一、 train部分
1.1 总体框架(主要介绍detectron2框架)
执行train_net.py-->
args = default_argument_parser().parse_args()加载参数-->
launch函数判断是否为多gpu训练,从launch末尾进入train_net的main函数-->
main函数主要是读取参数,同时判断是否先进入test(不进入)。之后根据从trainer = Trainer(cfg)进入Trainer类,同样是理解读取参数,具体操作包括加载数据集,模型,优化器等,
之后回到main函数-->
根据return trainer.train()函数进入Trainer类里的train函数-->
从self.train函数进入train_net.py的self.train_loop函数(开始训练)-->
训练分为三部分,如下:
self.before_step()
self.run_step()
self.after_step()
其中,hook函数只放在before和after中,而run函数专门负责训练,即执行如下语句
self._trainer.run_step() #位于defaults.py第495行值得一提的是,根据公约,计算比较复杂的操作一般放在after_step()函数中,而不放在before_step中。
1.2 参数读取
训练所需参数读取自/AdelaiDet/configs/SOLOv2/R50_3x.yaml文件,同时这个文件还继承自/AdelaiDet/configs/SOLOv2/Base-SOLOv2.yaml文件。后者中与前者相同的信息会被前者覆盖。但是实际训练用到的参数远多于这些,这些没有在上文提及的参数取自文件/AdelaiDet/adet/config/defaults.py。
1.3 Trainer(cfg)部分
trainer=Trainer(cfg)是将定义在train_net.py的Trainer类实例化的过程。这个类是继承自DefaultTrainer类,又继承自TrainerBase类(这两个被集成的类都有__init__方法而Trainer类没有)。因此会先执行他们的__init__方法。
在DefaultTrainer(&TrainerBase)类的__init__方法会进行一些必要的操作,包括上文提到的,根据cfg加载数据集,模型,优化器,保存权重轮数,钩子等。如下:
def __init__(self, cfg):
"""
Args:
cfg (CfgNode):
"""
super().__init__()
logger = logging.getLogger("detectron2")
if not logger.isEnabledFor(logging.INFO): # setup_logger is not called for d2
setup_logger()
cfg = DefaultTrainer.auto_scale_workers(cfg, comm.get_world_size())
# Assume these objects must be constructed in this order.
model = self.build_model(cfg) # 得到SOLOV2的模型,搭积木核心
optimizer = self.build_optimizer(cfg, model) # 选择优化器
data_loader = self.build_train_loader(cfg) #数据加载器,保存了图片的信息。 训练时直接传入这三个参数即可
model = create_ddp_model(model, broadcast_buffers=False) #如果是多进程,则对model进行修改。这里默认是不修改(return model)
self._trainer = (AMPTrainer if cfg.SOLVER.AMP.ENABLED else SimpleTrainer)( #执行trainer的初始化,也就是run.step函数所在类的init部分
model, data_loader, optimizer
)
self.scheduler = self.build_lr_scheduler(cfg, optimizer) #从配置中调度lr程序。
self.checkpointer = DetectionCheckpointer(
# Assume you want to save checkpoints together with logs/statistics
model,
cfg.OUTPUT_DIR,
trainer=weakref.proxy(self),
)
# self.checkpointer.save("model_999")
self.start_iter = 0
self.max_iter = cfg.SOLVER.MAX_ITER #最大轮数
self.cfg = cfg
self.register_hooks(self.build_hooks())
Trainer(cfg)有几个值得一提的函数,接下来将详细介绍他们。
1.3.0 self.build_model(cfg)函数
这句话是读取参数的核心,用于构建模型。内容较多,之后在soloV2.py一节有详细阐述。
1.3.1 build_lr_scheduler函数
这个函数的意义是从配置中构建LR调度程序,语句如下:
self.scheduler = self.build_lr_scheduler(cfg, optimizer)这个函数定义在build.py,主要分为两部分。
1.3.1.1 sched = MultiStepParamScheduler函数
第一部分为sched = MultiStepParamScheduler()部分,这部分根据输入的各部分轮数(非base.yaml)得到了每部分的步长。在原版里,输入的是(210000,250000),270000(MAX),各部分间步长为1,0.1,0.01。(但我没在yaml文件中找到0.1的参数,可能是默认的)
sched = MultiStepParamScheduler( #得到每一段的步长。信息输入取自R50_3x.yaml配置文件。 文件中三个数210000,250000,270000,三段间步长分别为1,0.1,0.01 这个步长我没在yaml文件中找到,可能是默认的
values=[cfg.SOLVER.GAMMA ** k for k in range(len(steps) + 1)], # 每一段为0.1的n次方。n为段数,也就是1,0.1,0.01
milestones=steps,
num_updates=cfg.SOLVER.MAX_ITER,
)1.3.1.2sched = WarmupParamScheduler()函数
第二部分为sched = WarmupParamScheduler()部分,这部分根据输入的各部分预热轮数(base.yaml)得到了各预热部分的步长,并对sched进行修改(相当于把前面那一小点儿变为预热训练)。
class WarmupParamScheduler(CompositeParamScheduler):
"""
Add an initial warmup stage to another scheduler.
"""
def __init__(
self,
scheduler: ParamScheduler,
warmup_factor: float, #预热的初始值
warmup_length: float, #预热长度所占比例(乘以总长度即为预热长度)
warmup_method: str = "linear", #预热方法:线性
):
"""
Args:
scheduler: warmup will be added at the beginning of this scheduler
warmup_factor: the factor w.r.t the initial value of ``scheduler``, e.g. 0.001
warmup_length: the relative length (in [0, 1]) of warmup steps w.r.t the entire
training, e.g. 0.01
warmup_method: one of "linear" or "constant"
"""
end_value = scheduler(warmup_length) # 预热结束时步长(不确定是实际步长还是步长与正常步长比值)the value to reach when warmup ends
start_value = warmup_factor * scheduler(0.0) # 预热开始时步长
if warmup_method == "constant":
warmup = ConstantParamScheduler(start_value)
elif warmup_method == "linear":
warmup = LinearParamScheduler(start_value, end_value)
else:
raise ValueError("Unknown warmup method: {}".format(warmup_method))
super().__init__(
[warmup, scheduler],
interval_scaling=["rescaled", "fixed"],
lengths=[warmup_length, 1 - warmup_length],
)
1.3.2 register_hooks函数
DefaultTrainer类的__init__方法最后一句为登记钩子,即:
self.register_hooks(self.build_hooks())DefaultTrainer类有自己的build_hooks()方法,但我们在Trainer类中重写了这个方法,所以程序会执行我们重写的方法(但我们重写的这个方法有继承自原来的方法,所以从结果上看是两个方法都执行了)
在DefaultTrainer类中,程序默认注册了六个钩子,如下:
hooks.IterationTimer(), #计算花费时间并在训练结束时打印总结
hooks.LRScheduler(), #torch内置LR调度程序
hooks.PreciseBN(
# Run at the same freq as (but before) evaluation.
cfg.TEST.EVAL_PERIOD,
self.model,
# Build a new data loader to not affect training
self.build_train_loader(cfg),
cfg.TEST.PRECISE_BN.NUM_ITER,
) #据说和BN层有关,有啥关我没太看懂 每period执行一轮(但是默认不加载这个hook)
hooks.PeriodicCheckpointer(self.checkpointer, cfg.SOLVER.CHECKPOINT_PERIOD)
#定期保存检查点(权重) 每period(默认5000)执行一轮 或者大于等于所设置的最高轮数时保存
# 这里我为了方便观察先将5000改为了1000
hooks.EvalHook(cfg.TEST.EVAL_PERIOD, test_and_save_results)
#定期进行评价每period(默认0轮,即不执行)执行一轮
hooks.PeriodicWriter(self.bu,ld_writers(), period=20)
#定期将事件写入EventStorage 就是输出的loss等信息(调用write.write函数)
#每period(默认20轮)输出一次信息1.4 run_step部分
这一部分对应4.1.1中提到的语句
def run_step(self):
self._trainer.iter = self.iter
self._trainer.run_step() #位于defaults.py第495行其核心语句self._trainer.run_step()如下
def run_step(self):
"""
Implement the standard training logic described above.
"""
assert self.model.training, "[SimpleTrainer] model was changed to eval mode!"
#判断是否处于training模式,否则输出: "[SimpleTrainer] model was changed to eval mode!"
start = time.perf_counter()
"""
If you want to do something with the data, you can wrap the dataloader.
"""
data = next(self._data_loader_iter) #得到图片信息(路径,长宽,像素信息等)
data_time = time.perf_counter() - start
"""
If you want to do something with the losses, you can wrap the model.
"""
loss_dict = self.model(data) #得到loss
if isinstance(loss_dict, torch.Tensor):
losses = loss_dict
loss_dict = {"total_loss": loss_dict}
else:
losses = sum(loss_dict.values())
"""
If you need to accumulate gradients or do something similar, you can
wrap the optimizer with your custom `zero_grad()` method.
"""
self.optimizer.zero_grad() #清空原梯度
losses.backward() # 反向传播
self._write_metrics(loss_dict, data_time) #输出loss信息
"""
If you need gradient clipping/scaling or other processing, you can
wrap the optimizer with your custom `step()` method. But it is
suboptimal as explained in https://arxiv.org/abs/2006.15704 Sec 3.2.4
"""
self.optimizer.step()二、solov2.py
2.1 流程框图
放上一位大佬绘制的流程框图(红笔为笔者写的注释):
其中backbone包括resnet部分和FPN部分。结束时输出FPN的五层。
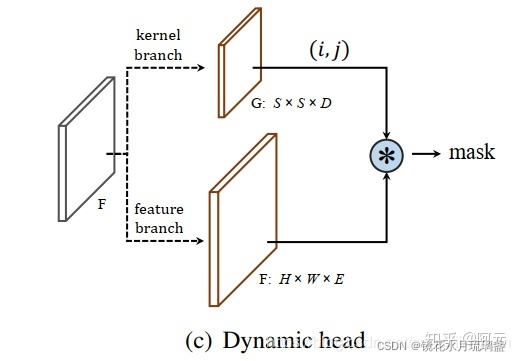
其中, E是输入特征的通道数。
这里对产生mask的卷积进行一下解释
"""手动定义卷积核(weight)和偏置"""
w = torch.rand(16, 3, 5, 5) # 16种3通道的5乘5卷积核
b = torch.rand(16) # 和卷积核种类数保持一致(不同通道共用一个bias)
"""定义输入样本"""
x = torch.randn(1, 3, 28, 28) # 1张3通道的28乘28的图像
"""2D卷积得到输出"""
out = F.conv2d(x, w, b, stride=1, padding=1) # 步长为1,外加1圈padding,即上下左右各补了1圈的0,
首先是特征图F(H×W×E),这里指的是一张E通道(也就是特征图厚度为E)的,大小为H×W的特征图。
然后是卷积核,这里可以理解为有S^2种卷积核,每个卷积核都在全图进行卷积,卷积生成一个H×W的掩码图。这个卷积核的输入是卷积核感受野×特征图厚度。比如卷积核的感受野是3×3,那该卷积核在每个位置输入的值一共有3×3×E这么多。这样,输出的结果就是S^2×H×W.
参考文献:F.conv2d pytorch卷积计算_wanghua609的博客-CSDN博客_f.conv2d
下图三条支路从左到右分别对应kernel预测(卷积核),cate预测(类别)和mask预测(实例)。

训练过程中分支分为ins分支和mask分支,ins分支得到的是kernel预测和cate预测,mask分支得到的是mask预测(而在loss输入里,又把mask预测看做ins预测)(注意,ins分支和ins预测没有任何关系)
最终cate预测得到类别信息(loss_cate),kernel预测和mask预测(即mask预测得到特征图,经过kernel一次卷积得到结果)共同得到掩码信息(loss_ins)
参考文献:
solov2网络结构图_Jumi爱笑笑的博客-CSDN博客_solov2网络结构
2.2 具体流程
在solov2.py中,一共定义了三个类,分别是SOLOv2,SOLOv2InsHead,SOLOv2MaskHead。其中SOLOV2类内容较多,包括损失函数等。而其余两类只有__init__方法和forward方法。接下来将他们三个的介绍分别写在三个小节里(2.3-2.5)。具体的运算,难点等将在各自的模块中提及。本小节只负责介绍在训练过程中数据流动的总体流程,并简要概括一些操作。
2.2.1 __init__部分
在执行1.3.0 self.build_model(cfg)函数时,会对SOLOv2类进行初始化(__init__)操作。具体各参数的注释写在了代码上。 其通过
self.backbone = build_backbone(cfg)函数构建主干网络 。
在初始化solov2类的过程中,有如下几行代码
# build the ins head.
instance_shapes = [backbone_shape[f] for f in self.instance_in_features]
self.ins_head = SOLOv2InsHead(cfg, instance_shapes)
# build the mask head.
mask_shapes = [backbone_shape[f] for f in self.mask_in_features]
self.mask_head = SOLOv2MaskHead(cfg, mask_shapes)在调用他们的过程中,同时对剩下两个类SOLOv2InsHead和SOLOv2MaskHead进行了初始化。
2.2.2 SOLOV2.forward部分
之后程序一直没有走进solov2.py,直到执行到函数1.4 run_step时,标志着训练正式开始。此时步入SOLOV2类的forward方法。
第一步:对图像进行预处理,即执行如下语句:
images = self.preprocess_image(batched_inputs)其中,输入的batched_inputs包括了图片全部信息,而images是一个元素为tensor的list。通过此方法得到了图片预处理(包括归一化,转化均值方差等操作)过后的像素信息。
第二步:通过如下语句:
if "instances" in batched_inputs[0]:
gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
elif "targets" in batched_inputs[0]:
log_first_n(
logging.WARN, "'targets' in the model inputs is now renamed to 'instances'!", n=10
)
gt_instances = [x["targets"].to(self.device) for x in batched_inputs]
else:
gt_instances = None将图片的标注信息(如类别,gt框等)保存到gt_instances中。
第三步:通过如下语句得到p2-p6五个头
features = self.backbone(images.tensor)第四步:ins分支(其实是cate和kernel部分)
ins分支执行如下语句
# ins branch
ins_features = [features[f] for f in self.instance_in_features]
ins_features = self.split_feats(ins_features)
cate_pred, kernel_pred = self.ins_head(ins_features)通过函数self.split_feats()对FPN得到的五层中最上层进行下采样,最下层进行上采样,如下(不同图片尺寸对应数据可能不同):
( 1,256,176,240)-->( 1,256,88,120)
( 1,256,88,120)-->( 1,256,88,120)
( 1,256,44,60)-->( 1,256,44,60)
( 1,256,22,30)-->( 1,256,22,30)
( 1,256,11,15)-->( 1,256,22,30)
然后通过self.ins_head()语句得到对种类(cate)和卷积核(kernel)的预测(详见2.3.2 )
第五步:mask分支
mask分支执行如下语句
# mask branch
mask_features = [features[f] for f in self.mask_in_features]
mask_pred = self.mask_head(mask_features)通过self.mask_head得到对掩码(mask)的预测(详见2.4.2 )
第六步:判断模型是训练还是评价。如果是训练则计算损失函数并返回loss(详见2.5 ),如果是评价则进行inference并返回result(详见2.6)。
2.3 class:SOLOv2InsHead
2.3.1 SOLOv2MaskHead.__init__方法
这里__init__方法的作用就是构建网络。在调用__init__ 方法时,用到了如下语句
head_configs = {"cate": (cfg.MODEL.SOLOV2.NUM_INSTANCE_CONVS, #创建一个字典
cfg.MODEL.SOLOV2.USE_DCN_IN_INSTANCE,
False),
"kernel": (cfg.MODEL.SOLOV2.NUM_INSTANCE_CONVS,
cfg.MODEL.SOLOV2.USE_DCN_IN_INSTANCE,
cfg.MODEL.SOLOV2.USE_COORD_CONV)
}创造了一个字典。在之后又用了如下语句
for head in head_configs:为两个分支(cate和kernel)添加卷积层。添加的结果如下
cate:256-->512-->512-->512-->80 kernel:258-->512-->512-->512-->256 (这里的258应该是256后面加入了xy坐标)
之后都是些辅助性步骤,对初始权重进行填充。构建出的网络如下(应该分别对应上图的中间支路和左支路)
SOLOv2InsHead(
(cate_tower): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 512, eps=1e-05, affine=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): GroupNorm(32, 512, eps=1e-05, affine=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): GroupNorm(32, 512, eps=1e-05, affine=True)
(8): ReLU(inplace=True)
(9): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): GroupNorm(32, 512, eps=1e-05, affine=True)
(11): ReLU(inplace=True)
)
(kernel_tower): Sequential(
(0): Conv2d(258, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 512, eps=1e-05, affine=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): GroupNorm(32, 512, eps=1e-05, affine=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): GroupNorm(32, 512, eps=1e-05, affine=True)
(8): ReLU(inplace=True)
(9): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): GroupNorm(32, 512, eps=1e-05, affine=True)
(11): ReLU(inplace=True)
)
(cate_pred): Conv2d(512, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(kernel_pred): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
2.3.2 SOLOv2InsHead.forward方法
从2.2.2 第四步 ins分支导入。方法都比较简单,每一步注释都写在后面了:
def forward(self, features):
"""
Arguments:
features (list[Tensor]): FPN feature map tensors in high to low resolution.
Each tensor in the list correspond to different feature levels.
Returns:
pass
"""
cate_pred = []
kernel_pred = []
for idx, feature in enumerate(features): # feature返回每个元素,idx返回每个元素的索引
ins_kernel_feat = feature
# concat coord
x_range = torch.linspace(-1, 1, ins_kernel_feat.shape[-1], device=ins_kernel_feat.device) #等间距生成从-1到1的120个数(即对应层宽度)
y_range = torch.linspace(-1, 1, ins_kernel_feat.shape[-2], device=ins_kernel_feat.device) #等间距生成从-1到1的88个数(即对应层高度)
y, x = torch.meshgrid(y_range, x_range) #用于划分单元网格,生成shape为(88,120),各行列分别被二者(y_range, x_range)对应元素填充的tensor 参考文献:https://blog.csdn.net/weixin_39504171/article/details/106356977
y = y.expand([ins_kernel_feat.shape[0], 1, -1, -1])
x = x.expand([ins_kernel_feat.shape[0], 1, -1, -1]) # 在最前面加两个一维,即(88,120)->(1,1,88,120)
coord_feat = torch.cat([x, y], 1) # (1,1,88,120)-->(1,2,88,120)
ins_kernel_feat = torch.cat([ins_kernel_feat, coord_feat], 1)# (1,1,88,120)-->(1,258,88,120) 这一段的作用就是将坐标xy添加到最后两个通道
# individual feature.
kernel_feat = ins_kernel_feat
seg_num_grid = self.num_grids[idx] #self.num_grids是一个列表,这里根据idx索引找到列表对应元素 应该是对不同层设置的grid个数
kernel_feat = F.interpolate(kernel_feat, size=seg_num_grid, mode='bilinear') #双线性插值,(1,1,88,120)-->(1,1,40,40)
cate_feat = kernel_feat[:, :-2, :, :] #抓出前256维,即(1,256,40,40)
# kernel
kernel_feat = self.kernel_tower(kernel_feat)
kernel_pred.append(self.kernel_pred(kernel_feat)) #执行针对kernel的卷积并保存结果
# cate
cate_feat = self.cate_tower(cate_feat)
cate_pred.append(self.cate_pred(cate_feat)) #执行针对cate的卷积并保存结果
return cate_pred, kernel_pred2.4 class:SOLOv2MaskHead
2.3.1 SOLOv2MaskHead. __init__方法
类似的,这里只用到了P2-P5四层,通过如下代码段构建神经网络层
for i in range(self.num_levels): 这里一共两个循环(i,j),创建了三个存储神经网络的列表,分别是
conv_tower:每个小循环刷新 (list类型) convs_per_level:每个大循环刷新 (sequential类型) self.convs_all_levels:不刷新 (modulelist类型)(最终保存的)
j循环比i循环小1;
当i=0时或j=0时,都进行一些相对特殊的操作;
此外,当i=3时,输入通道+2。
总之,通过这段代码构建出了如下网络(应该对应上图最右支路)
ModuleList(
(0): Sequential(
(conv0): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
)
(1): Sequential(
(conv0): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
(upsample0): Upsample(scale_factor=2.0, mode=bilinear)
)
(2): Sequential(
(conv0): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
(upsample0): Upsample(scale_factor=2.0, mode=bilinear)
(conv1): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
(upsample1): Upsample(scale_factor=2.0, mode=bilinear)
)
(3): Sequential(
(conv0): Sequential(
(0): Conv2d(258, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
(upsample0): Upsample(scale_factor=2.0, mode=bilinear)
(conv1): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
(upsample1): Upsample(scale_factor=2.0, mode=bilinear)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): GroupNorm(32, 128, eps=1e-05, affine=True)
(2): ReLU()
)
(upsample2): Upsample(scale_factor=2.0, mode=bilinear)
)
)
2.5.2 SOLOv2MaskHead.forward方法
从2.2.2 第五步 mask分支导入。
如上图所说,先对FPN输出的前四层各自卷积,并上采样到跟第一层一样的大小(1,128,176,240)然后相加(应该是对应元素相加,不是concat) 。
def forward(self, features):
"""
Arguments:
features (list[Tensor]): FPN feature map tensors in high to low resolution.
Each tensor in the list correspond to different feature levels.
Returns:
pass
"""
assert len(features) == self.num_levels, \
print("The number of input features should be equal to the supposed level.")
# bottom features first.,对FPN输出的前四层各自卷积,并上采样到跟第一层一样的大小(1,128,176,240)然后相加(应该是对应元素相加,不是concat)
feature_add_all_level = self.convs_all_levels[0](features[0]) # 第一层初始(1,256,176,240) 注意这里和ins分支不同,因为没有经过spilt_feats的下采样
for i in range(1, self.num_levels): # 2-4层初始分别为(...,88,120,(...,44,60),(...,22,30)
mask_feat = features[i] # 值得一提的是,第四层卷积前还加入了xy两个通道(第四层设计的卷积输入本来就是258,不影响输出),
if i == 3: # add for coord.
x_range = torch.linspace(-1, 1, mask_feat.shape[-1], device=mask_feat.device)
y_range = torch.linspace(-1, 1, mask_feat.shape[-2], device=mask_feat.device)
y, x = torch.meshgrid(y_range, x_range)
y = y.expand([mask_feat.shape[0], 1, -1, -1])
x = x.expand([mask_feat.shape[0], 1, -1, -1])
coord_feat = torch.cat([x, y], 1)
mask_feat = torch.cat([mask_feat, coord_feat], 1)
# add for top features.
feature_add_all_level += self.convs_all_levels[i](mask_feat)
mask_pred = self.conv_pred(feature_add_all_level)
return mask_pred2.5 training分支
如果是training模式,则执行如下代码
if self.training:
"""
get_ground_truth.
return loss and so on.
"""
mask_feat_size = mask_pred.size()[-2:] #得到mask分支中图片大小(就是P2的后两维)(仅仅是两个数)
targets = self.get_ground_truth(gt_instances, mask_feat_size)
losses = self.loss(cate_pred, kernel_pred, mask_pred, targets)
return losses通过函数self.get_ground_truth()可以返回实例gt框相关信息的列表。但该函数本质是一个循环执行函数get_ground_truth_single()的过程。
2.5.1 get_ground_truth()函数
该函数有如下几个循环:
大循环:对get_ground_truth_single()函数进行循环,就是对该batch中每张图片进行循环
for img_idx in range(len(gt_instances)): #len(gt_instances)) == batch_size二循环:对FPN输出的所有头(不同尺度)进行循环。
for (lower_bound, upper_bound), stride, num_grid \
in zip(self.scale_ranges, self.strides, self.num_grids): #二循环:对FPN输出的所有头(不同尺度)进行循环。三循环:对所有grid进行循环。
for seg_mask, gt_label, half_h, half_w, center_h, center_w, valid_mask_flag in zip(gt_masks, gt_labels, half_hs, half_ws, center_hs, center_ws, valid_mask_flags): #三循环:对每个独立的实例进行循环。四循环:对每个格子进行循环
for i in range(top, down+1):
for j in range(left, right+1): #对所有负责预测该格子的grid进行一次循环2.5.2 loss() 函数
这里先说明以下代码解读中“学习卷积核”的意思。其本质就是让训练输出的结果有两部分(对应上图左右支路)。第一部分为卷积核(kernel),第二部分为特征图(256层的特征图)。然后计算loss时,用卷积核对特征图进行卷积,就会得到预测结果。在将预测结果和实际样本进行diss_loss,从而得到loss(本来loss的范围应该是0到1,之后乘了一个权重3,所以跑飞了的时候显示的是3)。
2.6 test分支
执行train_net.py-->
args = default_argument_parser().parse_args()加载参数-->
launch函数判断是否为多gpu训练,从launch末尾进入train_net的main函数-->
main函数主要是读取参数,同时判断是否先进入test(进入)-->
通过Trainer.build_model函数加载被评价的model信息和超参数信息(比如各个层是干什么的,不包括加载权重参数weights)-->
通过AdetCheckpointer函数向model加载权重信息-->
之后由main函数进入python3.7/site-packages/detectron2/engine/defaults.py的test函数,根据输入的model,cfg和评价器类型(默认NONE)进行评价-->
如果评价器为NONE,则会进入train_net.py的build_evaluatior函数帮你构建评价器。这个函数会根据你在builtin中的注册,来选择合适的评价器(所以千万不要注册错)
之后进入detectron2/evalution/evaluator.py的inference_on_dataset函数,通过model函数运行得到分割结果并进入评价阶段-->
评价阶段用的是evaluator.process(inputs, outputs) 函数,定义在adet/evalution/text_evaluation.py中。其中input是原照片的信息,output是预测分割的结果(为什么没有原图分割信息?)-->
之后从这个函数进入同py文件中的instances_to_coco_json函数。这个函数作用应该是理解得到的参数。但是会报bug3.2.2。因为
三、主干网络
由于主干网络为resnet网络,比较复杂,因此这里单独开一个章节讲解。
3.1 主干网络流程
主干网络为resnet网络,通过文件/home/luoxinhao/anaconda3/envs/AdelaiDet-master/lib/python3.7/site-packages/detectron2/modeling/backbone/resnet.py进行构建
执行过程如下
build_resnet_backbone(cfg, input_shape)-->(进入build.py)build_backbone()-->backbone = BACKBONE_REGISTRY.get(backbone_name)(cfg, input_shape)-->(进入fpn.py)build_resnet_fpn_backbone()-->(进入resnet.py)bottom_up = build_resnet_backbone(cfg, input_shape)(此处开始着重讲解)-->build_backbone(cfg, input_shape=None)-->分别执行:
class BasicStem(CNNBlockBase)(得到stem)在一个for循环里反复构造BottleneckBlock(本质双循环)
class BottleneckBlock(CNNBlockBase)(得到核心组件,反复执行,通过调用ResNet.make_stage) (将上述两个组件传入ResNet类)-->class ResNet(Backbone):其他一些操作
3.2BottkeneckBlock内容:
一个bottleBlock包含的内容如下(括号内是名字,括号后是操作):
[BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)]其中shortcut部分有可能会有(每个res的第一个BottleneckBlock会有),res2-res5各自有(3,4,6,3)个这样的模块。这个在前面有定义
3.2构造方法:
进入BottleneckBlock类,然后分别定义shortcut,conv,conv2,conv3即可
最后进入resnet类将大家封装到一起
四、数据读取
数据加载通过train_net.py的这一行代码实现
def build_train_loader(cls, cfg): #为语义掩码添加分类标签,默认为false,作用不清楚
"""
Returns:
iterable
为语义掩码添加分类标签
It calls :func:`detectron2.data.build_detection_train_loader` with a customized
DatasetMapper, which adds categorical labels as a semantic mask.
"""
if cfg.MODEL.FCPOSE_ON:
mapper = FCPoseDatasetMapper(cfg, True)
else:
mapper = DatasetMapperWithBasis(cfg, True)
return build_detection_train_loader(cfg, mapper=mapper)
这里有一个if判断分支。接下来研究这个分支是干什么的
else路线:
if路线
看起来二者并么有什么区别
我先执行了else文件,写好注释,然后强行让他走if路线(FCpose)
源代码:
self.fcpose_on = cfg.MODEL.FCPOSE_ON
if self.fcpose_on:
self.gt_heatmap_stride = cfg.MODEL.FCPOSE.GT_HEATMAP_STRIDE
self.sigma = cfg.MODEL.FCPOSE.HEATMAP_SIGMA
self.head_sigma = cfg.MODEL.FCPOSE.HEAD_HEATMAP_SIGMA
self.HeatmapGenerator = HeatmapGenerator(17, self.sigma, self.head_sigma)目前执行进入这个分支之后,调试卡住,运行会报错没有keypoints
直接修改config/defaults.py,341行
_C.MODEL.FCPOSE_ON = True同样报错
推测 _C.MODEL.FCPOSE_ON = True分支需要手工打关键点来辅助收敛,而且是多物体识别时用于分开多个物体的(类似iou),这里放弃。
五、demo.py
执行demo.py-->
在90行执行run_on_image()函数(demo.py)-->
执行该函数中的predictions = self.predictor(image)函数(predictor.py)-->
执行该函数中的predictions = self.model([inputs])[0]函数(default.py)-->
执行该函数中的results = self.inference函数(solov2.py)-->
执行该函数中的result = self.inference_single_image函数(solov2.py)-->