Docker容器、K8s简单实战与概念理解
一:容器与镜像
1、简单理解容器
我们将通过操作系统管理进程这个例子来形象的理解容器的概念。
当登录到操作进程之后,可以看到各种进程,这些进程由系统自带的服务进程和用户进程组成。
这些进程之间有这些特点:
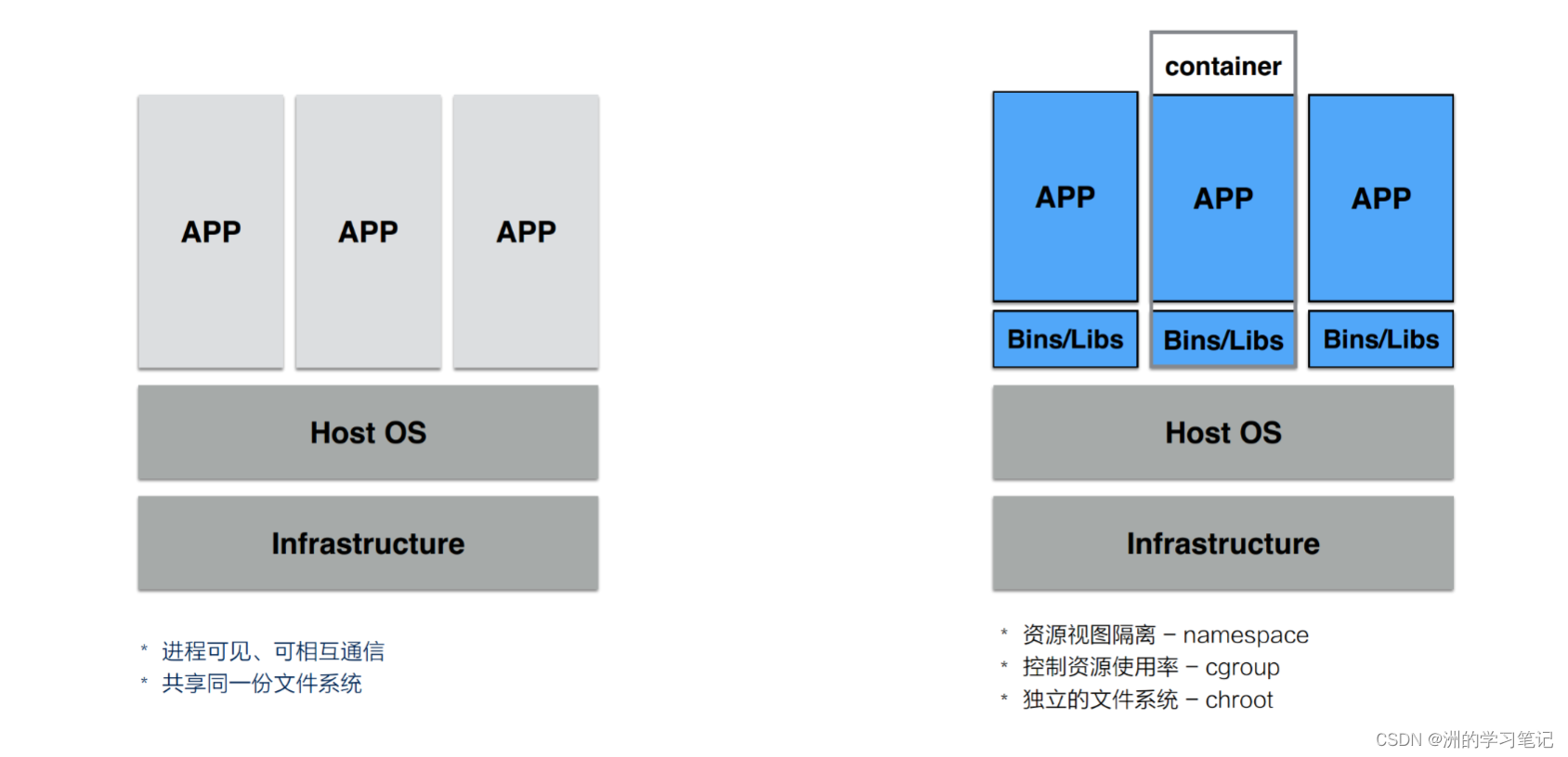
1、这些进程可以相互看到、相互通信。
2、使用的是同一个文件系统,可以对同一个文件进行读写操作。
3、使用的是相同的系统资源。
但正是由于这三个特点将会引发一些进程之间的问题等,如:
- 由于能够互相看到和通信,所以更高权限的进程可以攻击其他的进程。
- 对于第二点,由于用的同一个文件系统,这些进程都可以对已有的数据进行增删改查,所以,进程之间可能会误删其他进程的数据(例如具有更高级别权限的进程删掉别的进程的数据),这样就会破坏其他进程的正常运行。
- 进程和进程之间因为是同一个文件系统,所以可能存在依赖冲突,这样会造成不必要的宕机损失。
- 因为是使用相同的系统资源(即一个宿主机的资源),可能存在资源抢占的问题,当一个应用进程需要大量的CPU和内存资源的时候,就会导致其他应用进程等待、进入死锁等不能提供服务了。
那么针对上述的问题,该怎么样为进程提供一个独立的运行环境来解决问题?
- 针对不同进程使用同一个文件系统所造成的问题,Linux 和 Unix 操作系统可以通过 chroot 系统调用将子目录变成根目录,达到视图级别的隔离;进程在 chroot 的帮助下可以具有独立的文件系统,对于这样的文件系统进行增删改查不会影响到其他进程。
- 使用 Namespace 技术来实现进程在资源的视图上进行隔离(因为进程之间可以相互看见和通信)。在 chroot 和 Namespace 的帮助下,进程就能够运行在一个独立的环境下了。
- 在独立的环境下,进程所使用的还是同一个操作系统的资源,一些进程可能会侵蚀掉整个系统的资源。为了减少进程彼此之间的影响,可以通过 Cgroup 来限制其资源使用率,设置其能够使用的 CPU 以及内存量。
能够解决上述问题的进程运行环境,就是容器了。
容器,就是一个视图隔离、资源可限制、独立文件系统的进程集合。所谓“视图隔离”就是能够看到部分进程以及具有独立的主机名等;控制资源使用率则是可以对于内存大小以及 CPU 使用个数等进行限制。它将系统的其他资源隔离开来,具有自己独立的资源视图。
容器具有一个独立的文件系统,因为使用的是系统的资源,所以在独立的文件系统内不需要具备内核相关的代码或者工具,我们只需要提供容器所需的二进制文件、配置文件以及依赖即可。只要容器运行时所需的文件集合都能够具备,那么这个容器就能够运行起来。
2、Docker容器的三大函数
通过下述三大函数,Docker就实现了解决上述问题。
文件系统问题:chroot & pivot_root
作为一个容器,首要任务就是限制容器中进程的活动范围——能访问的文件系统目录。决不能让容器中的进程去肆意访问真实的系统目录,得将他们的活动范围划定到一个指定的区域,保证上述的问题得到解决。
而限制访问指定的活动区域,就是chroot & pivot_root,通过这两个函数,可以修改进程和系统目录到一个新的位置。有了这两个函数,Docke就可以来“伪造”一个文件系统来欺骗容器中的进程。
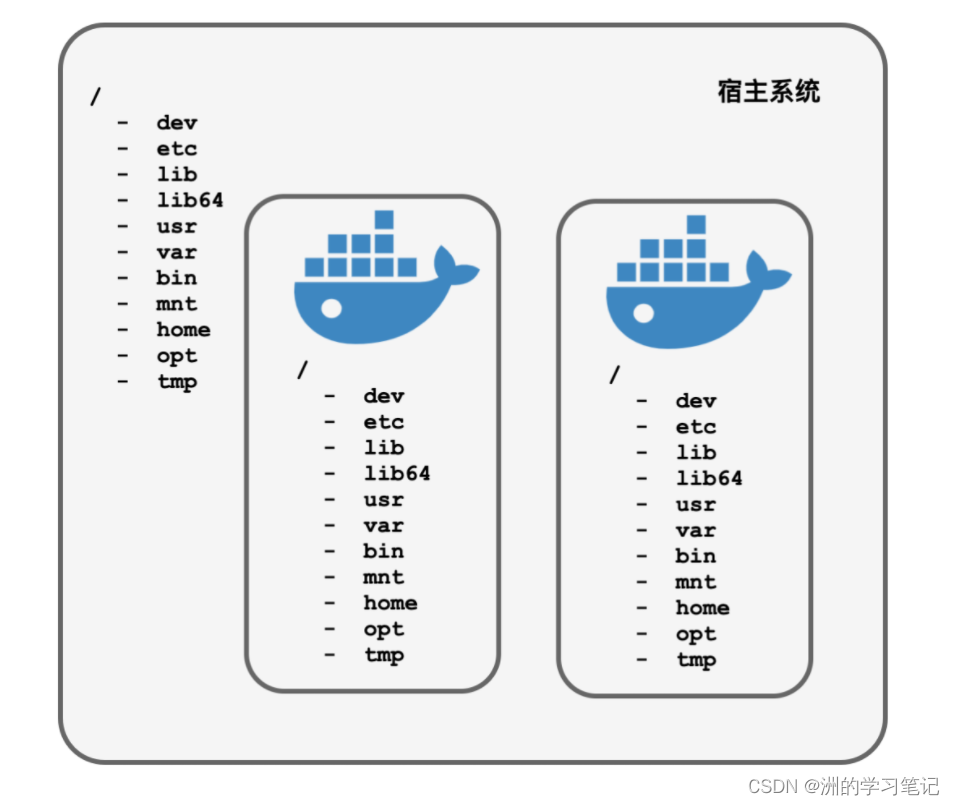
Docker用操作系统镜像文件挂载到容器进程的根目录下,变成容器的rootfs,和真实系统目录一模一样:
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
资源视图隔离:namespace
文件系统的问题解决了,但是还有一个问题,那就是如何把真实宿主机子系统所在的世界隐藏起来,不能使容器中的进程看到。
比如进程列表、网络设备、用户列表这些,是决不能让容器中的进程知道的,得让他们看到的世界是一个干净如新的系统。Docker虽然叫容器,但这只是表面现象,容器内的进程其实和自己一样,都是运行在宿主操作系统上面的一个个进程。
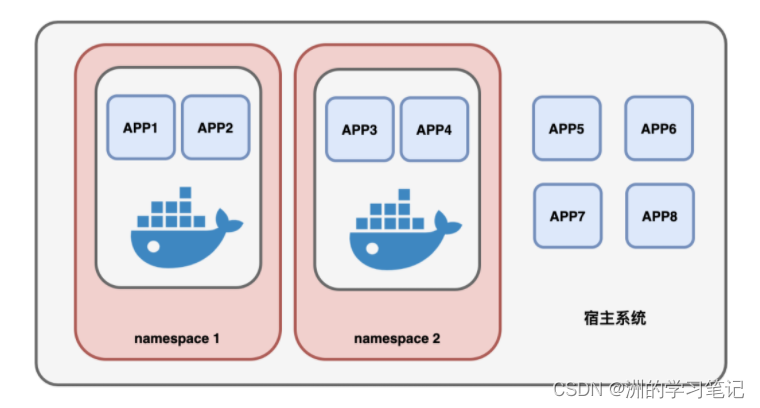
Docker想过用HOOK的方式,欺骗进程,但实施起来工作太过复杂,兼容性差,稳定性也得不到保障,于是就有了第二个命令:namespace。
这个namespace是linux提供的一种机制,通过它可以划定一个个的命名空间,然后把进程划分到这些命名空间中。(有点类似flask框架中的websocket接口划分namespace命名空间)如下图所示:每个命名空间都是独立存在的,命名空间里面的进程都无法看到空间之外的进程、用户、网络等等信息。将进程的“视野”锁定在容器规定的范围内,如此一来,容器内的进程再也看不到外面的系统资源。
CPU限制率:CGroup
通过上述的两个命令,试着运行了一段时间,一切都在Docker的运行之中,容器中的进程都能正常的运行,都能通过虚拟文件系统和隔离出来的系统环境来运行。
但这个时候redis、nginx等进程也开始加入,这个时候就容易出现问题了,内存容易被Redis等用光,这样Docker就崩了。如果容器中的某个进程可以随意的占用内存、cpu、网络、硬盘等各种资源,那么Docker肯定会崩掉。于是有了CGroup命令来限制资源使用。
CGroup是Linux帝国的一套机制,通过它可以划定一个个的分组,然后限制每个分组能够使用的资源,比如内存的上限值、CPU的使用率、硬盘空间总量等等。系统内核会自动检查和限制这些分组中的进程资源使用量。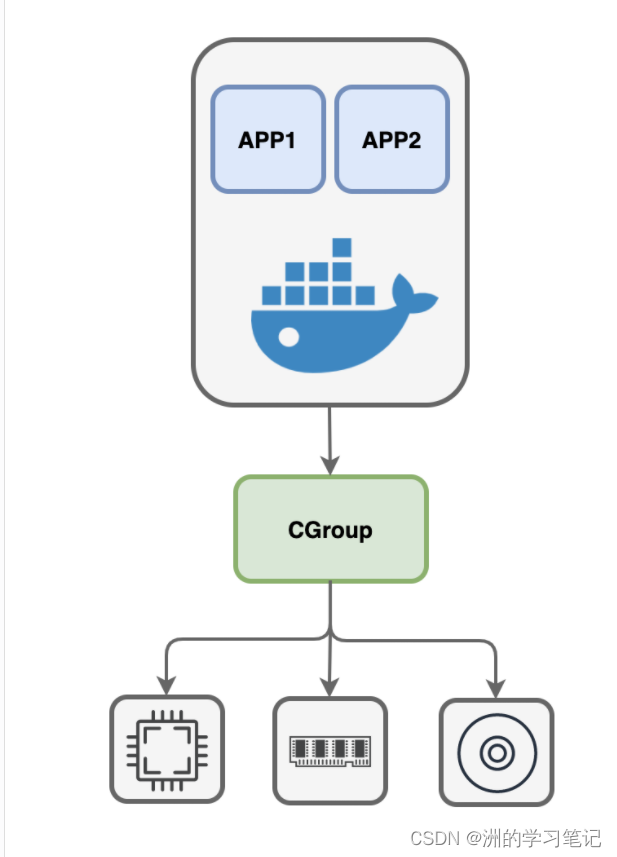
3、简单理解镜像
将这些容器运行时所需要的所有的文件集合称之为容器镜像。
通常情况下,会采用 Dockerfile 来构建镜像,这是因为 Dockerfile 提供了非常便利的语法糖,能够很好地描述构建的每个步骤。当然,每个构建步骤都会对已有的文件系统进行操作,这样就会带来文件系统内容的变化,我们将这些变化称之为 changeset。把构建步骤所产生的变化依次作用到一个空文件夹上,就能够得到一个完整的镜像。
changeset有几个很显著的特点:
- 能够提高分发效率,对于大的镜像而言,如果将其拆分成各个小块就能够提高镜像的分发效率,这是因为镜像拆分之后就可以并行下载这些数据;
- 因为这些数据是相互共享的,也就意味着当本地存储上包含了一些数据的时候,只需要下载本地没有的数据即可,举个简单的例子就是 golang 镜像是基于 alpine 镜像进行构建的,当本地已经具有了 alpine 镜像之后,在下载 golang 镜像的时候只需要下载本地 alpine 镜像中没有的部分即可;
- 因为镜像数据是共享的,因此可以节约大量的磁盘空间,简单设想一下,当本地存储具有了 alpine 镜像和 golang 镜像,在没有复用的能力之前,alpine 镜像具有 5M 大小,golang 镜像有 300M 大小,因此就会占用 305M 空间;而当具有了复用能力之后,只需要 300M 空间即可。
4、构造镜像代码
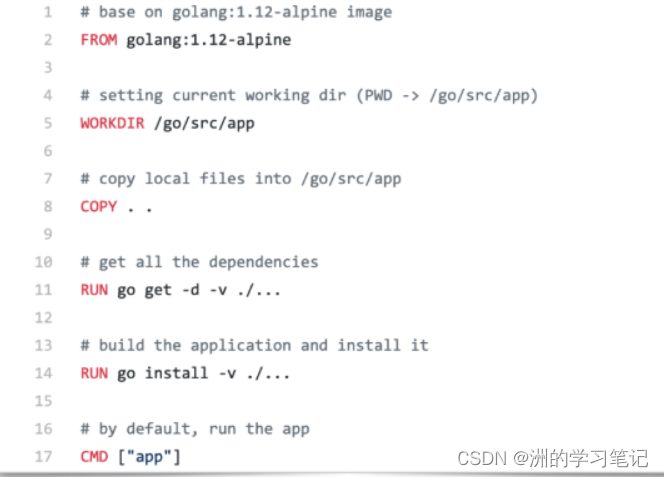
上述的Dockerfile适用于描述如何构建golang应用,每一行的意思大致如下:
- FROM 行表示以下的构建步骤基于什么镜像进行构建,正如前面所提到的,镜像是可以复用的;
- WORKDIR 行表示会把接下来的构建步骤都在哪一个相应的具体目录下进行,其起到的作用类似于 Shell 里面的 cd;
- COPY 行表示的是可以将宿主机上的文件拷贝到容器镜像内;
- RUN 行表示在具体的文件系统内执行相应的动作。当我们运行完毕之后就可以得到一个应用了;
- CMD 行表示使用镜像时的默认程序名字。
当有了 Dockerfile 之后,就可以通过 docker build 命令构建出所需要的应用。构建出的结果存储在本地,一般情况下,镜像构建会在打包机或者其他的隔离环境下完成。
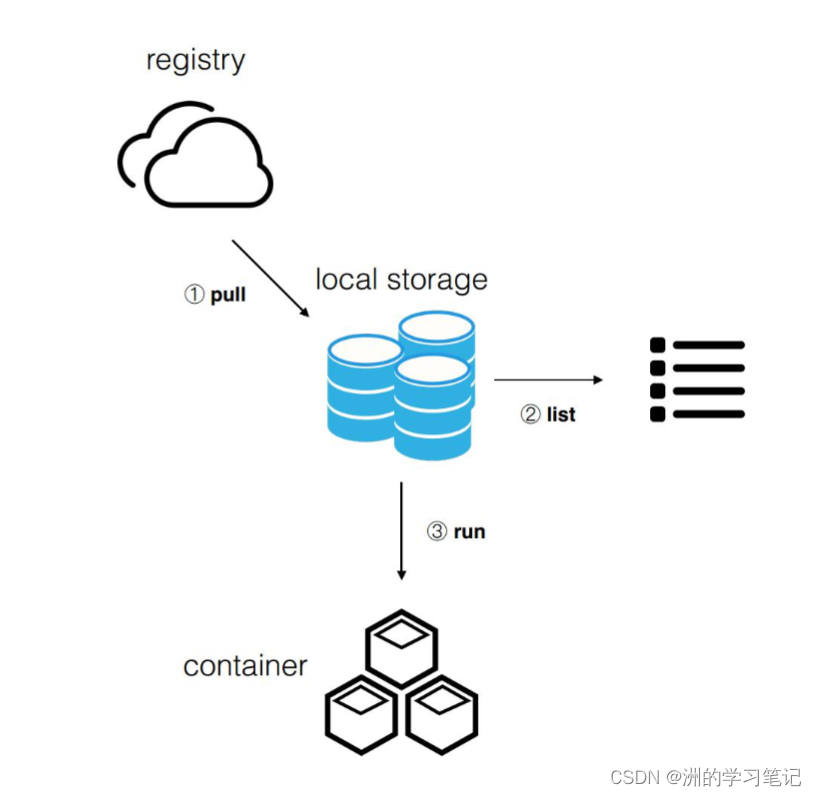
这些镜像如何运行在生产环境或者测试环境上呢?这时候就需要一个中转站或者中心存储,我们称之为 docker registry,也就是镜像仓库,其负责存储所有产生的镜像数据。我们只需要通过 docker push 就能够将本地镜像推动到镜像仓库中,这样一来,就能够在生产环境上或者测试环境上将相应的数据下载下来并运行了。
5、如何运行容器
第一步:从镜像仓库中将相应的镜像下载下来;
第二步:当镜像下载完成之后就可以通过 docker images 来查看本地镜像,这里会给出一个完整的镜像列表,可以在列表中选中想要的镜像;
第三步:当选中镜像之后,就可以通过 docker run 来运行这个镜像得到想要的容器,当然可以通过多次运行得到多个容器。一个镜像就相当于是一个模板,一个容器就像是一个具体的运行实例,因此镜像就具有了一次构建、到处运行的特点。
6、容器生命周期与数据管理
容器是一组具有隔离特性的进程集合,在使用 docker run 的时候会选择一个镜像来提供独立的文件系统并指定相应的运行程序。这里指定的运行程序称之为 initial 进程,这个 initial 进程启动的时候,容器也会随之启动,当 initial 进程退出的时候,容器也会随之退出。
因此,可以认为容器的生命周期和 initial 进程的生命周期是一致的。当然,因为容器内不只有这样的一个 initial 进程,initial 进程本身也可以产生其他的子进程或者通过 docker exec 产生出来的运维操作,也属于 initial 进程管理的范围内。当 initial 进程退出的时候,所有的子进程也会随之退出,这样也是为了防止资源的泄漏。
但是这样的做法也会存在一些问题,首先应用里面的程序往往是有状态的,其可能会产生一些重要的数据,当一个容器退出被删除之后,数据也就会丢失了,这对于应用方而言是不能接受的,所以需要将容器所产生出来的重要数据持久化下来。容器能够直接将数据持久化到指定的目录上,这个目录就称之为数据卷。
数据卷有一些特点,其中非常明显的就是数据卷的生命周期是独立于容器的生命周期的,也就是说容器的创建、运行、停止、删除等操作都和数据卷没有任何关系,因为它是一个特殊的目录,是用于帮助容器进行持久化的。简单而言,我们会将数据卷挂载到容器内,这样一来容器就能够将数据写入到相应的目录里面了,而且容器的退出并不会导致数据的丢失。
7、VMware与容器对比
VM 利用 Hypervisor 虚拟化技术来模拟 CPU、内存等硬件资源,这样就可以在宿主机上建立一个 Guest OS,这是常说的安装一个虚拟机。
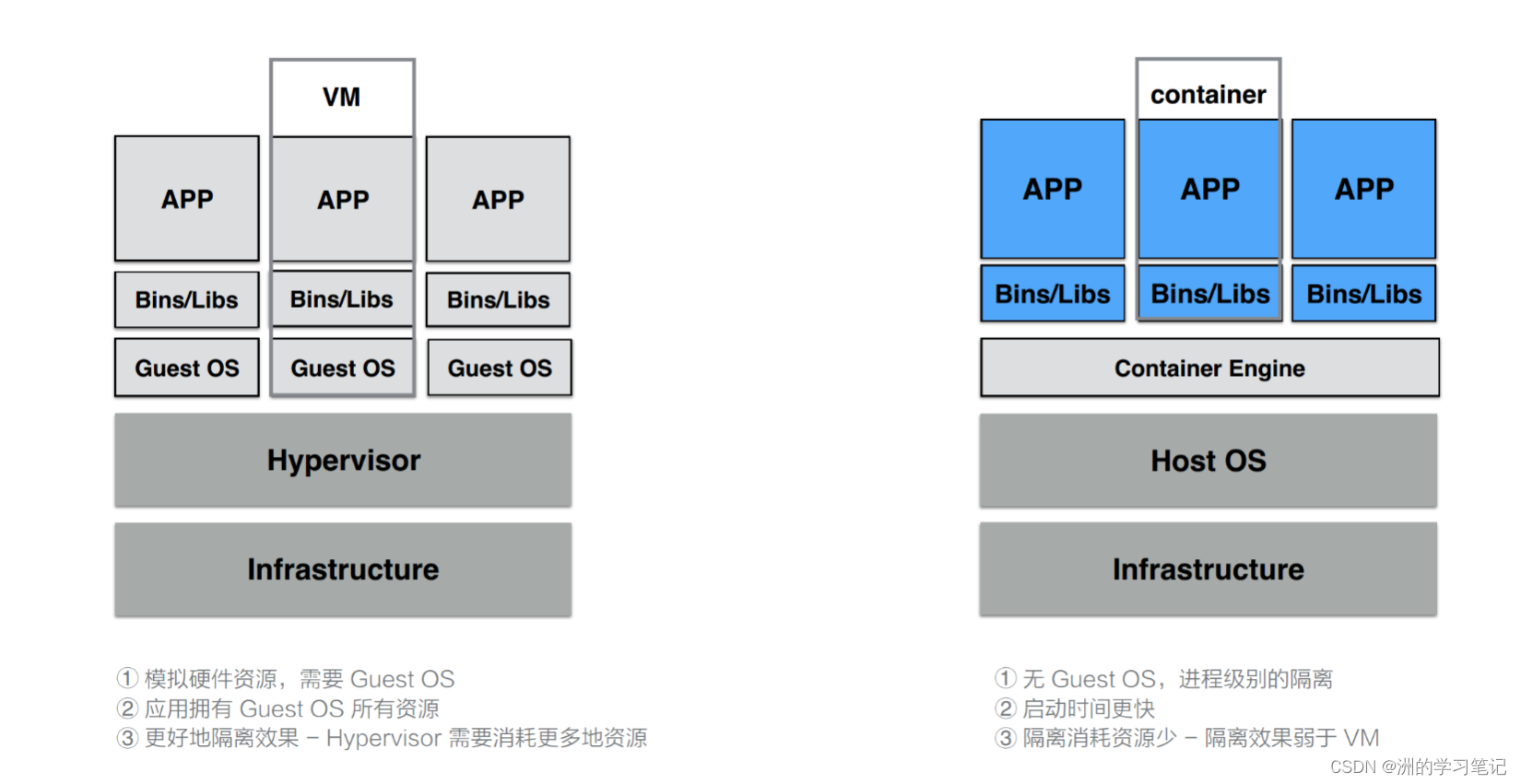
每一个 Guest OS 都有一个独立的内核,比如 Ubuntu、CentOS 甚至是 Windows 等,在这样的 Guest OS 之下,每个应用都是相互独立的,VM 可以提供一个更好的隔离效果。但这样的隔离效果需要付出一定的代价,因为需要把一部分的计算资源交给虚拟化,这样就很难充分利用现有的计算资源,并且每个 Guest OS 都需要占用大量的磁盘空间,比如 Windows 操作系统的安装需要 10~30G 的磁盘空间,Ubuntu 也需要 5~6G,同时这样的方式启动很慢。正是因为虚拟机技术的缺点,催生出了容器技术。
容器是针对于进程而言的,因此无需 Guest OS,只需要一个独立的文件系统提供其所需要文件集合即可。所有的文件隔离都是进程级别的,因此启动时间快于 VM,并且所需的磁盘空间也小于 VM。但是相对的进程级别的隔离并没有想象中的那么好,隔离效果相比 VM 要差很多。
完结:Docker容器总结
如下图所示,左边是普通的操作系统管理进程,而右边是使用了容器之后的。
二、Kubernetes
Kubernetes,从官方网站上可以看到,它是一个工业级的容器编排平台。Kubernetes 这个单词是希腊语,它的中文翻译是“舵手”或者“飞行员”。在一些常见的资料中也会看到“ks”这个词,也就是“k8s”,它是通过将8个字母“ubernete ”替换为“8”而导致的一个缩写。简单来说,K8s就是用来帮助我们管理容器的一个应用,是容器编排平台。
1、K8s核心功能
- 服务的发现与负载的均衡;
- 容器的自动装箱,会把它叫做 scheduling,就是“调度”,把一个容器放到一个集群的某一个机器上,Kubernetes 会帮助我们去做存储的编排,让存储的声明周期与容器的生命周期能有一个连接;
- Kubernetes 会帮助我们去做自动化的容器的恢复。在一个集群中,经常会出现宿主机的问题或者说是 OS 的问题,导致容器本身的不可用,Kubernetes 会自动地对这些不可用的容器进行恢复;
- Kubernetes 会帮助我们去做应用的自动发布与应用的回滚,以及与应用相关的配置密文的管理;
- 对于 job 类型任务,Kubernetes 可以去做批量的执行;
- 使得这个集群、这个应用更富有弹性,Kubernetes 支持水平的伸缩。
下面,以三个例子切实地介绍一下 Kubernetes 的能力:
调度功能
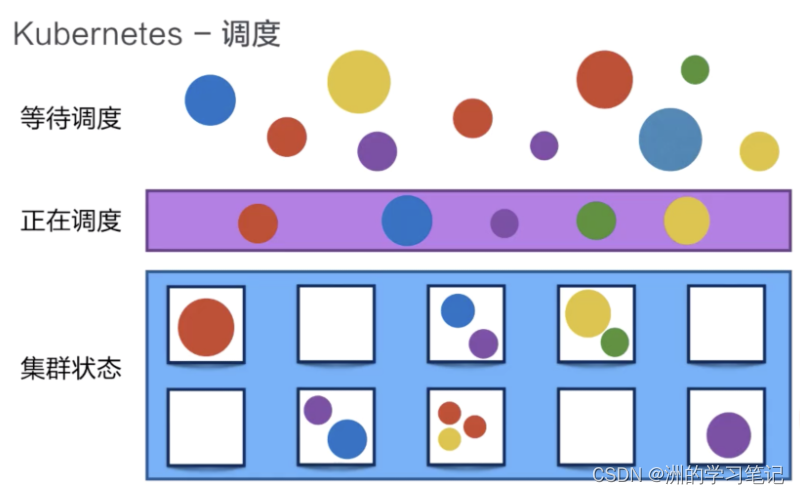
Kubernetes 可以把用户提交的容器放到 Kubernetes 管理的集群的某一台节点上去。Kubernetes 的调度器是执行这项能力的组件,它会观察正在被调度的这个容器的大小、规格。
比如说它所需要的 CPU以及它所需要的 memory,然后在集群中找一台相对比较空闲的机器来进行一次 placement,也就是一次放置的操作。在这个例子中,它可能会把红颜色的这个容器放置到第二个空闲的机器上,来完成一次调度的工作。
自动修复
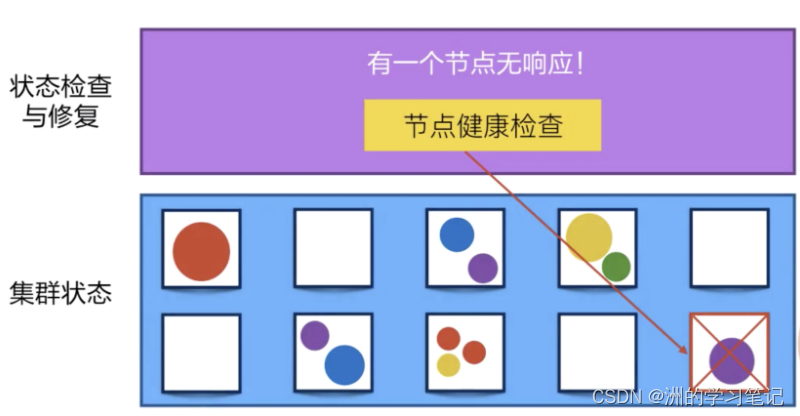
Kubernetes 有一个节点健康检查的功能,它会监测这个集群中所有的宿主机,当宿主机本身出现故障,或者软件出现故障的时候,这个节点健康检查会自动对它进行发现。
下面 Kubernetes 会把运行在这些失败节点上的容器进行自动迁移,迁移到一个正在健康运行的宿主机上,来完成集群内容器的一个自动恢复。
水平伸缩
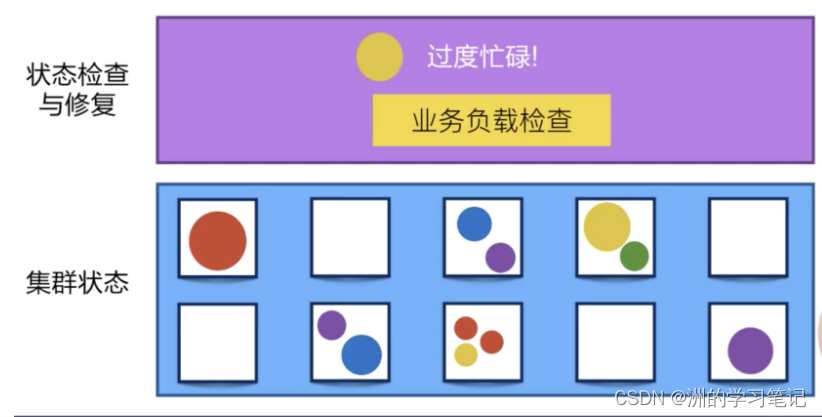
Kubernetes 有业务负载检查的能力,它会监测业务上所承担的负载,如果这个业务本身的 CPU 利用率过高,或者响应时间过长,它可以对这个业务进行一次扩容。
在下面的例子中,黄颜色的过度忙碌,Kubernetes 就可以把黄颜色负载从一份变为三份。接下来,它就可以通过负载均衡把原来打到第一个黄颜色上的负载平均分到三个黄颜色的负载上去,以此来提高响应的时间。
2、K8s核心架构
核心架构之Master
Kubernetes 架构是比较典型的二层架构和 server-client 架构。Master 作为中央的管控节点,会去与 Node 进行一个连接。
所有 UI 的、clients、这些 user 侧的组件,只会和 Master 进行连接,把希望的状态或者想执行的命令下发给 Master,Master 会把这些命令或者状态下发给相应的节点,进行最终的执行。
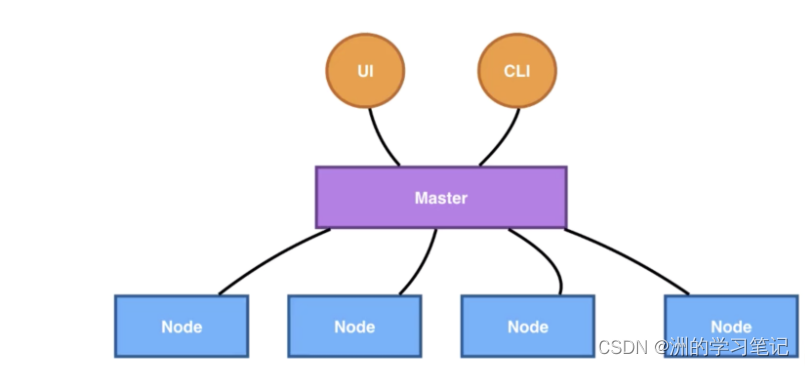
其中,Kubernetes 的 Master 包含四个主要的组件:API Server、Controller、Scheduler 以及 etcd。
- API Server:顾名思义是用来处理 API 操作的,Kubernetes 中所有的组件都会和 API Server 进行连接,组件与组件之间一般不进行独立的连接,都依赖于 API Server 进行消息的传送;
- Controller:是控制器,它用来完成对集群状态的一些管理。比如刚刚我们提到的两个例子之中,第一个自动对容器进行修复、第二个自动进行水平扩张,都是由Kubernetes 中的 Controller 来进行完成的;
- Scheduler:是调度器,“调度器”顾名思义就是完成调度的操作,就是我们刚才介绍的第一个例子中,把一个用户提交的 Container,依据它对 CPU、对 memory 请求大小,找一台合适的节点,进行放置;
- etcd:是一个分布式的一个存储系统,API Server 中所需要的这些原信息都被放置在 etcd 中,etcd 本身是一个高可用系统,通过 etcd 保证整个 Kubernetes 的 Master 组件的高可用性。
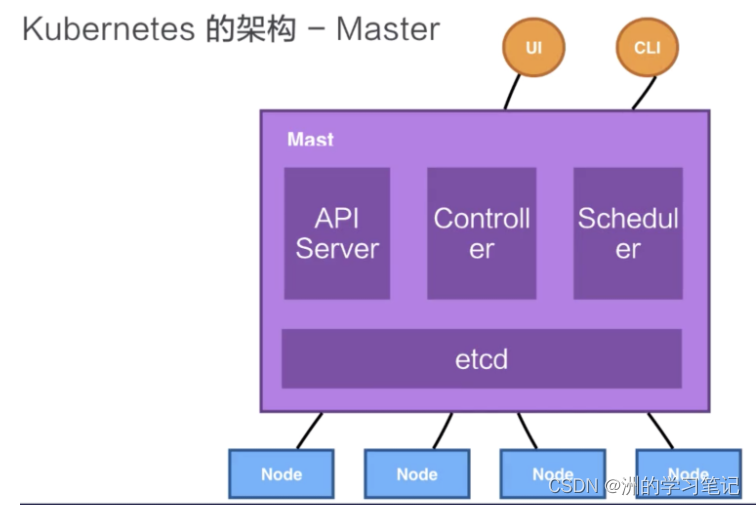
核心架构之Node
Kubernetes 的 Node 是真正运行业务负载的,每个业务负载会以 Pod 的形式运行。一个 Pod 中运行的一个或者多个容器,真正去运行这些 Pod 的组件的是叫做 kubelet,也就是 Node 上最为关键的组件,它通过 API Server 接收到所需要 Pod 运行的状态,然后提交到这个 Container Runtime 组件中。
在 OS 上去创建容器所需要运行的环境,最终把容器或者 Pod 运行起来,需要对存储跟网络进行管理。Kubernetes 并不会直接进行网络存储的操作,而是会靠 Storage Plugin 或者是网络的 Plugin 来进行操作。
用户自己或者云厂商都会去写相应的 Storage Plugin 或者 Network Plugin,去完成存储操作或网络操作。
在 Kubernetes 自己的环境中,也会有 Kubernetes 的 Network,它是为了提供 Service network 来进行搭网组网的。真正完成 service 组网的组件的是 Kube-proxy,它是利用了 iptable 的能力来进行组建 Kubernetes 的 Network,就是 cluster network,以上就是 Node 上面的四个组件。
Kubernetes 的 Node 并不会直接和 user 进行交互,而只会通过 Master。而 User 是通过 Master 向节点下发这些信息的。Kubernetes 每个 Node 上,都会运行刚才提到的这几个组件。
K8s核心概念1:Pod
Pod 是 Kubernetes 的一个最小调度及资源单元。用户可以通过 Kubernetes 的 Pod API 生产一个 Pod,让 Kubernetes 对这个 Pod 进行调度,也就是把它放在某一个 Kubernetes 管理的节点上运行起来。一个 Pod 简单来说是对一组容器的抽象,它里面一般会包含一个或多个容器。
比如下图中,包含了两个容器,每个容器可以指定它所需要资源大小。比如说,一个核一个 G,或者说 0.5 个核,0.5 个 G。在这个 Pod 中也可以包含一些其他所需要的资源:比如说我们所看到的 Volume 卷这个存储资源;比如说我们需要 100 个 GB 的存储或者 20GB 的另外一个存储。
在 Pod 里面,可以去定义容器所需要运行的方式。运行容器的 Command,以及运行容器的环境变量等等。Pod 这个抽象也给这些容器提供了一个共享的运行环境,它们会共享同一个网络环境,这些容器可以用 localhost 来进行直接的连接。而 Pod 与 Pod 之间,是互相有 isolation 隔离的。

K8s核心概念2:Volume
Volume 就是卷的概念,是用来管理 Kubernetes 存储的,用来声明在 Pod 中的容器可以访问文件目录的,一个卷可以被挂载在 Pod 中一个或者多个容器的指定路径下面。
Volume 本身是一个抽象的概念,一个 Volume 可以去支持多种的后端的存储。比如说 Kubernetes 的 Volume 就支持了很多存储插件,它可以支持本地的存储,可以支持分布式的存储,比如说像 ceph,GlusterFS ;它也可以支持云存储,阿里云上的云盘、AWS 上的云盘、Google 上的云盘等等。

K8s核心概念3:Deployment
Deployment 是在 Pod 这个抽象上更为上层的一个抽象,它可以定义一组 Pod 的副本数目、以及这个 Pod 的版本。一般用 Deployment 这个抽象来做应用的真正的管理,而 Pod 是组成 Deployment 最小的单元。Kubernetes 是通过 Controller,也就是我们刚才提到的控制器去维护 Deployment 中 Pod 的数目,它也会去帮助 Deployment 自动恢复失败的 Pod。
可以定义一个 Deployment,这个 Deployment 里面需要两个 Pod,当一个 Pod 失败的时候,控制器就会监测到,它重新把 Deployment 中的 Pod 数目从一个恢复到两个,通过再去新生成一个 Pod。通过控制器,会完成发布的策略。比如进行滚动升级,进行重新生成的升级,进行版本的回滚。
K8s核心概念4:Service
Service 的作用是:提供了一个或者多个 Pod 实例的稳定访问地址。
一个 Deployment 可能有两个甚至更多个完全相同的 Pod。对于一个外部的用户来讲,访问哪个 Pod 其实都是一样的,所以它希望做一次负载均衡,在做负载均衡的同时,若只想访问某一个固定的 VIP,也就是 Virtual IP 地址,并不用得知每一个具体的 Pod 的 IP 地址。
如果Pod本身终止失败了,可能会换成一个新的。对一个外部用户来讲,提供了多个具体的 Pod 地址,这个用户要不停地去更新 Pod 地址,当这个 Pod 再失败重启之后,所以希望有一个抽象,把所有 Pod 的访问能力抽象成一个第三方的一个 IP 地址,而实现这个的 Kubernetes 的抽象就叫 Service。
可以通过ClusterIP、NodePort、LoadBalanceer等方式来实现Service。
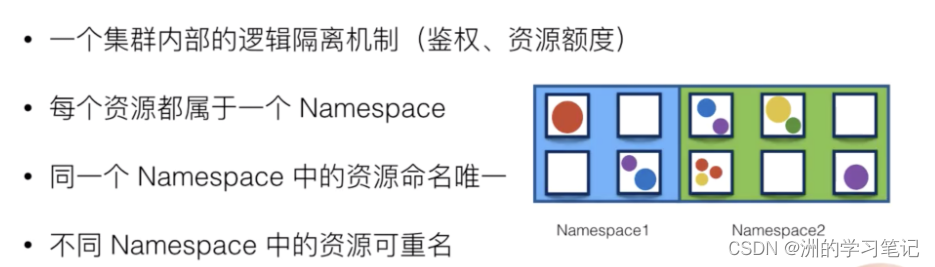
K8s核心概念5:Namespace
Namespace 是用来做一个集群内部的逻辑隔离的,它包括鉴权、资源管理等。Kubernetes 的每个资源,比如刚才讲的 Pod、Deployment、Service 都属于一个 Namespace,同一个 Namespace 中的资源需要命名的唯一性,不同的 Namespace 中的资源可以重名。
3、K8s的API
从 high-level 上看,Kubernetes API 是由 HTTP+JSON 组成的:用户访问的方式是 HTTP,访问的 API 中 content 的内容是 JSON 格式的。
比如说:对于这个 Pod 类型的资源,它的 HTTP 访问的路径,就是 API,然后是 apiVesion: V1, 之后是相应的 Namespaces,以及 Pods 资源,最终是 Podname,也就是 Pod 的名字。
如果去提交一个 Pod,或者 get 一个 Pod 的时候,它的 content 内容都是用 JSON 或者是 YAML 表达的。下图中有个 yaml 的例子,在这个 yaml file 中,对 Pod 资源的描述也分为几个部分。
-
第一个部分:API 的 version。比如在这个例子中是 V1,它也会描述我在操作哪个资源;比如说我的 kind 如果是 pod,在 Metadata 中,就写上这个 Pod 的名字;比如说 nginx,我们也会给它打一些 label。在 Metadata 中,有时候也会去写 annotation,也就是对资源的额外的一些用户层次的描述。
-
比较重要的一个部分叫做 Spec,Spec 也就是我们希望 Pod 达到的一个预期的状态。比如说它内部需要有哪些 container 被运行;比如说这里面有一个 nginx 的 container,它的 image 是什么?它暴露的 port 是什么?当从 Kubernetes API 中去获取这个资源的时候,一般来讲在 Spec 下面会有一个项目叫 status,它表达了这个资源当前的状态;比如说一个 Pod 的状态可能是正在被调度、或者是已经 running、或者是已经被 terminates,就是被执行完毕了。

刚刚在 API 图之中,有个 metadata 叫做“label”,这个 label 可以是一组 KeyValuePair。
比如下图的第一个 pod 中,label 就可能是一个 color 等于 red,即它的颜色是红颜色。当然你也可以加其他 label,比如说 size: big 就是大小,定义为大的,它可以是一组 label。
这些 label 是可以被 selector,也就是选择器所查询的。这个能力实际上跟sql 类型的 select 语句是非常相似的,比如下图中的三个 Pod 资源中,就可以进行 select。name color 等于 red,就是它的颜色是红色的,我们也可以看到,只有两个被选中了,因为只有他们的 label 是红色的,另外一个 label 中写的 color 等于 yellow,也就是它的颜色是黄色,是不会被选中的。

通过 label,kubernetes 的 API 层就可以对这些资源进行一个筛选,那这些筛选也是 kubernetes 对资源的集合所表达默认的一种方式。
刚刚介绍的 Deployment,它可能是代表一组的 Pod,它是一组 Pod 的抽象,一组 Pod 就是通过 label selector 来表达的。当然我们刚才讲到说 service 对应的一组 Pod,就是一个 service 要对应一个或者多个的 Pod,来对它们进行统一的访问,这个描述也是通过 label selector 来进行 select 选取的一组 Pod。label 是一个非常核心的 kubernetes API 的概念。