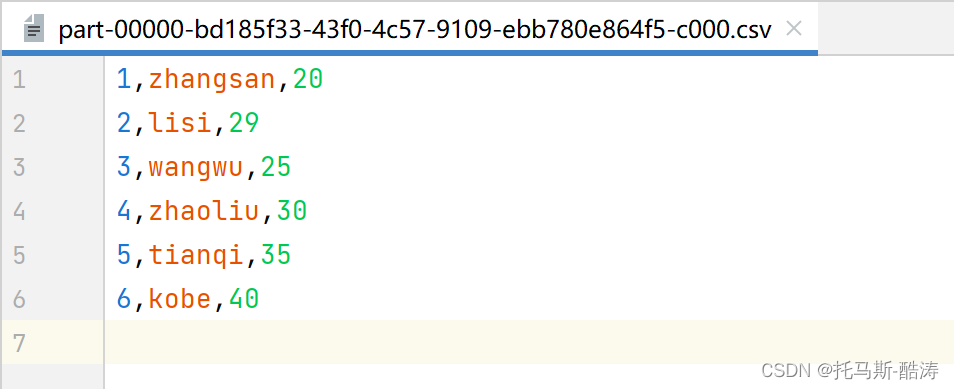
输入文件
代码
package example.spark.sql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object RDD_DF_DS {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[6]").config("spark.sql.warehouse.dir", "E:/").getOrCreate()
val sc: SparkContext = spark.sparkContext
Logger.getLogger("org").setLevel(Level.ERROR)
val lines: RDD[String] = sc.textFile("data/input/csv")
// val personRDD: RDD[(Int,String,Int)] = lines.map(line => {
val personRDD: RDD[Person] = lines.map(line => {
val str: Array[String] = line.split(",")
// (str(0).toInt, str(1), str(2).toInt)
Person(str(0).toInt, str(1), str(2).toInt)
})
//转换1: RDD->DF
import spark.implicits._
val personDF: DataFrame = personRDD.toDF("id", "name", "age")
//转换2:RDD->DS
val personDS: Dataset[Person] = personRDD.toDS()
//转换3:DF->RDD DF没有泛型
val rdd: RDD[Row] = personDF.rdd
//转换4:DS->RDD
val rdd1: RDD[Person] = personDS.rdd
//转换5:DF-->DS
val ds: Dataset[Person] = personDF.as[Person]
//转换6:DS-->DF
val df: DataFrame = personDS.toDF()
personDF.show()
personDS.show()
rdd.foreach(println)
rdd1.foreach(println)
//关闭资源
spark.stop()
}
case class Person(id: Int, name: String, age: Int)
}
结果打印
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
[1,zhangsan,20]
[2,lisi,29]
[4,zhaoliu,30]
[3,wangwu,25]
[5,tianqi,35]
[6,kobe,40]
Person(1,zhangsan,20)
Person(4,zhaoliu,30)
Person(5,tianqi,35)
Person(6,kobe,40)
Person(2,lisi,29)
Person(3,wangwu,25)
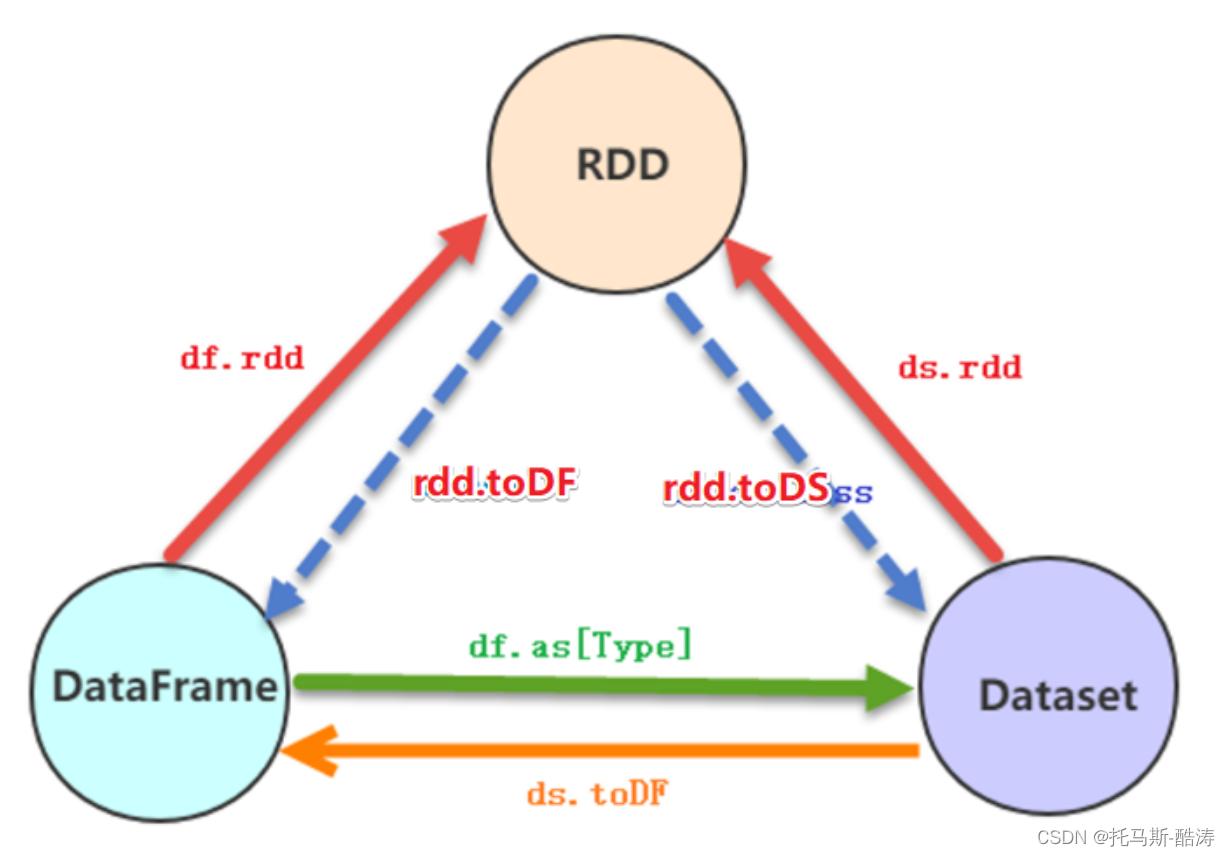
1)DF/DS转RDD
Val Rdd = DF/DS.rdd
2) DS/RDD转DF
import spark.implicits._
调用 toDF(就是把一行数据封装成row类型)
3)RDD转DS
将RDD的每一行封装成样例类,再调用toDS方法
4)DF转DS
根据row字段定义样例类,再调用asDS方法[样例类]
特别注意:在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用。