + 1] == '='){
this.setBegin(index1+2);
return new Token(">=", this.keyWords.get(">="));
} else{
this.setBegin(index1+1);
return new Token(">", this.keyWords.get(">"));
}
case '+':
case '-':
case '*':
case '/':
case '=':
case '#':
case ',':
case ';':
case '(':
case ')':
this.setBegin(index1+1);
return new Token(String.valueOf(code[index1]), this.keyWords.get(String.valueOf(code[index1])));
case '.':
return new Token(".", 0);
default:
return new Token("noneType", -1);
}
}
}
至此,词法分析器已经完成。
完整代码见:LexicalAnalysis.java文件。
LL1文法的判定
需要编写一个程序,判定一个给定的文法是不是LL1文法的,重点在于实现文法的机内表示以及判定算法。
关于文法的机内表示,终结符号集和非终结符号集可以用Set<String>来表示,为什么不使用 Character类呢?,主要考虑到一些符号是形如E'这样的,产生试集合可以使用一种数据结构,映射,一个左部对应一个右部列表,Map<String, String[]>。
首先定义好一些成员变量:
// 存储文法的映射(产生式规则集合)
private Map<String, String[]> P;
// 文法的开始符号
private String start;
// 非终结符号集
private Set<String> nonEndChars;
// 终结符号集
private Set<String> endChars;
// FIRST集合
private Map<String, Set<String>> FIRST;
// FOLLOW集合
private Map<String, Set<String>> FOLLOW;
// SELECT集合
private Map<String, Set<String>> SELECT;
读取文法并且存储入映射:
// 存储文法
private void storeGrammar(String[] Vn, String[] Vt, String[] P, String start){
this.nonEndChars = new HashSet<>();
this.endChars = new HashSet<>();
this.start = start;
this.P = new HashMap<>();
try{
// 存储产生式
for (String value : P) {
// 分割左部、右部
String[] split1 = value.split("->");
// 分割右部的不同产生式
String[] split2 = split1[1].split("\\|");
this.P.put(split1[0], split2);
}
// 存储符号集
Collections.addAll(nonEndChars, Vn);
Collections.addAll(endChars, Vt);
} catch (Exception e){
System.out.println("输入文法有错误!");
e.printStackTrace();
}
}
计算SELECT集合
-
对于产生式
A->a,如果符号串a能推出空串,SELECT(A) = FIRST(a)-空串并上FOLLOW(A)。 -
如果不能推导出,那么
SELECT(A) = FIRST(a)。
// 计算SELECT集
private void calculateSELECT(){
// 为true的话,说明右部可以推导出空串
boolean situation;
SELECT = new HashMap<>();
// 遍历产生式
for (Map.Entry<String, String[]> entry : P.entrySet()){
String leftItem = entry.getKey();
String[] rightItems = entry.getValue();
// 遍历右部
for (String item : rightItems){
situation = false;
// 分解串为符号
List<String> characters = disassemble(item);
Set<String> first = new HashSet<>();
// 计算串的FIRST集
for (int i=0; i<characters.size(); i++){
String character = characters.get(i);
Set<String> currentFIRST = FIRST.get(character);
if (currentFIRST.contains("NULL")){
// 如果最后一个符号也能推导出空串,说明右部可以推导出空串
if (i == characters.size()-1){
situation = true;
first.addAll(FIRST.get(character));
first.remove("NULL");
} else{
first.addAll(FIRST.get(character));
first.remove("NULL");
}
} else{
first.addAll(FIRST.get(character));
break;
}
}
String p = leftItem + " -> " + item;
if (situation){
Set<String> follow = FOLLOW.get(leftItem);
first.addAll(follow);
SELECT.put(p, first);
} else{
SELECT.put(p, first);
}
}
}
}
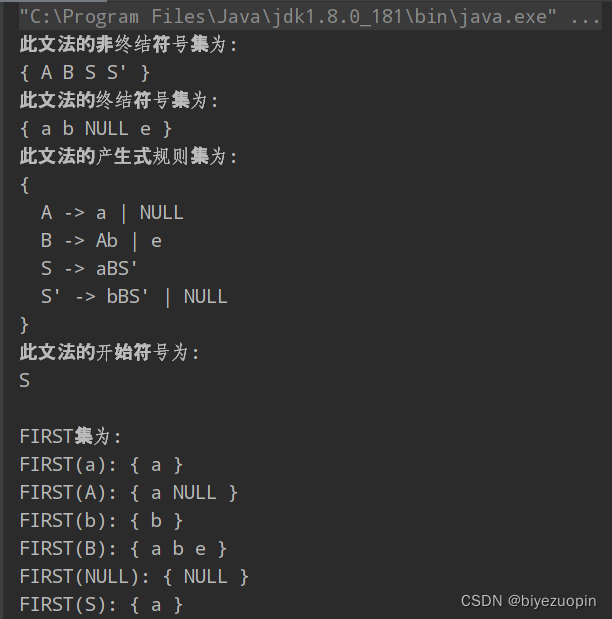

判断是否是LL1文法
只要保证任意两条产生式的可选集不相交就说明是LL1文法。
// 判断是否是LL1文法
public boolean isLL1(){
boolean isIntersect = false;
List<Set<String>> cList = new ArrayList<>(SELECT.values());
outer:for (int i=0; i<cList.size(); i++){
Set<String> set1 = cList.get(i);
for (int j=i+1; j<cList.size(); j++){
Set<String> set2 = cList.get(j);
if (set1.retainAll(set2)){
break outer;
} else{
set1 = cList.get(i);
}
}
}
return isIntersect;
}
资源下载地址:https://download.csdn.net/download/sheziqiong/85824573
资源下载地址:https://download.csdn.net/download/sheziqiong/85824573