shell脚本之正则表达式
一、常见的管道命令
1.1sort命令
- 以
行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
格式:sort [选项] 参数
常用选项:
| 选项 | 说明 |
|---|---|
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
| -n | 按照数字进行排序,默认以文字形式排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行,去重 注意:行尾有空格去重就不成功 |
| -t | 指定字段分隔符,默认使用[Tab]键或空格分隔 |
| -k | 指定排序区域,哪个区间排序 |
| -o | <输出文件> 将排序后的结果转存至指定文件 |
1.1.1 经典案例
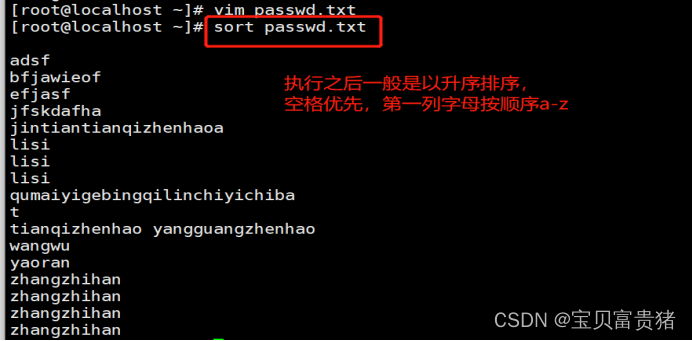
1.sort passwd.txt //不加任何选项默认按第一列升序,字母的话就是从a到z由上
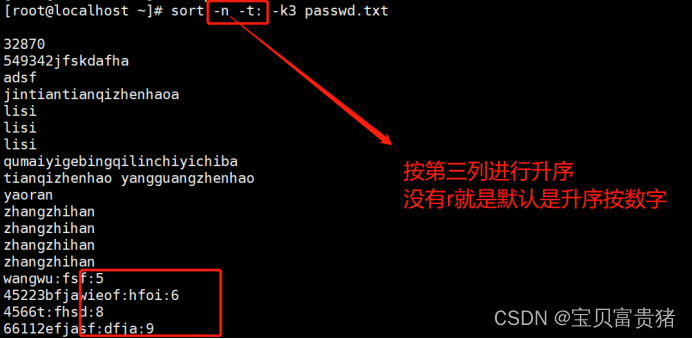
2.sort -n -t: -k3 passwd.txt //以冒号为分隔符,以数字大小对第三列排序(升序)
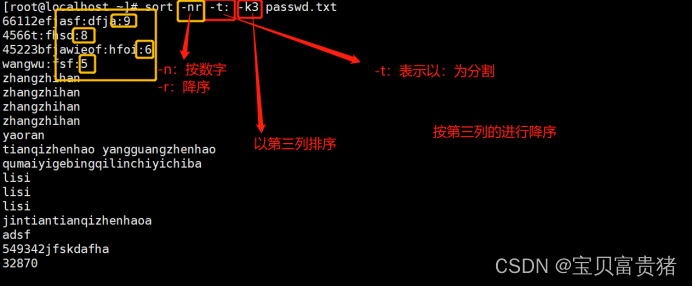
3.sort -nr -t: -k3 passwd.txt //以冒号为分隔符,以数字大小对第三列排序(降序)
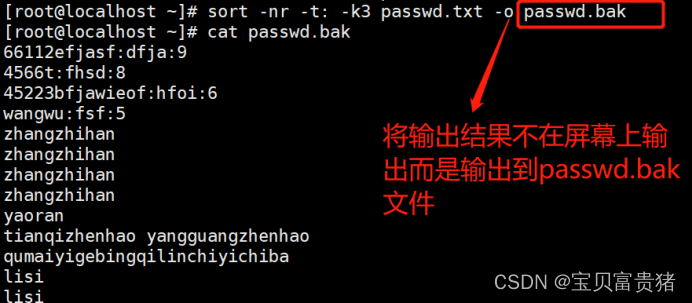
4.sort -nr -t: -k3 passwd.txt -o passwd.bak //将输结果不在屏幕上输出而是输出到passwd.bak文件
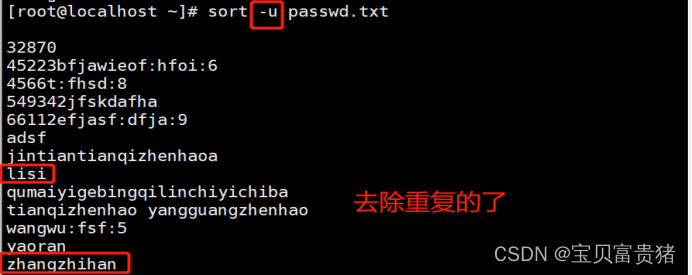
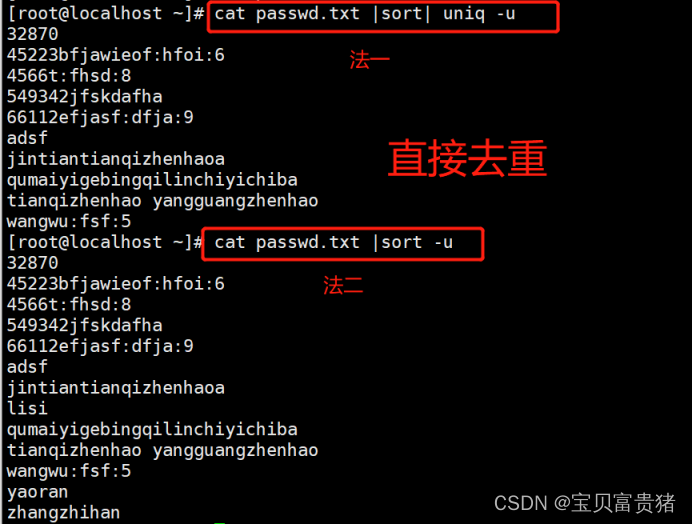
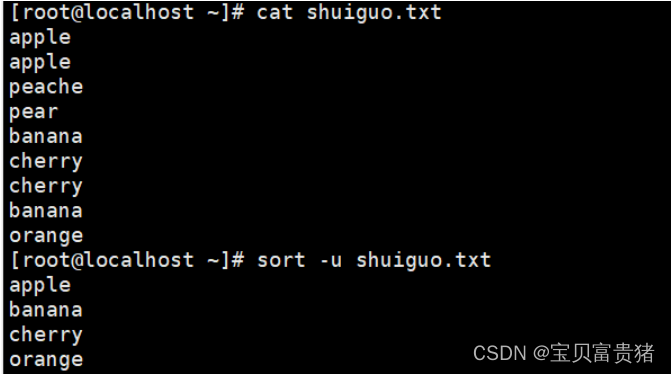
5.sort -u passwd.txt //去掉文件中重复的行(重复的行可以是不连续的)
zhangsan
zhangsan
zhangsan
gggggg
lisi
1.2uniq命令
- 主要用于去除连续的
重复行 - 注意: 是
连续的行,所以通常和sort结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行他不能去重
格式:uniq [选项] 参数
常用选项:
| 选项 | 说明 |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
1.[root@localhost ~]# cat fruit //创建一个水果类型的文件,一共9行内容
apple
apple
peache
pear
banana
cherry
cherry
banana
orange
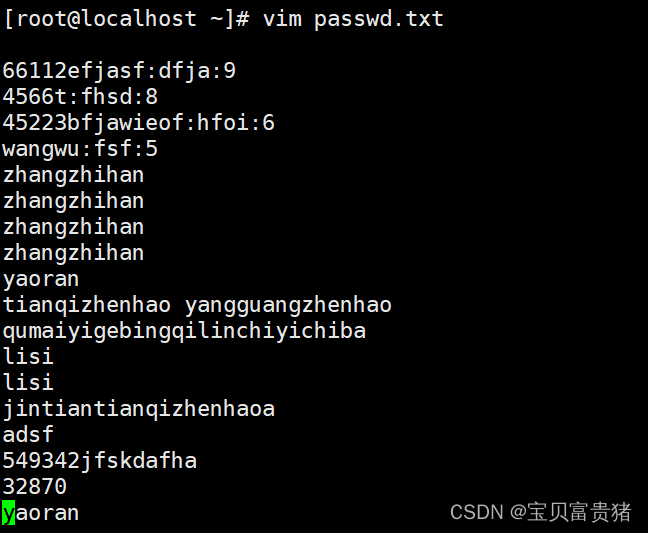
2.[root@localhost ~]# cat fruit | uniq -c //统计重复行的次数,不连续的重复行他不算做重复行
2 apple
1 peache
1 pear
1 banana
2 cherry
1 banana
1 orange
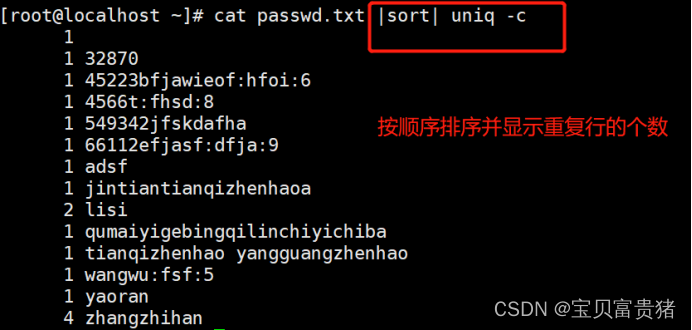
3.[root@localhost ~]# cat fruit | sort | uniq -c //结合sort使用就是我们想要的效果
2 apple
2 banana
2 cherry
1 orange
1 peache
1 pear
4.[root@localhost ~]# cat fruit | sort | uniq -d //结合sort使用,过滤出重复行
apple
banana
cherry
5.[root@localhost ~]# cat fruit | sort | uniq -u //结合sort使用,过滤出不重复的行
orange
peache
pear
6.[root@localhost ~]# cat fruit | sort | uniq //结合sort使用,去重
apple
banana
cherry
orange
peache
pear
7.[root@localhost ~]# cat fruit | sort -u //也可以直接用sort -u
apple
banana
cherry
orange
peache
pear
执行如图所示:
1.2.1 统计重复行的个数【不连续的不计数】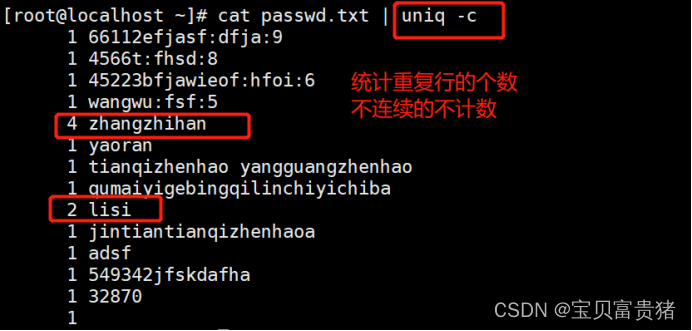
1.2.2按顺序排序并显示重复行的个数
1.2.3 显示重复行

1.2.4 去重
1.3 替换 tr
tr:它可以
用一个字符来替换另一个字符,或者可以完全除去一些字符,也可以用它来除去重复字符
语法
用法:
tr [选项]… SET1 [SET2]从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
常用选项
| -d | 删除字符 |
|---|---|
| -s | 删除所有重复出现的字符,只保留第一个 |
1.3.1经典案例
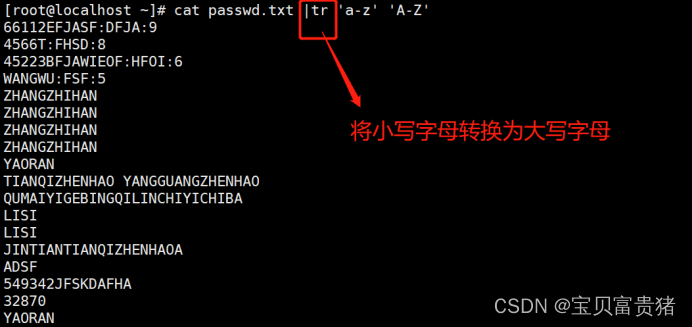
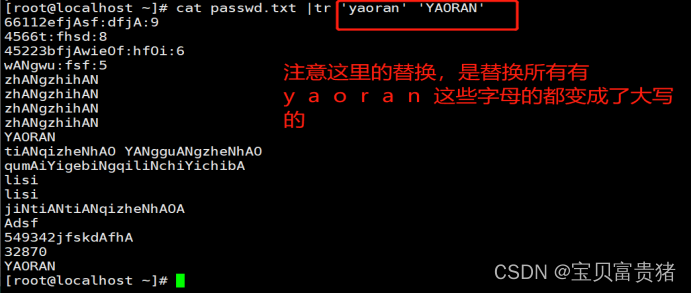
[root@localhost ~]# cat fruit | tr 'a-z' 'A-Z'
APPLE
APPLE
PEACHE
PEAR
BANANA
CHERRY
CHERRY
BANANA
ORANGE
[root@localhost ~]# cat fruit | tr 'apple' 'APPLE' //替换是一一对应的字母的替换
APPLE
APPLE
PEAchE
PEAr
bAnAnA
chErry
chErry
bAnAnA
orAngE
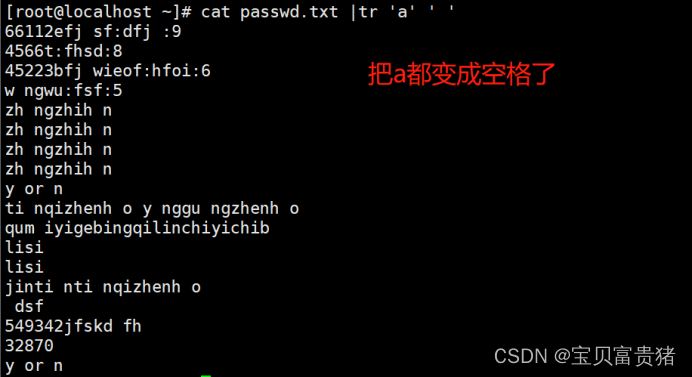
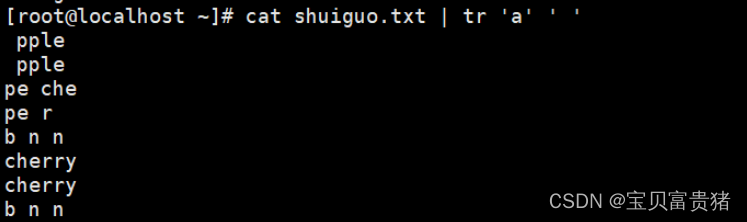
[root@localhost ~]# cat fruit | tr 'a' ' ' //把替换的字符用单引号引起来,包括特殊字符
pple
pple
pe che
pe r
b n n
cherry
cherry
b n n
or nge
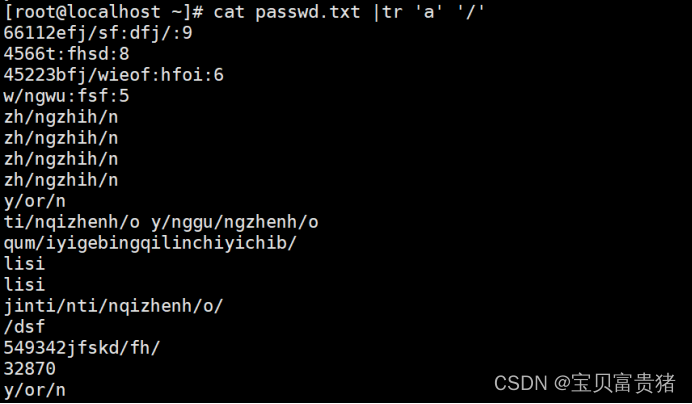
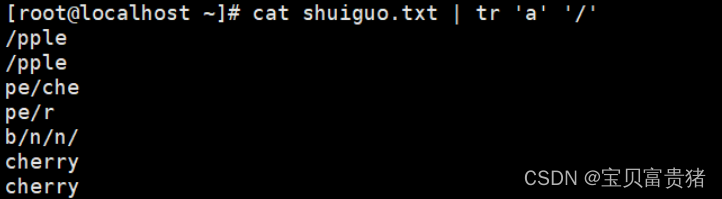
[root@localhost ~]# cat fruit | tr 'a' '/'
/pple
/pple
pe/che
pe/r
b/n/n/
cherry
cherry
b/n/n/
or/nge
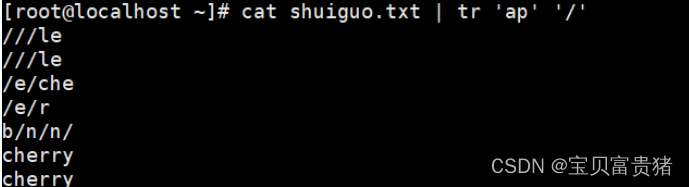
[root@localhost ~]# cat fruit | tr 'ap' '/' //多个字符替换成一个
///le
///le
/e/che
/e/r
b/n/n/
cherry
cherry
b/n/n/
or/nge
[root@localhost ~]# cat fruit | tr 'apple' 'star' //a替换成s,p替换成a,le替换成r
saarr
saarr
arschr
arsr
bsnsns
chrrry
chrrry
bsnsns
'orsngr'
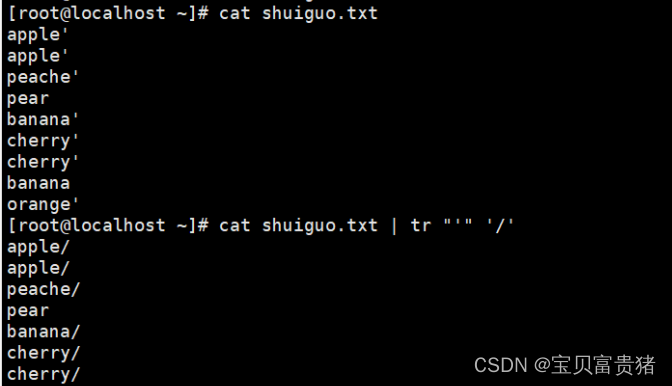
[root@localhost ~]# cat fruit | tr "'" '/' //如果想替换单引号则需要用双引号把单引号引起来,反斜杠转义也不行
apple
apple
peache
pear
banana
cherry
cherry
banana
/orange/
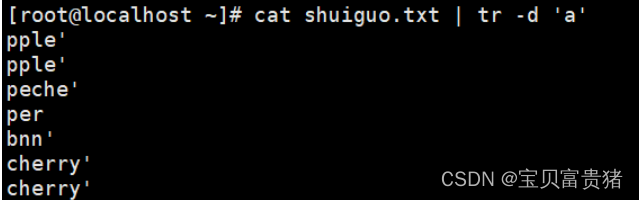
[root@localhost ~]# cat fruit | tr -d 'a' //删除所有a
pple
pple
peche
per
bnn
cherry
cherry
bnn
'ornge'
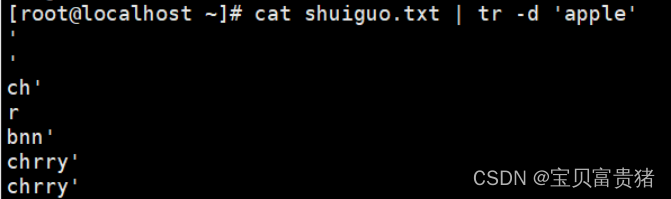
[root@localhost ~]# cat fruit | tr -d 'apple' //把所有含有这5个字母的都删除
ch
r
bnn
chrry
chrry
bnn
'orng'
[root@localhost ~]# cat fruit | tr -d '\n' //删除换行符
appleapplepeachepearbananacherrycherrybanana'orange'[root@localhost ~]#
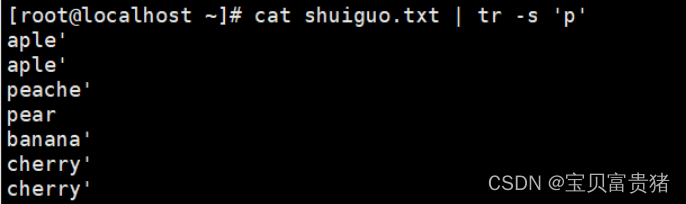
[root@localhost ~]# cat fruit | tr -s 'p' //对p字符去重,只保留第一个
aple
aple
peache
pear
banana
cherry
cherry
banana
'orange'
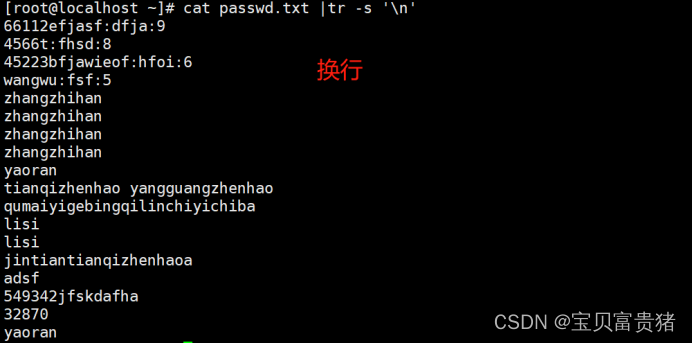
[root@localhost ~]# cat fruit | tr -s '\n' //遇到多个回车只保留一个回车,相当于去除空行
apple
apple
peache
pear
banana
cherry
cherry
banana
'orange'
注:替换是一一对应的字母的替换

1.3.2 扩展命令
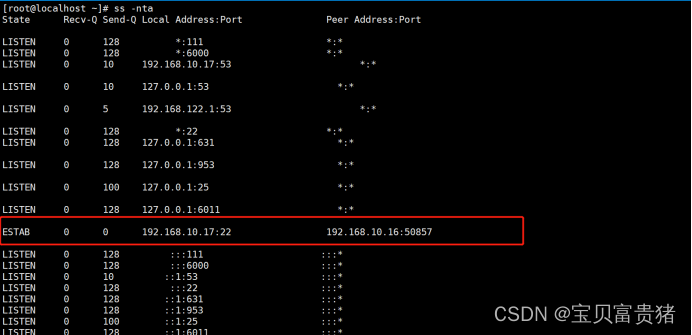
1.统计当前连接主机数
ss -nt |tr -s " "|cut -d " " -f5|cut -d ":" -f1 |sort|uniq -c|
2.统计当前主机的连接状态
ss -nta | grep -v '^State' |cut -d" " -f1|sort |uniq -c


二.正则表达式
2.1概述
通常用于判断语句中,用来检查某一 字符串是否满足某一格式
正则表达式是由普通字符与元字符组成
普通字符: 包括大小写字母、数字、标点符号及一些其他符号
元字符: 是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
Linux 中常用的有两种正则表达式引擎
基础正则表达式:BRE
扩展正则表达式: ERE
2.1 正则表达式定义
- 正则表达式,又称正规表达式、常规表达式
- 使用字符串来描述、匹配一系列符合某个规则的字符串
- 正则表达式组成
- 普通 字符
大小写字母、数字、标点符号以及一些其他符号
- 元字符
- 在正则表达式中`具有特殊意义的专用字符
- 普通 字符
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,正则表达式不只有一种,而且 Linux 中不同的程序可能会使用不同的正则表达式。
2.2 常见元字符(支持的工具:grep、egrep、sed和awk)
基础正则表达式是常用的正则表达式部分
除了普通的字符外,常见到以下元字符
| 元字符 | 作用 | 案例 |
|---|---|---|
| \ | 转义字符,用于取消特殊符号的的含义 |
例:!,\n,$等 |
| ^ | 匹配字符串开始的位置 |
例:a,the,#,[a-z] |
| $ | 匹配字符串结束的位置 |
例:wordKaTeX parse error: Expected group after '^' at position 2: ,^̲匹配空行 |
| . | 匹配除\n之外的任何一个字符 |
例:go.d , g…d |
| * | 匹配前面子表达式0次或者多次 |
例:goo*d,go.*d |
| [list] | 匹配list列表中的一个字符 |
例:go[loa]d,[a-z],[0-9]匹配任意一位数字 |
| [^list] | 匹配任意非list列表中的一个字符 |
例:[0-9],[a-z]匹配任意一位非小写字母 |
| {n} | 匹配前面子表达式n次 |
例:go{2}d,'[0-9]{2}'匹配两位数字 |
| {n,} | 匹配前面子表达式不少于n次 |
例:go{2,}d,'[0-9]{2,}'匹配两位及两位以上的数字 |
| {n,m} | 匹配前面子表达式n到m次 |
例:go{2,3}d,'[0-9]{2,3}'匹配两位到三位数字 |
注:
1.egrep,awk使用{
n}、{
n,}、{
n,m} 匹配时“{
}”前面不用加“\”
2. egrep -E -n 'wo{2}d' test.txt1/-E用于显示文件中符合条件的字符
3.egrep -E -n 'wo{2,3}d' test.txt
2.3扩展正则表达式元字符
支持egrep、awk
| 元字符 | 作用 | 案例 |
|---|---|---|
| + | 匹配前面子表达式一次以上 | 例:go+d,将匹配至少一个o,如god,good,goood等 |
| ? | 匹配前面子表达式0次或一次 | 例:go?d,匹配将为gd或者god |
| () | 将括号内的字符创作为一个整体 | 例:g(oo)+d,将匹配oo整体一次以上 |
| l | 以或的方式匹配字符条串 | 例:g(oo l la)d,将匹配good或glad |
定位符
^ 匹配输入字符串开始的位置
$匹配输入字符串结尾的位置
非打印字符
\n匹配一个换行符
\r匹配一个回车符
\t匹配一个制表符
三. grep命令
grep命令使用正则表达式来搜索文本,并且把匹配的文本打印出来。
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符,fgrep就是fixed grep或fastgrep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
格式:grep [options] pattern [file]
option表示选项,pattern表示匹配的模式。file表示一系列文件名。
常用选项:
-c 只打印匹配的文本行的次数,不显示文本内容。
-i 匹配时忽略字母大小写
-h 当搜索多个文件,不显示匹配文件名前缀。
-l 只列出含义匹配的文本行的文件的文件名,不显示其具体匹配的内容。-L 列出文件内容不符合指定的范本样式的文件名称
-n 列出所有匹配的文本行,并显示行号
-s不显示关于不存在或无法读取文件的错误信息-q 安静模式,不会有任何输出内容,查找到匹配内容会返回0,未查找到匹配内容就返回非0
-v 只显示不匹配的文本行,反向选择,显示与搜索字符串不相符的行。
-w 匹配整个单词
-x 匹配整个文本行
-r 递归搜索,不仅搜索当前目录,还有各级子目录
-E 开启扩展(extend)的正则表达式-V 打印grep的版本号
–color=auto 可以将找到的关键词部分加上颜色的显示-m num 当匹配内容的行数达到num行后,grep停止搜索,并输出停止前搜索到的匹配内容
简述
-a --text #不要忽略二进制的数据。 将 binary 文件以 text 文件的方式搜寻数据
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的行数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或–silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
–color=auto :可以将找到的关键词部分加上颜色的显示
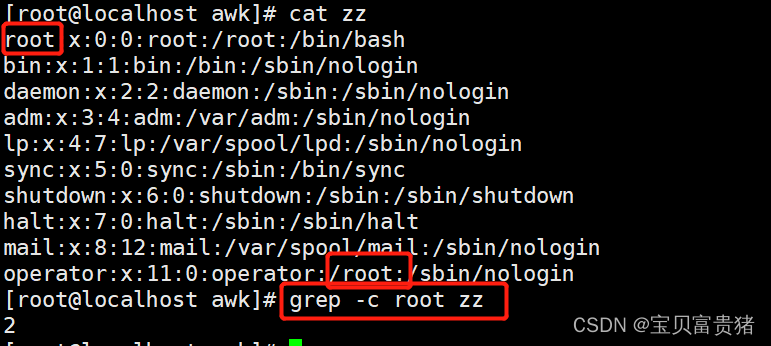
经典案例:
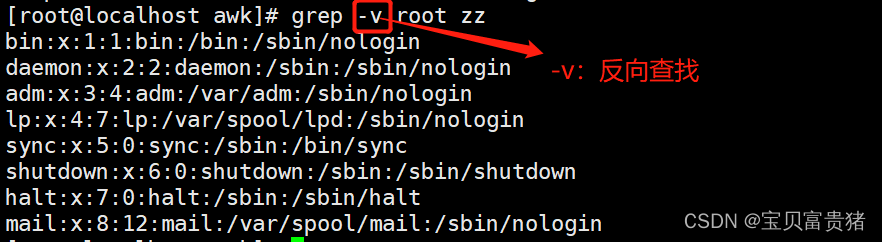
3.1 统计root字符总行数
或者

3.2不区分大小写查找the所有的行

3.3 查看/etc/passwd,将没有出现root’的行取出来
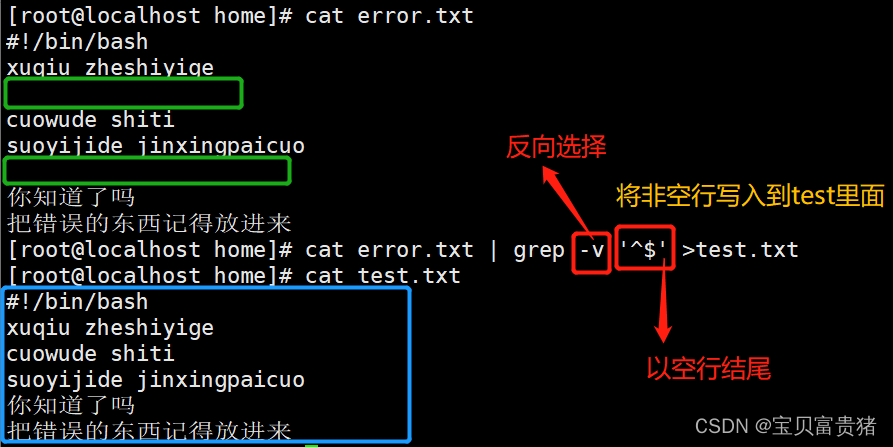
3.4 将非空行写入到test.txt文件
四. 元字符操作案例
4.1 查找特定字符
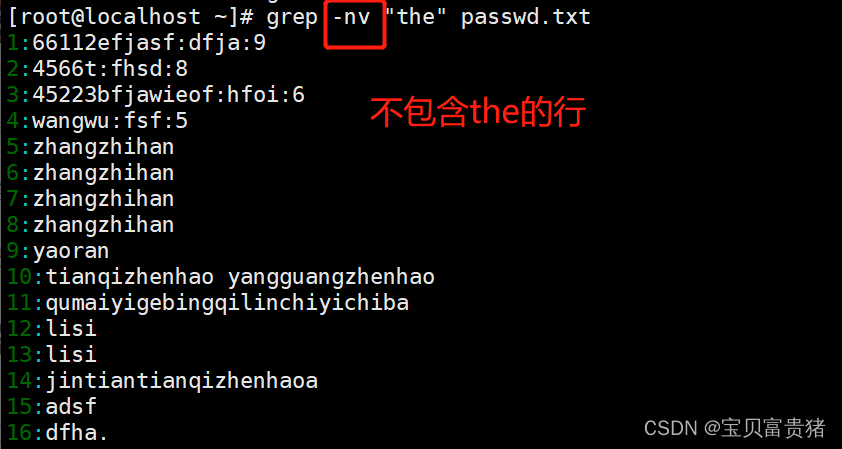
a. 查找特定字符非常简单,如执行以下命令即可从 test.txt 文件中查找出特定字符“the”所在位置。其中“-n”表示显示行号、“-i”表示不区分大小写。命令执行后,符合匹配标准的字符, 字体颜色会变为红色。

b. 若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-v”选项实现,并配合“-n”一起使用显示行号。
4.2 利用中括号“[]”来查找集合字符
a. 想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh”与“rt”。此时执行以下命令即可同时查找到“shirt”与“short”这两个字符串,其中“[]”中无论有几个字符, 都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”。

b. 若要查找包含重复单个字符“oo”时,只需要执行以下命令即可

c. 若查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]”来实现该目的。例如执行“grep -n‘[^w]oo’test.txt”命令表示在 test.txt 文本中查找“oo”前面不是“w”的字符串。
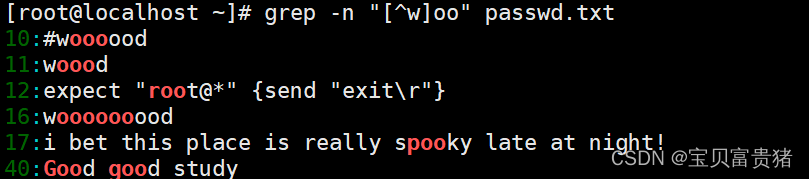
在上述命令的执行结果中发现“woood”与“wooooood”也符合匹配规则,二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知, “#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood #”也符合匹配规则。
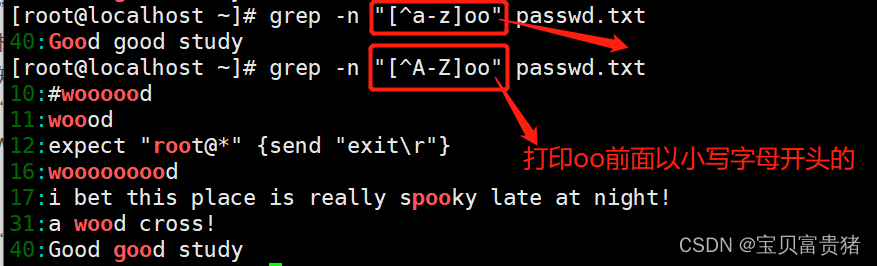
d. 若不希望“oo”前面存在小写字母,可以使用“grep -n‘[^a-z]oo’test.txt”命令实现,其中“a-z”表示小写字母,大写字母则通过“A-Z”表示。

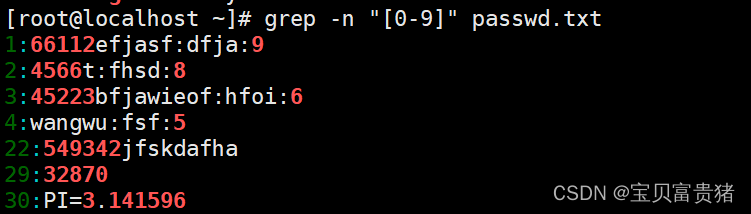
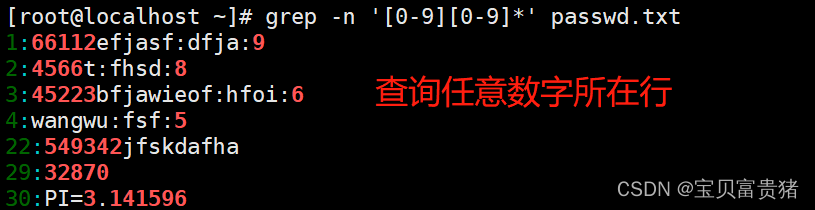
e. 查找包含数字的行可以通过“grep -n ‘[0-9]’ test.txt”命令来实现
4.3 查找行首“^” 与行尾字符“$”
a. 基础正则表达式包含**两个定位元字符:“^”(行首)与“$”(行尾)。在上面的示例中, 查询“the”字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为行首的行,则可以通过“^”元字符来实现。

b. 查询以小写字母开头的行可以通过“1”规则来过滤,查询大写字母开头的行则使用
“[A-Z]”规则,若查询不以字母开头的行则使用“[^a-zA-Z]”规则。
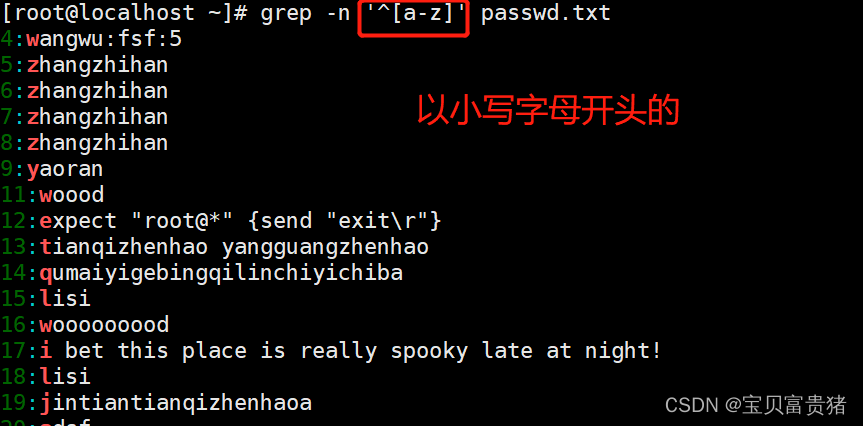


“^”符号在元字符集合“[]”符号内外的作用是不一样的,在“[]”符号
内表示反向选择,在“[]”符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。
c. 执行以下命令即可实现**查询以小数点(.)结尾的行**。因为小数点(.)在正则表达式中也是一个元字符,所以在这里需要用转义字符“\”将具有特殊意义的字符转化成普通字符。
d. 当查询空白行时,执行“grep -n‘^$’ passwd.txt”命令即可

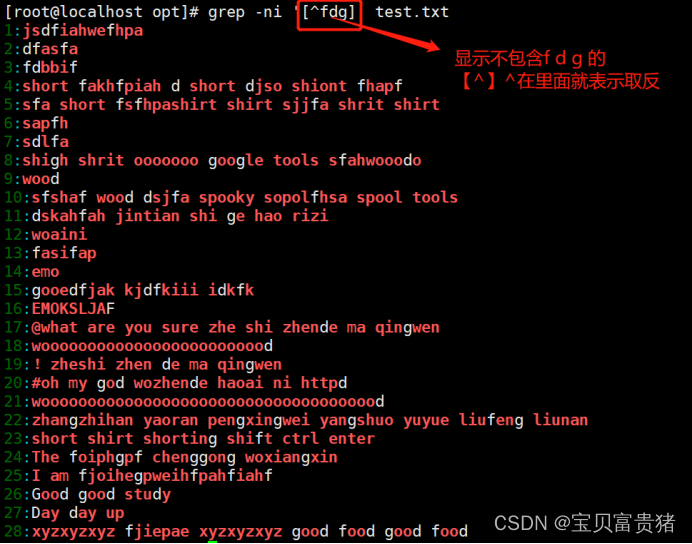
4.4 查找任意一个字符“.”与重复字符“*”
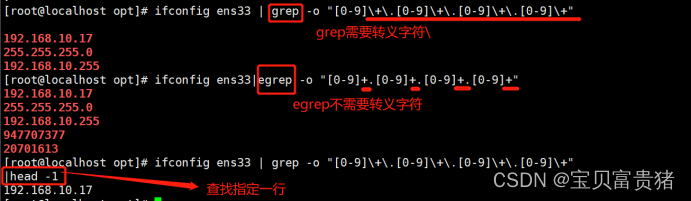
a. 前面提到,在正则表达式中小数点(.)也是一个元字符,代表任意一个字符。例如执行以下命令就可以查找“w??d”的字符串,即共有四个字符,以 w 开头 d 结尾。

b. 在上述结果中,“wood”字符串“w…d”匹配规则。若想要查询 oo、ooo、ooooo 等资料, 则需要使用星号(*)元字符。但需要注意的是,**“”代表的是重复零个或多个前面的单字符。
“o”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符,所以执行“grep -n ‘o*’ passwd.txt”命令会将文本中所有的内容都输出打印。如果是“oo*”,则第一个 o 必须存在, 第二个 o 则是零个或多个 o,所以凡是包含 o、oo、ooo、ooo,等的资料都符合标准。同理,若查询包含至少两个 o 以上的字符串,则执行“grep -n ‘ooo*’ passwd.txt”命令即可。
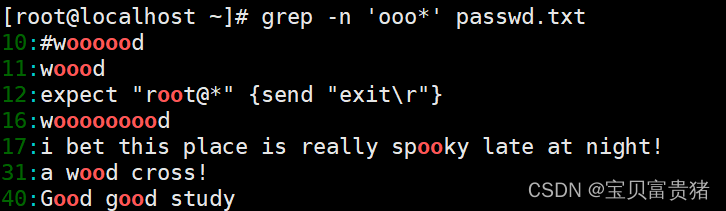
c. 查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串,执行以下命令即可实现。
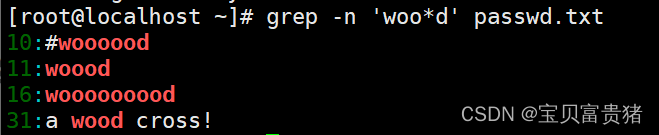
d. 执行以下命令即可查询以 w 开头 d 结尾,中间的字符可有可无的字符串。

e. 执行以下命令即可查询任意数字所在行
4.5 查找连续字符范围“{}”
在上面的示例中,使用了“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?
a. 例如,查找三到五个 o 的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。因为“{}”在 Shell 中具有特殊意义,所以在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。“{}”字符的使用方法如下所示。
4.5.1查询两个 o 的字符
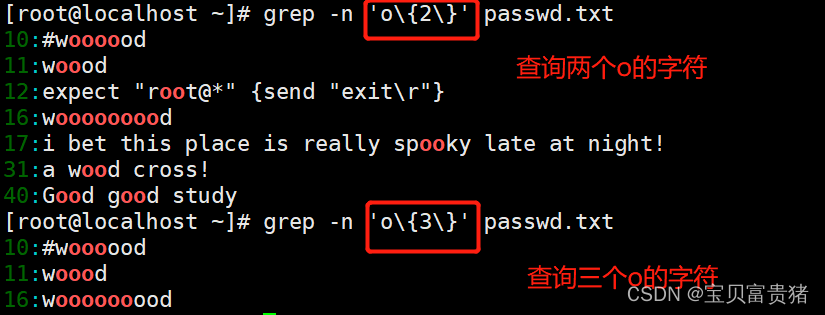
4.5.2 查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串
[root@localhost ~]# grep -n 'wo\{2,5\}d' passwd.txt
10:#woooood
11:woood
31:a wood cross!

4.5.3 查询以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o 的字符串

五. cut 、sort、uniq、tr
5.1 cut :列截取工具
使用说明:cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一
| 选项 | 功能 |
|---|---|
| -b | 按字节截取 |
| -c | 按字符截取,常用于中文 |
| -d | 指定以什么为分隔符截取,默认为制表符 |
| -f | 通常和-d一起 |
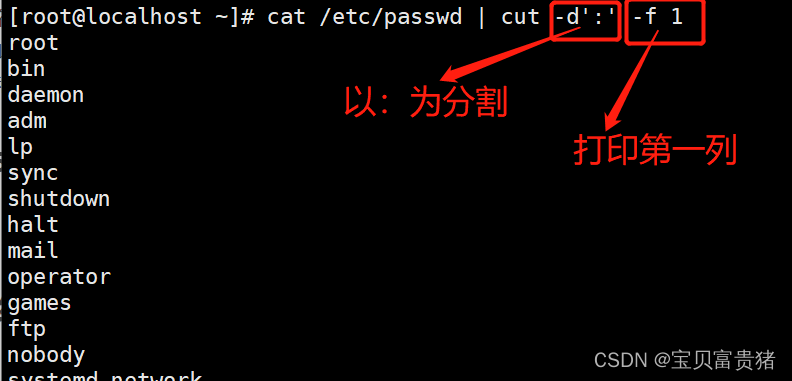
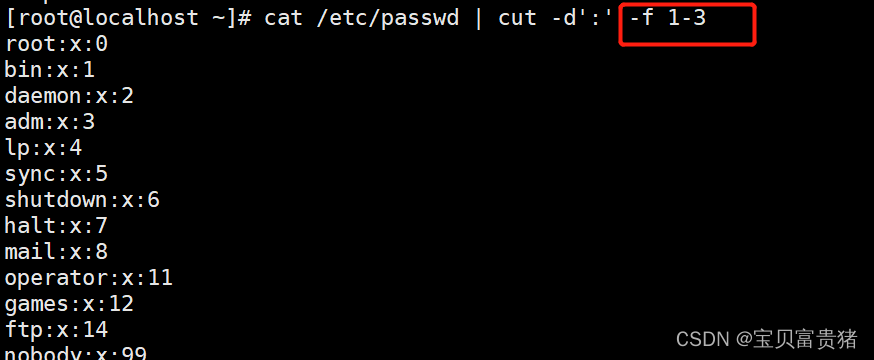
5.1.1 分割打印passwd的第一列
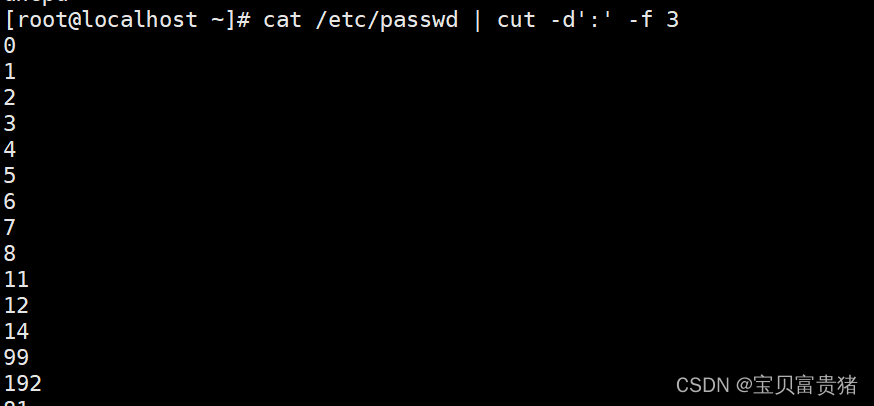
5.1.2 分割打印passwd第三列
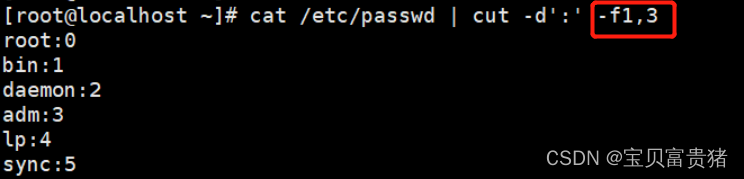
5.1.3 分割打印passwd的第一列和第三列【,表示和】
5.1.4 以:分割打印passwd第一列到第三列【-表示范围】
5.1.5查看当前登录用户的第三个字节

5.1.6查看文件中的字符位置
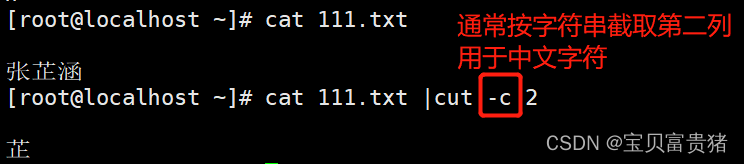
注意:
cut只擅长于处理单个字符为间隔的文本,-b只能分割字母,-c既可以分割字母也可以分割中文
5.2 sort:排序工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。例如数据和字符的排序就不一样
sort [选项] 参数
常用选项
-t:指定分隔符,默认使用[Tab]吧 键或空格分隔
-k:指定排序区域,哪个区间排序
-n:按照数字进行排序,默认是以文字形式排序
-u:等同于 uniq,表示相同的数据仅显示一行,注意:如果行尾有空格去重就不成功
-r:反向排序,默认是升序,-r就是降序
-o:将排序后的结果转存至指定文件
-f: 忽略大小写,会将小写的字母都转换为大写字母来进行比较
-b: 忽略每行前面的空格
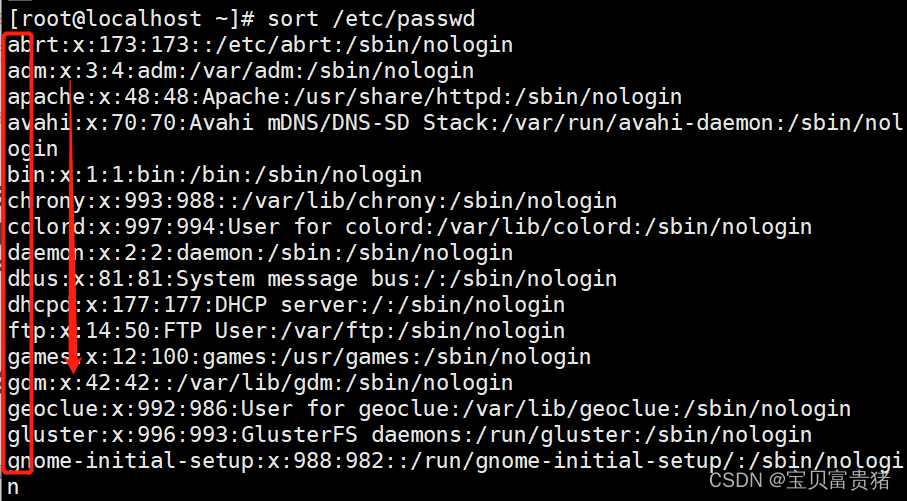
5.2.1 不加任何选项默认按第一列升序,字母的话就是从a到z由上而下显示
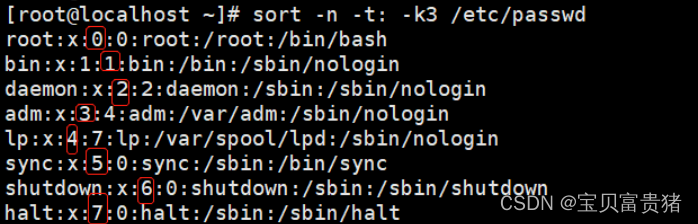
5.2.2 以冒号为分隔符,以数字大小对第三列排序(升序)
5.2.3 以冒号为分隔符,以数字大小对第三列排序(降序)
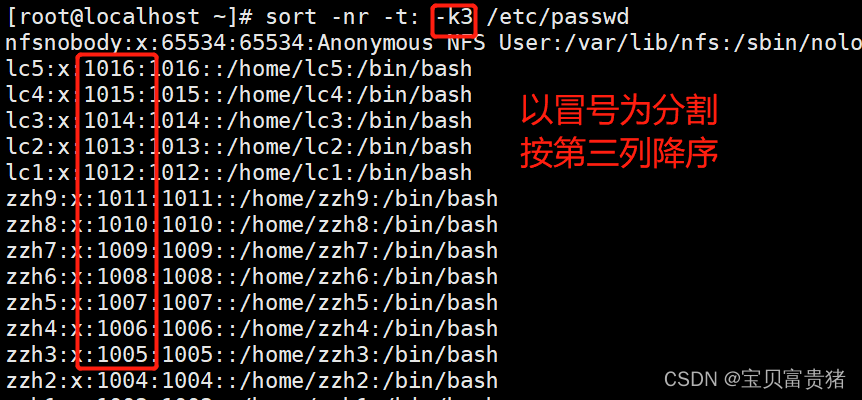
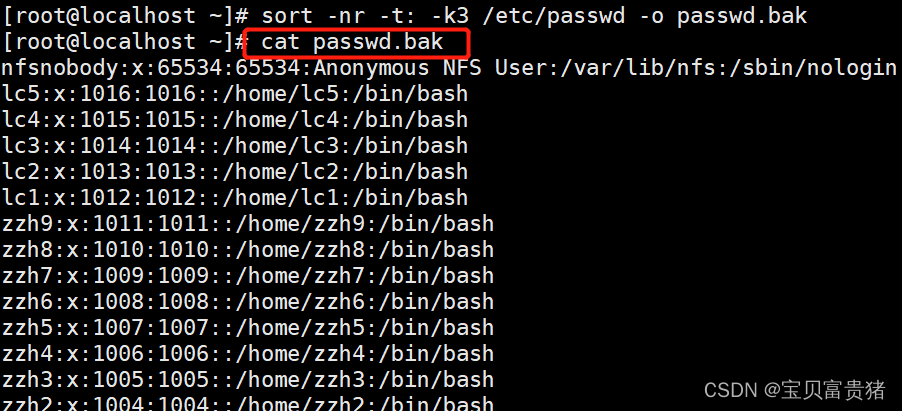
5.2.4将输结果不在屏幕上输出而是输出到passwd.bak文件
5.2.5去掉文件中重复的行(重复的行可以是不连续的)
5.3 uniq:去重工具
主要用于去除连续的重复行
注意:是连续的行,所以通常和sort结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行他不能去重
格式: uniq [选项] 参数
| 选项 | 功能 |
|---|---|
| -c | 对重复的行进行计数; |
| -d | 仅显示重复行; |
| -u | 仅显示出现一次的行 |
5.3.1统计重复行的次数,不连续的重复行他不算做重复行
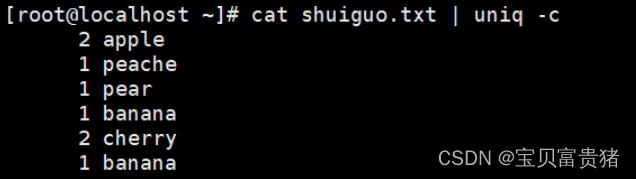
结合sort使用就是我们想要的效果
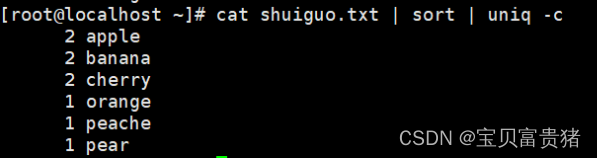
5.3.2 结合sort使用,过滤出重复行

5.3.3 结合sort使用,过滤出不重复的行

5.3.4 结合sort使用,去重
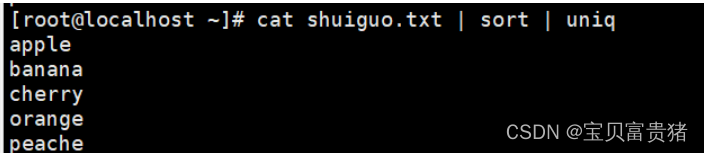
或sort -u(上方有案例)
5.3.5 3.5sort和uniq使用实例
①查看登陆用户
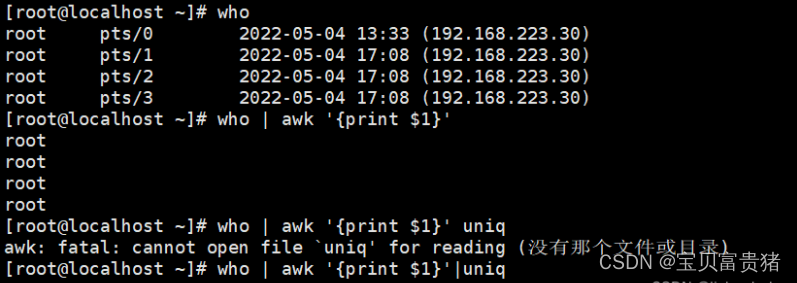
②查看登陆过系统的用户

③查看登陆ip和使用者个数

④查看客户端和监听服务端个数

六 、tr:修改工具
它可以用一个字符来替换另一个字符,或者可以完全除去一些字符,也可以用它来除去重复字符
用法:tr [选项]… SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
常用选项
-d 删除字符
-s 删除所有重复出现的字符,只保留第一个
6.1 将所有小写改成大写
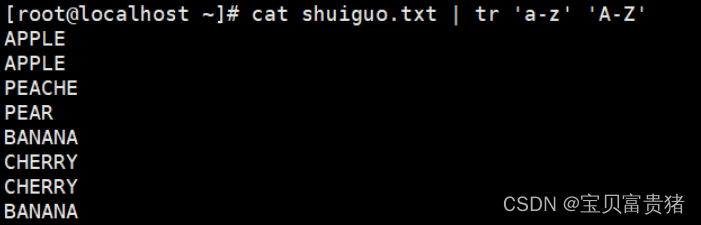
6.2替换是一一对应的字母的替换

当字符数量不对等时,相同字符只识别后一个,剩下未对应的全是最后替换字符
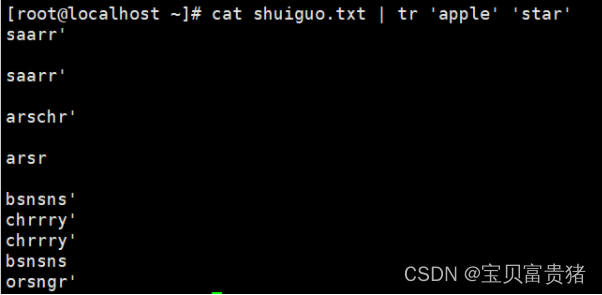
即a-s p-a(pp相同去后一个a) le-r
6.3 把替换的字符用单引号引起来,包括特殊字符
6.4 多个字符替换成一个
6.5 如果想替换单引号则需要用双引号把单引号引起来,反斜杠转义也不行
6.6 删除所有a
6.7 把所有含有这5个字母的都删除
6.8删除换行符

6.9对p字符去重,只保留第一个
6.10遇到多个回车只保留一个回车,相当于去除空行
总结
- 正则表达式
- 基础正则表达式
- 扩展正则表达式
- 文本处理器
- sed
awk- grep
- egrep
- sort
- uniq
- tr
a-z ↩︎