
MySQL备份原理
数据备份是数据安全的底线,在任何场景下面,无论是上线后的数据回滚,数据丢失都能够有效的止损,将损失降到最低程度。
衡量数据备份与恢复的两个重要指标:
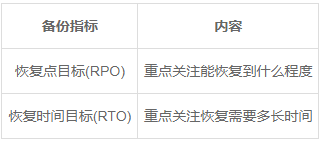
对于MySQL备份主要分为以下两种:

热备又分为两种:

快照备份:LVM使用写时复制(copy-on-write)技术来创建快照

例如对整个卷的某个瞬时的逻辑副本,类似于数据库中的innodb存储引擎的MVCC,只不过LVM的快照在文件系统层面,而MVCC在数据库层面,而且仅仅支持innodb存储引擎。
LVM有一个快照预留区域,如果原始数据有变化时,LVM保证在任何变更写入之前会复制受影响块到快照预留区域。
简单来说,快照区域内保存了快照开始时候的一致的所有old数据,对于更新很少的数据库,快照也会非常小。
对于MySQL而言,为了使用快照备份,需要将数据文件,日志文件都存放在一个逻辑卷中,然后对该卷做备份即可。

快照备份更偏向于对误操作防范,可以将数据库迅速恢复到快照产生的时间点,然后结合二进制日志可以恢复到指定的时间点。
逻辑备份
冷备份和快照备份由于其弊端在生产环境很少使用,使用更多的是MySQL自带的逻辑备份工具和物理备份工具。
MySQL官方虽然通过了MySQLdump逻辑备份工具,虽然已经足够用了,但是存在单线程备份慢的问题。
在社区提供了更加优秀的逻辑备份工具mysqldumper,它的优势主要体现在多线程备份,备份的速度更加快。
mysqldump工具
MySQLdump备份不得不提的两个关键参数
--single-transcation
--master-data=2
--master-data=2,--master-data=1 默认的话会--lock-all-tables,会锁住整个mysql数据库中的所有表。但是如果加上--single-transaction会加上事务,不会锁表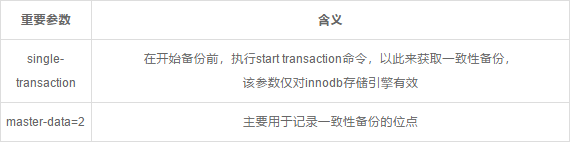
在mysqldump过程中,之前其实一直不是很理解为什么加了--single-transaction就能保证innodb的数据是完全一致的,而myisam引擎无法保证,必须加--lock-all-tables,前段时间抽空详细地查看了整个mysqldump过程。
理解master-data和--dump-slave
--master-data=2表示在dump过程中记录主库的binlog和pos点,并在dump文件中注释掉这一行;
--master-data=1表示在dump过程中记录主库的binlog和pos点,并在dump文件中不注释掉这一行,即恢复时会执行;
--dump-slave=2表示在dump过程中,在从库dump,mysqldump进程也要在从库执行,记录当时主库的binlog和pos点,并在dump文件中注释掉这一行;
--dump-slave=1表示在dump过程中,在从库dump,mysqldump进程也要在从库执行,记录当时主库的binlog和pos点,并在dump文件中不注释掉这一行;
注意:在从库上执行备份时,即--dump-slave=2,这时整个dump过程都是stop io_thread的状态
关于mysqldump工作原理
一定要区别对待事务表innodb和非事务表myisam,因为备份流程与此息息相关。
注意:即使到目前为止,我们所有业务使用的表都是innodb,我们也无法规避myisam表,因为MySQL库中的系统表仍然采用的是myisam表。
备份流程如下:
1.调用FWRL(flush tables with read lock),全局禁止读写
2.开启快照读,获取此期间的快照(仅仅对innodb起作用)
3.备份非innodb表数据(*.frm,*.myi,*.myd等)
4.非innodb表备份完毕之后,释放FTWRL
5.逐一备份innodb表数据
6.备份完成整个过程如图:

MySQLdump 备份时如何保持数据的一致性( –single-transaction)
打开general_log
mysql> set global general_log=on;
mysql> show variables like '%general_log_file%';
+------------------+------------------------------+
| Variable_name | Value |
+------------------+------------------------------+
| general_log_file | /var/lib/mysql/localhost.log |
+------------------+------------------------------+打开general_log,开启备份,添加--single-transaction和--master-data=2参数,查看general_log,信息如下,每一步添加了我的理解 (此选项会将隔离级别设置为:REPEATABLE READ。并且随后再执行一条START TRANSACTION语句,让整个数据在dump过程中保证数据的一致性,这个选项对InnoDB的数据表很有用,且不会锁表)
备份整个库
[root@localhost backup]# mysqldump -uroot -proot -h127.0.0.1 --all-databases --single-transaction --routines --events --triggers --master-data=2 --hex-blob --default-character-set=utf8mb4 --flush-logs --quick > all.sql
mysqldump: [Warning] Using a password on the command line interface can be insecure.查看日志信息
[root@localhost ~]# tail -f /var/lib/mysql/localhost.log
2020-06-20T06:27:31.809852Z 5 Connect root@localhost on using SSL/TLS
2020-06-20T06:27:31.811401Z 5 Query /*!40100 SET @@SQL_MODE='' */
2020-06-20T06:27:31.812146Z 5 Query /*!40103 SET TIME_ZONE='+00:00' */
2020-06-20T06:27:31.812605Z 5 Query FLUSH /*!40101 LOCAL */ TABLES
2020-06-20T06:27:31.821019Z 5 Query FLUSH TABLES WITH READ LOCK
#批注:因为开启了--master-data=2,这时就需要flush tables with read lock锁住全库,记录当时的
#master_log_file和master_log_pos点
2020-06-20T06:27:31.821587Z 5 Refresh
/usr/sbin/mysqld, Version: 5.7.30-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /var/lib/mysql/mysql.sock
Time Id Command Argument
2020-06-20T06:27:31.827045Z 5 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
#批注:--single-transaction参数的作用,设置事务的隔离级别为可重复读,即REPEATABLE READ,这样能保证在一个事务中所有相同的查询读取到同样的数据,也就大概保证了在dump期间,如果其他innodb引擎的线程修改了表的数据并提交,对该dump线程的数据并无影响,然而这个还不够,还需要看下一条
2020-06-20T06:27:31.827934Z 5 Query START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */
#这时开启一个事务,并且设置WITH CONSISTENT SNAPSHOT为快照级别
想象一下,如果只是可重复读,那么在事务开始时还没dump数据时,这时其他线程修改并提交了数据,那么这时第一次查询得到的结果是其他线程提交后的结果
而WITH CONSISTENT SNAPSHOT能够保证在事务开启的时候,第一次查询的结果就是事务开始时的数据A,即使这时其他线程将其数据修改为B,查的结果依然是A总结如下
MySQLdump 对不同类型的存储引擎,内部实现也不一样。主要是针对两种类型的存储引擎:支持事务的存储引擎(如 InnoDB )和不支持事务的存储引擎(如 MyISAM ),下面分别看看这两种存储引擎的实现:
1 、对于支持事务的引擎如 InnoDB , 参数上是在备份的时候加上 –single-transaction 保证数据一致性
–single-transaction 实际上通过做了下面两个操作 :
① 在开始的时候把该 session 的事务隔离级别设置成 repeatable read ;
② 然后启动一个事务(执行 begin ),备份结束的时候结束该事务(执行 commit )
有了这两个操作,在备份过程中,该 session 读到的数据都是启动备份时的数据(同一个点)。可以理解为对于 innodb 引擎来说加了该参数,备份开始时就已经把要备份的数据定下来了,备份过程中的提交的事务时是看不到的,也不会备份进去。
2 、对于不支持事务的引擎如 MyISAM ,只能通过锁表来保证数据一致性,这里分三种情况:
① 导出全库 : 加 –lock-all-tables 参数 , 这会在备份开始的时候启动一个全局读锁 ( 执行 flush tables with read lock ), 其他 session 可以读取但不能更新数据 , 备份过程中数据没有变化 , 所以最终得到的数据肯定是完全一致的 ;
② 导出单个库:加 –lock-tables 参数,这会在备份开始的时候锁该库的所有表,其他 session 可以读但不能更新该库的所有表,该库的数据一致;