在使用libtorch进行部署时,会面临显存不够用的情况。因此需要对显存的利用进行管理,对此研究libtorch的api,尝试进行显存管理。libtorch运行程序时,显存占用可以分为3块:模型参数占用显存、输入输出tensor占用显存、模型forword过程临时变量占用显存。
使用cudaFree(tensor.data_ptr())可以释放掉tensor所占用的显存,也可以使用该函数释放掉模型参数所占用的显存。使用CUDACachingAllocator::emptyCache函数可以释放掉模型在forword过程中的一些显存。
为了探究模型部署时各阶段的显存占用和管理,进行以下代码测试。
1、环境配置
进行显存管理时,需要配置cuda,cuda配置可以参考图1。此外,还需要在链接器-》输入-》附加依赖项中,配置cudnn.lib;cublas.lib;cudart.lib;。

libtorch的配置可以参考pytorch 4 libtorch配置使用实录(支持cuda的调用)_万里鹏程转瞬至的博客-CSDN博客
2、库导入和基本函数实现
下列代码主要实现cuda和libtorch的导入,和cuda使用查询的函数
#include <torch/script.h>
#include <torch/torch.h>
#include <c10/cuda/CUDAStream.h>
#include <ATen/cuda/CUDAEvent.h>
#include <iostream>
#include <memory>
#include <string>
#include <cuda_runtime_api.h>
using namespace std;
static void print_cuda_use( )
{
size_t free_byte;
size_t total_byte;
cudaError_t cuda_status = cudaMemGetInfo(&free_byte, &total_byte);
if (cudaSuccess != cuda_status) {
printf("Error: cudaMemGetInfo fails, %s \n", cudaGetErrorString(cuda_status));
exit(1);
}
double free_db = (double)free_byte;
double total_db = (double)total_byte;
double used_db_1 = (total_db - free_db) / 1024.0 / 1024.0;
std::cout << "Now used GPU memory " << used_db_1 << " MB\n";
}首先实现cuda利用查询的函数
static void print_cuda_use( )
{
size_t free_byte;
size_t total_byte;
cudaError_t cuda_status = cudaMemGetInfo(&free_byte, &total_byte);
if (cudaSuccess != cuda_status) {
printf("Error: cudaMemGetInfo fails, %s \n", cudaGetErrorString(cuda_status));
exit(1);
}
double free_db = (double)free_byte;
double total_db = (double)total_byte;
double used_db_1 = (total_db - free_db) / 1024.0 / 1024.0;
std::cout << "Now used GPU memory " << used_db_1 << " MB\n";
}3、libtorch过程显存管理
代码中的d_in_out.pt参考自,但略有不同(模型参数更多了,博主把模型的参数增加了100倍,其实就是把每一个kernel的filer_num增大了)pytorch 6 libtorch部署多输入输出模型(支持batch)_万里鹏程转瞬至的博客-CSDN博客_pytorch多输入
代码中的注释详细说明了每一个操作是否有效和其影响
int main() {
string path = "d_in_out.pt";
//设置不需要存储梯度信息
at::NoGradGuard nograd;
int gpu_id = 0;
//加载模型
torch::jit::Module model = torch::jit::load(path);
model.to(at::kCUDA);
model.eval();//设置评价模式
std::cout << "加载模型后的显存占用\n";
print_cuda_use();
//构建双输入数据
//对于单输入模型只需要push_back一次
at::Tensor x1_tensor = torch::ones({ 1,3,512,512 }).to(at::kCUDA);
at::Tensor x2_tensor = torch::ones({ 1,3,512,512 }).to(at::kCUDA);
at::Tensor result1,result2;
std::cout << "\n初始化tensor的显存占用\n";
print_cuda_use();
std::cout << "\n循环运行5次\n";
for (int i = 0;i < 5;i++) {
//result=model.forward({ x1_tensor,x2_tensor }).toTensor();//one out
auto out = model.forward({ x1_tensor,x2_tensor });
auto tpl = out.toTuple();//out.toTensorList();
result1 = tpl->elements()[0].toTensor();
result2 = tpl->elements()[1].toTensor();
print_cuda_use();
}
std::cout << "\n释放tensor所占用的显存(帮助不大)\n";
cudaFree(x1_tensor.data_ptr());
cudaFree(x1_tensor.data_ptr());
cudaFree(result1.data_ptr());
cudaFree(result2.data_ptr());
print_cuda_use();
std::cout << "\nCUDACachingAllocator::emptyCache (有点效果)\n";
c10::cuda::CUDACachingAllocator::emptyCache();
print_cuda_use();
std::cout << "\n释放模型参数占用的显存(无意义)\n";
for (auto p : model.parameters())
cudaFree(p.data_ptr());//接下来不能使用cuda,导致model.to(at::kCUDA);报错
print_cuda_use();
//torch::jit::Module::Module::freeze(model);
std::cout << "\n调用模型的析构函数(无效)\n";
model.~Module();//对显存变化没有实际帮助
print_cuda_use();
std::cout << "\n重置cuda状态(无效)\n";
c10::cuda::CUDACachingAllocator::init(gpu_id);
c10::cuda::CUDACachingAllocator::resetAccumulatedStats(gpu_id);//对显存变化没有实际帮助
c10::cuda::CUDACachingAllocator::resetPeakStats(gpu_id);
print_cuda_use();
std::cout << "\ncudaDeviceReset(有效,会导致后续模型无法使用cuda)\n";
//需要配置cuda
cudaDeviceReset();//完全释放GPU资源 接下来不能使用cuda,导致model.to(at::kCUDA);报错 除非能重新初始化libtorch的cuda环境
print_cuda_use();
torch::cuda::synchronize();
model = torch::jit::load(path);
model.to(at::kCUDA);
print_cuda_use();
return 0;
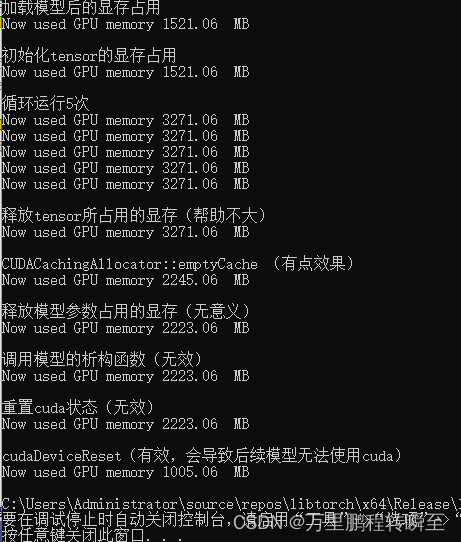
}上述代码的执行结果如下图所示。