关系型数据库设计-6种范式
关系型数据库的规范化理论
规范化理论用来改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余问题。
数据依赖
- 通过一个关系中属性间值的相等与否体现出来的数据键的相互关系
- 现实世界属性间相互联系的抽象
- 数据的内在的性质
- 语义的体现
函数依赖
- 关系的X属性集上的值,可以唯一决定R的Y属性集上的值
- 对于R的任意两个元组,X上的值相等,Y上的值必相等。
满足这种关系, 则:
-
X函数决定Y,Y函数依赖于X, 记作 X→Y
-
X称为 决定因素,Y称为依赖因素。
说明:
- 如果X→Y,并且Y→X, 则记为 X↔Y
- 如果Y不函数依赖于X, 则记为 X↛ Y
对于关系模式R(U),U为属性集,X、Y为U的子集,根据函数依赖定义和实体间联系的定义,可以得到如下变换的方法:
- 如果X和Y之间是1:1的联系, 则存在函数依赖X↔Y
- 如果X和Y之间是n:1的联系, 则存在函数依赖X→Y
- 如果X和Y之间是m:n的联系,则X和Y之间不存在函数依赖
函数依赖实际上是指一个关系中一个属性集和另一个属性集间的多对一关系
多对一关系可以用外键来描述
平凡函数依赖与非平凡函数依赖
-
平凡函数依赖
X→Y, 但是 Y⊆X
平凡函数依赖必然存在的
-
非平凡函数依赖
X→Y, Y⊈X
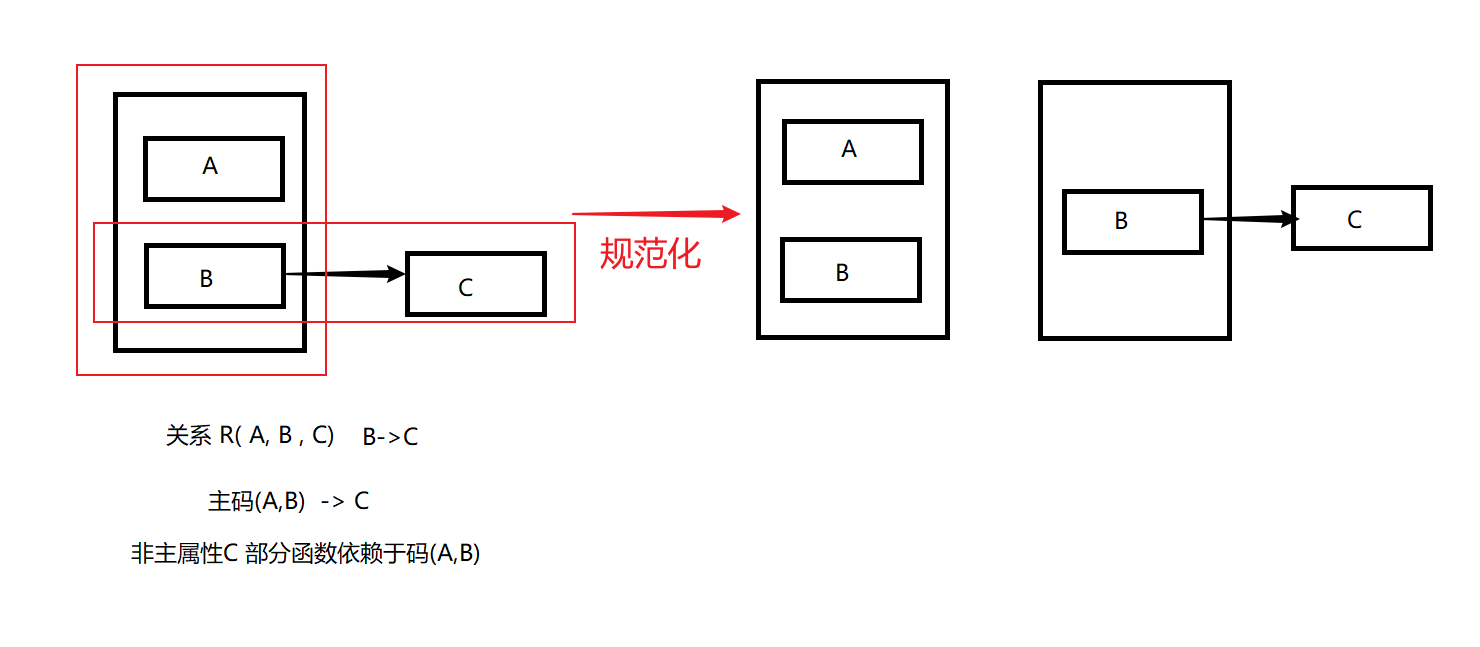
完全函数依赖与部分函数依赖
-
部分函数依赖
X→Y , 存在 X的某一个真子集 X’ →Y
-
完全函数依赖
X→Y , 不存在 X的某一个真子集 X’ →Y
也就是X是可以决定Y的最小集合
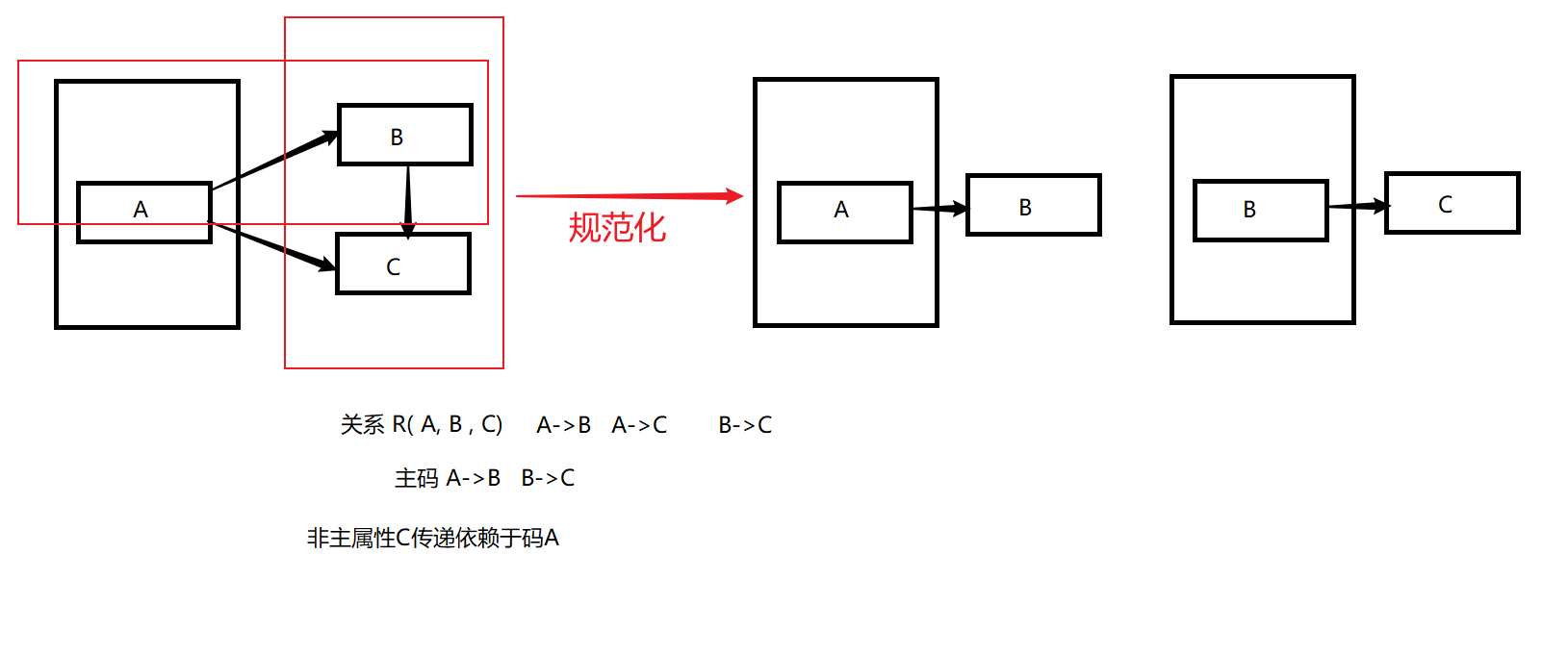
传递函数依赖
- X→Y, Y→Z
- 并且 Y不是 X的子集, Z不是Y的子集
- 同时 Y↛ X
码&主码、主属性&非主属性
码&主码
- 候选码,简称码
- 候选码是能够唯一确定关系中任何一个元组的最少属性集合
- 主码是候选码中任意选定的一个
外码(外键)
关系模式R中属性或者属性组X, 并非R的码,但X是另一个关系模式的S的码,则称X是R的外码
主属性&非主属性
-
主属性
包含在任何一个候选码中的属性,取值不能为空值
-
非主属性
不包含在任何码中的属性
范式
满足特定要求的模式
- 不同级别的范式要求不同
- 范式可以作为衡量一个关系模式的好坏的标准
- 若关系模式R满足范式xNF, 记为 R∈xNF
第一范式(1NF)
所有属性都是不可分的基本数据项, 即属性不可分
1NF是关系的基本要求, 否则不能称为关系数据库
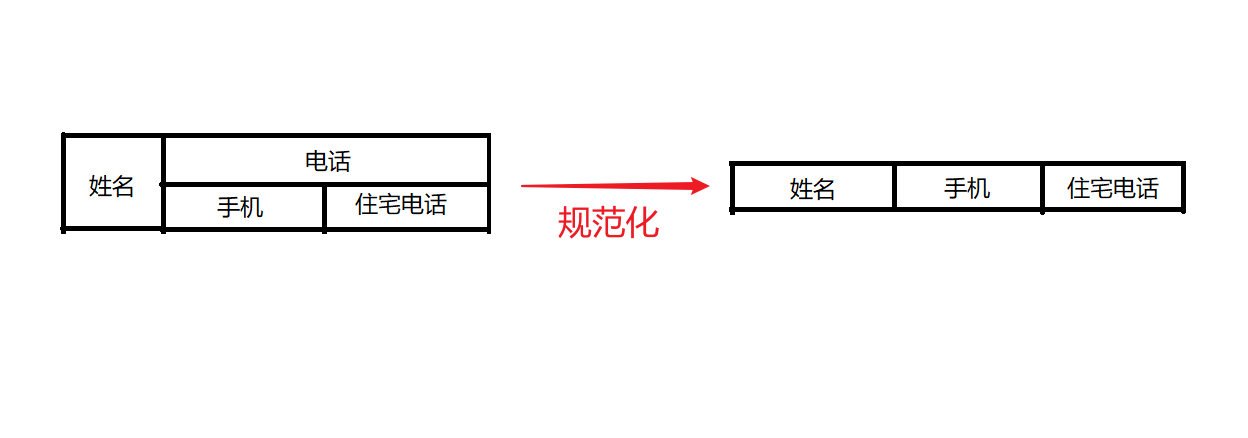
第二范式(2NF)
- 关系模式R ∈ 1NF
- 每一个非主属性完全函数依赖于R的码
符合1NF, 并且消除了非主属性对码的部分函数依赖
推论
- 如果关系模式R∈1NF, 并且每个候选码都是单码,则R∈2NF
第三范式(3NF)
- 关系模式R∈2NF
- R的每个非主属性都不传递依赖于任何候选码
符合2NF,并且消除了非主属性对码的传递函数依赖
推论
- 不存在非主属性的关系模式一定为3NF
BC范式(BCNF)
每一个决定属性集,都包含候选码
X→Y, Y不是X的子集, 则X必包含候选码, 那么R∈BCNF
符合3NF,并且消除了主属性对码的部分函数依赖和传递依赖
推论:
- 如果R∈3NF, 并且R只有一个候选码,则必有R∈BCNF
BCNF是在函数依赖条件下对模式分解所能达到的最高分离程度,BCNF在函数依赖范畴内达到了最高的规范化程度。
BCNF的关系所具有的性质
- 所有非主属性都完全函数依赖于每个候选码
- 所有主属性都完全函数依赖于每个不包含它的候选码
- 没有任何属性完全函数依赖于非码的任何一组属性
第四范式(4NF)
消除表中的多值依赖
第五范式(5NF)
将表分割为尽可能小的块,为了排除在表中所有的冗余。
关系模式规范化
概念
将低一级的范式的关系模式,通过模式分解转换为高一级的关系模式集合的过程,叫做关系模式的规范化
遵循原则
-
关系模式进行无损连接分解
关系模式分解过程中数据不能丢失或者增加,必须把全局关系模式中的所有数据无损的分解到各个子关系模式中,以保证数据的完整性
-
合理选择规范化程度
-
存取效率
低级模式造成的冗余度很大,浪费存储空间,影响数据的一致性
-
查询效率
低级范式比高级范式好连接运算的代价较小
-
-
正确性与可实现性原则
关系模式的分解
有三种定义
- 分解具有无损连接性
- 分解要保持函数依赖
- 分解既要 保持函数依赖 又要具有 无损连接性
无损连接
分解后子模式的自然连接结果 和 原模式相等
只有具有无损连接性的分解才能够保证不丢失信息
保持函数依赖
原模式蕴含的函数依赖 一定 也可以由分解得到的某个关系模式中的函数依赖所逻辑蕴含