OLAP(Online Analytical Processing)是指在线联机分析,基于数据查询计算并实时获得返回结果。日常业务中的报表、数据查询、多维分析等一切需要即时返回结果的数据查询任务都属于OLAP的范畴。对应的,行业内也有相应产品来满足这类需求,那就是OLAP Server。
OLAP Server现状
当前主流OLAP Server几乎都是基于RDB或封装成RDB的大数据平台,有点类似早期的ROLAP(这个词已经很少被提及了),其中一个关键的特征是使用SQL作为查询语言。
RDB和SQL的特性会给OLAP Server带来诸多困难。
复杂报表困难
事实上,报表才是OLAP业务的重头戏,OLAP的查询需求中有相当大一部分都是事先做好的报表查询界面,而不是自由拖拽的多维分析,而复杂报表又经常占据报表需求的一半以上。这类报表的典型特点是数据处理逻辑复杂,每个报表都需要单独编写代码进行数据准备,最常见的做法是使用复杂SQL或存储过程,如果碰到一些数据库无法实现的场景(如文件等外部数据源、跨数据源计算、前后端分离等)还需要通过JAVA完成,过程十分繁琐。
SQL实现这些计算很难,存储过程也有很多缺点(无移植性、有安全隐患等)导致越来越少使用,Java集合运算困难且无法热切换而难以适应复杂多变的报表需求。当前OLAP Server在复杂报表这方面就表现的很不理想了。
自助关联差
即使不管复杂报表,只考虑多维分析的这种基础的OLAP任务,使用SQL作为查询语言时也很难胜任,只能解决一小部分无关联的单表分析,满足一些相对固定的多维分析需求,适用范围很小,难以适应灵活的自助分析场景。
体系封闭
当前OLAP Server严重依赖数据库,数据库有“库”的概念,数据只有“入库”才能处理,而且通常只能同时处理一个数据库,无法同时计算数据库外部的数据。而OLAP名为在线分析,业务上还要求做T+0式的实时查询分析。其他数据源的数据需要先ETL到数据库中才能计算,这就造成了不实时。典型的场景是OLAP业务经常要查询业务库的实时数据,要将实时数据(业务库)和历史数据(分析库)混合查询分析(T+0查询),这是当前OLAP Server难以满足的。何况还有很多非关系数据库的数据也无法被OLAP Server直接计算。
性能低
退一步来讲,即使只关注历史数据,不考虑实时生产数据,也只使用单一的数据库,当前OLAP查询也面临性能低的问题,我们经常会遇到查询报表要等几分钟、实时查询不实时、多维分析卡顿的情况。根本原因仍然是SQL的问题,基于关系代数理论的SQL难以实现高性能算法,仅靠数据库在工程上优化并不能根本解决问题,SQL复杂时数据库优化经常无效而导致性能仍然很低。
开源SPL重新定义OLAP Server
SPL技术问世之后,将使OLAP Server的上述窘境大为改观。
SPL是结构化数据计算专用程序语言(Structured Process Language)的简称。SPL提供丰富的计算类库和敏捷的开发语法可以快速完成各类复杂数据处理;SPL的计算能力不依赖于数据库(数据源),天然支持多样性数据源,可以完成跨数据源混合计算,实现跨异构源的实时查询;SPL内置了大量高性能算法和存储方案以及并行计算机制保证计算的高性能。
敏捷的过程计算适应复杂报表
在复杂数据处理方面,SPL提供独立的敏捷语法支持过程计算,相对于SQL,SPL的语法更简洁,适合完成复杂报表数据准备。
比如要计算:一只股票最长连续上涨了多少天?
用SQL借助窗口函数还要写成四层嵌套的语句:
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
而同样的逻辑用SPL写要简单得多:
| A | |
| 1 | =T(“/dw/stockRecord.txt”) |
| 2 | =A1.group@i(closePrice< closePrice[-1]).max(~.len()) |
SPL提倡分步运算,复杂计算可以按照自然思维一步一步实现。
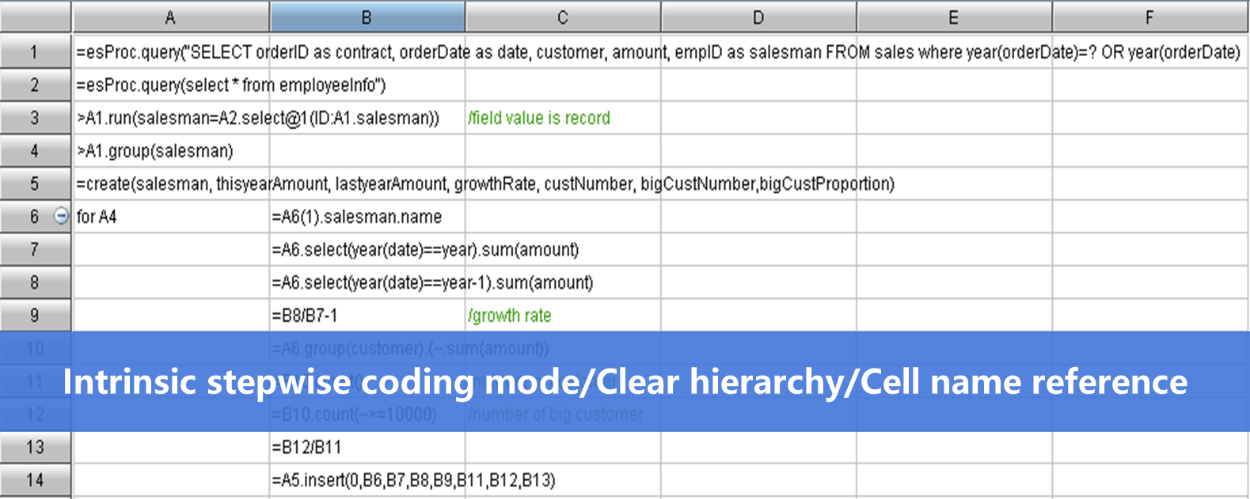
再借助SPL丰富的计算类库可以大幅简化数据处理难度。
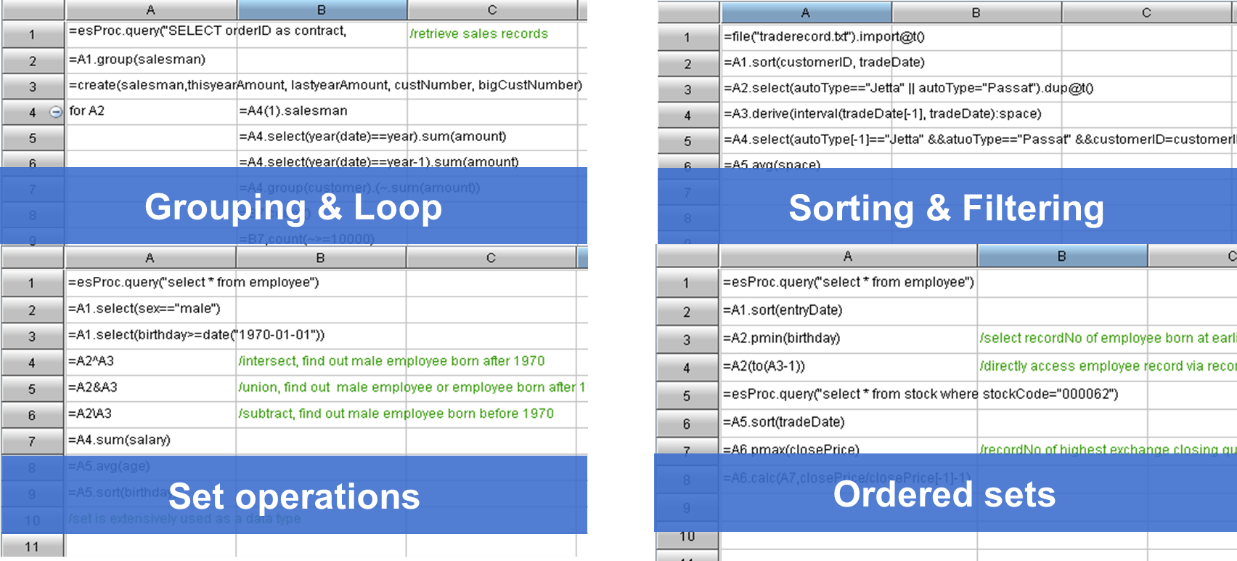
针对SQL的调试困难,SPL还提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…
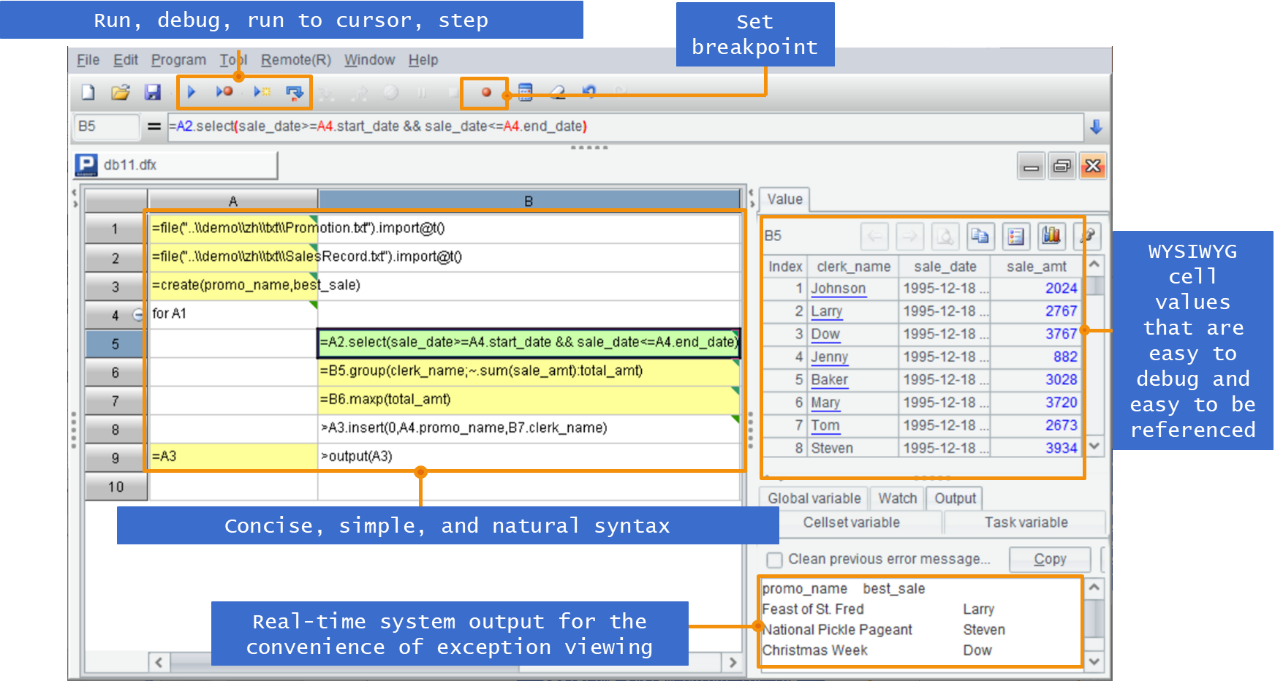
业务开展过程中报表会不断新增、修改。使用报表工具可以解决报表呈现模板的快速制作,但却无法应对复杂多变的报表数据准备,以往无论使用SQL/存储过程还是Java都难以很好应对。
使用SPL完成报表数据准备,可以实现报表数据准备工具化,加之原有呈现端的报表工具,使报表开发全面工具化,从而低成本、快速地应对没完没了的报表。
SPL是解释执行的程序语言,天然支持热切换。报表(数据准备)修改无需重启服务即可生效,以适应不断修改的报表需求。
不仅如此,借助SPL敏捷和易切换特性,还可以很好与微服务等开发框架融合。SPL提供不依赖数据库的计算能力,算法外置完成微服务数据处理,相对Java硬编码也更有优势,能有效降低应用各个模块间的耦合性。
体系开放
相对传统OLAP Server的封闭性,基于SPL实现的OLAP Sever体系则更加开放。SPL的计算不依赖于数据库,也不再有“库”的限制,甚至没有“库“的概念。无论什么数据源都可以直接使用,CSV、Excel、JSON/XML、NoSQL、RestAPI、HDFS、Kafka、Elasticsearch、SAP均能支持,还可以进行混合计算。数据源可以来自本地应用系统,也可以是外部系统或者远程云应用。
这种开放的计算体系能很方便完成T+0实时数据查询,同时连接存储热数据的业务库和存储冷数据的分析库(或文件)进行混合计算即可实现T+0。
高性能
SPL没有基于关系代数理论,而是创新地发明了离散数据集代数。这样,很多SQL很难实现的高性能算法及存储方案用SPL却可以轻松实现,而软件提高性能关键就在于算法和存储。
例如,SPL支持更彻底的集合化,可以把TopN理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。
| A | ||
| 1 | =file(“data.ctx”).create().cursor() |
|
| 2 | =A1.groups(;top(10,amount)) |
金额在前10名的订单 |
| 3 | =A1.groups(area;top(10,amount)) |
每个地区金额在前10名的订单 |
SQL描述上面的运算会涉及大排序,性能非常低下,只能寄希望于数据库的优化。但在稍复杂的情况(比如A3中伴随分组运算)数据库优化器就会失效。
再比如,SPL的游标支持复用,可以在一次遍历中聚合出多个结果。
| A | ||
| 1 | =file(“order.ctx”).create().cursor() | 准备遍历 |
| 2 | =channel(A1).groups(product;count(1):N) | 配置复用计算 |
| 3 | =A1.groups(area;sum(amount):amount) | 遍历,并获得分组结果 |
| 4 | =A2.result() | 取出复用运算的结果 |
而SQL无法描述这种算法,实现上述运算就会不可避免地将大数据遍历多次,造成性能低下。而且这个问题还是理论层面的,数据库优化引擎无能为力。
SPL提供的其它与OLAP业务相关性能优化技术还有:有序归并实现订单和明细之间的关联、预关联技术实现多维分析中的多层维表关联、位存储技术实现上千个标签统计、布尔集合技术实现多个枚举值过滤条件的查询提速、时序分组技术实现复杂的漏斗分析,倍增分段存储技术实现列存的平滑并行、…。其中有相当一部分是SPL发明的算法。
用TPCH国际标准实测,SPL能在低性能ARM芯片上跑出比高性能Intel芯片上Oracle快出数倍的成绩,这就是创新算法带来的优势。。
在SPL的高性能算法和存储方案的支持下,历史大数据的计算会获得更高的性能,配合实时业务热数据进行混合查询还可以进一步提升T+0查询效率。
关联查询
针对传统OLAP Server多维分析时关联能力差的问题,基于SPL还发展了一种关联查询分析语法DQL。DQL(Dimensional Query Language)是以维度为核心的类SQL查询语言在解决表间关联问题时采用了与SQL不同的思路。
当前基于SQL的OLAP Server在实现多表关联时并没有特别好的办法,要么采用逻辑宽表,但由于会产生过多字段(维表字段会被复制多次,多层关联、自关联、循环关联都会加剧这种情况)导致用户无法使用,而且性能也很差。有些BI产品可以根据用户选择的字段在页面上自动关联,但只适用简单的的情况,当遇到同维字段(如同一个表有2个以上地区字段)时就无法匹配了,自关联的情况也没法处理。将表和字段都开放给用户让用户自己关联显然更不现实。
那么DQL是如何处理的呢?比如这样一句SQL:
--SQL
SELECT A.* FROM EMPLOYEE A, DEPARTMENT B, EMPLOYEE C
WHERE A.country='USA'
AND C. country ='China'
AND A. dept_id =B. dept_id
AND B. manager=C. emp_id
其中涉及多表和自关联,很难让业务用户在BI界面中正确地描述出其中的关联关系。
而同样的查询用DQL写出来是这样:
--DQL
SELECT * FROM EMPLOYEE
WHERE country ='USA' AND dept_id.manager.country ='China’
将复杂的多表关联转换成了简单的单表查询,普通业务用户都能理解并在界面中自行实施。
总结
SPL及DQL的问世,将对OLAP Server产生深刻的影响。
基于SPL的敏捷性(过程计算、算法外置、解释执行)可以很好适应OLAP业务中复杂报表的需要,快速开发、热切换、低耦合可以很好与微服务融合;开放的计算体系以及无约束数据组织形式打破了传统OLAP产品的封闭性,可以直接使用各类数据源,轻松实现T+0查询;通过基于SPL的DQL则可以解决多维分析时的实时关联查询的难题;SPL的高性能算法和存储技术则保证了OLAP运算性能,高效完成报表查询、T+0查询、多维分析等查询分析任务。
我们期待基于SPL技术的新一代OLAP Server以及BI 产品的出现。
SPL资料

欢迎对SPL有兴趣的加小助手(VX号:SPL-helper),进SPL技术交流群