入站须知
一.个人博客简介
项目地址:http://www.tcefrep.site/ (源码地址在本文末尾),感谢阿里云爸爸,送了一个两个月的2核4g的服务器,现在搜索模块也用上了elasticsearch,https://github.com/asiL-tcefreP,源码在此,觉得项目不错就star一下吧
1.1 博客主要页面:
1.1.1 首页

1.1.2 分类页
1.1.3 分类页
1.1.4 归档页
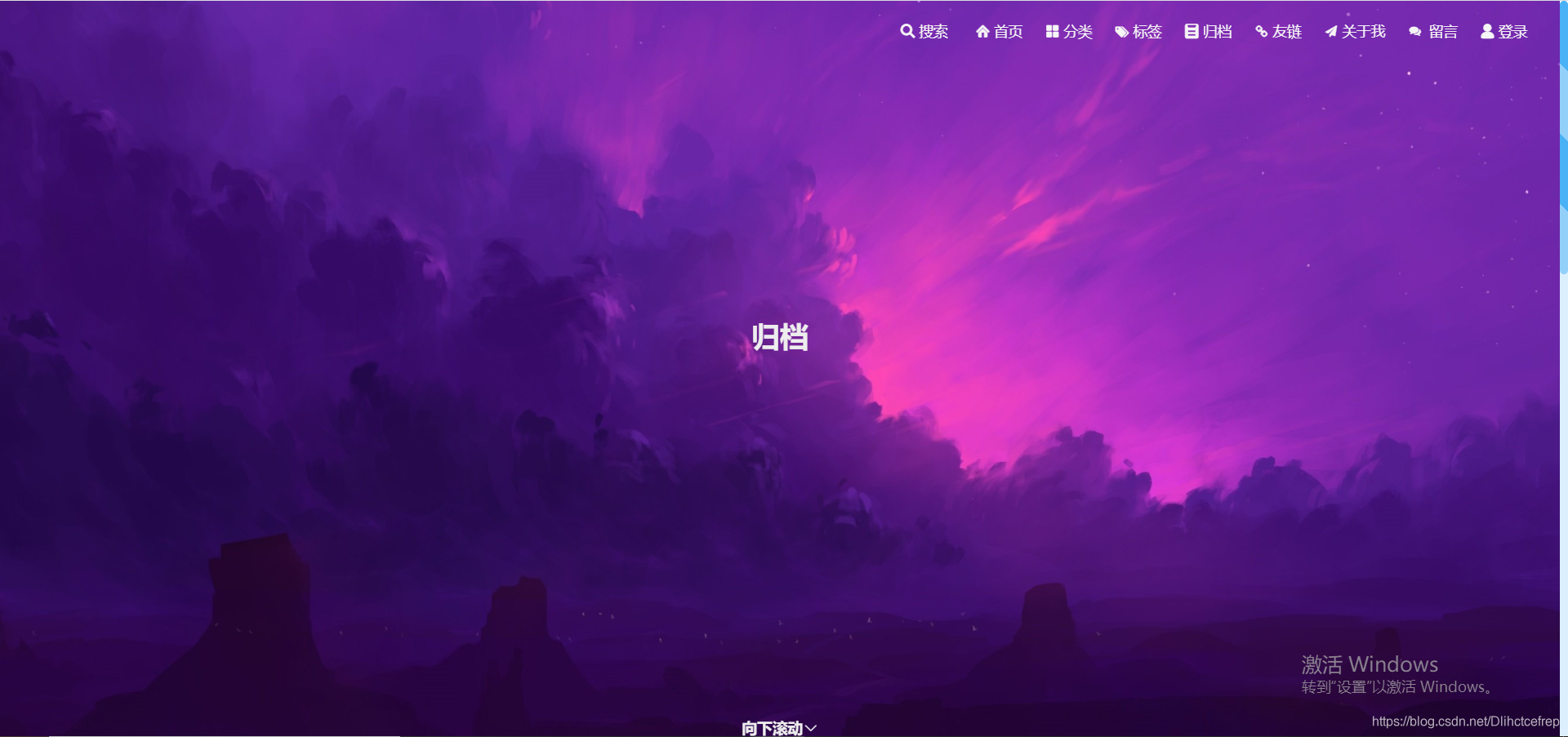

1.1.5 友链页

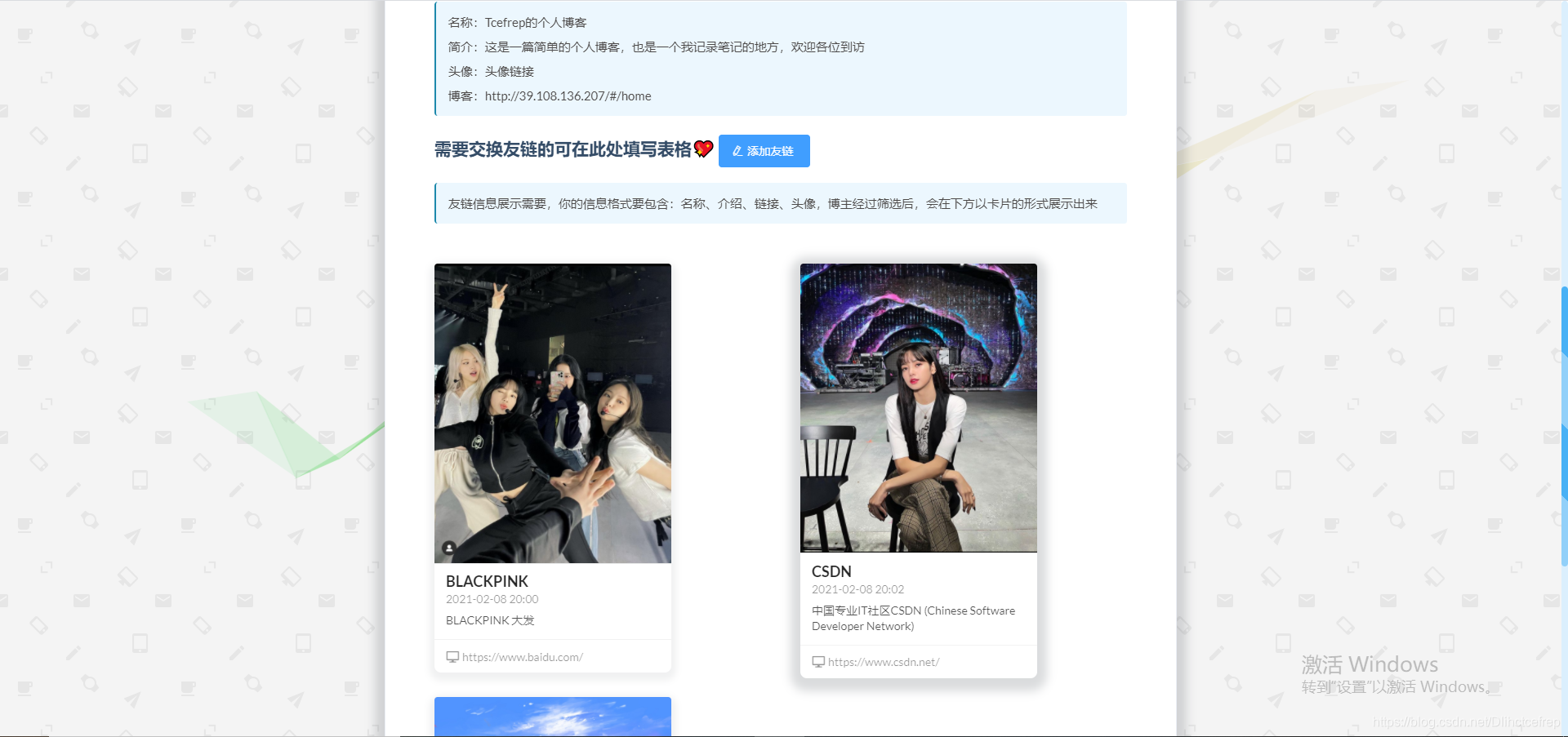
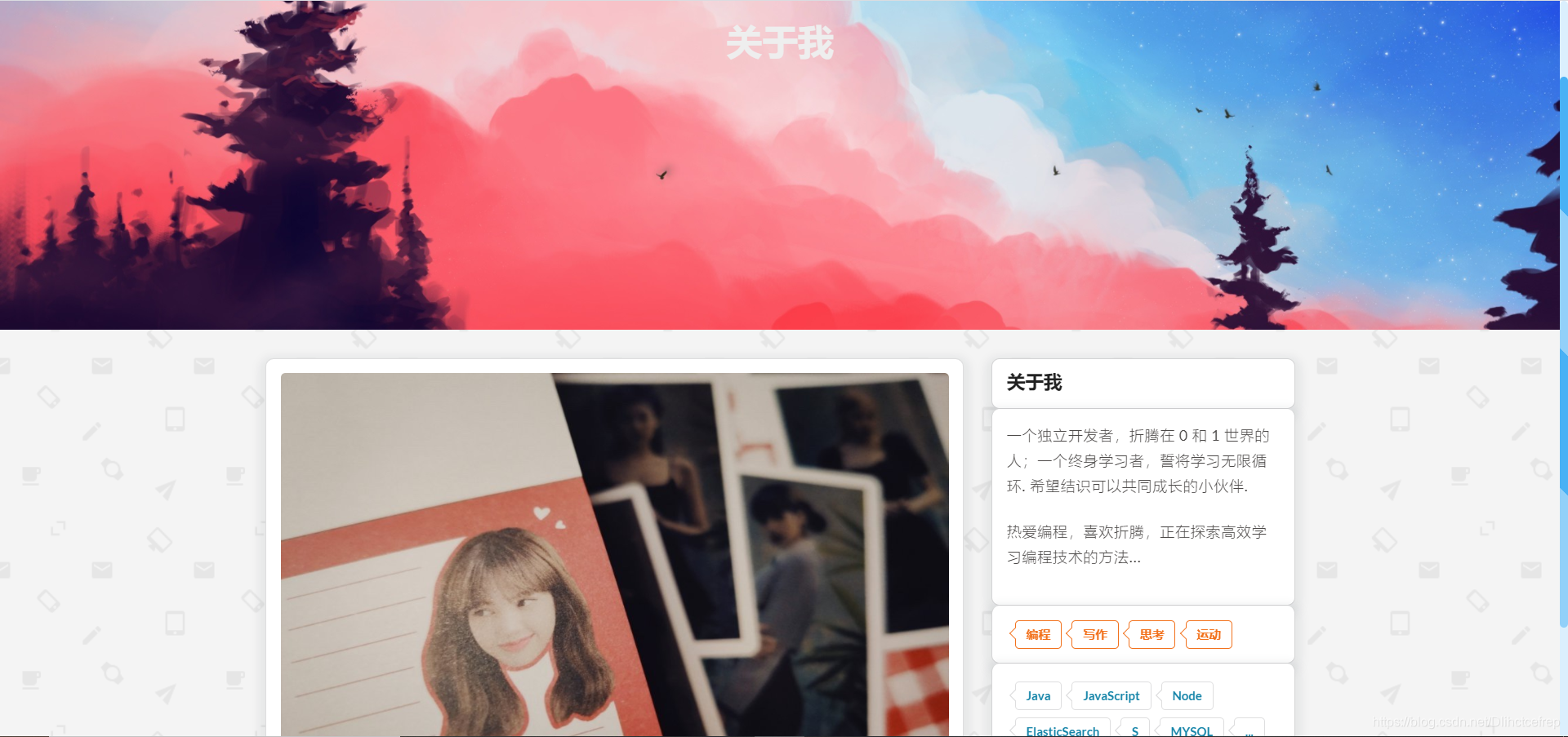
1.1.6 关于我
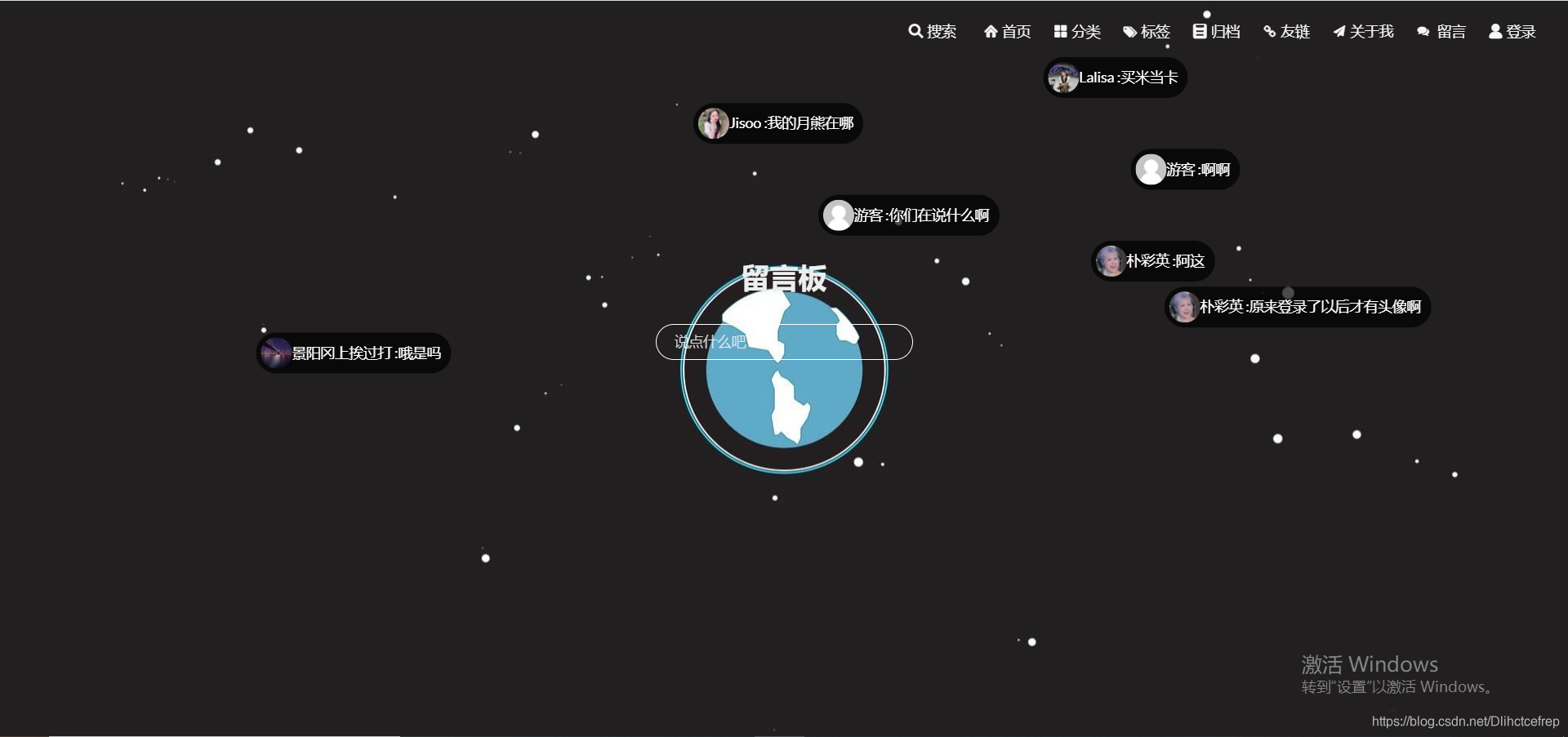
1.1.7 留言页面

1.1.8 登录页面

1.1.9 博客详情页面
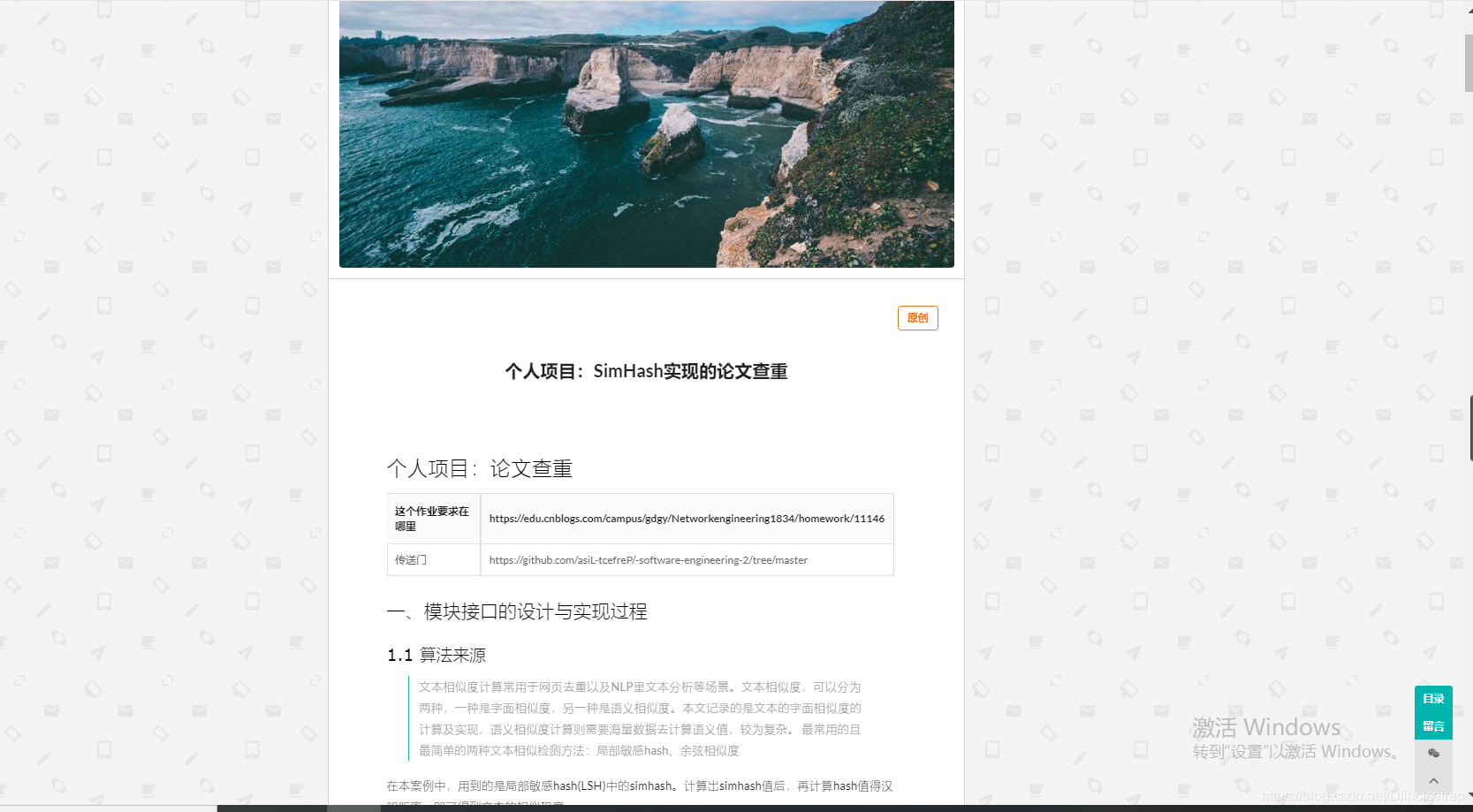
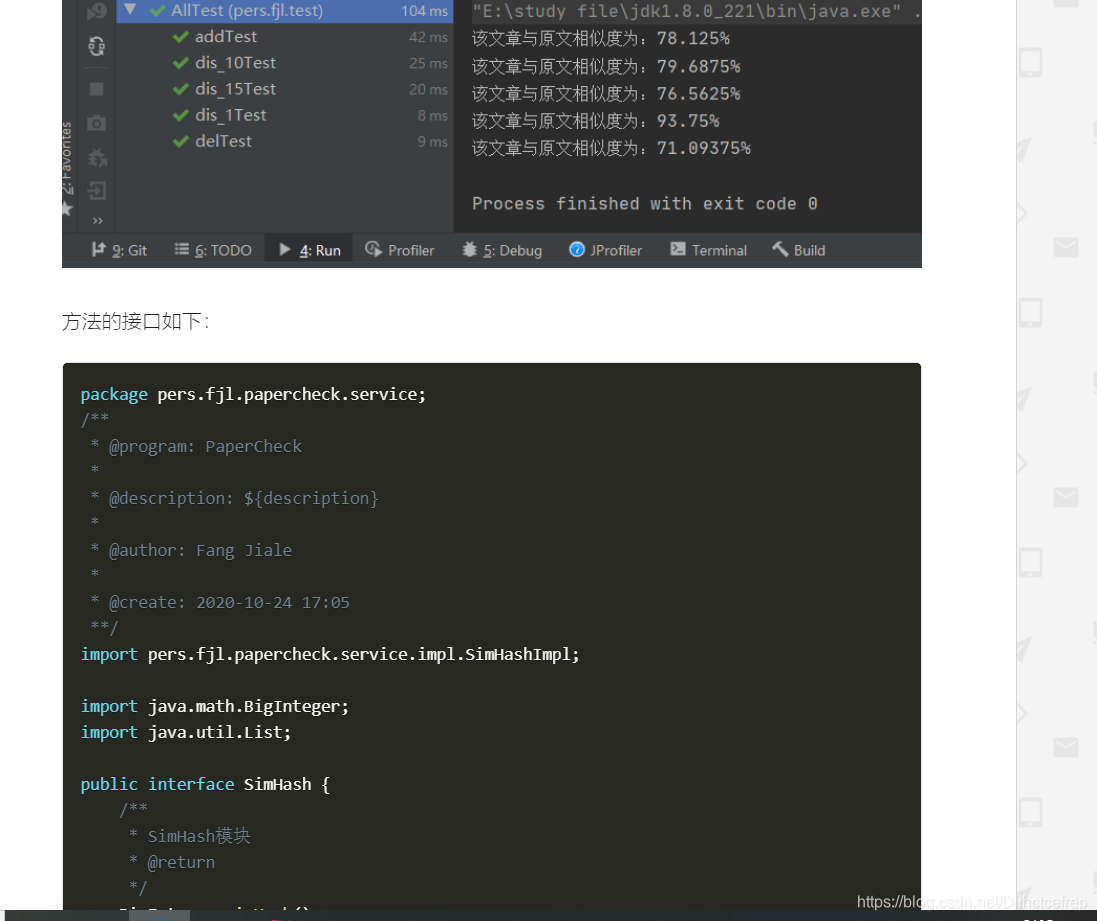
1.1.10 爬虫页面
从csdn爬取了三千篇文章放到数据库做文本分类的训练集,仅做学习使用。
1.1.11 AI模块页面
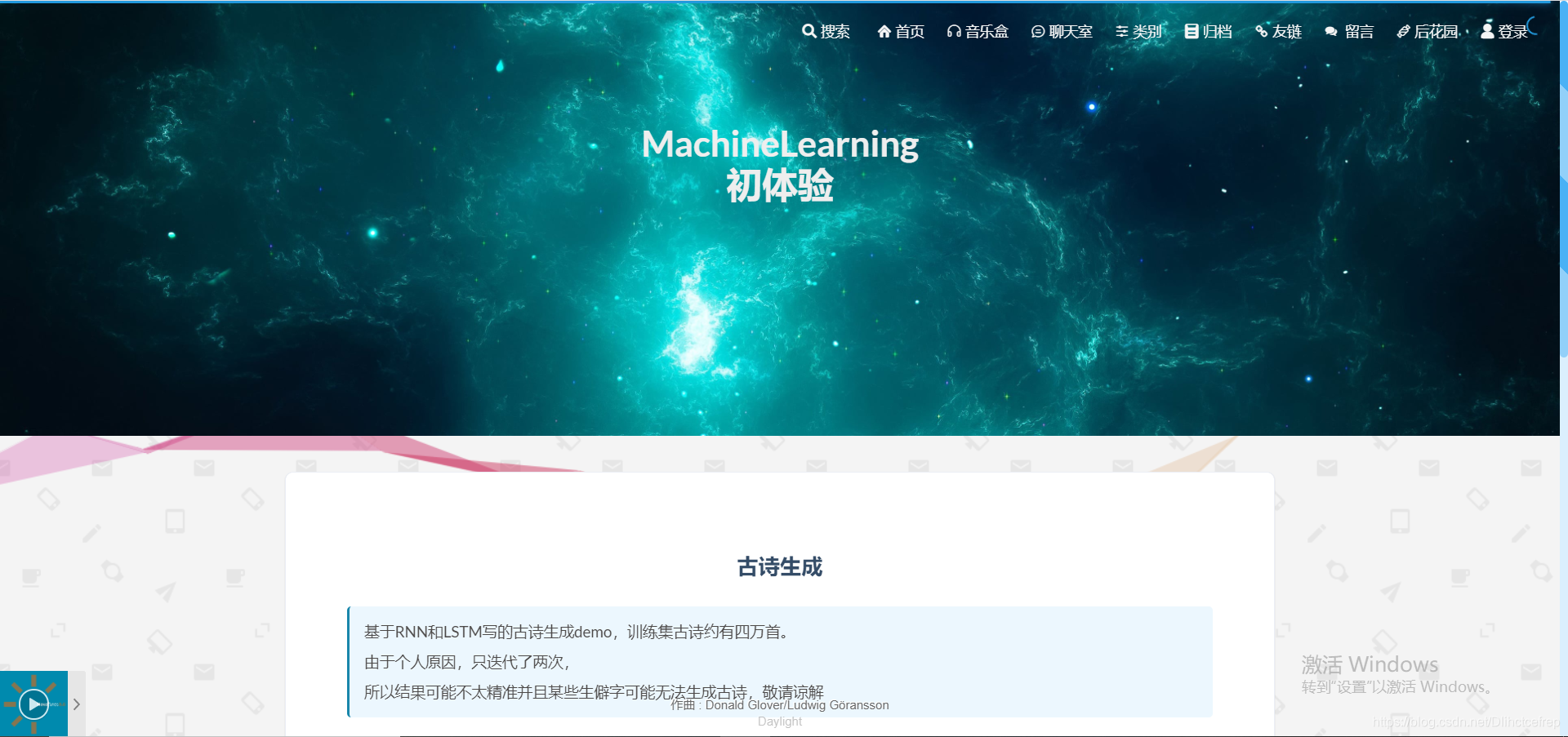
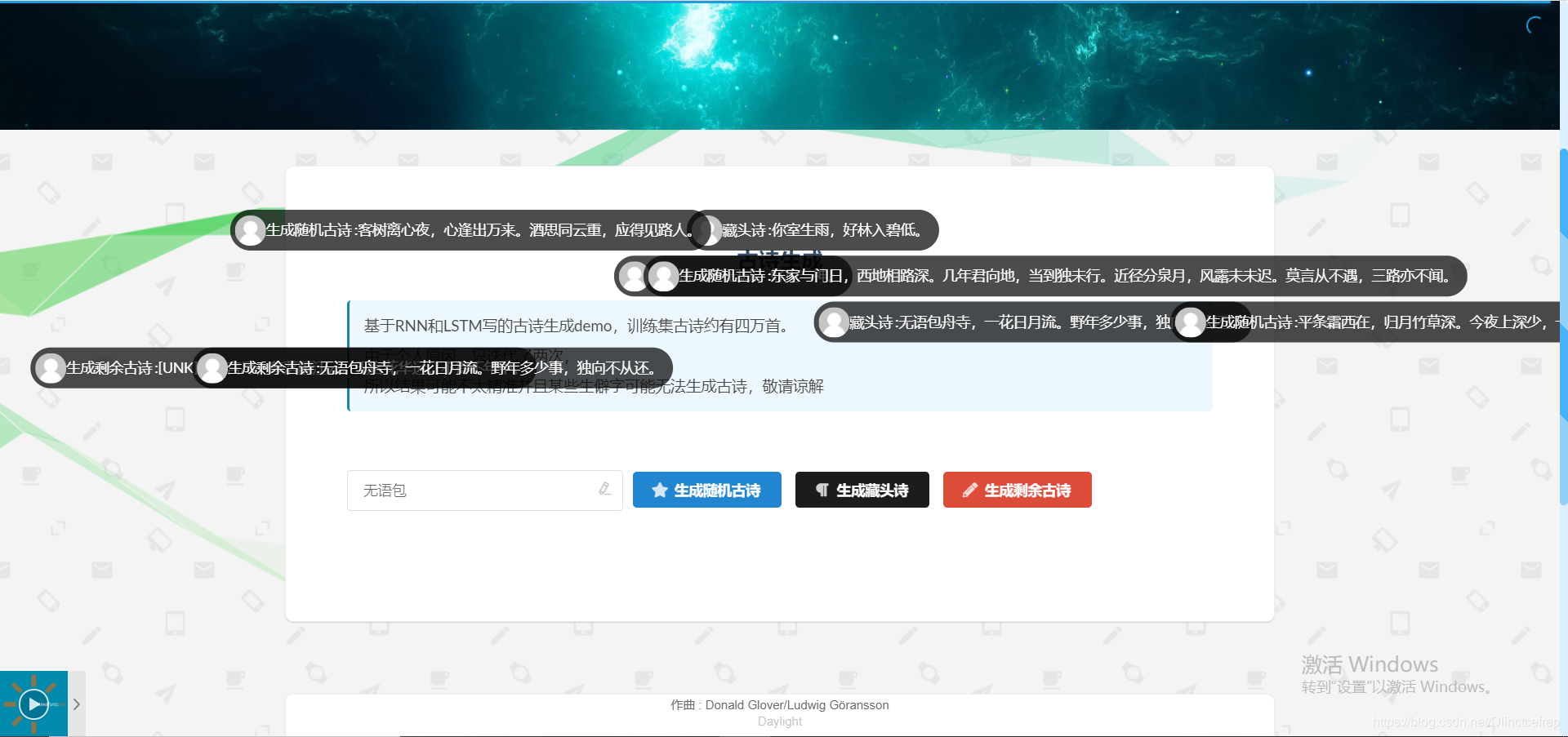
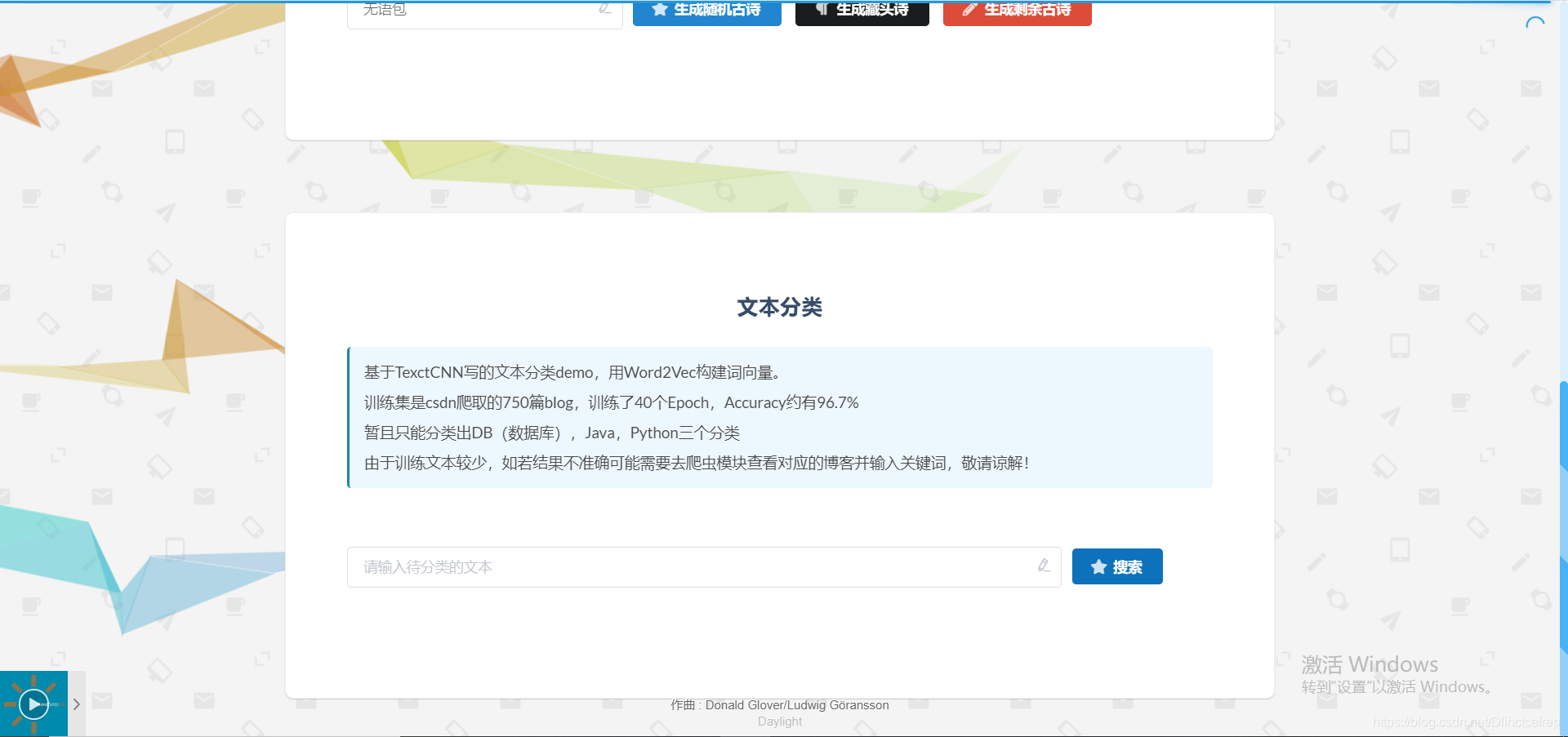
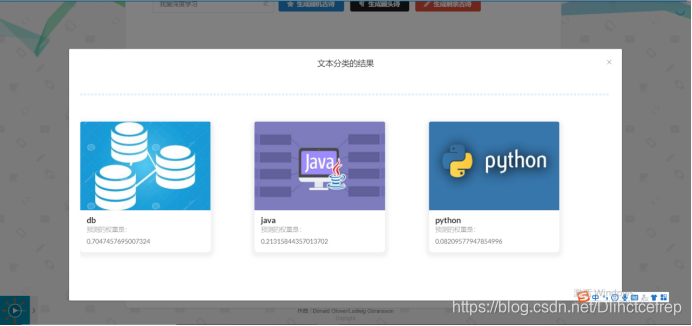
1.2 博客后台管理页面:
后台管理主要有三大模块构成:用户管理,博客管理,数据统计构成。

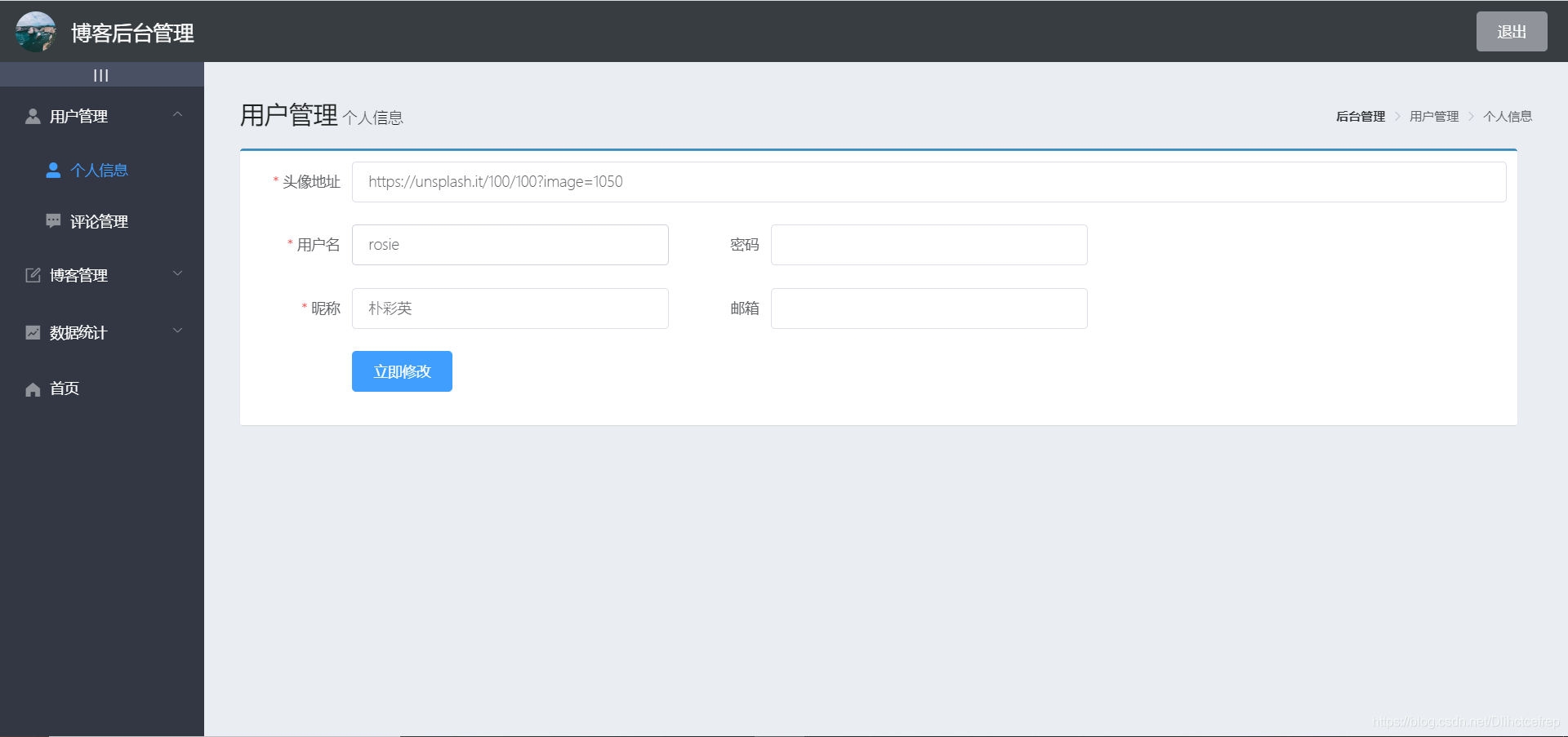
1.2.1 用户管理模块
- 个人信息界面
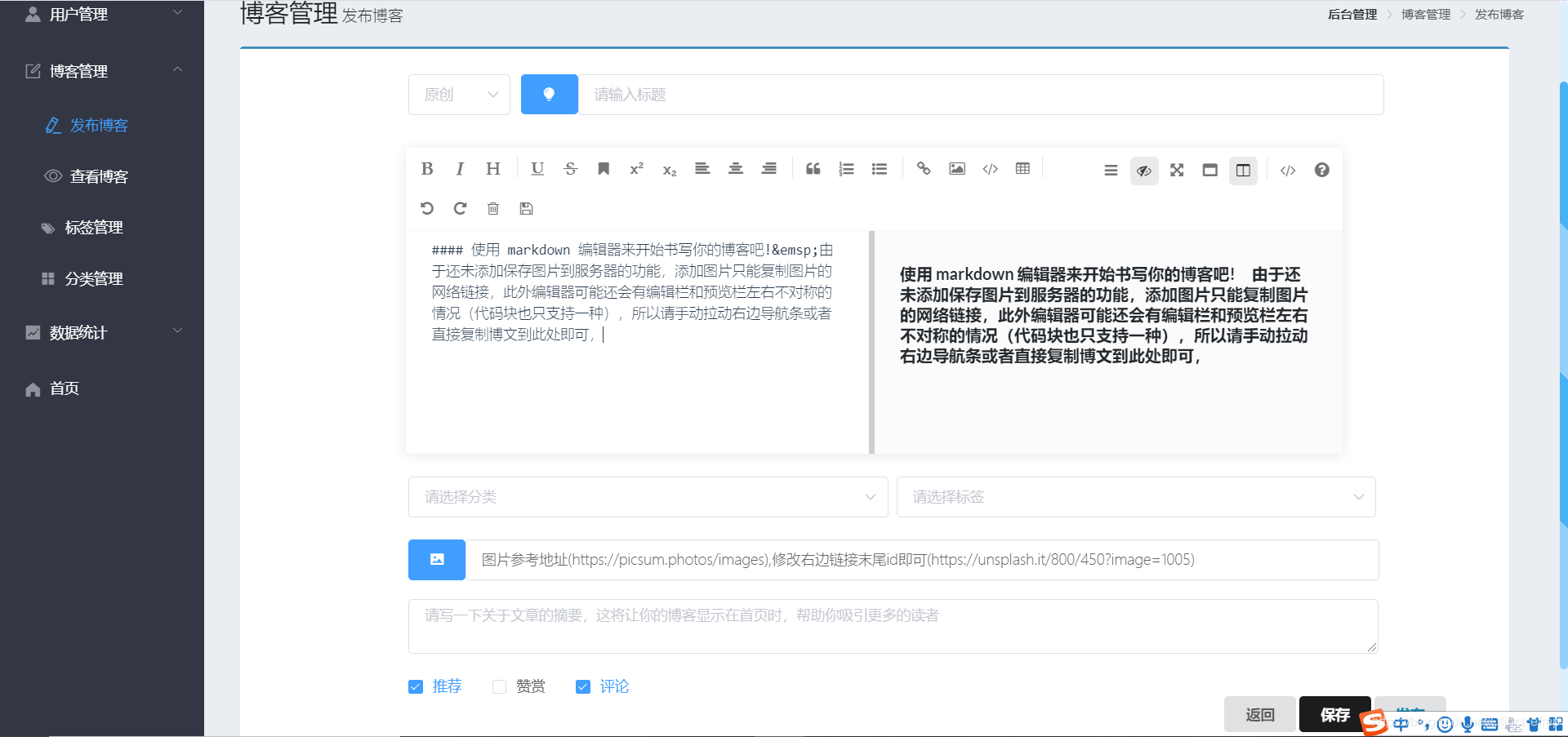
1.2.2 博客管理模块
- 发布博客页面
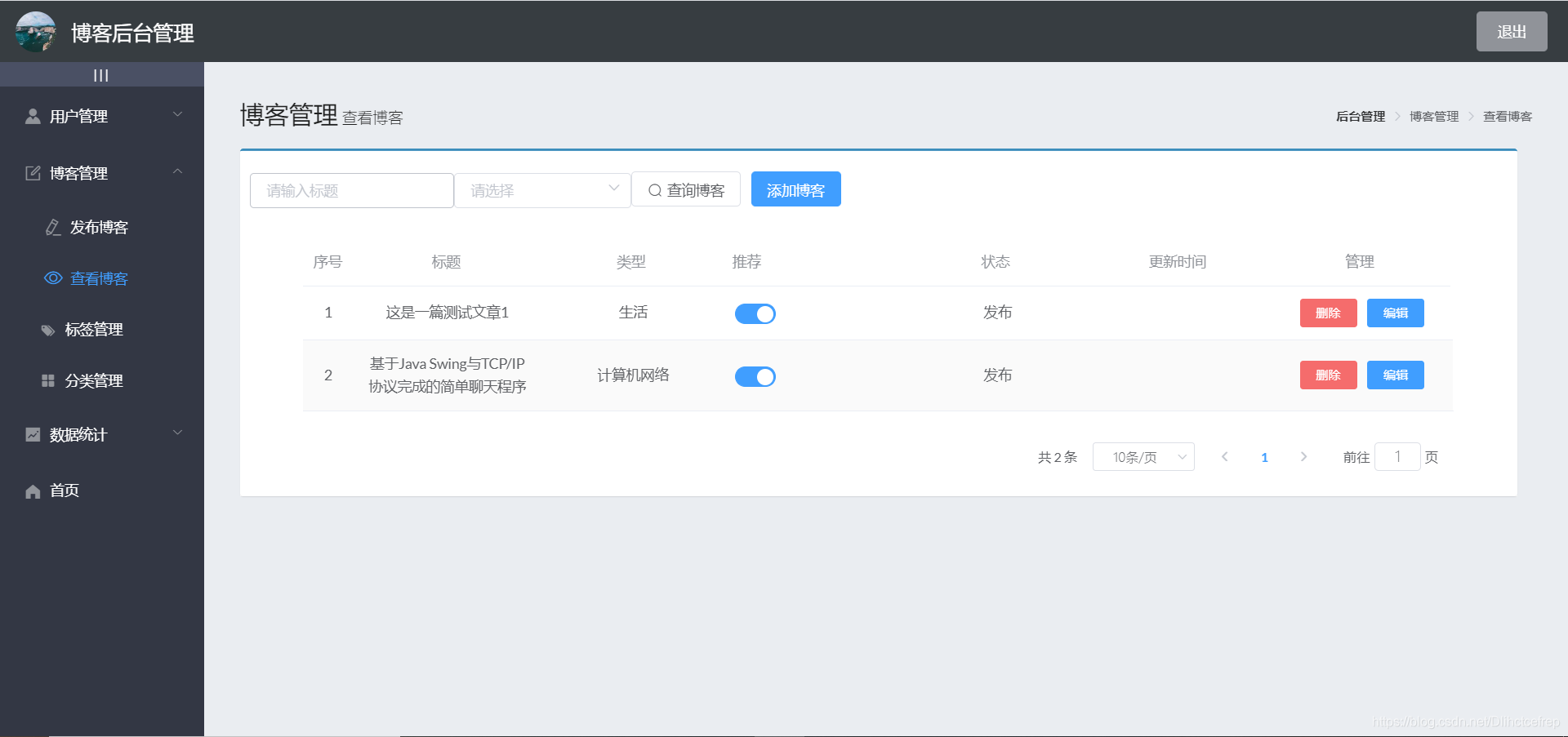
- 查看博客页面
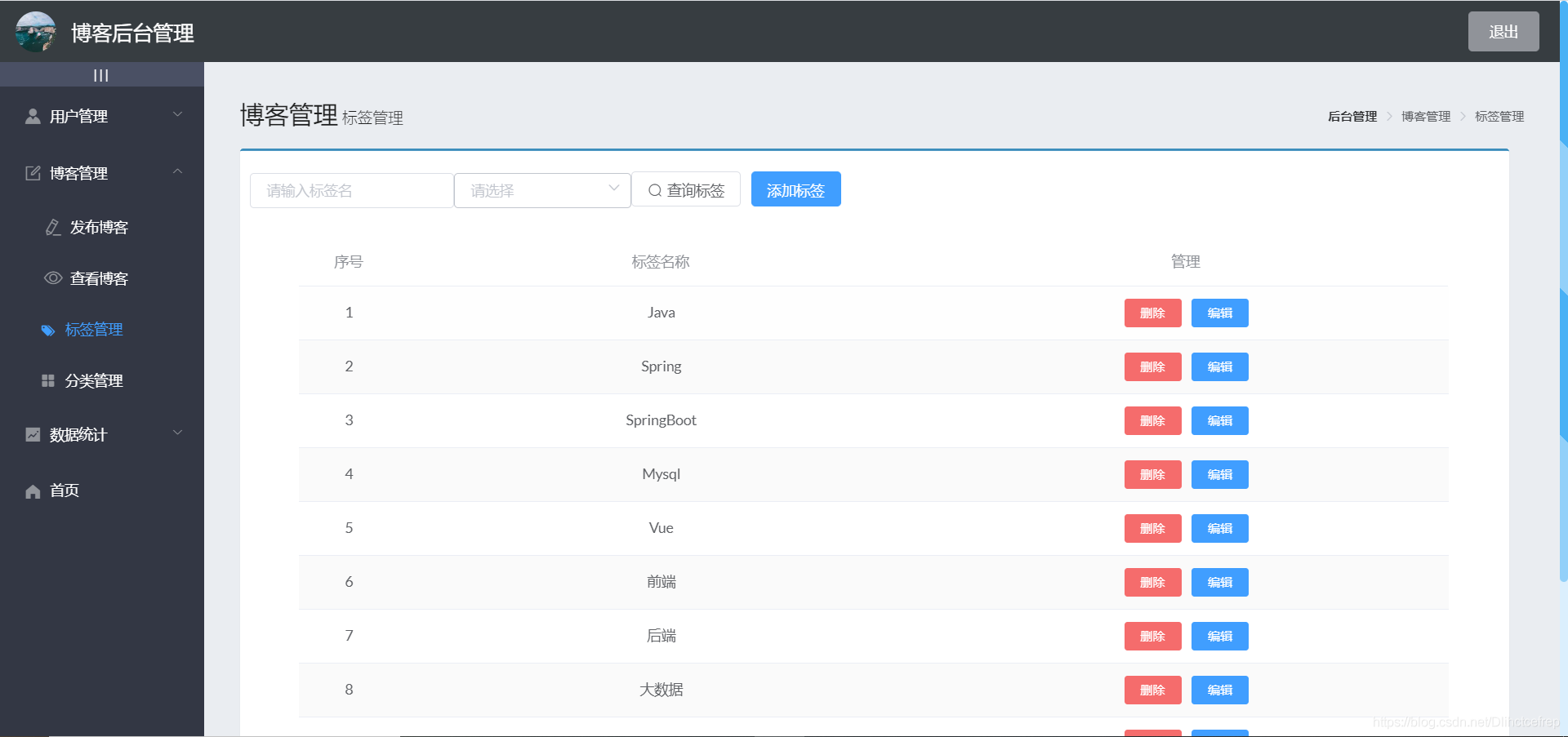
- 标签管理
- 分类管理
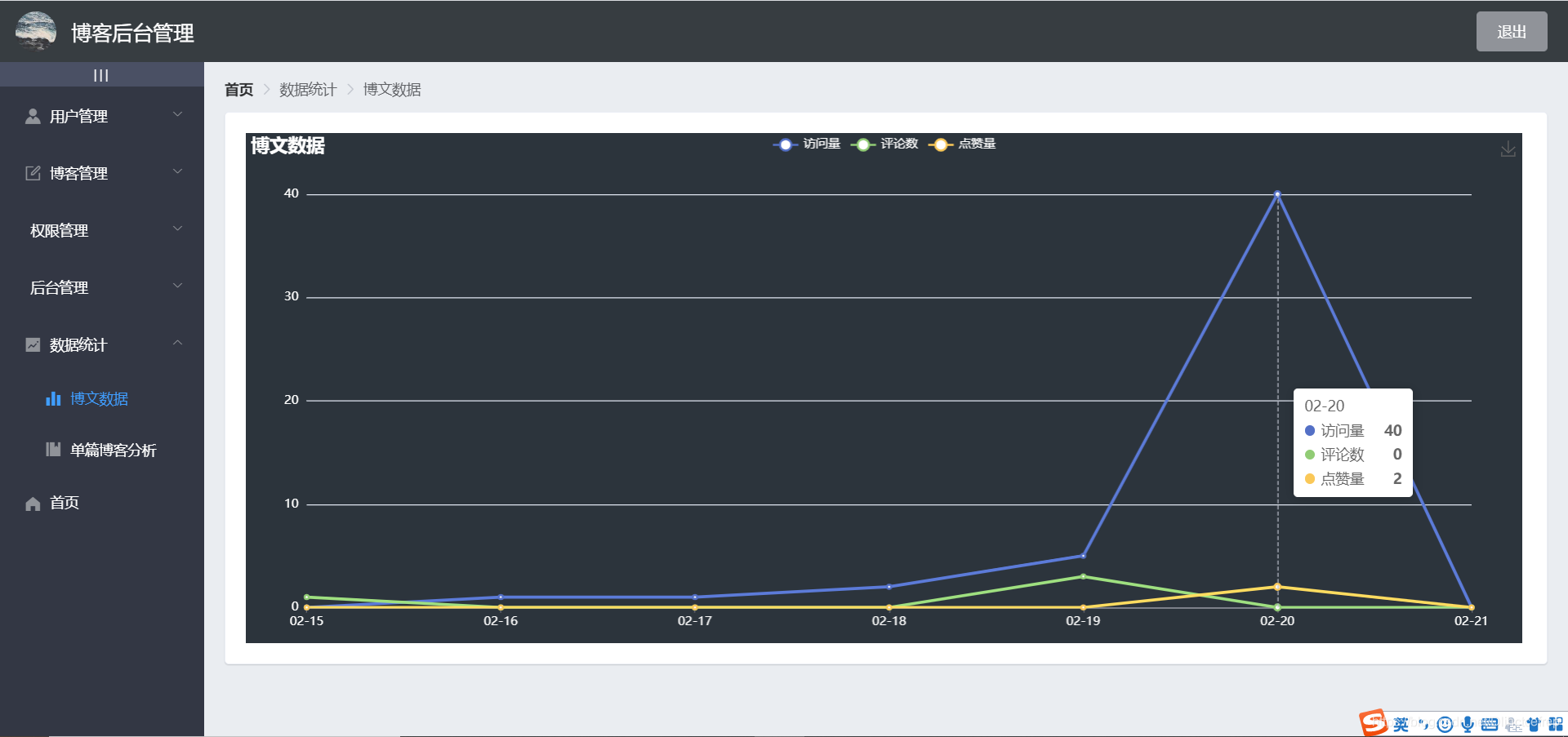
1.2.3 数据统计模块
- 博文数据
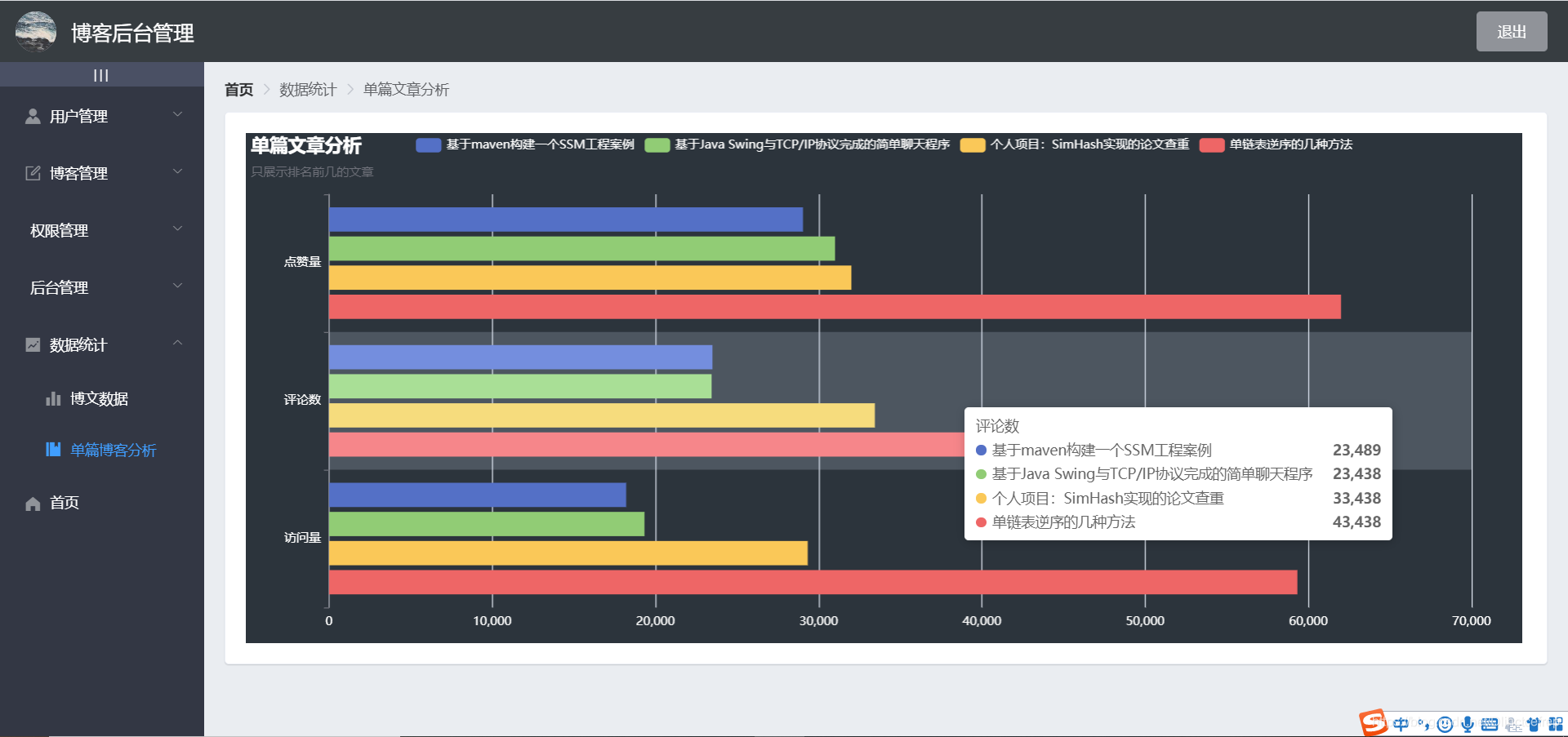
- 单篇博客分析
1.3 网站音乐盒模块(仿网易云):
后花园中的音乐盒有,五个主要模块组成:发现音乐,推荐歌单,最新音乐,最新MV,搜索模块。后台接口调用的是网易云的api
1.3.1 发现音乐:
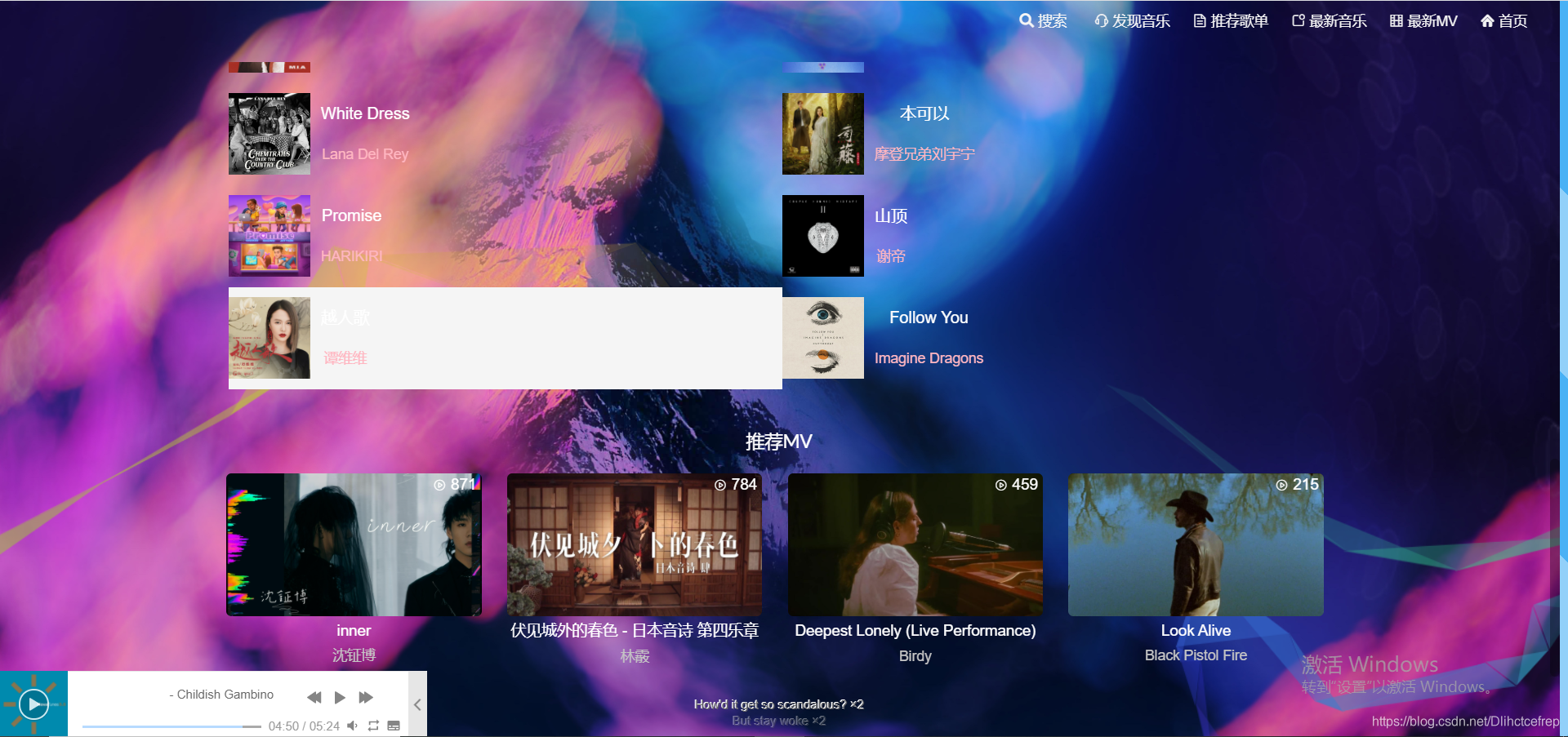
1.3.2 推荐歌单:
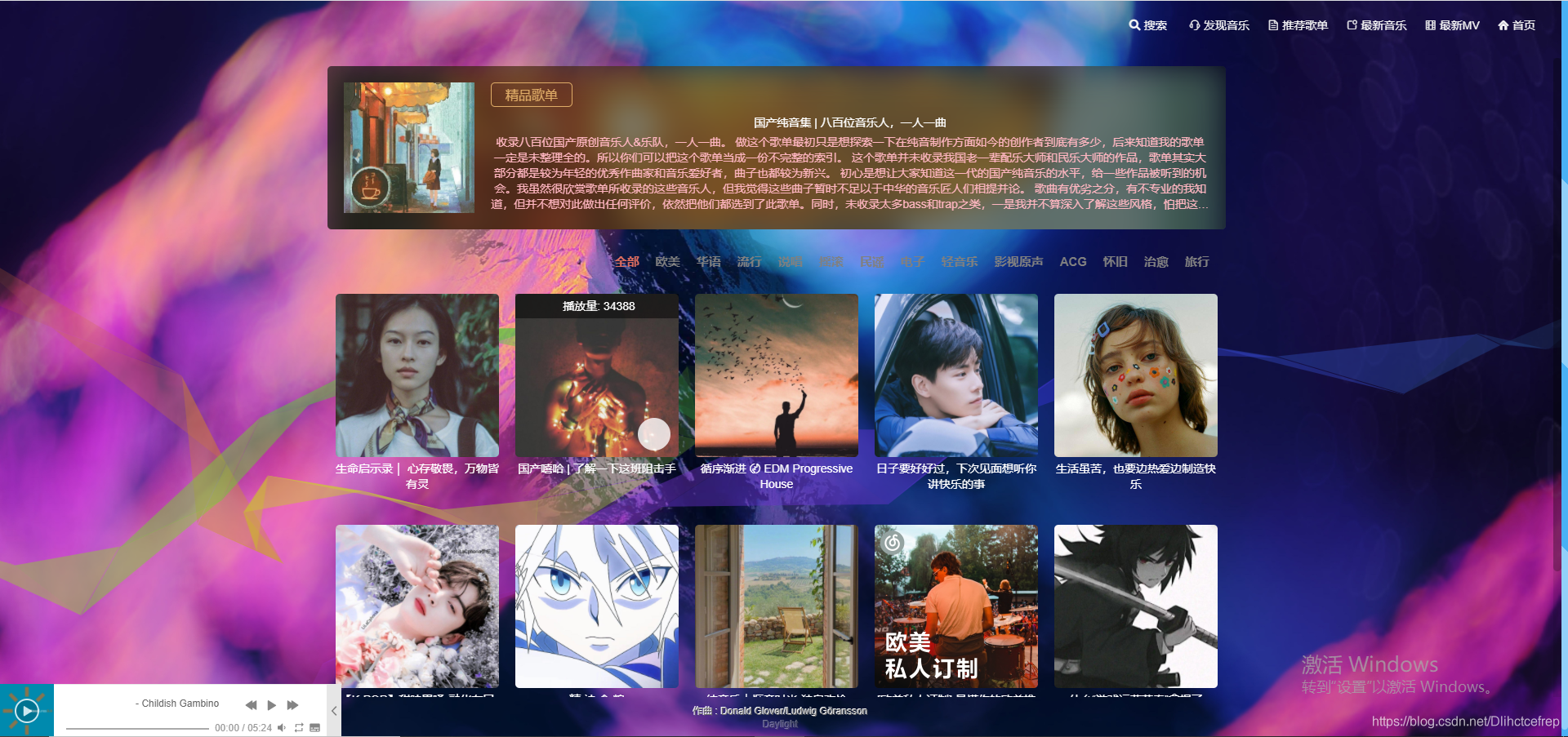
1.3.3 最新音乐:
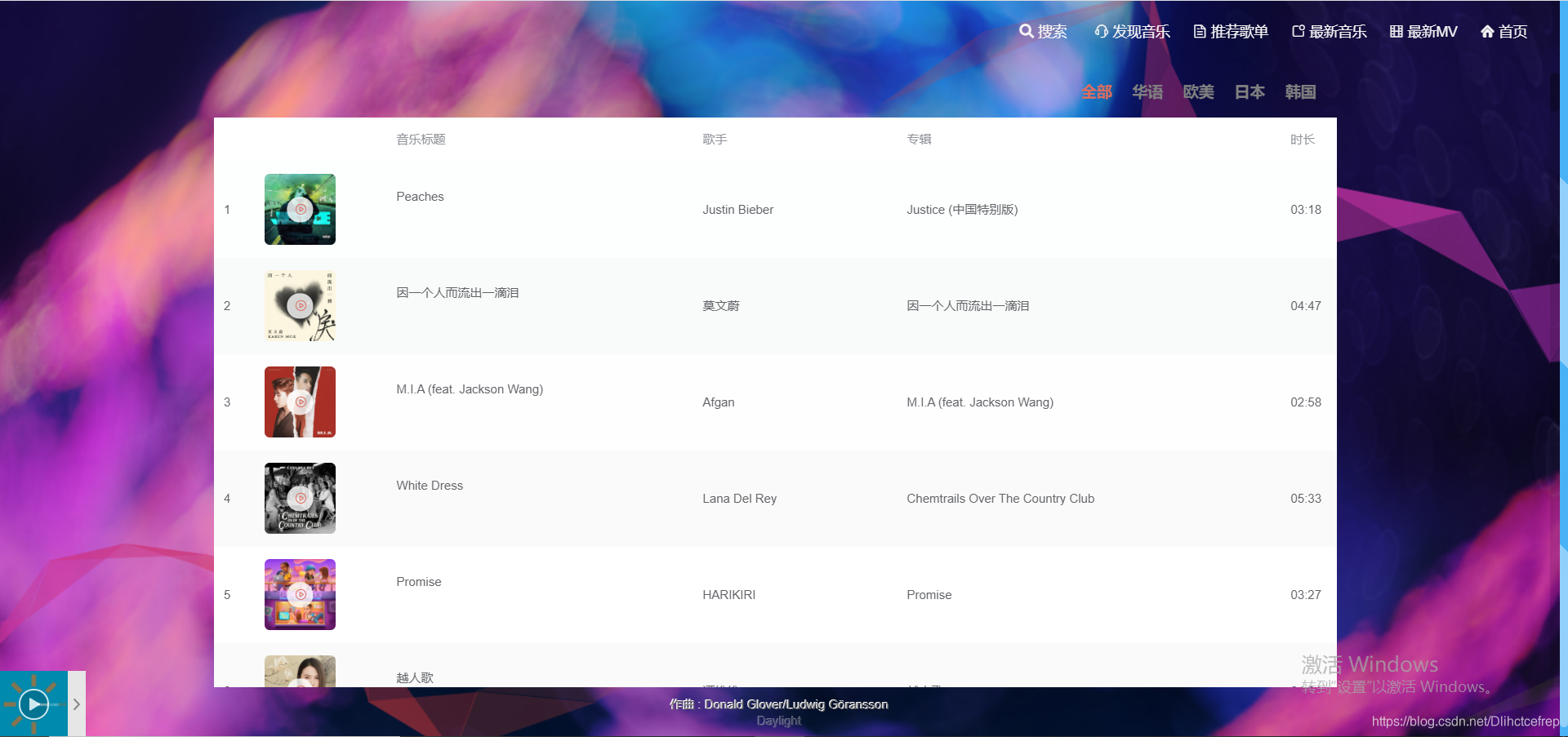
1.3.4 最新MV:
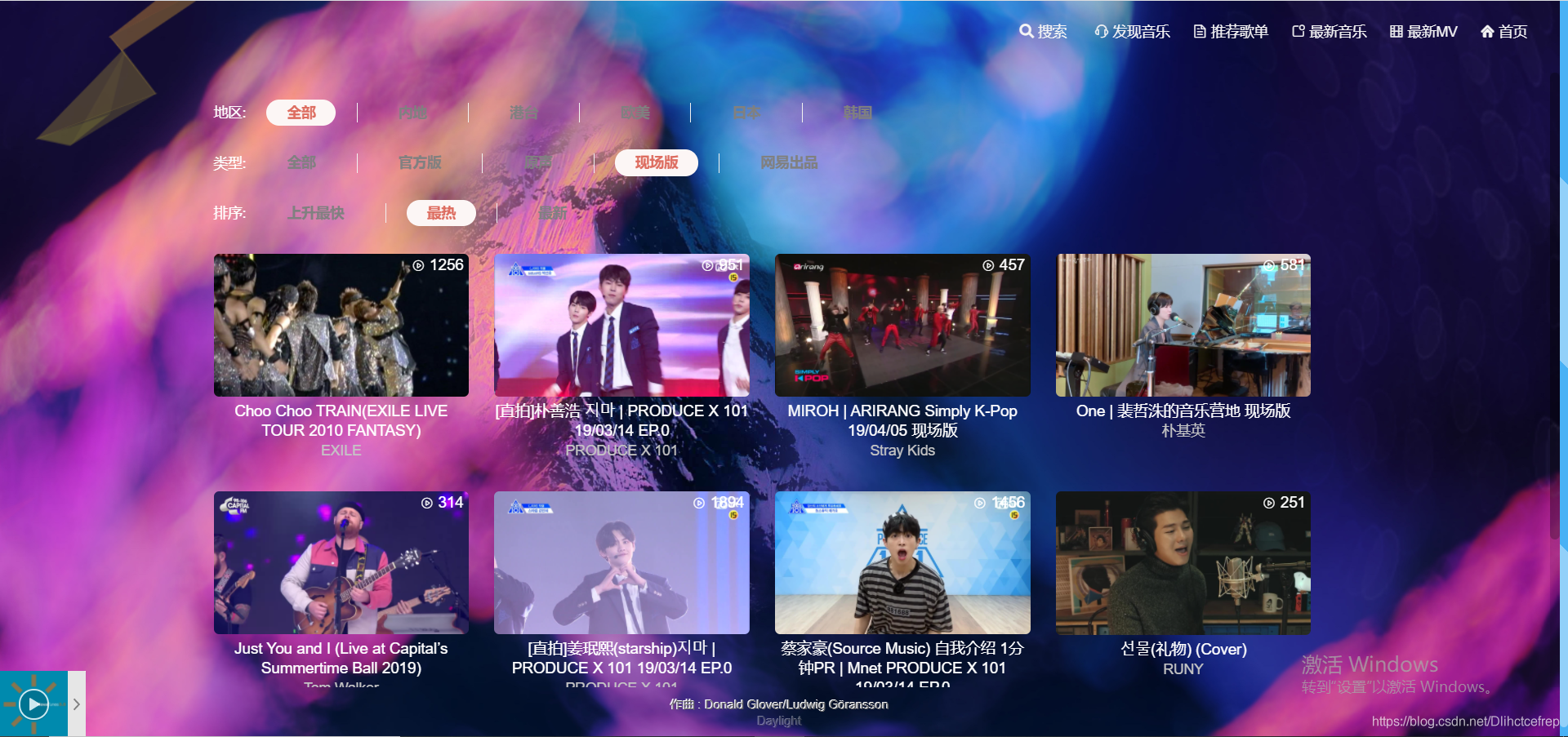
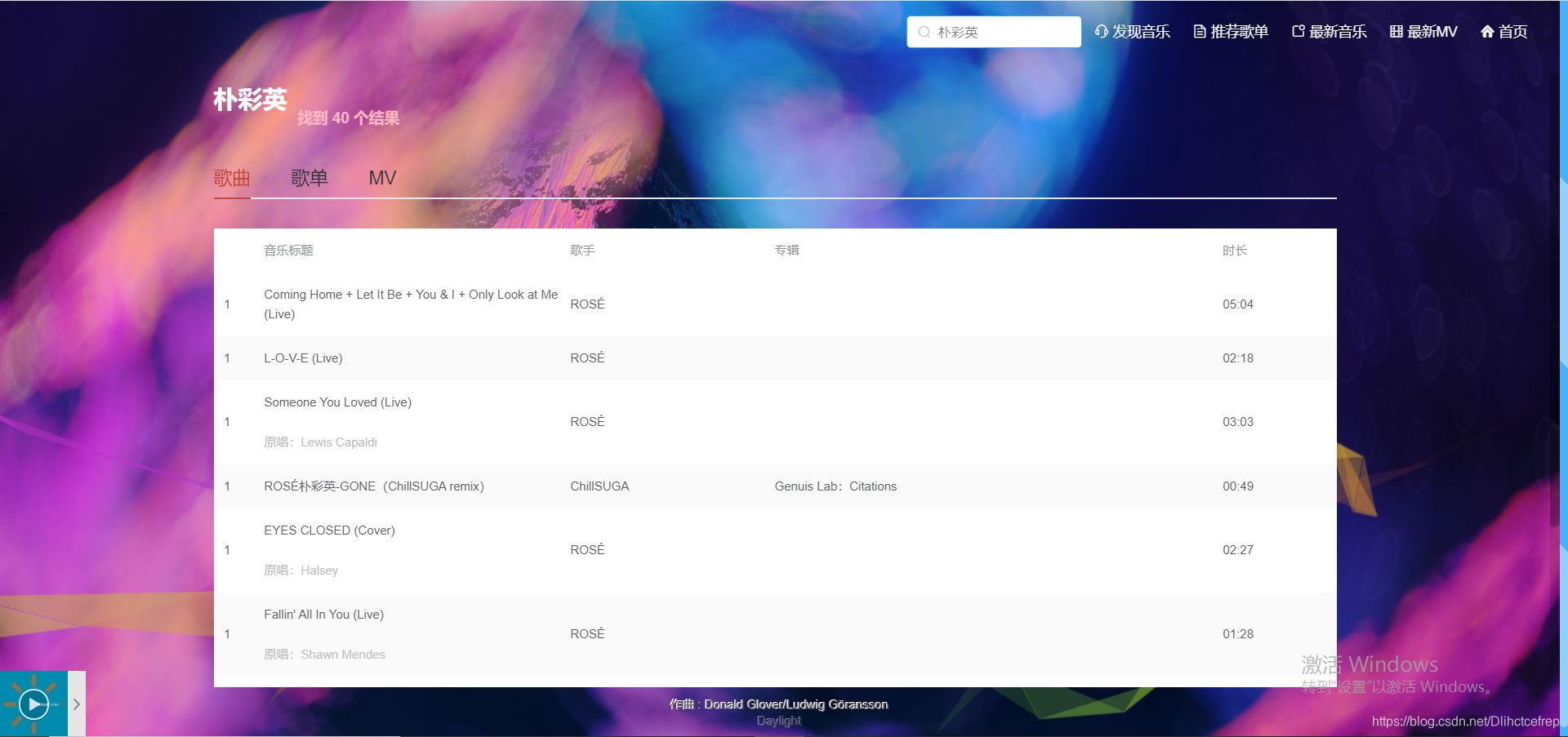
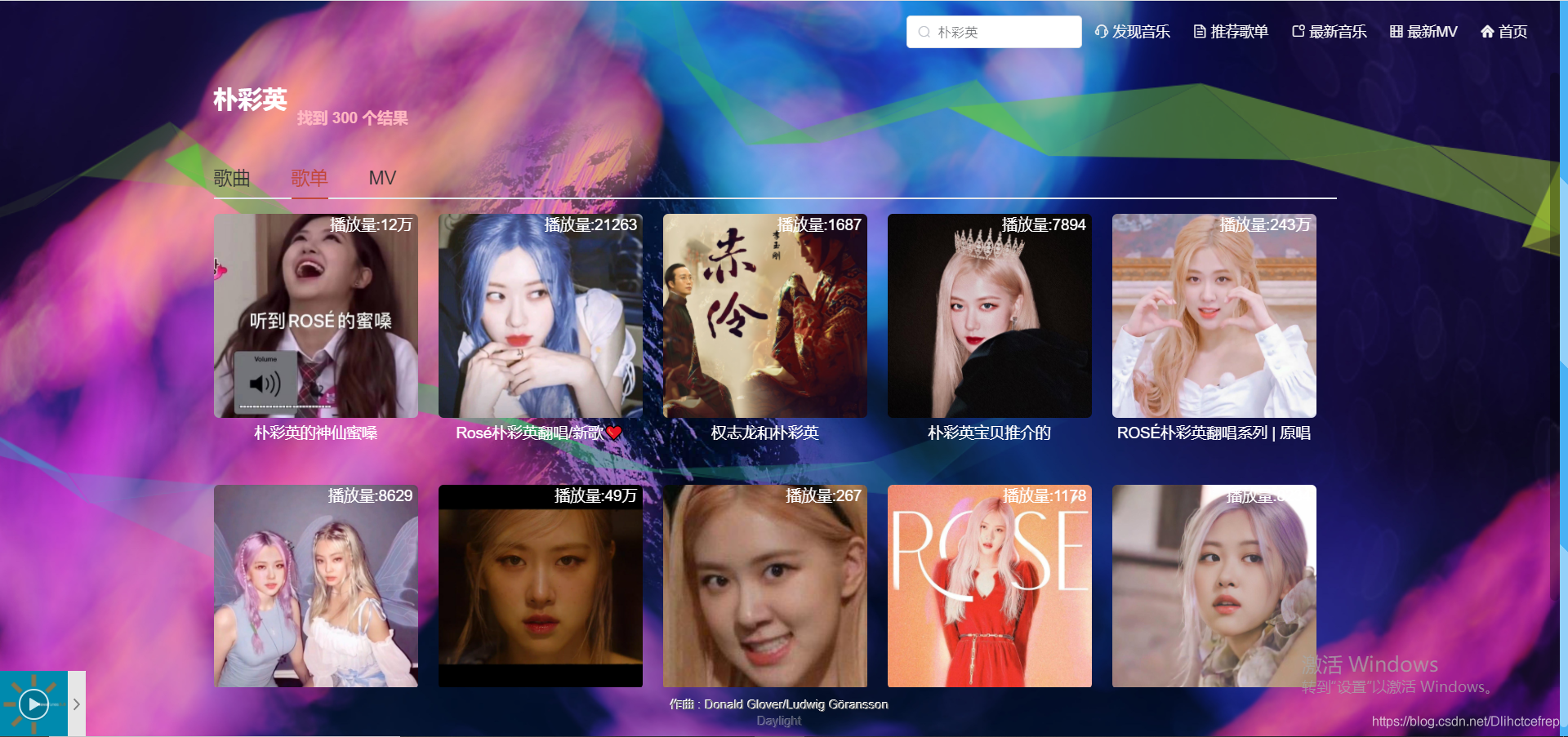
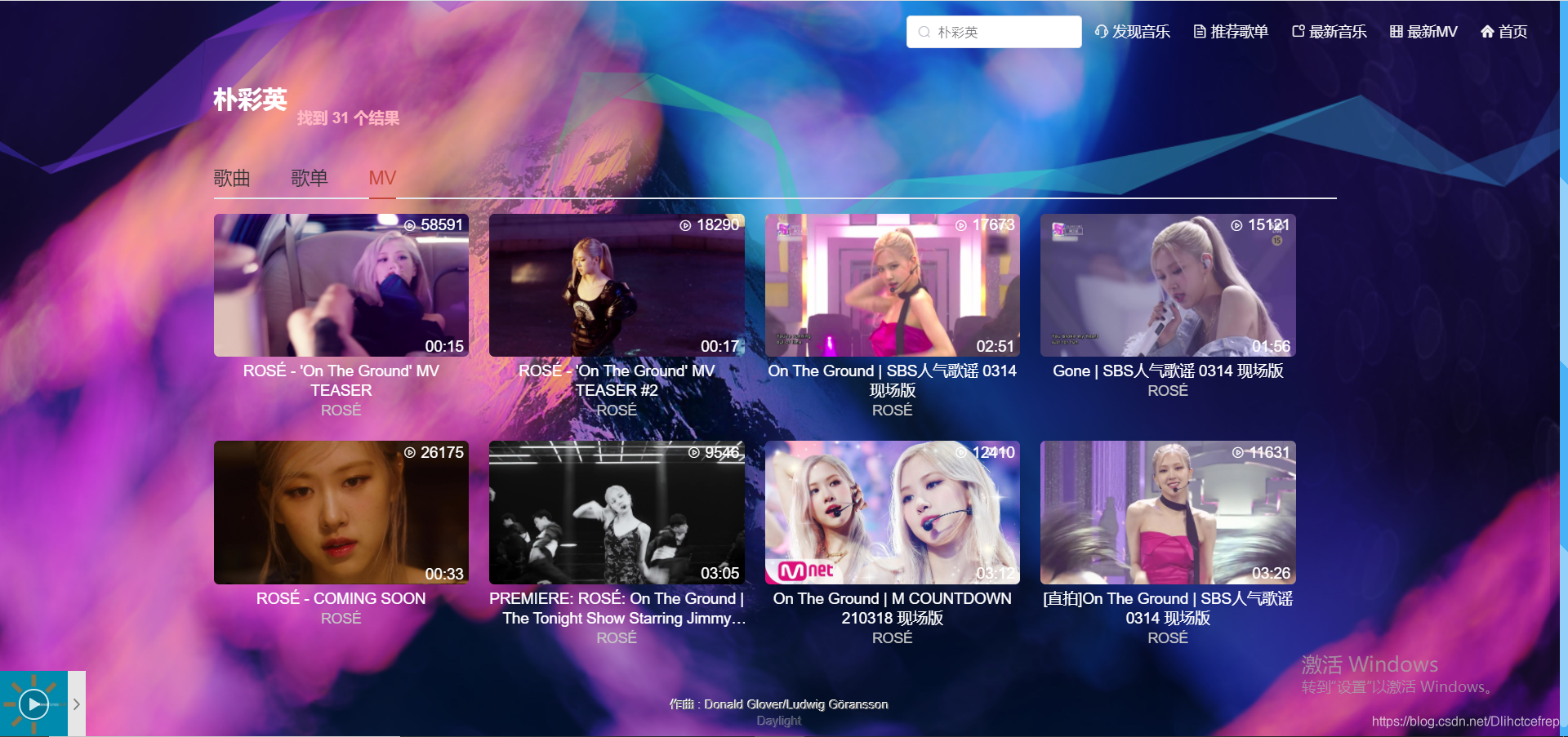
1.3.5 搜索详情页:
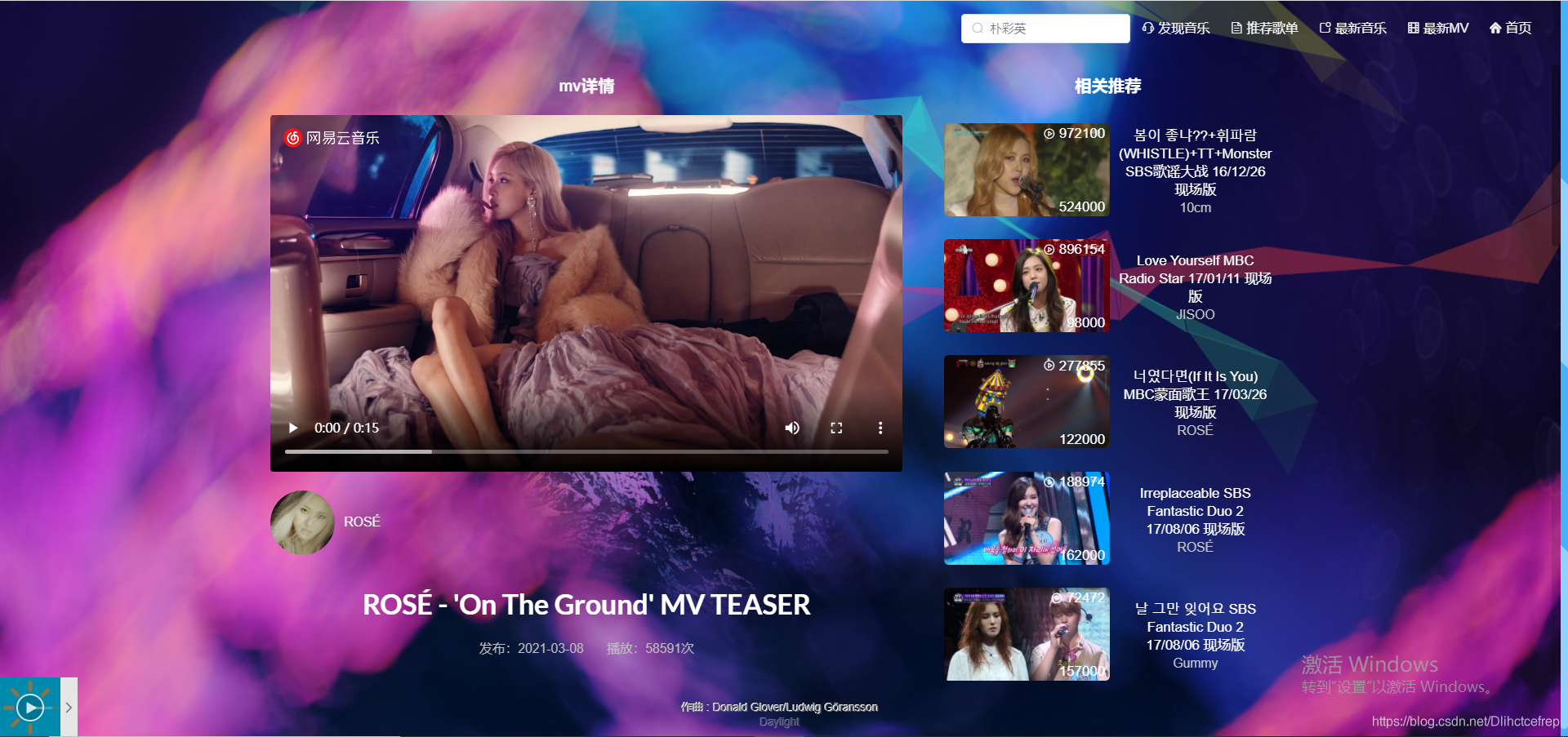
1.3.6 MV详情页:
1.3.7 歌单详情页:
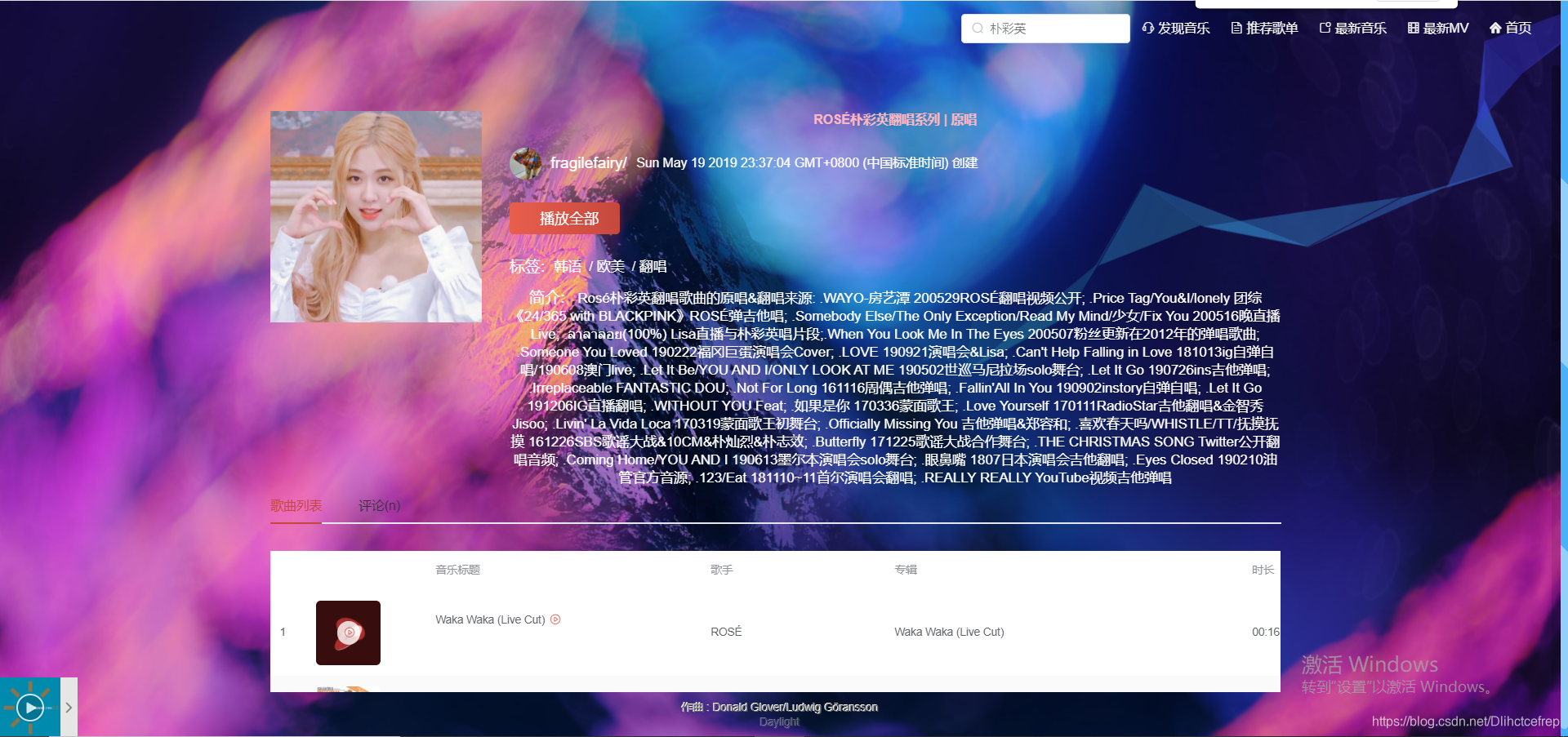
1.3.8 评论详情:
歌单和MV中都有评论
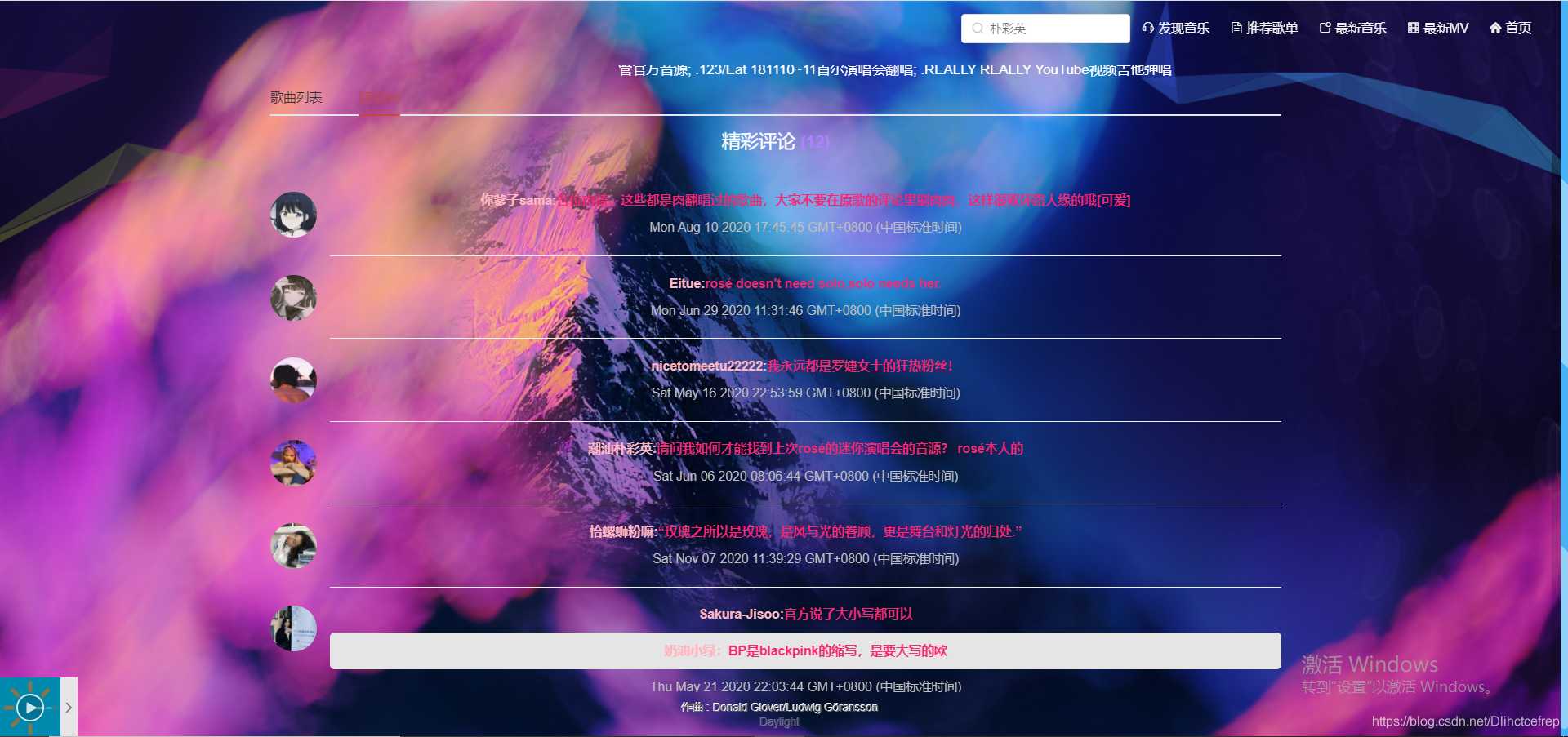
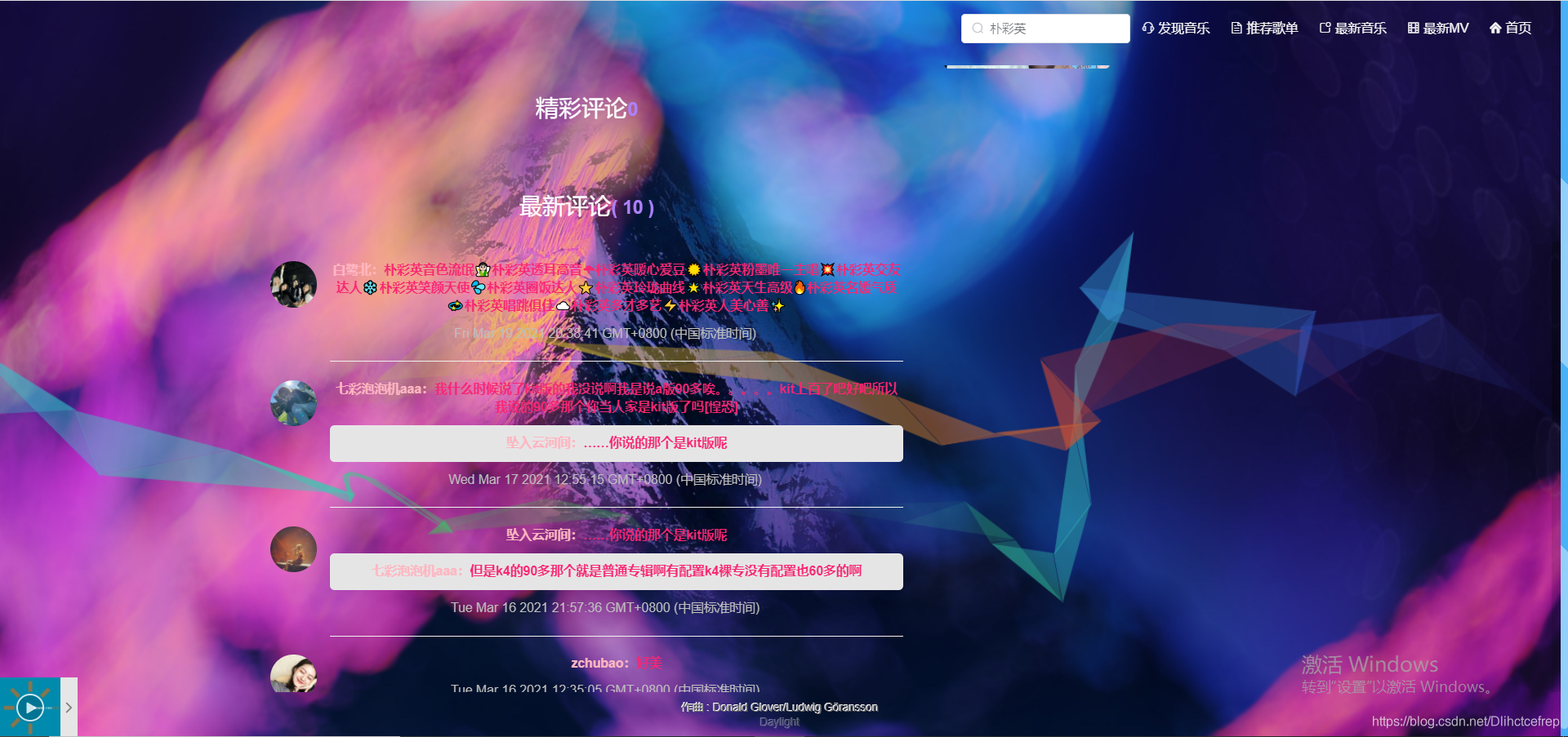
1.4 网站聊天室模块:
1.4.1 初始界面
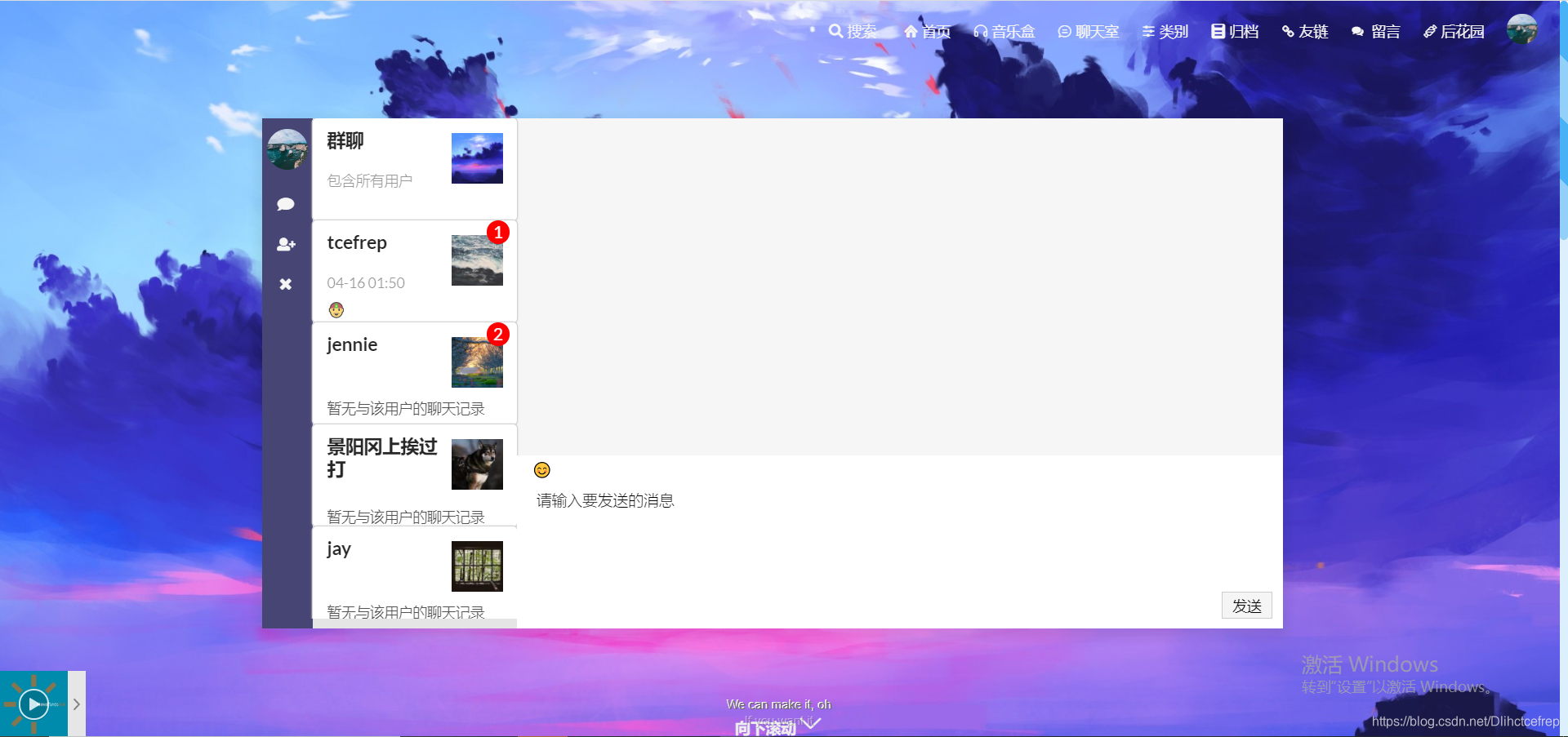
1.4.2 群聊界面
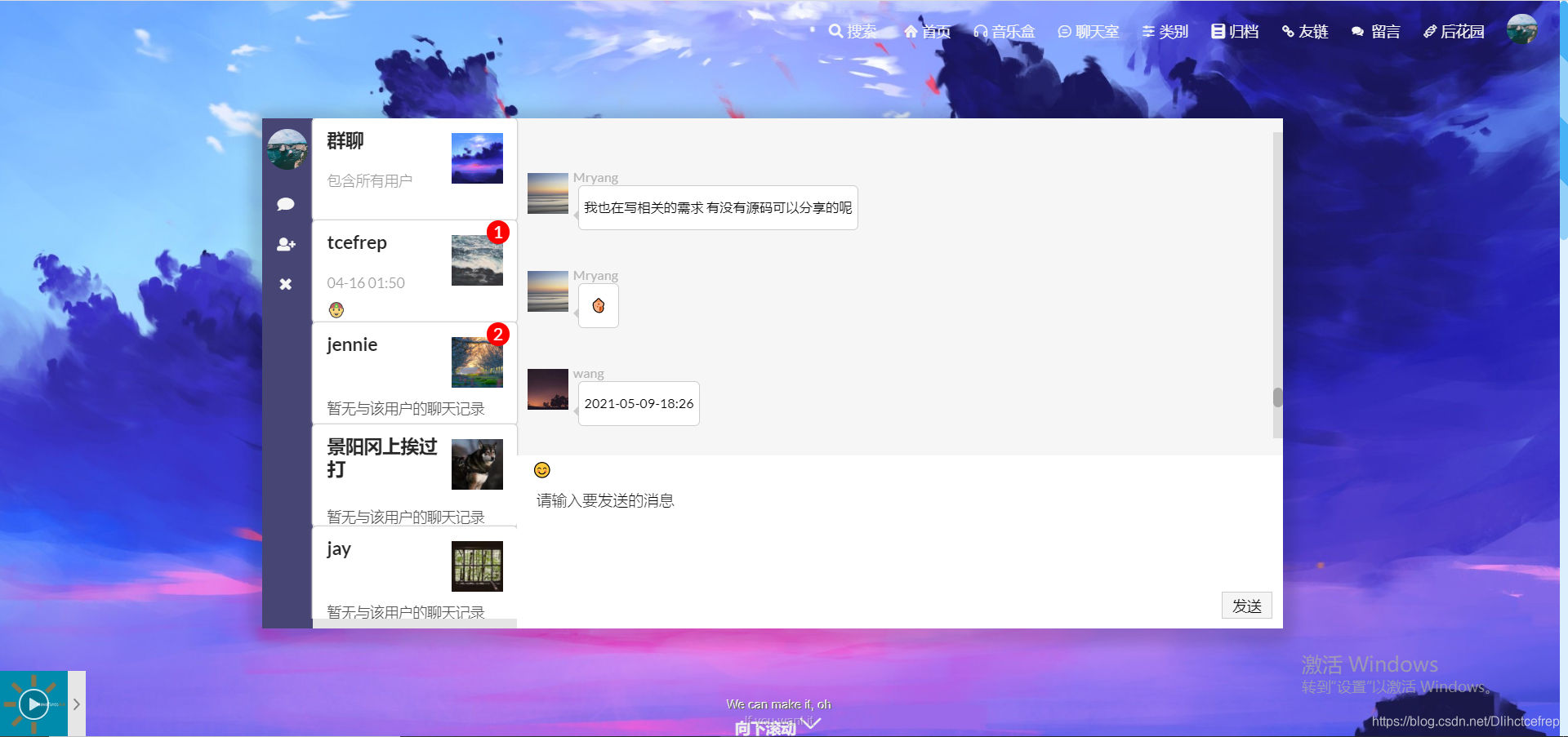
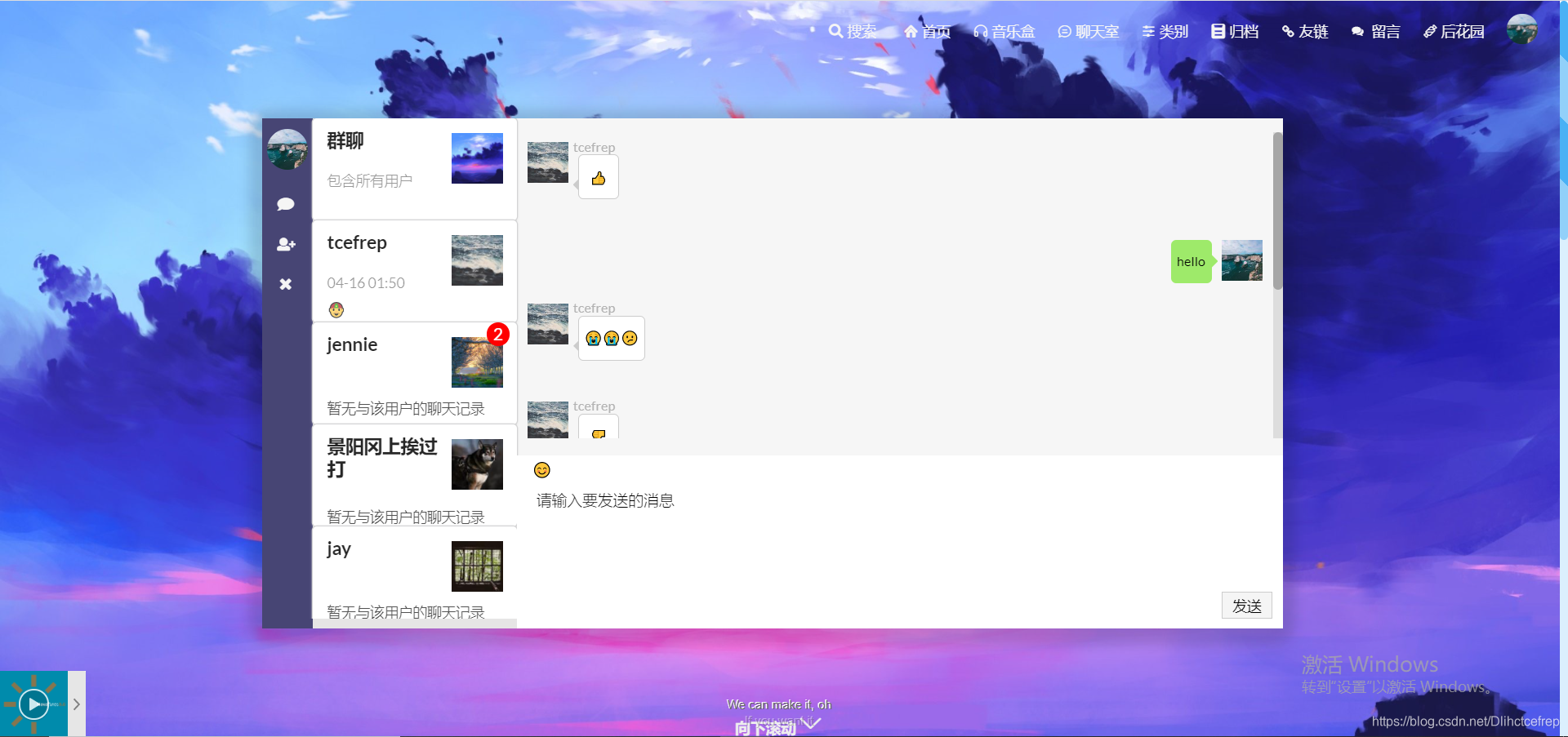
1.4.3 私聊界面
1.5 功能介绍:
本博客简单实现了博客展示、后台管理、发布博客还有评论等功能,其中后台管理、发布博客和评论功能要在用户登录后才可使用,而后台管理的某些功能普通用户只有查看的权限,并没有分配增删改的权限。
1.6 博客介绍
由于博客是由博主一人完成的,所以暂且只做了一些简单的功能,部分地方还是有不完善的地方甚至有bug,欢迎各位在本篇博文下评论处指出。
1.7 Tips
1.7.1
编写博客的markdown编辑器在文章过长时,编写栏和预览栏可能会有错位,此时可手动拉动预览栏滚动条)
1.7.2
暂未设置图片上传功能,涉及图片的上传和使用建议使用网络地址。推荐的图片地址(https://picsum.photos/images#1),使用的时候,将右侧链接的(https://unsplash.it/100/100?image=1002) 1002 改成自己的图片id即可,100/100是图片的尺寸,即长宽。
1.7.3
前端的请求没有用baseURL封装到一个js里。
1.7.4
由于笔者偷懒,没有使用vuex存储某些共享数据,用的都是sessionstorage。
二.前端开发:
2.1 简介:
https://github.com/asiL-tcefreP/blog-vue(前端源码地址)
采用了vue.js,前端框架采用了semantic-ui和element-ui,此外还有一些关于页面动态和渲染的js和css类似(animate.css,pricsm等)。此外,需要说明的是,本人后端狗一枚,页面样式是基于网上部分模板样式的修改,其余开发是独立完成的。
2.2 项目介绍
项目结构采用的是vue-cli3,值得一提的是其中用到的插件还是不错的。
三.后端开发:
3.1 简介:
https://github.com/asiL-tcefreP/blog(后端源码地址)
- 大致框架采用了SpringBoot+MybatisPlus+SpringCloud(Eureka)+ElasticSearch完成的,用redis做缓存中间件,采用微服务的架构。
- 安全方面采用了SpringSecurity和BCEncrypt
- 用了jwt来请求访问接口
- 利用RSA算法对前端发送的重要参数进行加密,经过网关解密后把参数发送到后端服务器。
- 由于服务器内存和配置的原因,服务器只上线了四个模块
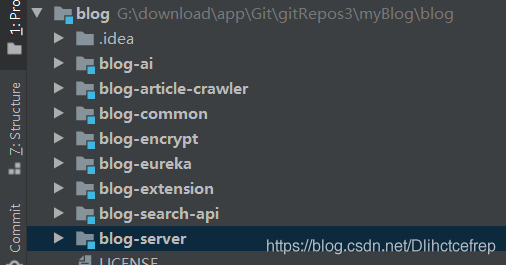
项目是由八个模块组成的,
- blog-common: 博客服务端的实体类
- blog-encrypt: 博客的服务代理类(从前端接收请求,网关RSA解密后转发给服务端接口)
- blog-eureka: 微服务注册中心server
- blog-server: 主体服务端
- blog-extension: 拓展服务端(留言和友链功能),上线的版本集成了blog-search-api模块,因为阿里云服务器内存太小了
- blog-search-api: ElasticSearch的服务端,分出一个模块是为了更清晰的展现微服务架构,但是服务器内存太小,所以集成在上述模块中,自己开发可以直接使用本模块
- blog-article-crawler:爬虫和人工智能模块,用的webmagic框架爬取数据,deeplearning4j做文本分类
- blog-ai:里面的服务类调用了py脚本来实现古诗词生成
3.3 开发中遇到的一些问题:
3.3.1 关于jwt与zuul
本人使用自定义注解@LoginRequired来对某些类或者接口进行jwt验证,但是在一开始加入网关微服务的时候,发现后端用了jwt验证的接口一直访问不通过。在浏览器看,发的请求的请求头明明都带上了token,这是一开始百思不得其解的地方之一。
后来才得知,原来是在网关转发前端的请求后,再把请求转发给后端服务器时,请求头中的token丢失,于是只能在网关filter里面,在转发请求给后端前,手动的把token加到头部。
package pers.fjl.encrypt.filter;
import com.google.common.base.Charsets;
import com.google.common.base.Strings;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import com.netflix.zuul.http.HttpServletRequestWrapper;
import com.netflix.zuul.http.ServletInputStreamWrapper;
import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.util.StreamUtils;
import org.springframework.web.bind.annotation.CrossOrigin;
import pers.fjl.encrypt.rsa.RsaKeys;
import pers.fjl.encrypt.service.RsaService;
import javax.annotation.Resource;
import javax.crypto.BadPaddingException;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.net.URLDecoder;
/**
* 网关过滤器
*
* @author fangjiale 2020年1月6日
*/
@Component
@CrossOrigin
public class RSARequestFilter extends ZuulFilter {
@Resource
private RsaService rsaService;
private String tokenHeader = "Authorization";
@Override
public String filterType() {
//过滤器在什么环境下执行,解密操作需要在转发之前执行
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
//设置过滤器的执行顺序
return FilterConstants.PRE_DECORATION_FILTER_ORDER + 1;
}
@Override
public boolean shouldFilter() {
//是否使用过滤器
return true;
}
@Override
public Object run() throws ZuulException {
/**
* 1. 从request body中读取出加密后的请求参数
* 2. 将加密后的请求参数用私钥解密
* 3. 将解密后的请求参数写回request body中
* 4. 转发请求
*/
//获取容器
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
HttpServletResponse response = ctx.getResponse();
String token = request.getHeader(this.tokenHeader);
//声明存放加密后的数据变量
String requestData = null;
//声明解密后的数据变量
String decryptData = null;
//网关从前端接收过来的request后,还要再加上token到头转发request,否则后端服务器会拦截
ctx.addZuulRequestHeader("Authorization",token);
//需要设置request请求头中的Content-Type为json格式,否则api接口模块就需要进行url转码操作
ctx.addZuulRequestHeader("Content-Type", String.valueOf(MediaType.APPLICATION_JSON) + ";charset=UTF-8");
try {
//通过request获取inputStream
ServletInputStream inputStream = request.getInputStream();
//从inputStream中得到加密后的数据
requestData = StreamUtils.copyToString(inputStream, Charsets.UTF_8);
String s = URLDecoder.decode(requestData, "UTF-8");
String s2 = s.replace(' ', '+');
if (requestData != null && s2 != null) {
System.out.println("加密后" + requestData);
System.out.println("替换后" + s2);
}
//对加密后的数据进行解密
if (!Strings.isNullOrEmpty(s2)) {
try {
decryptData = rsaService.RSADecryptDataPEM(s2, RsaKeys.getServerPrvKeyPkcs8());
} catch (BadPaddingException e) {
System.out.println("网关发送的是明文数据");
}
System.out.println("解密后" + decryptData);
}
if (!Strings.isNullOrEmpty(decryptData)) {
byte[] bytes = decryptData.getBytes();
//使用RequestContext进行数据的转发
ctx.setRequest(new HttpServletRequestWrapper(request) {
@Override
public String getHeader(String name) {
return token;
}
@Override
public ServletInputStream getInputStream() throws IOException {
return new ServletInputStreamWrapper(bytes);
}
@Override
public int getContentLength() {
return bytes.length;
}
@Override
public long getContentLengthLong() {
return bytes.length;
}
});
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
3.3.2 关于RSA解密与Json

获取到前端的加密请求参数时,还有对其进行URLdecode解码,然而加密后的数据中的空格依旧没有转换成加号,此时就得自己用字符串替换。前端传来的数据要进行解码否则就会有%2F,%3D等出现,其次base64编码的+号会变成空格,要对字符串进行处理重新变为+号,关于转码问题可以参考: 这篇文章。

3.4 有意思的插件
- captcha:自动生成验证码
- commonmark:将markdown格式的文章转换成html格式的显示在页面
- NeteaseCloudMusicApi:网易云音乐后台数据的api接口
3.5 关于ELK
之前一直没做项目关于ElasticSearch的整合,是因为不知道项目如果采用了ES后,对数据库的操作该怎么实现。
例如:当我更改数据库的数据时,还要同步ES索引中的数据,这也未免太过繁琐。此外,数据库中的多对多、一对多关系在ES索引中该如何表示?Linux系统下该怎么部署ES?
后来查阅资料,才明白不一定要把数据库表的所有字段都存在索引中,只需要存我们需要的字段即可,ES的查询速度比mysql确实快的不止一星半点,并且还有IK分词器对搜索词分词,然后进行得分排序显示查询出来的结果。
然后要说的就是Logstash了,就是他完成了数据库和索引的实时同步(最快就是一分钟同步一次),不过只能实现增量同步。
具体关于ELK的配置,还请各位点击我的这篇文章,其中有详细说明。
3.6 关于AI和爬虫模块
用了三千篇从csdn上爬取下来的文章做训练集。总共迭代了二十次,词向量维度是200,
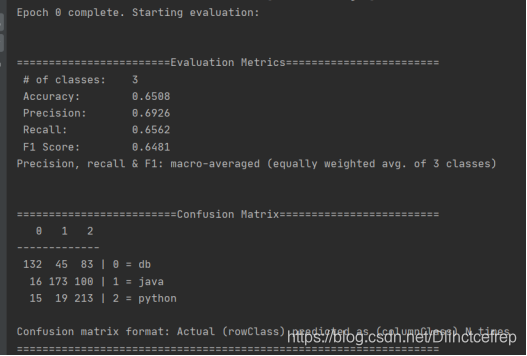
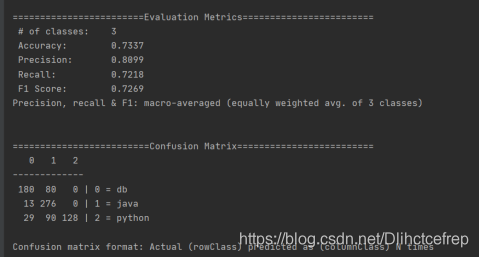
可以看到的是在第一个Epoch,准确率只有65%,但是在第二个Epoch的时候已经有了明显提升。
第十次Epoch,loss值在0.6左右
第二十次Epoch,loss值在0.4左右
第三十次Epoch,loss值在0.2几左右,但是此时准确率已经达到了96.7%。
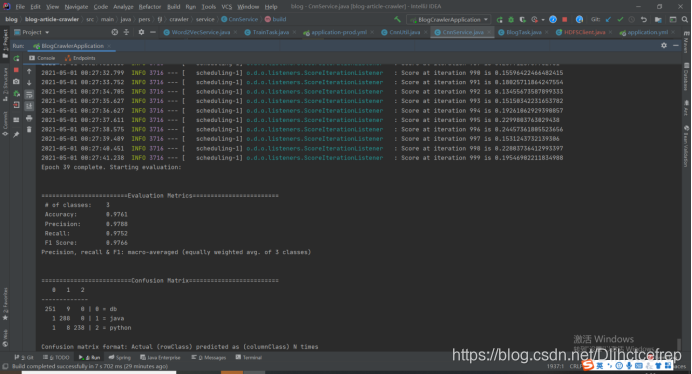
第四十次Epoch,loss值约在0.2,准确率达到97.6%。
训练完成后,用ModelSerializer.writeModel方法将模型持久化即可。


根据爬取下来的三千篇文章的内容和标题做的分词,以及词向量分析,算法就不在此细说了,用的都是别人的,源码中都有。
值得一提的是,在使用webmagic根据页面元素的Xpath获取指定数据的过程还是挺有趣的
项目涉及增删改查的部分还是挺好理解的,各位看看源码应该都能理解,所以笔者在此不再赘述。
如果这篇文章对你有帮助,麻烦点个赞,并star一下仓库,有问题请在评论处指出,感谢各位支持!