一些许写在前面的无厘头
刚入CS看无线传感的实验确实一头雾水(其实是没时间看这些边缘知识emmmm),但期末老师很有想法的给我们来了一次英文文献训练做大作业,有点不是那么废柴了哈哈哈。
虽然也是很拉,拖到上台前一天晚上通宵啃下论文直接上(别骂了真的打题完了就没啥时间了)。好歹也是弄懂了大部分(纯理工生英语差的一匹后面皆机翻),文献报告难得还是在你能力范围绝对好好搞,最后谢老师给我这种弱鸡A,真的救了大命!!!
目录
错误接受率(FAR-False Acceptance Rate)
摘 要
本文基于当前传统的2D人脸识别技术无法满足欺骗攻击、人脸识别机制所受关注度提高、智能手机行业屏幕最大化的市场趋势的背景,提出了一种新的活体检测系统FaceRevelio,该系统适用于于带有单前置摄像头的普通智能手机,同时满足了智能手机行业屏幕最大化的市场趋势。
本文主要研究了活体检测系统FaceRevelio的具体实现。该系统利用了由随机光模式组合而成的光密码技术、光度立体技术、孪生神经网络深度学习系统技术。
该系统创新性地仅借用智能手机单前置摄像头实现了高效活体检测。通过利用屏幕不同方向的光照亮脸部,采集不同光照下人脸图像,利用光度立体技术,恢复人脸表面法线,再将其恢复为3D模型。通过该3D模型的面部深度特征进行识别。同时为了防范重放攻击,该作者团队研究并提出了由随机光模式组合而成的光密码概念。
其性能结果评估良好,在30名用户不同光照条件下进行2D欺骗攻击且密码为1时,该系统对图片攻击和视频攻击平均EER分别为1.4%和0.15%。
研究背景及意义
研究背景与动机
研究背景
随着科技发展,在日常生活中可靠的用于认证来保证私人信息和移动支付愈发重要。当前传统的2D人脸识别技术无法满足利用2D照片/视频或3D面具欺骗攻击。该技术利用计算机视觉技术[1][2][3],需要理想光照条件,实际中很难保证。或利用响应协议,也由于其耗时和用户合作要求使其受限,甚至可以用基于媒体的面部伪造来模拟动作表情[4]。
部分手机厂家通过在屏幕嵌入专门硬件部件来实现3D人脸活体检测,如华为Mate 20Pro,或iPhone X/XR/XS的TrueDepth系统[5]采用的红外点投影仪。它是通过在前置摄像头旁额外加入专用的红外摄像头实现该识别功能。
但基于智能手机行业屏幕最大化的市场趋势,该设计明显不够最优。基于此,三星推出了S10。但它缺乏专门硬件,使得其无法满足利用2D照片/视频或3D面具欺骗攻击[6]。
基于以上背景,本文提出以下研究目的和动机:实现仅借用智能手机单前置摄像头进行高效的活体检测。
研究意义
创新性
该文开创性地提出基于随机光模型的光密码概念。系统巧妙借用屏幕分区照亮的方法实现不同方向的光照,灵活通过借用屏幕光和摄像头的简单现有构件及光度立体[7]的方法实现三维面部模型构建,并大胆使用孪生神经深度学习系统实现精准识别。
实用性
该系统不需要额外的昂贵硬件,仅依靠带有单前置摄像头的普通智能手机即可实现,其推广的普遍性和便利性显而易见,可解决当今实际市场的尴尬处境,具有较强的推广性。且在光模式频率设计上考虑了用户体验,后期也提出背景图案的加入以增强用户体验,这些举措也进一步增强该系统的用户友好型体验效果。
前瞻性
该系统及时地为当今及未来市场急需的高效便捷活体人脸识别问题提出一种可行的解决方案。由于其无需多于硬件、使用大部分普通智能手机、用户友好型等显著、性能良好特性,可预期其在市场的推广面应当很广。
核心思想
该系统创新性地仅借用智能手机单前置摄像头实现了高效活体检测。通过利用屏幕不同方向的光照亮脸部,用前置摄像头采集不同光照下人脸图像,利用光度立体技术,通过固定相机曝光参数、反转伽玛校正来线性化相机响应[8]、最小二乘法、使用通用面部法线模板、地标感知网格法从录像中恢复4张人脸立体图像,进一步恢复人脸表面法线图。最后利用二次法向积分法将其恢复为3D模型[9]。通过该3D模型的面部深度特征进行识别。
同时为了防范重放攻击,该团队研究并提出了由随机光模式组合而成的光密码概念。该光密码运用正交和“零均值”的方法消除环境光影响。
本文贡献
- 通过重建人脸的3D表面,不需要任何额外的硬件或人工配合,设计了一个只有一个前置摄像头的商用智能手机活体检测系统。
- 引入了光密码的概念,它结合了随机产生的照明模式。光密码可以从立体图像中重建三维结构,更重要的是,可以防御重放攻击。
- 在智能手机上实现了facerevelioas应用程序,并在不同的场景下评估了30个用户的系统性能。我们的评价结果表明,该方法在适用性和有效性方面都取得了很好的效果。
国内外研究现状
国内研究现状
李威等(2021)基于LBP(Local Binary Patterns)的人脸关键点算法实现活体检测,实现了对于人脸眨眼,摇头,张嘴三种行为模式的检测。
张高铭和冯瑞(2017)基于复合的眨眼检测与背景分析算法, 通过区域增长算法进行人眼定位、形态学操作进行人眼张合判断、感知Hash算法进行背景差异对比, 使用OpenCV2.4.9与vs2012的MFC架构,设计了一个包含眨眼检测模块与背景分析模块、可以抵御照片攻击与视频攻击的活体检测系统。
国外研究现状
Li等(2018)基于局部二值模式(LBP)、定向梯度直方图(HOG)、灰度共生矩阵(GLCM)、Haar-like(HAAR)等方法对每个合法用户的面部表情进行特征提取图像和照片人脸图像,然后使用支持向量机(SVM)网络进行活体证明。
Xu等(2016)将眼区检测与跟踪技术应用于防伪应用,设计了一种基于眼区活动的活体检测系统。首先提出了尺度平衡和“面对眼”策略来快速检测眼部区域,然后使用KLT算法跟踪检测到的眼部区域。最后向用户发出随机指令(闭眼、向左或向右移动),并根据用户合作的结果给出活跃度判断。
区别和已有工作的不足
已有工作大部分需要额外硬件,本系统仅依靠带有单前置摄像头的智能手机即可实现,符合现在手机市场大屏化需求趋势,有利于推广。且不需要而外响应,更加方便。
文献中已提出几种基于软件的人脸活体检测技术,而无额外硬件。基于纹理方法检测真实面部和照片/屏幕之间的纹理差异。
使用局部二值模式来检测真实人脸和使用二值分类的二维图像的局部信息的差异[10]。测量环境光扩散速度有助于区分人脸[11]。通过比较前后摄像头捕获的面部、指尖视频[12],提取photoplethysmograms。使用rPPG和纹理特征的组合进行欺骗检测[13]。这些受光线和摄像头限制,相比下FaceRevelio可不受限。
其他技术需要响应,如眨眼[14]、嘴唇动作[15]、面部表情、头部动作等[16],但无法抵御视频重放攻击。运用颜色变化验证时间同步,面部表情防御静态攻击[17]。通过用户移动手机和运动传感器来检测[18][19]。以上方法需要用户交互,而FaceRevelio可独立于用户运行,更为便捷。
基于硬件技术需要额外硬件或传感器来检测更多人脸特征。Apple在iPhone X引入的FaceID使用深度传感器提供安全3D面部验证[20],但它占用屏幕。使用前置摄像头和麦克风捕获面部3D特征[21]。但它受限于光线,且需要大量训练的深度学习。使用声学传感器检测,播放声音使得它对用户不是那么友好[22]。其他如用热像仪[23]、3D相机或多个2D相机[24]也会增加额外成本。
研究内容
本文主要研究了可防御各种欺骗攻击的人脸活体检测系统。
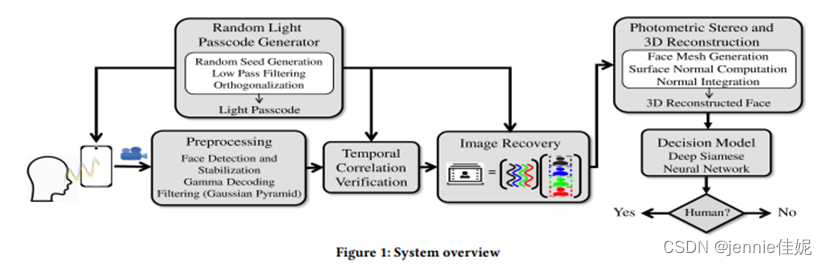
图1显示该架构。通过手机屏幕分为4部分,每部分作为光源操作。由随机光密码生成器模块选择随机光密码。前置摄像头录制一段视频。视频先经过对齐的预处理,再逆伽马校准操作确保线性相机响应,最后高斯过滤使其平滑并二次采样去除噪声。如果高相关,则恢复4个立体图像。通过光度立体技术得面部表面法线图,借用模板和网线准确计算。最后二次法线积分重建3D模型。孪生神经网络提取深度特征,比较得相似分。如果高于阈值为真实人脸。
主要挑战及创新点
主要挑战
- 基于当前市场趋势,需要实现不依靠额外硬件就可实现的有效防御欺骗攻击的人脸活体检测系统。
- 简单且易伪造的光图案易受重放攻击。
- 环境光影响。
- 光模式区分。
- 未知照明方向使法线不确定。
创新点
解决挑战(1),可巧妙借用普通智能手机的屏幕4分屏照亮模式实现不同光方向的照明,以及前置摄像头的摄影和光度立体等技术实现有效的人脸活体检测系统。
解决挑战(2),本文创新地设计了由随机光模式组合的光密码模型,光强会变化使其可防御欺骗攻击。
解决挑战(3),本文设计了正交和“零均值”光密码模型。
解决挑战(4),本文通过固定相机曝光参数和反向伽马校正来线性相机响应。
解决挑战(5),可使用通用模板和网格。
技术路线及实现
FACEREVELIO系统设计:
光密码生成器
将屏幕四分,每部分假定为一个光源。视频录制时等间隔交替亮,其他3部分暗,如图2,以及其3D模型。
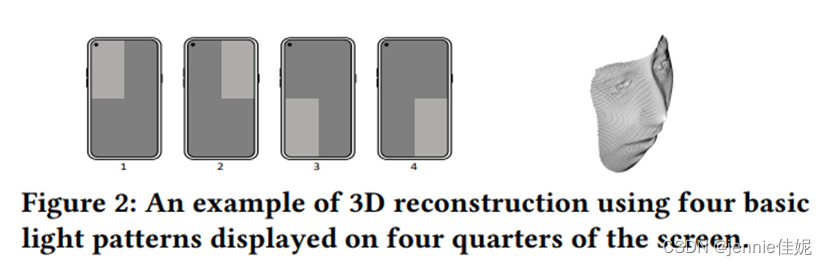
随机光密码生成器:可见如此简单设计易受重放攻击,可改变其光强。
光模式运用屏幕刷新频率为3Hz的理想低通滤波器。虽然智能手机支持60Hz刷新率但屏幕更新会有延迟。因此太高时光强可能不一致。此外用户不舒服。然后将这些过滤后的模式归一化,使得每个模式都是零均值。
视频混合四种光模式反射,为区分作者团队通过高斯滤波[25]引入正交性。图3显示4种光模式密码在运用高斯过滤前后的FFT。

获得4个正交的零均值光图案作为密码后,每个值乘以60幅度,最后将密码添加到恒定的基本像素强度值128。3.2.5描述如何防御重放视频攻击。
视频预处理和过滤
前置摄像头记录面部反射视频。通过使用Face++[26]识别面部标志(83个)定位提取人脸,消除微动影响。
- 视频预处理
作者团队主要通过光照条件变化作用进行识别,则通过将每一帧从色彩空间转换为HSV空间[27]预处理视频,只有反映亮度的V分量被保留。
- 过滤
通过高斯滤波使其去噪声和平滑,同时降低空间采样密度仅保留重要特征减小大小以降低处理时间。
图像恢复
G为f×n矩阵,表示视频帧中每个像素的光强,f表示帧数,n表示1帧中像素。W为f×4光模式矩阵[P1;P2;P3;P4]。X为n×4矩阵[I1;I2;I3;I4],代表要恢复4个立体图。
为准确捕获光强准确值,需使用手动相机模式,如智能手机相机APIs[1]。
此外,相机对原始相机传感器图像数据伽马校正[28]像素值和光强间非线性处。为获得2者间的线性关系,作者团队对获得的视频帧逆伽马校正。同时该线性关系可表示为y=kx+b,即
K为所有视频帧,将式子(4)带入式子(5)得:
最后用最小二乘法求解:
即
B为常数阵,密码W 4个模式每一个为零均值,则WTB可消去,则:
X具有不确定性,设X'=αX,k'=1αk,X’、k’将最小化上述函数。又由SVD有
设k=1,有
考虑环境光和屏幕基本光强,式子(5)变为
C为环境光常数,由于正交和零均值,则WTC可消去。
为确保视频帧对齐,需计算每帧平均亮度且作为记录密码,用该平均亮度低通滤波。平均亮度峰谷值与密码匹配,最后DTW[29]对齐。将其输入方程得到X。
恢复4个立体图示例如图4,第二行为其二进制表示,像素大于其他3个图均值则为1,强调了图像的不同及如何表示光照方向。
 光度立体和3D重建
光度立体和3D重建
- 光度立体
利用4个立体图计算人脸表面法线,利用到3.3相关技术介绍里的光度立体技术。
使用人脸通用模板Nt求解矩阵A,使其没有歧义。用2D三角网格Mt连接模板面部标志(顶点)。该网格表示如下:

最后使法线对称,这需要减少恢复立体图中噪声以减少表面法线。用面部轮廓、鼻子、嘴巴找中心轴,调整其他如眼睛、眉毛使其对称。如图5:

- 3D重建
恢复表面法线后,用二次法向积分法[30]进行3D重建,结果如图6,显示每个模型的侧视图和顶视图。

活体检测
该系统可抵御2D照片攻击和视频重放攻击。
- 2D照片攻击
照片缺乏深度特征,如鼻子、嘴巴、眼睛,如图7:

作者团队训练了一个孪生神经网络[31]来抵御该类攻击。它包含2个结构相同的并行神经网络,但输入不同。一个输入真实人脸深度图,一个输入待验证人脸深度图。分别得到相应特征向量并比较。网络最终输出是真实人脸概率。如果高于阈值,则为真实人脸。图8展示该孪生神经网络的结构。

对于该过程,假设有N个照片深度图和N个视频深度图,最多可获得N(N-1)/2对正样本(皆为真实人脸的视频深度图)和N2对负样本(每对包含1张验证用的真实人脸的视频深度图和1张非真人的照片深度图)。为保证正负样本数目相同负样本也随机选取N(N-1)2对。每次验证都需要输入1对。
孪生神经网络为一次性学习[32]且每次只需1对数据量,远小于传统卷积神经网络。
不采用原始录像训练是因为其环境影响大,数据量大,直接用深度图可节约存储和计算成本。
- 视频重放攻击
第一道防线为光密码随机性
光密码与所录视频具有高相关性,如图9所示,图右侧展示密码时长为1s、2s、3s相关性高于0.84、0.85、0.86所占百分比。由图可见,在超过99.9%情况下相关性高于0.85。对于3秒的密码,只有0.0003%的密码对相关性大于0.84。所以基本没有可能实现密码重现巧合。
第二道防线为3D模型检测
首先攻击者很难实现重放攻击时间同步,其次即使同步成功,密码的差异使其无法通过解方程的方法正确恢复立体图并构建3D模型。

相关技术介绍
光度立体技术:通过同一物体的多个不同光照条件图像恢复3D表面[33]。
光照条件已知时,给定3个点光源,表面法向量为S(至少3个图像):
其中I=I1,I2,I3为3幅立体图,L=L1,L2,L3是各自光照方向。
未知光照条件时,光强矩阵为M,大小m×n,m为图像数,n为各图像像素数:
求解该近似值用奇异值分解(SVD)[34]:
性能评估
实验设置
移动设备配置:
实验在运行Android 9 的带有Camera2 API 10 MP 前置摄像头的三星S10。视频分辨率为1280×960,帧率为30fos。
辅助工具
- Face++[35]:人脸标志识别。
- OpenCV:图像恢复。
- TensorFlow的Python库[36]、Keras:训练神经系统进行活体检测。
- TensorFlow Lite
实验者
30名志愿者(19名男性,11名女性,18到60岁之间,美国/亚洲/欧洲/非洲)。
自然光(白天)/黑暗,灰色背景。
作者团队收集了高质量图像和4900个视频,包括
- 每位志愿者在自然光(白天)/黑暗2种环境进行10次1s密码活体检测。另外测试2s、3s效果。
- 10名志愿者在室内照明/不同手机距离/不同面部方向30次1s密码活体检测。
- 使用背景图片影响。
- 测试3.2.5提及的孪生神经网络抵御照片攻击。每个用户用留一法,其他29个用户深度图进行训练。29个用户的深度图80%用于训练,20%用于验证。实验时用待测深度图和29个用户数据中随机1个深度图作为输入对提供给孪生神经网络,判定真人相似度阈值设为0.7。
评价指标
正确接受率
正确接受率为该接受的样本里你接受的比例。
错误接受率
错误接受率为不该接受的样本里你接受的比例。
或表示为
式中 NIRA 代表的是类间测试次数,即不同类别间的测试次数,打比方如果有1000个识别模型,有1000个人要识别,而且每人只提供一个待识别的素材,那NIRA=1000×(1000-1)。NFA是错误接受次数。
等错误率
取一组0到1之间的等差数列,分别作为识别模型的判别界限,既坐标x轴,画出FFR和FAR的坐标图,交点就是EER值。
时长
即检测所需时间。
性能评价
整体性能
本文评估了抵御2D打印照片和视频重放攻击的能力。
- 抵御2D打印照片性能
图10表示了该系统在黑暗和日光下防御照片攻击且密码1s的ROC曲线。
在黑暗中,其正确接受率为98%,错误接受率仅为0.33%。表明有2%结果为验证不符时,识别准确率为99.7%,等错误率为1.4%。
在白天时,当正确接受率为97.7%时,识别准确率为99.3%,等错误率为1.4%。
可见黑暗环境性能更好,其信噪比更高,有利于3D重建。
- 抵御视频重放攻击性能
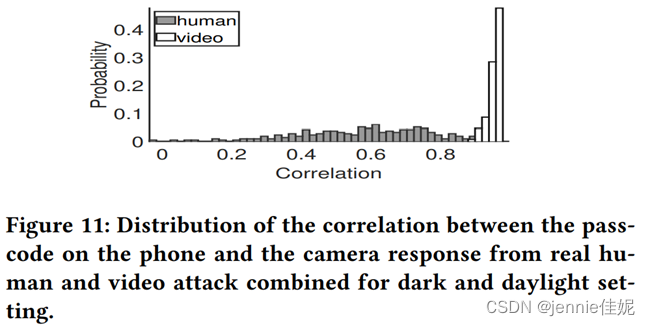
视频播放于屏幕分辨率为1920×1080的联想Thinkpad笔记本。系统检测到了,黑暗环境下EER为0%,日光环境下为0.3%。图11显示了了1s密码与重放视频里密码相机响应之间的相关性的直方图。相关性都小于0.9,而真实人脸99.8%的视频的相关性都高于0.9。
- 总时长
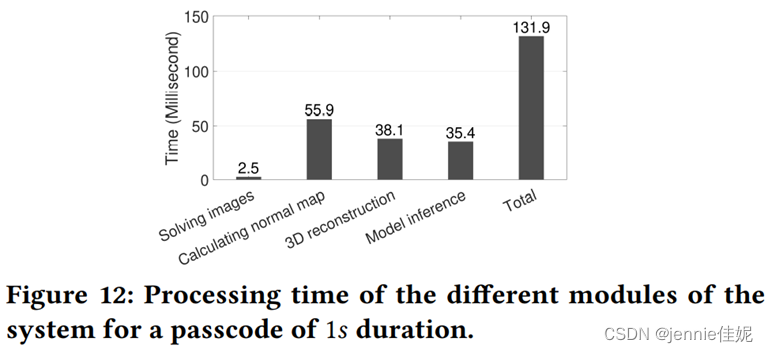
图12显示各模块处理时长。总时长只需0.13s。恢复立体图像只需3.6ms,耗时最长为法线计算,需要56ms,因为它需要2次2D变换。通过孪生神经网路进行3D重建和特征提取分别需要38.1ms和35.4ms。
光密码时长影响
本文测试了1、2、3s密码的性能。
- 照片攻击
图13显示在黑暗(左)和日光(右)设置不同时长密码的照片攻击的ROC曲线。可看出随时长增加性能有所提高。但即使1s密码也能完成检测。
黑暗
检测准确率为99.7%,正确接受率(精度)为98%、99%、99.3%,EER分别为1.44%、0.7%、0.7%。
日光
检测准确率分别为99.3%、99.3%、99.7%,正确接受率(精度)为97.7%、98.3%、99.3%。
- 视频重放攻击
图14展示2s密码(图左)和3s密码(图右)视频攻击的密码和原密码的相关性。3种密码处理总时长皆低于0.15s。
2s密码
相关性都小于0.84,而99.8%真人数据相关性都高于0.86。
3s密码
相关性都小于0.8,而99.8%真人数据相关性都高于0.8。
室内照明影响
实验在有多盏灯室内对10名志愿者进行,使用1s密码。当正确接受率为98%时,该系统对抗2D攻击的准确率为99.7%,EER为1.4%,接近黑暗时结果。所以在室内该系统性能良好。
手机距离影响
团队测量得10名志愿者平时与手机的平均距离为27cm。所以设置了20、30、40cm的变量。图15为各种距离对抗2D攻击的ROC曲线,可见距离大也可防御欺骗攻击。

自然距离(27cm)/30cm
正确接受率为98%时,检测出2D攻击的准确率为99.3%。
20cm
正确接受率为98%时,检测出2D攻击的准确率为99.7%。
40cm
正确接受率为96.7%时,检测出2D攻击的准确率为99.3%。
人脸朝向影响
图16显示不同朝向的性能,EER为1.44%。实验证明该系统可防御面部不同方向的欺骗攻击,主要因为计算法线时采用面部标志网格法(详见3.3.4.1)。

自然情况
正确接受率为98.3%时,检测出2D攻击的准确率为99.7%。
其他(面部方向为上/下/左/右)
检测出2D攻击的准确率为99.7%
面部方向为上
正确接受率为98%。
面部方向为下
正确接受率为98.3%。
面部方向为左
正确接受率为98%。
面部方向为右
正确接受率为98.3%。
背景图案影响
实验选择如图17示例的5张图片,第二行为密码具体示例。

实验让10个用户在5个背景图和日光下进行10次实验,防御欺骗攻击的EER为1.15%。正确接受率为97%时,检测照片攻击准确率为99.4%。证明背景图案影响不大,用户可根据喜好选择背景图片。
功耗
当亮度最大时,每次消耗1.08mAh,假设每天解锁100次[37]而现代旗舰智能手机电池容量3500 mAh[38],该系统每天耗电仅占3.4%。
与其他活体检测技术对比
表1概述了智能手机上面部活体检测的现有方法,且具体展示各自可防御攻击类型、是否需要额外硬件、是否需要用户交互。市场上,三星人脸识别易受2D照片攻击,需要结合其他方式[39]。苹果的FaceID[20]包含TureDepth摄像头,可最安全抵御2D和3D欺骗攻击,通过面部3D重建可捕捉细节。但FaceRevelio是所有不依靠额外硬件的技术中[40][19][41][42]最快的、检测2D照片和视频攻击具备最高准确率的技术。Tang等人[42]使用响应实现高精度,但需要用户交互且需要大于6s的时间。而FaceRevelio在1s内无需交互可检测欺骗攻击。同时对于光照条件要求,在黑暗下无法准确检测[40][17][21]。EchoFace[22]借用声学传感器实现较高准确率,但外放声音(由于智能手机扬声器限制[43])使其对用户不是那么友好。
论文评述
论文优缺点
优点
本文创新性地设计出仅依靠带有前置摄像头的普通智能手机就可实现的高精度的活体检测系统,为当今手机市场急需不依靠额外硬件就可实现的有效防御2D照片和视频攻击的人脸活体检测提出可靠方案。优点具体如下
- 论文idea在创新性和实用性强
开创性地提出基于随机光模型的光密码概念系统,仅依靠带有单前置摄像头的普通智能手机即可实现,其推广的普遍性和便利性显而易见,可解决当今实际市场的尴尬处境,具有较强的推广性,且不需要额外的昂贵硬件。
- 论文的技术方法合理
巧妙借用屏幕分区照亮的方法实现不同方向的光照,灵活通过借用屏幕光和摄像头的简单现有构件及光度立体[7]的方法实现三维面部模型构建,并大胆使用孪生神经深度学习系统实现精准识别。
- 论文中的实验设置合理严谨
通过收集来自全球各地用户的4900数据进行实验评估,实验数据充分可靠。
- 论文中对所提方法、系统的评价是否合理
针对八大方向依次设计好严谨实验过程保证实验的可靠性,充分利用实验数据,评估结果可靠。
- 市场前景好
该系统及时地为当今及未来市场急需的高效便捷活体人脸识别问题提出一种可行的解决方案。由于其无需多于硬件、使用大部分普通智能手机、用户友好型等显著、性能良好特性,可预期其在市场的推广面应当很广。在光模式频率设计上考虑了用户体验,后期也提出背景图案的加入以增强用户体验,这些举措也进一步增强该系统的用户友好型体验效果。
缺点
- 论文对于响应系统和市场趋势的评价过于牵强
文中评价用户交互不方便,对老人不够友好,实际在此方面说法优点偏妥,仅依靠简单表情动作实现的交互认证系统在实际运用场景还是很方便的,市场也不一定特别在意额外增加的微小硬件设备。应该说不同的系统各具优势,具备他们各自最佳的运用场景。
- 该系统无法很好防御3D欺骗攻击
如它可能无法检测出3D打印面具。
- 该系统无法识别面部细节,仅能活体检测
该项技术不能区别不同人之间差异,仅能辨别是否为活体,用于提高现有人脸认证技术的安全度。暂时无法做到人脸认证识别。
改进方向
- 防御3D欺骗攻击
优化3D重建算法和孪生神经网络。
- 人脸认证识别
优化3D重建算法,修改法线计算的网格变形步骤以保留面部微小细节。添加人脸认证识别系统。
阅读收获
本次阅读收获良多,可以说是这门对我以后的科研学习道路帮助最大的一个环节,他算是我第一次严格意义的科研英文文献阅读和学习的过程。作为一名刚接触这个学科和进入实验室不久的学生,这样的一种为自己未来研究生及以后科研道路的基本文献阅读学习能力打基础的过程是很有必要的。所以十分感谢老师及课题组的课程安排,给我一个机会能窥探一下科研的世界并掌握受益终身的技能;这也更加坚定我以后在这条路上稳扎稳打的决心。
虽然由于我自身课程安排等原因无法在学期中预留出充足时间给最后的Preseneation,但最后也是有保证20个小时以上的充足准备再上台,也不希望让自己对在这门课最后的表现抱有遗憾。考虑到我现在所处项目组以及未来很大概率会继续的研究方向,我这一次选择了之前已经在实验室有过接触的人脸识别(仅活体检测)的论文,算是为我以后的研究历程打一个小小的基础。
之前由于对自己英语能力的不信任,一直有点畏惧外国文献,但经过这一个学期的学习我也愈发意识到在这个学科英语能力的重要性。由于学科的特殊性,当今计算机的大部分前沿优秀文献资料基本为外文,提高英语阅读能力显得尤为必要。也借此机会我挑战了阅读10多页英文文献,也算是克服了自己的一个心理障碍,这对我自身的研究生科研生活及未来显得尤为重要。
在此过程中,我首次透彻理解了一片科研论文的完整结构,与之前停留于听课的大概了解完全不同,也揭开在很多本科生眼里高高在上的论文的神秘面纱,不再畏惧,可以算是我以后的毕设以及实验室生活的一个很宝贵的敲门砖。同时我很庆幸本次我阅读的文献也与我正在接触的研究方向是一致的,论文中提及的很多技术和研究方法、以及实验的设置和评估方法都将给我很大帮助,所以我也尤为认真地对待这一次文献阅读。
如果说由于时间问题,我在Preseneation前无法很完美地完成关于评估方面的学习,课上我答辩时老师对我存在的问题的及时点拨可以说是对我后期完成这份大作业报告起了很大的指导作用。回来后我虚心接受老师指出来的我还存在缺漏的部分,认真阅读研究关于人脸识别实验评估的常用指标和实验设置方法,受益良多,对我后期的研究学习也起了极为重要的帮助。
尤其在完成大作业报告的过程,我相当于利用论文里学的知识,亲身体验了论文撰写的过程。如果说纯粹地阅读还存在遗漏的地方的话,那么在撰写大作业报告的过程我已经把整项技术过程理解得十分透彻。在此过程中我还学习了很多论文撰写的技巧,包括排版格式设置、公式输入、专有名词输入、参考文献标注等,对我后期的学习生涯受益良多。
此为我牢记老师说的带着思考去阅读的要求,在充分理解学习论文所写内容后,我也尝试着独立去思考论文的优缺点,认识到了这种辩证性、开创性思考在科研学习中的重要性。
附录
Presentation环节答辩问题补充
错误接受率(FAR-False Acceptance Rate)
图像识别评价模型时要用到这三个指标:
- 错误接受率 (FAR-False Acceptance Rate)
或表示为
式中 NIRA 代表的是类间测试次数,即不同类别间的测试次数,打比方如果有1000个识别模型,有1000个人要识别,而且每人只提供一个待识别的素材,那NIRA=1000×(1000-1)。NFA是错误接受次数。
- 错误拒绝率 (FRR-False Rejection Rate)
错误拒绝率为不该拒绝的样本里你拒绝的比例。
或表示为
上式中NGRA是类内测试次数,既同类别内的测试次数,打比方如果有1000个识别模型,1000个人要识别,而且每人只提供一个待识别的素材,那 NGRA=1000,如果每个人提供N张图片,那么NGRA=N×1000。NFR是错误拒绝次数。
- 等错误率 (EER-Equal Error Rate)
取一组0到1之间的等差数列,分别作为识别模型的判别界限,既坐标x轴,画出FFR和FAR的坐标图,交点就是EER值。
孪生神经网络
它包含2个结构相同的并行神经网络,但输入不同。一个输入真实人脸深度图,一个输入待验证人脸深度图。分别得到相应特征向量并比较。网络最终输出是真实人脸概率。如果高于阈值,则为真实人脸。图8展示该孪生神经网络的结构。

对于该过程,假设有N个照片深度图和N个视频深度图,最多可获得N(N-1)/2对正样本(皆为真实人脸的视频深度图)和N/2对负样本(每对包含1张验证用的真实人脸的视频深度图和1张非真人的照片深度图)。为保证正负样本数目相同负样本也随机选取N(N-1)/2对。每次验证都需要输入1对。
孪生神经网络为一次性学习[32]且每次只需1对数据量,远小于传统卷积神经网络。
不采用原始录像训练是因为其环境影响大,数据量大,直接用深度图可节约存储和计算成本。
参考文献:
[1]Shaxun Chen, Amit Pande, and Prasant Mohapatra. 2014. Sensor-assisted facial recognition: an enhanced biometric authentication system for smartphones.In Proceedings of the 12th annual international conference on Mobile systems,applications, and services. ACM, 109–122.
[2]Klaus Kollreider, Hartwig Fronthaler, and Josef Bigun. 2009. Non-intrusive liveness detection by face images. Image and Vision Computing 27, 3 (2009),233–244.
[3]Xiaoyang Tan, Yi Li, Jun Liu, and Lin Jiang. 2010. Face liveness detection from a single image with sparse low rank bilinear discriminative model. In European Conference on Computer Vision. Springer, 504–517.
[4]Yan Li, Yingjiu Li, Qiang Yan, Hancong Kong, and Robert H Deng. 2015. Seeing your face is not enough: An inertial sensor-based liveness detection for face authentication. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 1558–1569.
[5][n.d.].AboutNFaceNID advanced technology. https://support.apple.com/en-us/HT208108.
[6][n.d.].ProcessingNRaw Images in MATLAB. https://rcsumner.net/raw_guide/RAWguide.pdf.
[7]Hideki Hayakawa. 1994. Photometric stereo under a light source with arbitrary motion. JOSA A 11, 11 (1994), 3079–3089.
[8][n.d.].Understanding Gamma Correction. https://www.cambridgeincolour.com/tutorials/gamma-correction.htm
[9]Yvain Quéau, Jean-Denis Durou, and Jean-François Aujol. 2017. Variational Methods for Normal Integration. CoRR abs/1709.05965 (2017). arXiv:1709.05965 http://arxiv.org/abs/1709.05965.
[10]Xiaoyang Tan, Yi Li, Jun Liu, and Lin Jiang. 2010. Face liveness detection from a single image with sparse low rank bilinear discriminative model. In European Conference on Computer Vision. Springer, 504–517.
[11]Wonjun Kim, Sungjoo Suh, and Jae-Joon Han. 2015. Face liveness detection from a single image via diffusion speed model. IEEE transactions on Image processing 24, 8 (2015), 2456–2465.
[12]Y. Chen, J. Sun, X. Jin, T. Li, R. Zhang, and Y. Zhang. 2017. Your face your heart: Secure mobile face authentication with photoplethysmograms. In IEEE INFOCOM 2017 - IEEE Conference on Computer Communications. 1–9. https://doi.org/10.1109/INFOCOM.2017.8057220.
[13]Bofan Lin, Xiaobai Li, Zitong Yu, and Guoying Zhao. 2019. Face Liveness De-tection by RPPG Features and Contextual Patch-Based CNN. In Proceedings of the 2019 3rd International Conference on Biometric Engineering and Applications (ICBEA 2019). Association for Computing Machinery, New York, NY, USA, 61âĂŞ68. https://doi.org/10.1145/3345336.3345345.
[14]Hyung-Keun Jee, Sung-Uk Jung, and Jang-Hee Yoo. 2006. Liveness detection for embedded face recognition system. International Journal of Biological and Medical Sciences 1, 4 (2006), 235–238.
[15]Klaus Kollreider, Hartwig Fronthaler, Maycel Isaac Faraj, and Josef Bigun. 2007.Real-time face detection and motion analysis with application in liveness assessment. IEEE Transactions on Information Forensics and Security 2, 3 (2007),
548–558.
[16]Bofan Lin, Xiaobai Li, Zitong Yu, and Guoying Zhao. 2019. Face Liveness Detection by RPPG Features and Contextual Patch-Based CNN. In Proceedings of the 2019 3rd International Conference on Biometric Engineering and Applications (ICBEA 2019). Association for Computing Machinery, New York, NY, USA, 61âĂŞ68. https://doi.org/10.1145/3345336.3345345.
[17]Di Tang, Zhe Zhou, Yinqian Zhang, and Kehuan Zhang. 2018. Face Flashing: a Secure Liveness Detection Protocol based on Light Reflections. arXiv preprintarXiv:1801.01949 (2018).
[18] Shaxun Chen, Amit Pande, and Prasant Mohapatra. 2014. Sensor-assisted facialrecognition: an enhanced biometric authentication system for smartphones.In Proceedings of the 12th annual international conference on Mobile systems,applications, and services. ACM, 109–122.
[19]Yan Li, Yingjiu Li, Qiang Yan, Hancong Kong, and Robert H Deng. 2015. Seeing your face is not enough: An inertial sensor-based liveness detection for face authentication. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 1558–1569.
[20][n.d.].About Face ID advanced technology. https://support.apple.com/en-us/HT208108.
[21]Bing Zhou, Jay Lohokare, Ruipeng Gao, and Fan Ye. 2018. EchoPrint: Two-factor Authentication using Acoustics and Vision on Smartphones. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking.ACM, 321–336.
[22]H. Chen, W. Wang, J. Zhang, and Q. Zhang. 2020. EchoFace: Acoustic Sensor-Based Media Attack Detection for Face Authentication. IEEE Internet of Things Journal 7, 3 (March 2020), 2152–2159. https://doi.org/10.1109/JIOT.2019.2959203.
[23]Tejas I Dhamecha, Aastha Nigam, Richa Singh, and Mayank Vatsa. 2013. Disguise detection and face recognition in visible and thermal spectrums. In Biometrics(ICB), 2013 International Conference on. IEEE, 1–8.
[24]AndreaLagorio,MassimoTistarelli,MarinellaCadoni,ClintonFookes,andSridha Sridharan. 2013. Liveness detection based on 3D face shape analysis.. In IWBF.1–4.
Kimberly A. Dukes. 2014. Gram–Schmidt Process. American Cancer Society.https://doi.org/10.1002/9781118445112.stat05633arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781118445112.stat05633.
[n. d.]. Face++. https://www.faceplusplus.com/landmarks/
MaxKAgoston.2005.ComputerGraphicsandGeometricModeling:Implementation and Algorithms. Springer London.
[28][n.d.].Understanding Gamma Correction. https://www.cambridgeincolour.com/tutorials/gamma-correction.htm.
[29]Donald J Berndt and James Clifford. 1994. Using dynamic time warping to find patterns in time series.. In KDD workshop, Vol. 10. Seattle, WA, 359–370.
[30]Yvain Quéau, Jean-Denis Durou, and Jean-François Aujol. 2017. Variational Methods for Normal Integration. CoRR abs/1709.05965 (2017). arXiv:1709.05965 http://arxiv.org/abs/1709.05965.
[31]Gregory Koch, Richard Zemel, and Ruslan Salakhutdinov. 2015. Siamese neural networks for one-shot image recognition. In ICML deep learning workshop, Vol. 2.Lille.
[32]Li Fei-Fei, Rob Fergus, and Pietro Perona. 2006. One-shot learning of object categories. IEEE transactions on pattern analysis and machine intelligence 28, 4(2006), 594–611.
[33] Robert J Woodham. 1980. Photometric method for determining surface orienta-tion from multiple images. Optical engineering 19, 1 (1980), 191139.
[34]Lloyd N Trefethen and David Bau III. 1997. Numerical linear algebra. Vol. 50.Siam.
[35][n. d.]. Face++. https://www.faceplusplus.com/landmarks/.
[36]Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen,Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, San-jay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard,Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg,Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng.2015. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems.https://www.tensorflow.org/ Software available from tensorflow.org.
[37][n.d.].How many times do you unlock your phone? https://www.techtimes.com/articles/151633/20160420/how-many-times-do-you-unlock/-your-iphone-per-day-heres-the-answer-from-apple.htm.
[38][n. d.]. Fact check: Is smartphone battery capacity growing or staying the same? https://www.androidauthority.com/smartphone-battery-capacity-887305/.
[39][n. d.]. How does Face recognition work on Galaxy Note10, Galaxy
Note10+,and Galaxy Fold? https://www.samsung.com/global/galaxy/what-is/face-recognition/
[40]Y. Chen, J. Sun, X. Jin, T. Li, R. Zhang, and Y. Zhang. 2017. Your face your heart: Secure mobile face authentication with photoplethysmograms. In IEEE INFOCOM 2017 - IEEE Conference on Computer Communications. 1–9. https://doi.org/10.1109/INFOCOM.2017.8057220.
[41]Yan Li, Zilong Wang, Yingjiu Li, Robert Deng, Binbin Chen, Weizhi Meng, and Hui Li. 2019. A Closer Look Tells More: A Facial Distortion Based Liveness DetectionforFaceAuthentication. InProceedingsofthe2019ACMAsiaConfereneon Computer and Communications Security (Asia CCS âĂŹ19). Association for Computing Machinery, New York, NY, USA, 241âĂŞ246. https://doi.org/10.1145/3321705.3329850.
[42]Di Tang, Zhe Zhou, Yinqian Zhang, and Kehuan Zhang. 2018. Face Flashing: a Secure Liveness Detection Protocol based on Light Reflections. arXiv preprintarXiv:1801.01949 (2018).
[43]Patrick Lazik and Anthony Rowe. 2012. Indoor pseudo-ranging of mobile devices using ultrasonic chirps. In Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems. 99–112.
[44]Li S , Qin L , Hu J . Face liveness detection system based on specific environment[J]. Huazhong Keji Daxue Xuebao (Ziran Kexue Ban)/Journal of Huazhong University of Science and Technology (Natural Science Edition), 2018, 46(11):87-91.
[45]Xu G Z , Yin P L , Lei B J , et al. Eye Region Activity State based Face Liveness Detection System[J]. International Journal of Security and its Applications, 2016, 10(1):361-374.
[46]李威,翟雨佳,李文清,赵芳,叶青.基于人脸关键点的活体检测系统[J].中国科技信息,2021(02):98-100.
[47]张高铭,冯瑞.基于人脸的活体检测系统[J].计算机系统应用,2017,26(12):37-42.DOI:10.15888/j.cnki.csa.006100
[1] Android Lollipop 5.1 开始支持手动相机模式