前言:
问题引出:关闭Connection后,ResultSet结果集无法使用,ResultSet结果集不利于数据的管理。
具体看下面的示意图
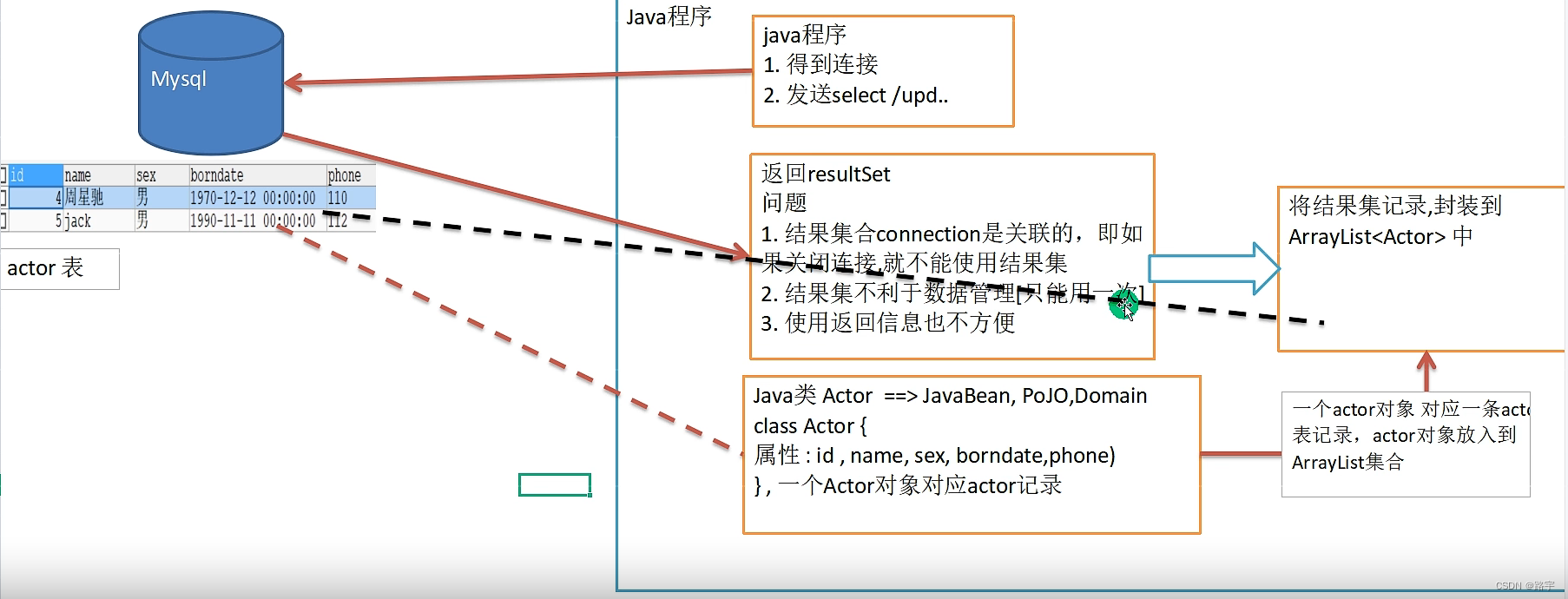
一、首先用自己的方法把ResultSet结果集封装到ArrayList集合中
代码如下
public class JDBCUtilsByDruid_Use {
//自己封装解决将ResultSet 封装到ArrayList中
@Test
public ArrayList<Actor> testSelectToArrayList() {
Connection connection = null;
String sql = "SELECT id,name,borndate,sex,phone FROM ACTOR WHERE id >= ?";
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
ArrayList<Actor> list = new ArrayList<>();//创建ArrayList对象,存放Actor对象
try {
//1.得到连接
connection = JDBCUtilsByDruid.getConnection();
System.out.println(connection.getClass());//class com.alibaba.druid.pool.DruidPooledConnection
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 2);
//执行得到结果集
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
String name = resultSet.getString("name");
String phone = resultSet.getString("phone");
int id = resultSet.getInt("id");
Date borndate = resultSet.getDate("borndate");
String sex = resultSet.getString("sex");
//把得到的resultSet的记录,封装到Actor对象,放入到List集合
list.add(new Actor(id, name, sex, borndate, phone));
}
System.out.println("list集合数据=" + list);
for (Actor actor : list) {
System.out.println(actor.getSex());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtilsByDruid.close(resultSet, preparedStatement, connection);
}
//因为ArrayList和Connection没有任何关联,所以该集合可以复用
return list;
}
}
二、使用Apache组织提供的一个开源JDBC工具库,它是对JDBC的封装,使用DBUtils能极大简化jdbc编码的工作量。
1、Apache-DBUtils的基本介绍

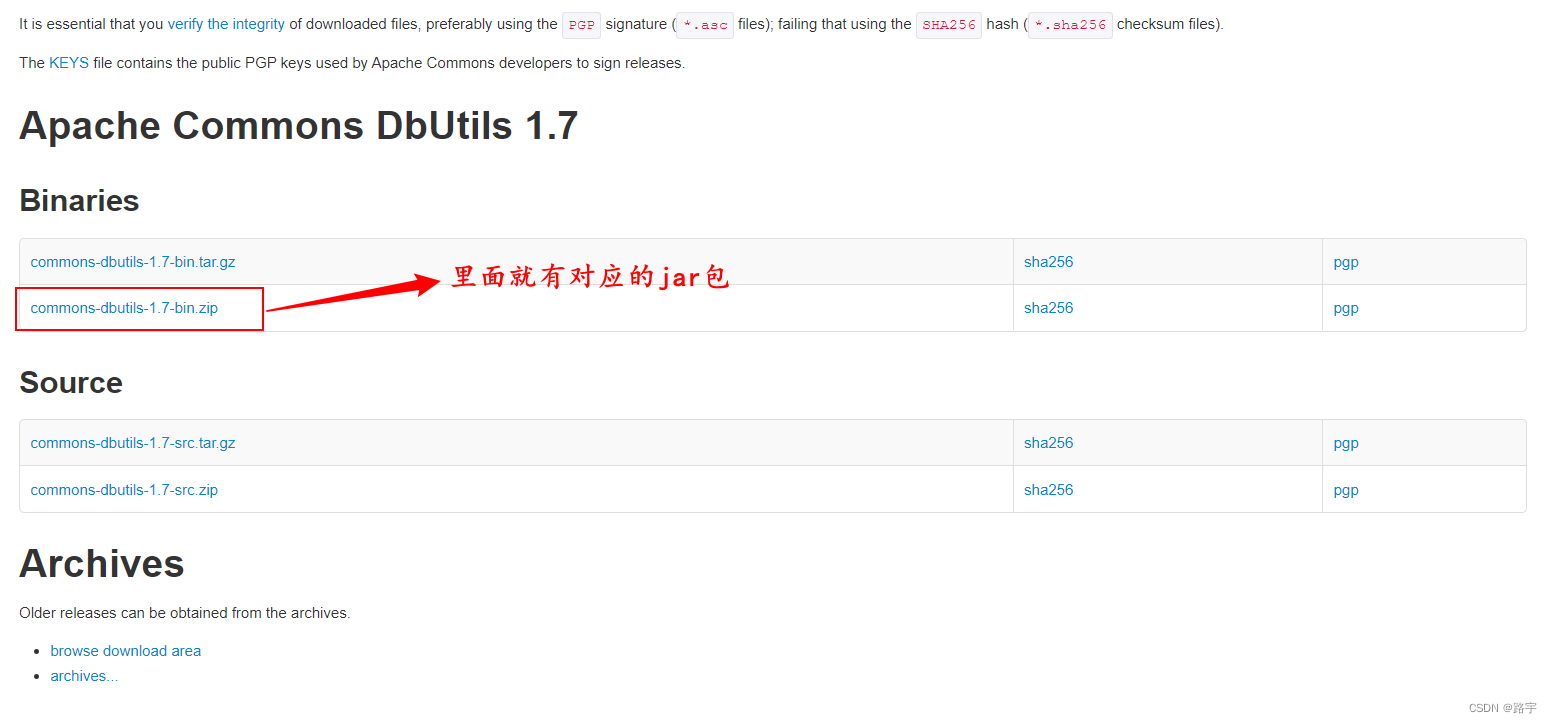
commons-dbutils-1.7.jar包的下载
下载对应的jar包即可
2、演示apache-DBUtils 工具类的使用
public class DBUtils_USE {
//使用apache-DBUtils 工具类 + druid 完成对表的crud操作
@Test
public void testQueryMany() throws SQLException {
//返回结果是多行的情况
Connection connection = JDBCUtilsByDruid.getConnection();
//使用DBUtils类和接口,放入DBUtils相关的jar,放入到本Project
//1.创建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//2.就可以执行相关的方法,返回ArrayList结果集
// String sql = "SELECT * FROM ACTOR WHERE id >= ?";
//注意:sql语句 也可以查询部分列
String sql = "SELECT id,name FROM ACTOR WHERE id >= ?";
//解读:
//1.query方法就是执行sql语句,得到resultSet --封装到-->ArrayList集合中
//2.返回集合
//3.connection:连接
//4.sql:执行sql语句
//5.new BeanListHandler<>(Actor.class):在将resultSet ->Actor对象->封装到ArrayList中
//底层使用反射机制,去获取Actor类的属性,进行封装
//6. 1 就是给sql语句中的?号赋值的,可以有多个值,因为是可变参数 Object... params
//7.底层得到的resultSet,会在query()方法关闭,prepareStatement关闭
/**
* 分析:queryRunner.query方法
* private <T> T query(Connection conn, boolean closeConn, String sql, ResultSetHandler<T> rsh, Object... params) throws SQLException {
* if (conn == null) {
* throw new SQLException("Null connection");
* } else if (sql == null) {
* if (closeConn) {
* this.close(conn);
* }
*
* throw new SQLException("Null SQL statement");
* } else if (rsh == null) {
* if (closeConn) {
* this.close(conn);
* }
*
* throw new SQLException("Null ResultSetHandler");
* } else {
* PreparedStatement stmt = null; //定义PreparedStatement
* ResultSet rs = null; //接收返回的ResultSet
* Object result = null; //返回ArrayList
*
* try {
* stmt = this.prepareStatement(conn, sql); //创建PreparedStatement
* this.fillStatement(stmt, params); //对SQL 进行? 赋值
* rs = this.wrap(stmt.executeQuery());//执行sql,返回resultSet
* result = rsh.handle(rs); //返回的resultSet-->arrayList[resultSet][使用反射,对传入的class对象处理]
* } catch (SQLException var33) {
* this.rethrow(var33, sql, params);
* } finally {
* try {
* this.close(rs);//关闭resultSet
* } finally {
* this.close(stmt); //关闭PrepareStatement
* if (closeConn) {
* this.close(conn);
* }
*
* }
* }
*
* return result;
* }
* }
*/
List<Actor> list = queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
System.out.println("输出集合的信息");
for (Actor actor : list) {
System.out.println(actor);
}
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
//使用apache-DBUtils 工具类 + druid 完成 返回的结果是单行记录(单个对象)
@Test
public void testQuerySingle() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
//使用DBUtils类和接口,放入DBUtils相关的jar,放入到本Project
//1.创建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//2.就可以执行相关的方法,返回单个对象
String sql = "SELECT * FROM ACTOR WHERE id = ?";
//解读:
//因为我们返回的单行记录<-->单个对象,使用的Handler是BeanHandler
Actor actor = queryRunner.query(connection, sql, new BeanHandler<>(Actor.class), 3);
System.out.println(actor);
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
//使用apache-DBUtils 工具类 + druid 完成查询结果是单行单列-返回的就是object
@Test
public void testScaler() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
//使用DBUtils类和接口,放入DBUtils相关的jar,放入到本Project
//1.创建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//2.就可以执行相关的方法,返回单行单列,返回的就是Object
String sql = "SELECT name FROM ACTOR WHERE id = ?";
//解读:
//因为我们返回的单行记录<-->单个对象,使用的Handler是BeanHandler
//解读:因为返回的是一个对象,使用的handler就是ScalarHandler
Object object = queryRunner.query(connection, sql, new ScalarHandler(), 3);
System.out.println(object);//周润发
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
//使用apache-DBUtils 工具类 + druid 完成DML操作(insert,delete,update)
@Test
public void testDML() throws Exception {
//1.得到连接(druid)
Connection connection = JDBCUtilsByDruid.getConnection();
//2使用DBUtils类和接口,放入DBUtils相关的jar,放入到本Project
//3.创建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//4.这里组织sql完成update,insert,delete
// String sql = "UPDATE ACTOR SET NAME=? WHERE id = ?";
// String sql = "INSERT INTO ACTOR VALUES(NULL,?,?,?,?)";
String sql = "DELETE FROM ACTOR WHERE id = ?";
//解读:
//1.执行DML 操作是queryRunner.update()
//2.返回的值是受影响的行数
// int affectedRow = queryRunner.update(connection, sql, "张无忌", "男", "1979-01-01", "123456");
int affectedRow = queryRunner.update(connection, sql, 4);
System.out.println(affectedRow > 0 ? "执行成功" : "执行没有影响到表");//执行成功
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
}