第6章 数据库编程
1、理解ODBC连接数据库的方法
2、掌握数据库连接技术(JDBC)
3、掌握JavaWeb数据库编程
4、掌握数据库存储过程原理与编程
5、掌握数据库触发器原理与编程
6、掌握数据库游标的原理与编程
7、理解嵌入式SQL编程的过程
6.1 数据库连接技术(ODBC)
本节的主要内容
• 了解数据库编程的内容
• 了解ODBC的技术背景
• 掌握数据库ODBC的层次架构
• 理解ODBC访问数据库的过程
• 掌握ODBC数据源的配置方法
一、数据库编程简介
(1)客户端应用编程
(2)数据库服务器端编程
(3)编程结合ODBC/JDBC
二、ODBC的技术背景
在传统应用开发,应用系统通常选用特定的DBMS管理系统;
网络环境下,应用系统通常需要对多种数据库的实现互连和资源共享;
如果从一种DBMS改变到另一种DBMS,就意味着要重写应用程序;
而在同一应用系统中,编制多种能在不同的DBMS上运行的应用程序,显然不是可取的方法。
Microsoft推出了开放式数据库互连(Open DataBase Connectivity,简写为ODBC)技术。
ODBC实现了应用程序对多种不同DBMS的数据库的访问,实现了数据库连接方式的变革。
ODBC定义了一套基于SQL的、公共的、与数据库无关的API(应用程序设计接口);
使每个应用程序利用相同的源代码就可访问不同的数据库系统,存取多个数据库中的数据;
从而使得应用程序与数据库管理系统(DBMS)之间在逻辑上的独立性,使应用程序具有数据库无关性。
三、ODBC的层次结构
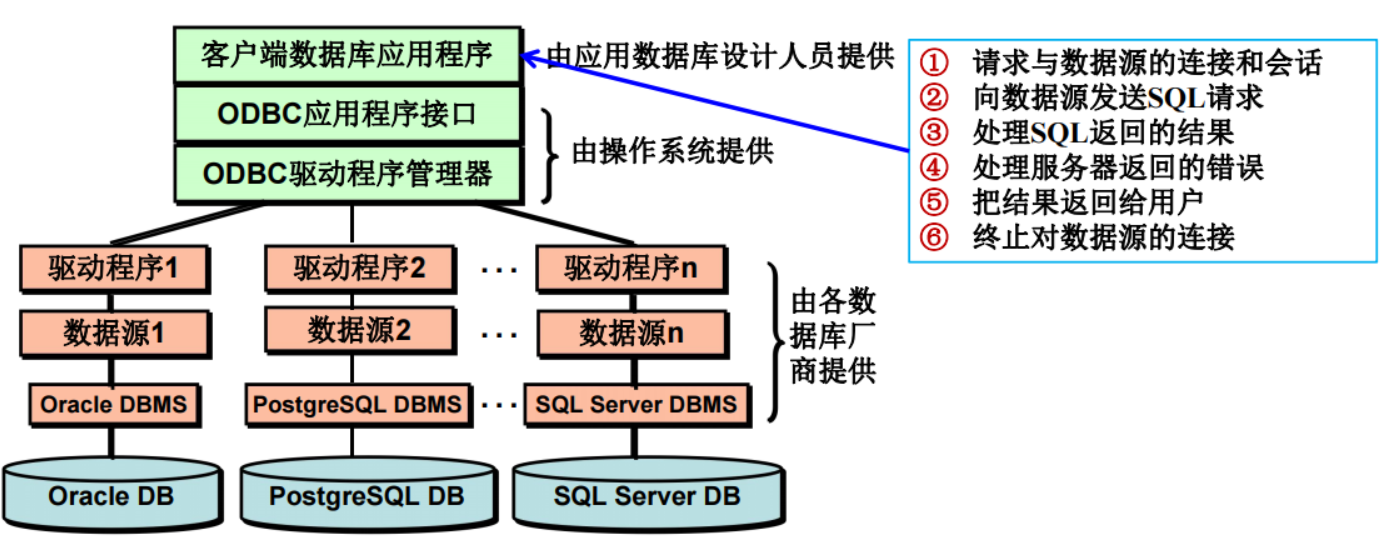
客户端数据库应用程序
- 请求与数据源的连接和会话
- 向数据源发送SQL请求
- 处理SQL返回的结果
- 处理服务器返回的错误
- 把结果返回给用户
- 终止对数据源的连接
ODBC应用程序接口
是ODBC提供并由应用程序调用,
实现应用程序与数据库互连的API。
ODBC驱动程序管理器
用于管理系统的各种驱动程序。
驱动程序
- 驱动程序是一个用于支持ODBC函数调用的模块,通常是一个动态链接库DLL。
- 不同RDBMS有不同的驱动程序;每种数据库都要向ODBC驱动程序管理器注册它自己的驱动程序;
- 建立与数据源的连接,向数据源提交请求;并进行据格式的转换;
- 返回结果给应用程序;并将错误信息转换为标准格式返回给应用程序。
数据源
- 数据源是驱动程序与数据库系统连接的桥梁。
- 它不是数据库系统,而是用于表达ODBC驱动程序与DBMS特殊连接的命名。
- 在连接中,用数据源名来代表用户名、服务器名、连接的数据库名等;
- 可以将数据源名看成是与一个具体数据库建立的连接;
- 创建数据源最简单的方法是使用Windows的ODBC驱动程序管理器
SQL Server DBMS
- 是用户向各数据库厂商购买的管理数据库的管理软件;
- 是管理数据库的系统软件;用户可以执行SQL语句;
- 创建数据库、表、视图等;
- 对数据库进行权限管理。
Oracle DB、PostgresQL DB、SQL Server DB
- 用户创建的数据库;
- 用于存储用户数据、对象。
四、应用程序使用ODBC访问数据库的步骤
① 首先必须用ODBC管理器注册一个数据源;
② 管理器根据数据源提供的数据库位置、数据库类型及ODBC驱动程序等信息,建立起ODBC与具体数据库的联系;
③ 应用程序只需将数据源名提供给ODBC,ODBC就能建立起与相应数据库的连接;
④ 这样,应用程序就可以通过驱动程序管理器与数据库交换信息;
⑤ 驱动程序管理器负责将应用程序对ODBC API的调用传递给正确的驱动程序;
⑥ 驱动程序在执行完相应的SQL操作后,将结果通过驱动程序管理器返回给应用程序
五、使用ODBC管理器配置数据源
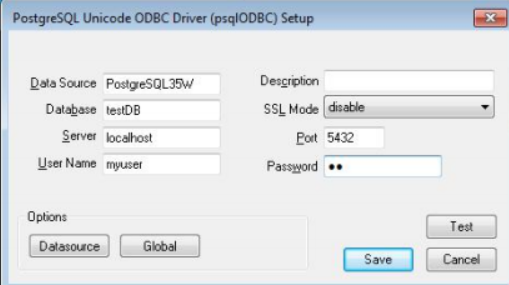
① 首先必须在数据库厂商的官网下载与你的数据库对应的驱动程序;
② 例如:名字为psqlodbc_x64.msi的驱动程序支持PostgreSQL 64位数据库;
③ 执行psqlodbc_x64.msi,安装PostgreSQL数据库驱动程序;
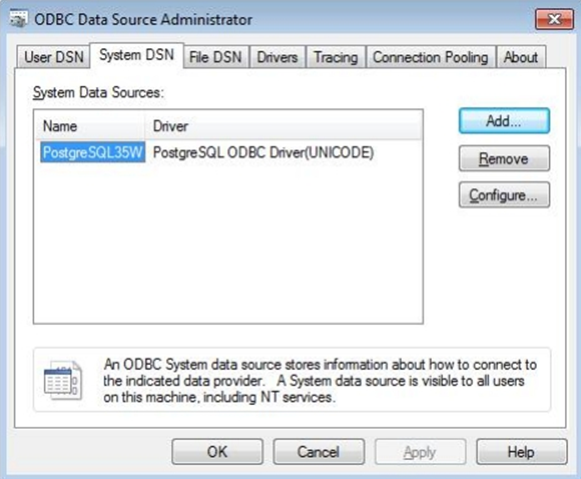
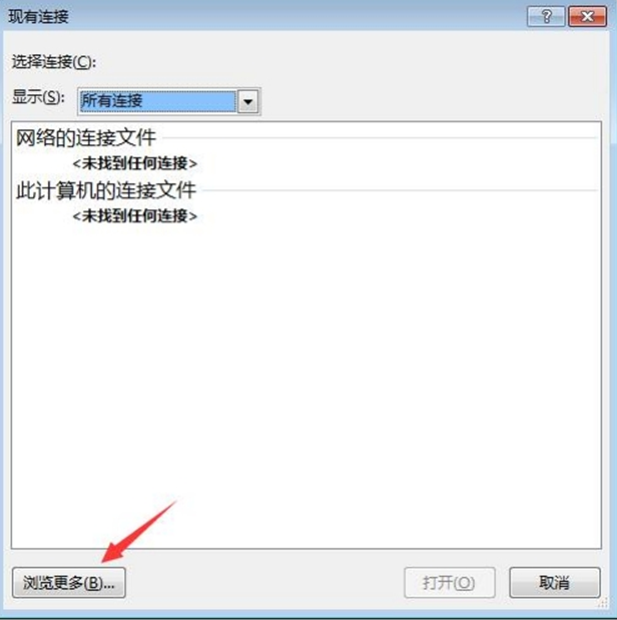
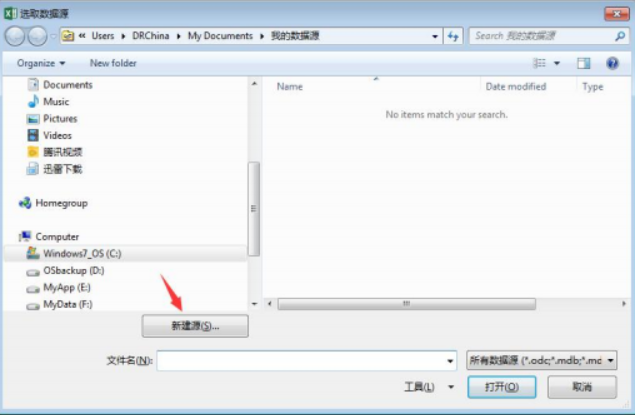
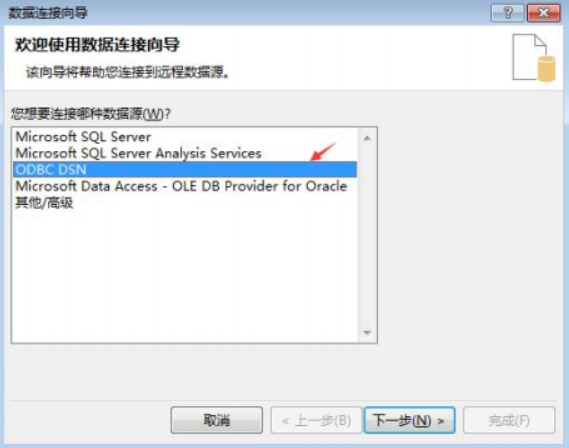
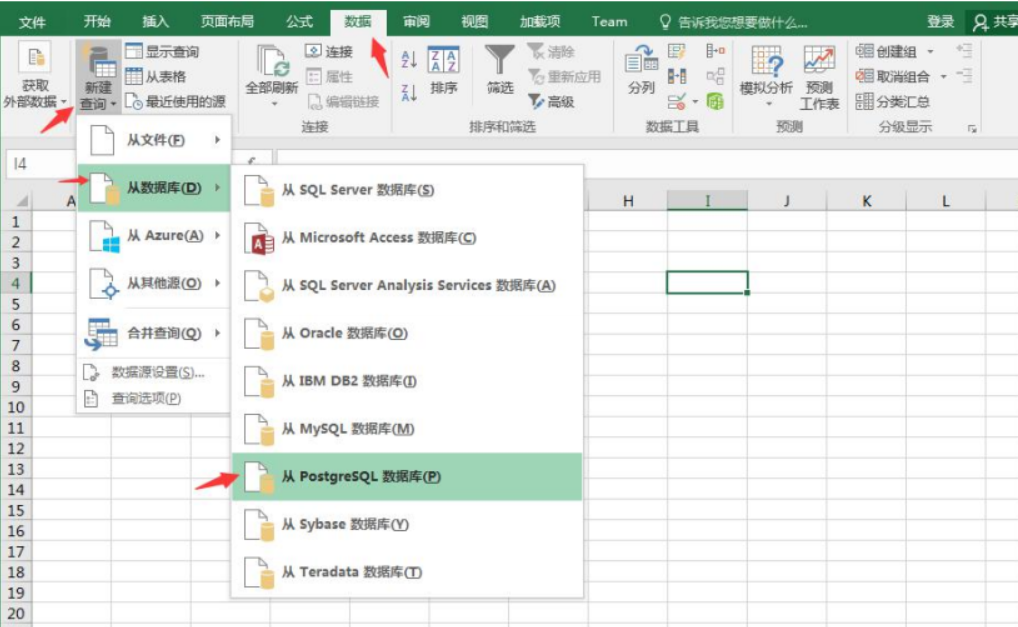
④ 打开windows 7的ODBC管理器,如下图:
6.2 数据库连接技术(JDBC)
本节的主要内容
• 了解什么是JDBC
• 掌握数据库JDBC的层次架构
• 理解应用程序使用JDBC访问数据库的步骤
• 掌握Java使用JDBC连接数据库的方法
一、什么是JDBC
• JDBC(Java DataBase Connectivity,Java数据库连接)技术的简称 ,是一种用于执行SQL语句的Java API。
• 它由一组用Java编程语言编写的类和接口组成。这个API由java.sql.*包中的一些类和接口组成,它为数据库开发人员提供了一个标准的API,使他们能够用纯Java API 来编写数据库应用程序。
• 注意:使用JDBC访问数据库需要相应数据库的JDBC驱动程序。
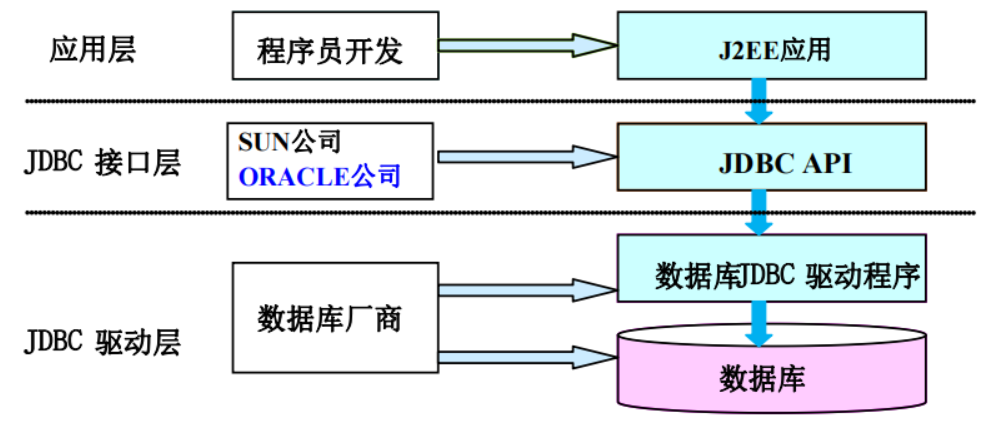
二、JDBC工作原理
三、JDBC程序访问数据库步骤
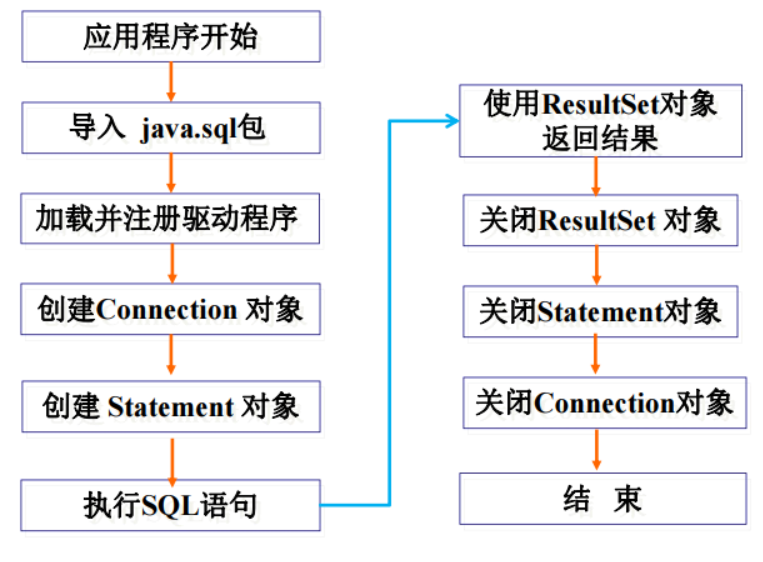
(1)加载驱动
• 加载JDBC驱动是通过调用方法:
Class.forName("驱动名字")
• 下面是PostgreSQL数据库驱动程序加载语句:
Class.forName("org.postgresql.Driver");
(2)建立连接
• 与数据库建立连接的方法是调用DriverManager.getConnection(String url)方法。
• 下面与PostgreSQL数据库建立连接的语句:
① String URL = "jdbc:postgresql://localhost:5432/testdb";
② String userName = "myuser";
③ String passWord = "sa";
④ connection conn = DriverManager.getConnection(URL,userName,passWord);
(3)创建Statement对象
• 可以用Connection对象的方法createStatement()创建Statement。
示例如下:
Statement stmt = conn.createStatement();
(4)执行SQL语句
• 创建了Statement对象 ,就可以向Statement对象发送SQL语句。主要掌握两种执
行SQL语句的方法:executeQuery()、executeUpdate()
• executeQuery():返回语句执行后的单个结果集的,所以通常用于select语句
• executeUpdate()返回值是一个整数,指示受影响的行数(可以用于update、
insert、delete语句)。
示例如下:
Statement stmt = conn.createStatement();
String sql = "INSERT INTO public.student (sid, sname, gender, birthday, major, phone)"
+ " VALUES ('2017001', '张山', '男', '1998-10-10','软件工程','13602810001')";
stmt.executeUpdate(sql);
(5)ResultSet保存结果集
• ResultSet对象它被称为结果集,它代表符合SQL语句条件的所有行,并且它通过
一套getXXX方法提供了对这些行中数据的访问。
• ResultSet里的数据一行一行排列,每行有多个字段,并且有一个记录指针,指针
所指的数据行叫做当前数据行,我们只能来操作当前的数据行。我们如果想要取
得某一条记录,就要使用ResultSet的next()方法 ,如果我们想要得到ResultSet里的
所有记录,就应该使用while循环。
示例代码如下:
Statement stmt = conn.createStatement();
String sql = "SELECT id, name, age FROM company";
ResultSet rs = stmt.executeQuery(sql);
(6)关闭连接
• 作为一种好的编程风格,在不需要ResultSet对象、Statement对象和Connection对
象时,应该显式地关闭它们。关闭这些对象的方法为: close() ;
示例:
① rs.close();//关闭结果集对象
② stmt.close();//关闭执行对象
③ conn.close();//关闭连接对象
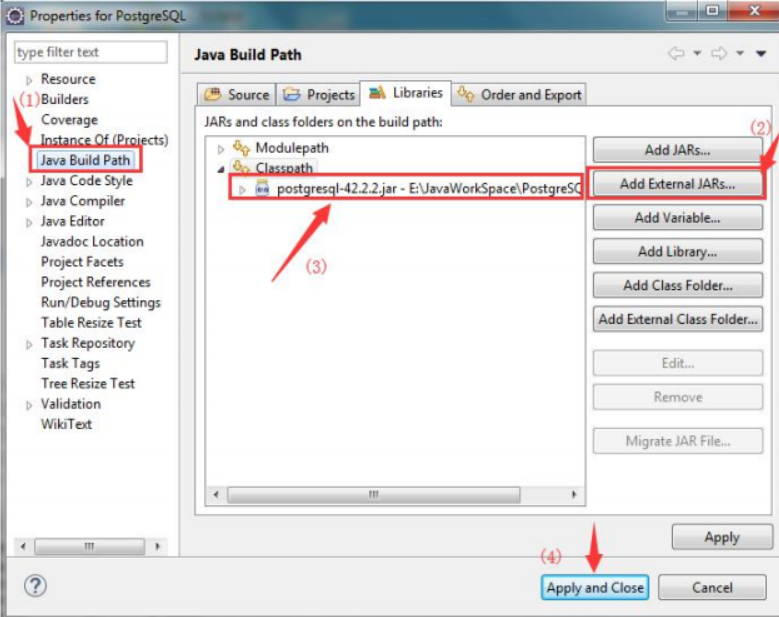
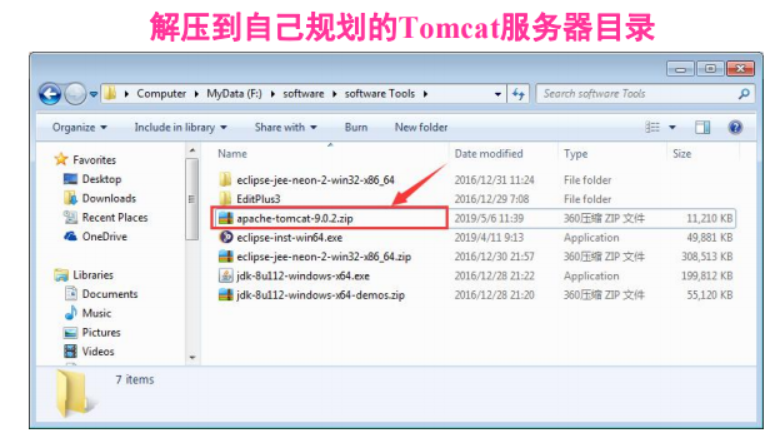
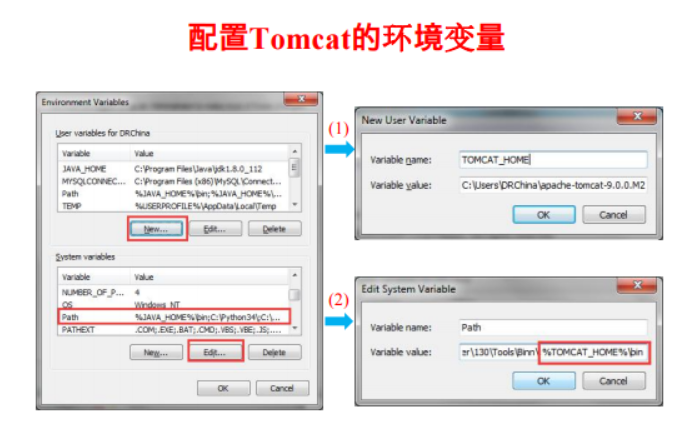
四、在Eclipse下使用JDBC连接数据库
• 在PostgreSQL官网下载JDBC驱动
程序包 postgresql-42.2.2.jar
• 在Eclipse中创建工程 PostgreSQL;
• 在PostgreSQL工程中创建jdbclib目
录,并将postgresql-42.2.2.jar拷贝
到该目录;
• 并在工程中做如右图配置
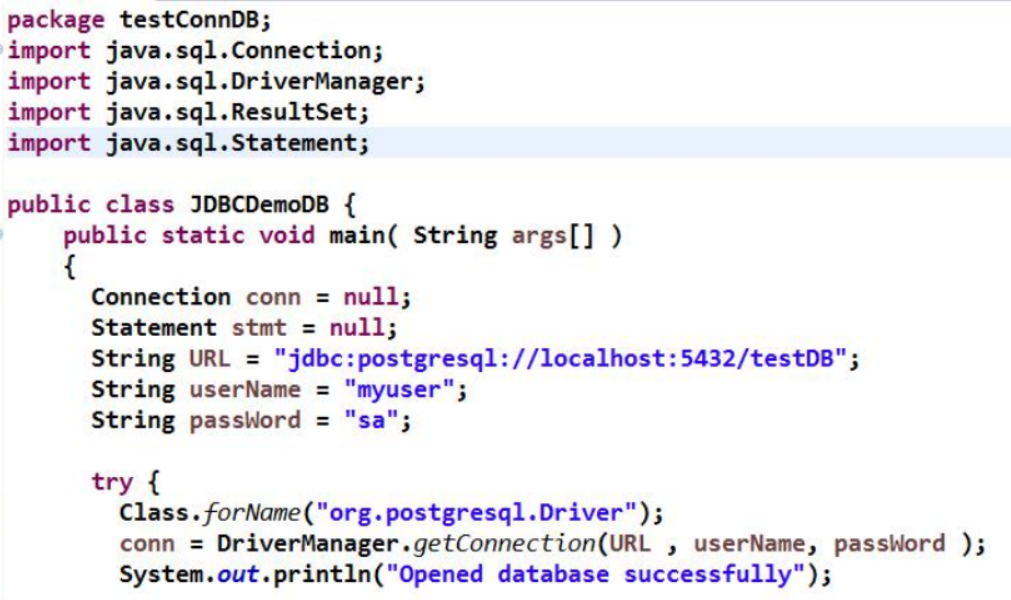
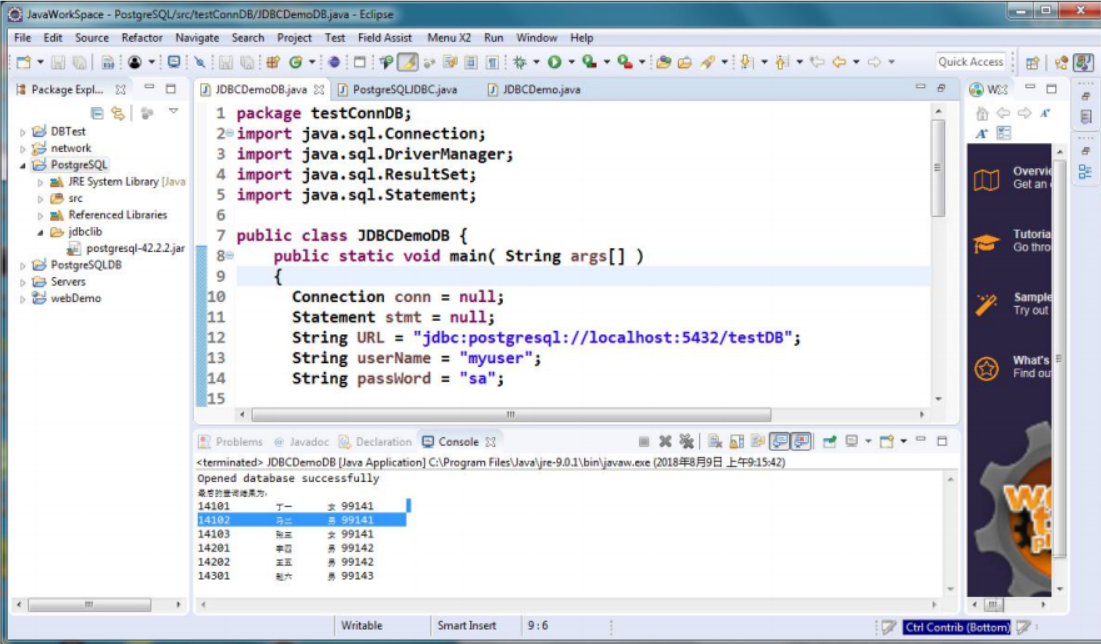
五、Java使用JDBC连接数据库的例子

五、Java使用JDBC连接数据库的例子运行结果
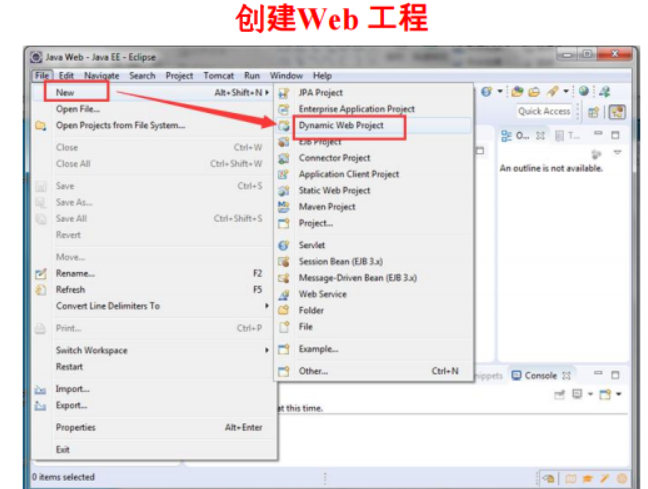
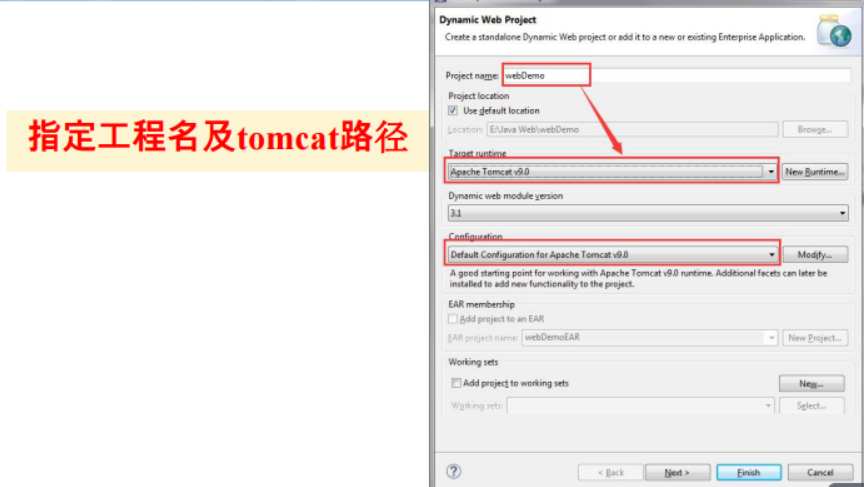
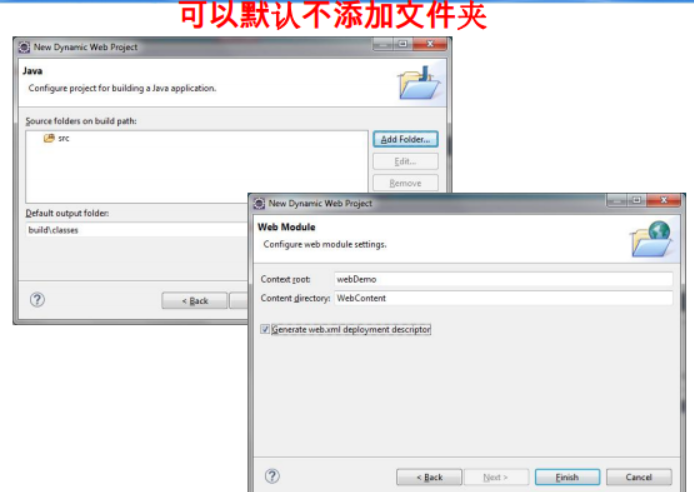
6.3 Java Web数据库编程
【本节的主要内容】
• Java web简介
• JSP工作过程
• Severlet工作
• Mybatise访问数据库
Web服务器介绍
① Java Web,是用Java技术来解决相关web互联网领域的技术总和。
② web包括:web服务器和web客户端两部分。
Java Web常用开发技术
进行Java Web项目的开发一般需要掌握如下几种技术:
① HTML
② CSS
③ JavaScript
④ Servlet技术
⑤ JSP技术
⑥ JavaBean技术
⑦ JDBC技术
⑧ XML
⑨ AJAX技术
Web服务器介绍
① Tomcat(Apache):当前应用最广的JavaWeb服务器;
② JBoss(Redhat红帽):支持JavaEE,应用比较广;
③ GlassFish(Oracle):Oracle开发JavaWeb服务器,应用不是很广;
④ Weblogic(Oracle):Oracle开发JavaWeb服务器,支持JavaEE,适合大型项目;
⑤ Websphere(IBM):IBM开发JavaWeb服务器,支持JavaEE,适合大型项目;
以上几款常用的服务器产品,用户可以根据自己的需要进行选择。本课程选用Apache
Tomcat作为JSP开发和运行的服务器,是一款开源软件,可作为独立的服务器来运行
JSP和Servlets,也可以集成在 Apache Web Server中。
Java Web IDE集成开发工具
① Eclipse 是 Java 的集成开发环境(IDE),是一个开源的、基于 Java 的可扩展开发平台 。Eclipse 也可以作为其它开发语言的集成开发环 境 , 如 C, C++, PHP, 和Ruby 等。
② MyEclipse企业级工作平台(MyEclipse Enterprise Workbench ,简称MyEclipse)是对EclipseIDE的扩展,利用它可以在数据库和JavaEE的开发、发布以及应用程序服务器的整合方面极大的提高工作效率。它是功能丰富的JavaEE集成开发环境,包括了完 备 的 编 码 、 调 试 、 测 试 和 发 布 功 能 , 完 整 支 持 HTML , Struts , JSP , CSS ,Javascript,Spring,SQL,Hibernate
③ IDEA 全称IntelliJ IDEA,是Java语言开发的集成环境,是JetBrains公司的产品;
IntelliJ在业界被公认为最好的Java开发工具之一。
Servlet的特点
Servlet是用Java语言编写的服务器端小程序,驻留在web服务器中,
并在其中运行,扩展了web服务器的动态处理功能。
什么是Servlet?
① 移植性好,本身是一个Java类,具有跨平台性;
② Java EE平台支持的全部Java API都可用于Servlet;
③ 安全性提高,服务器崩溃的可能性减小;
④ 多个Servlet可以组织在一起,输出可由组生成,有助于代码复用;
⑤ 可以与服务器中的其它组件交互
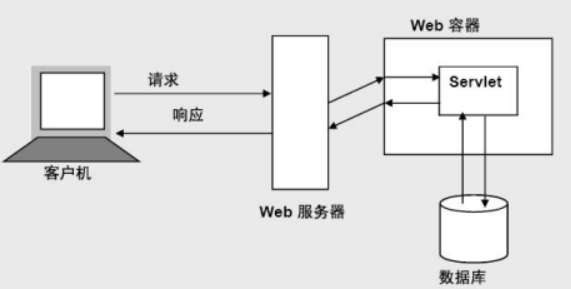
Servlet执行原理
① 客户机将HTTP 请求发送给Web 服务器
② Web 服务器将该请求转发给Servlet
③ Servlet 处理该请求
④ Servlet 将响应发送给Web 服务器
⑤ Web 服务器将响应转发给客户机
Web 容器
① Web 容器提供了运行servlet 所需的环境;
② 它负责实例化、初始化、调用服务方法并从服务中移除servlet,管理
Servlet 的生命周期;
③ 实现Servlet API;
④ 它充当Web 服务器和Servlet 之间的桥梁;
⑤ 将请求从Web 服务器转发到Servlet;
⑥ 将响应从Servlet 转发到Web 服务器。
Servlet基本工作流程
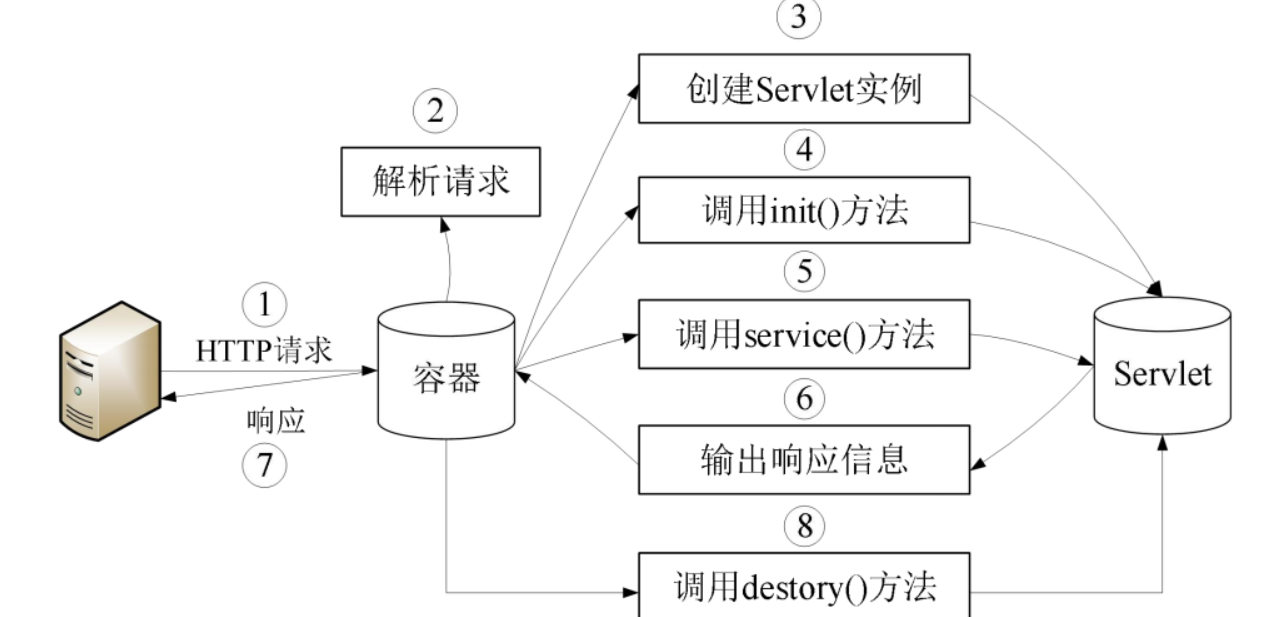
① 客户机将请求发送到服务器;
② Servlet程序是由Web服务器调用,Web服务器收到客户端的Servlet访问
请求后,解析客户端的请求;
③ 服务器上的Web容器转载并实例化Servlet;
④ 调用Servlet实例对象的init()方法;
⑤ 调用Servlet的service()方法并将请求和响应对象作为参数传递进去;
⑥ Servlet 创建一个响应,并将其返回到Web容器。
⑦ Web容器将响应发回客户机。
⑧ 服务器关闭或Servlet空闲时间超过一定限度时,调用destory()方法退出。
什么是JSP
JSP(Java Server Pages)是基于Java 语言的一种Web应用开发技术。
利用这一技术可以建立安全、跨平台、易维护的Web 应用程序。
① Java Server Pages
② 一种 Web 服务器端的开发技术
③ JSP ≈ HTML + Java
JSP运行原理
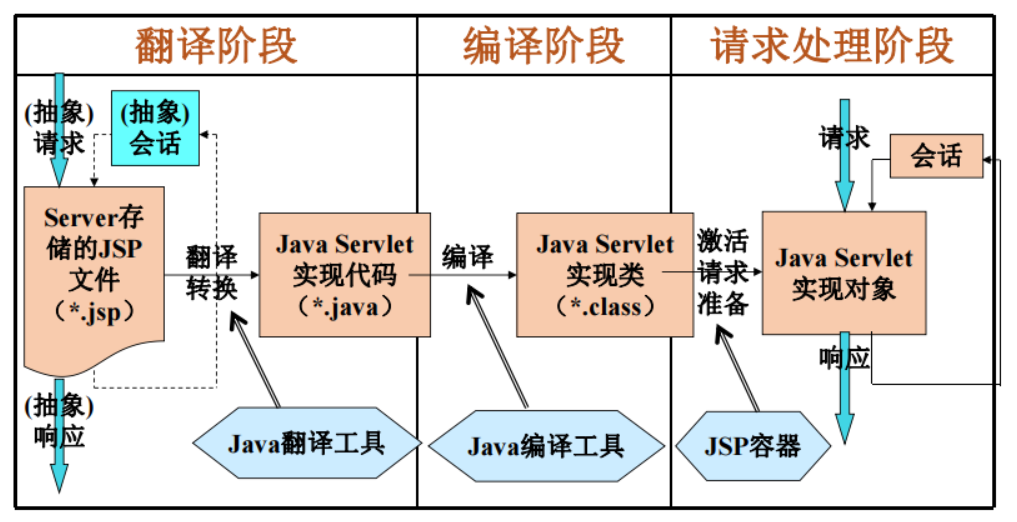
JSP页面的组成
① HTML标记
② JSP标记(分为指令标记、动作标记)
③ 成员变量与成员方法<%! %>
④ Java程序片<% %>
⑤ Java表达式<%= %>
⑥ 注释
JSP页面的基本结构
• JSP页面可由5种元素组合而成:
• ① 普通的HTML标记符;
• ② JSP标记,如指令标记、动作标记;
• ③ 变量和方法的声明;
• ④ Java程序片;
• ⑤ Java表达式 ;
<%@ page contentType="text/html;charset=GBK" %>
<%@ page import="java.util.Date" %>
<%!
Date date;
int sum;
public int getFactorSum(int n) {
for(int i=1;i<n;i++) {
if(n%i==0)
sum=sum+i;
}
return sum;
}
%>
<HTML>
<BODY bgcolor=cyan>
<FONT size=4><P>程序片创建Date对象:
<% date=new Date();
out.println("<br>"+date+"<br>");
int m=100;
%>
<%= m %>
的因子之和是(不包括<%=m%>):
<%= getFactorSum(m) %>
</FONT>
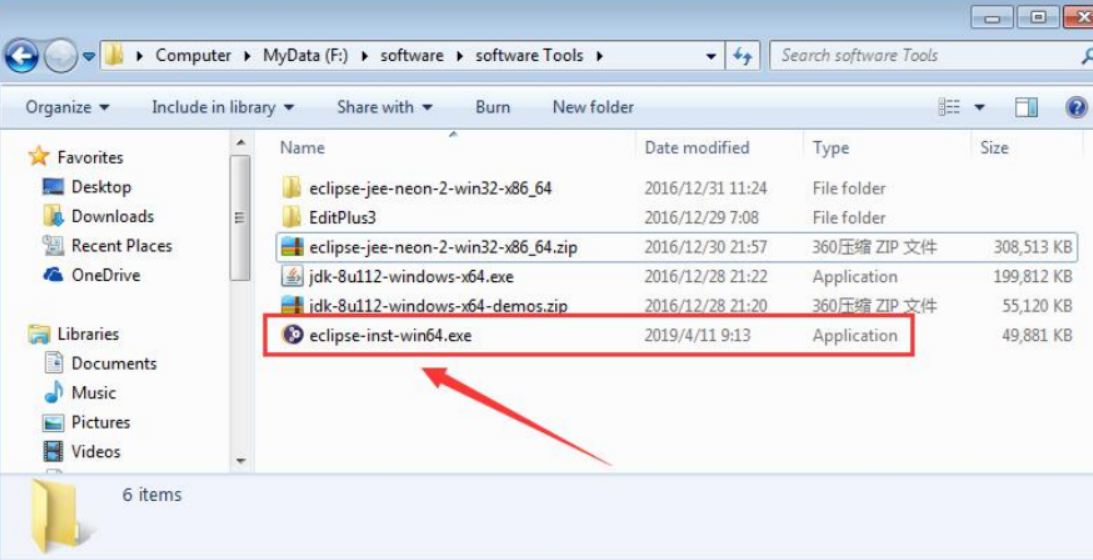
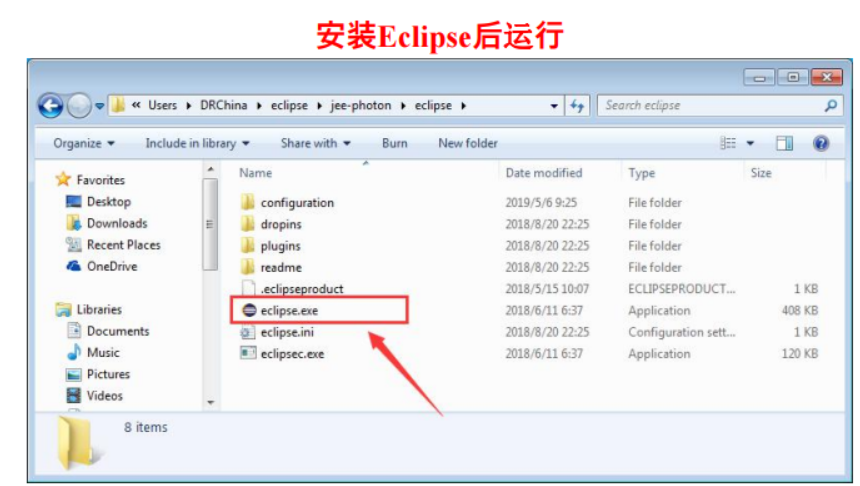
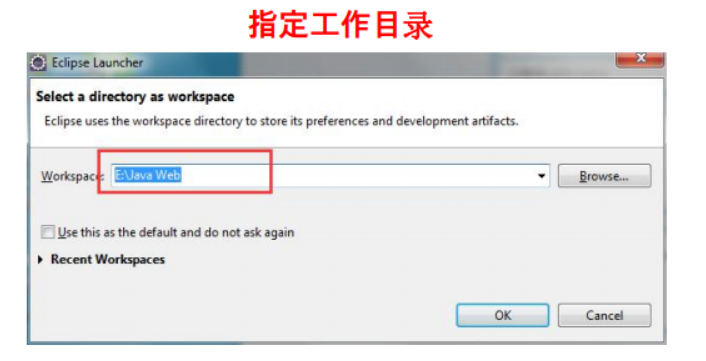
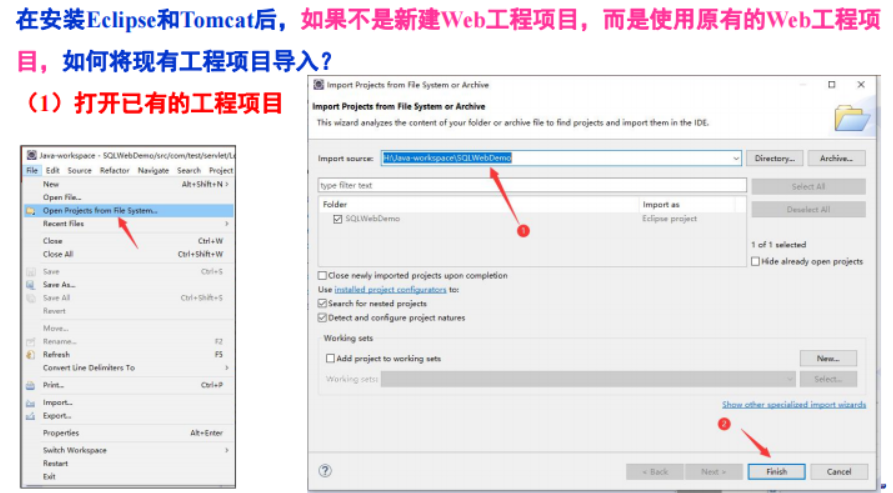
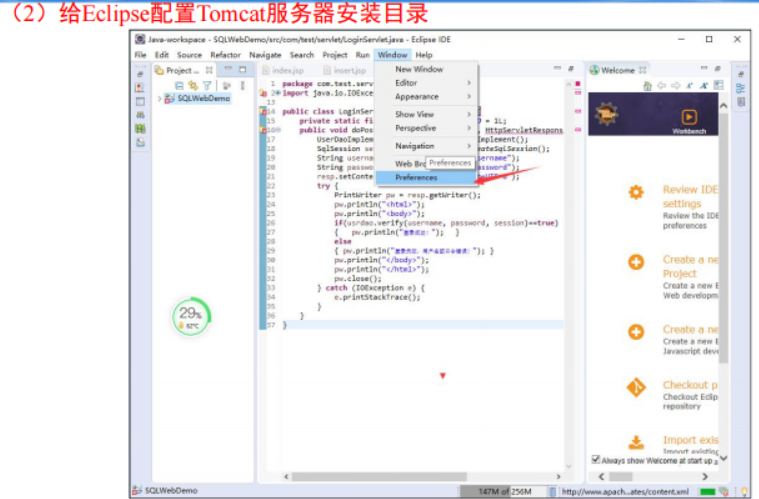
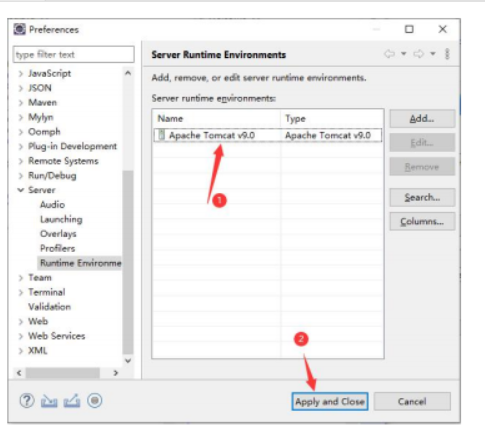
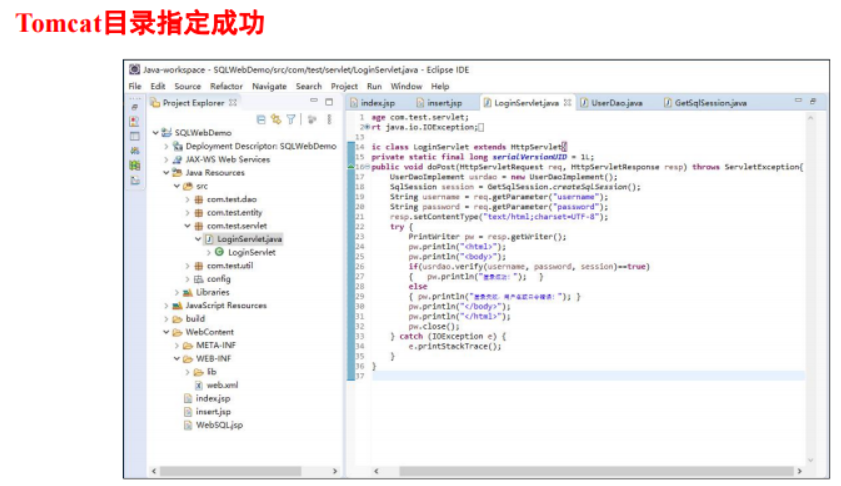
</HTML>下载Eclipse联机安装文件,并安装

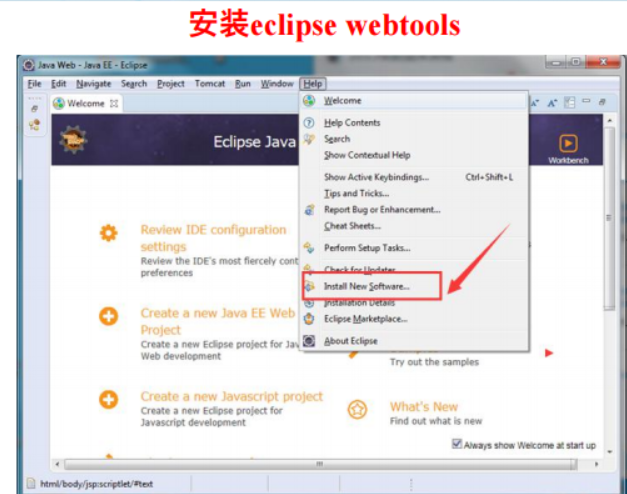
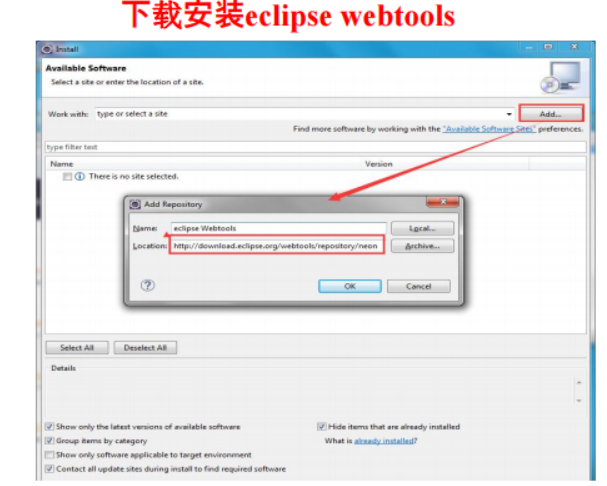
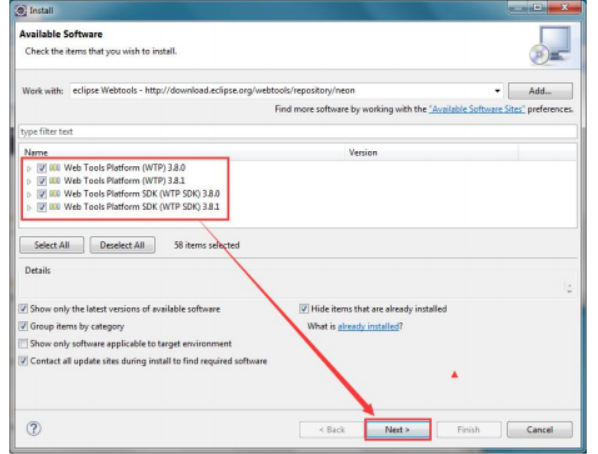
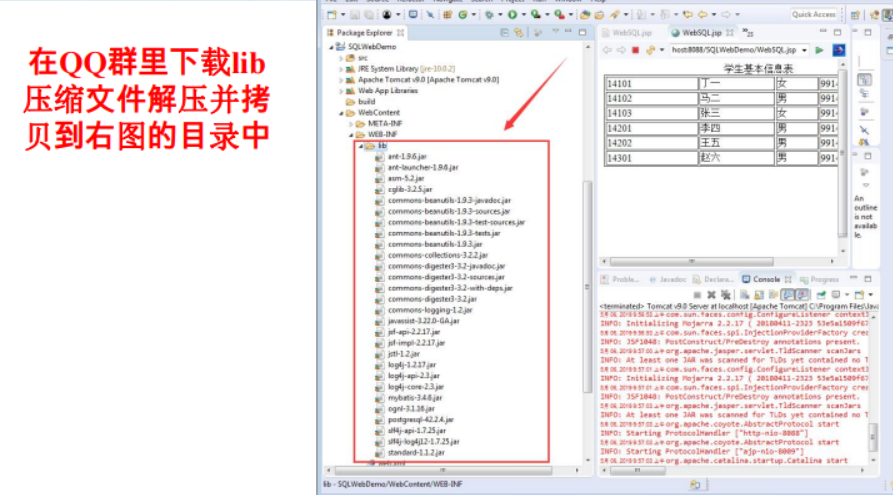
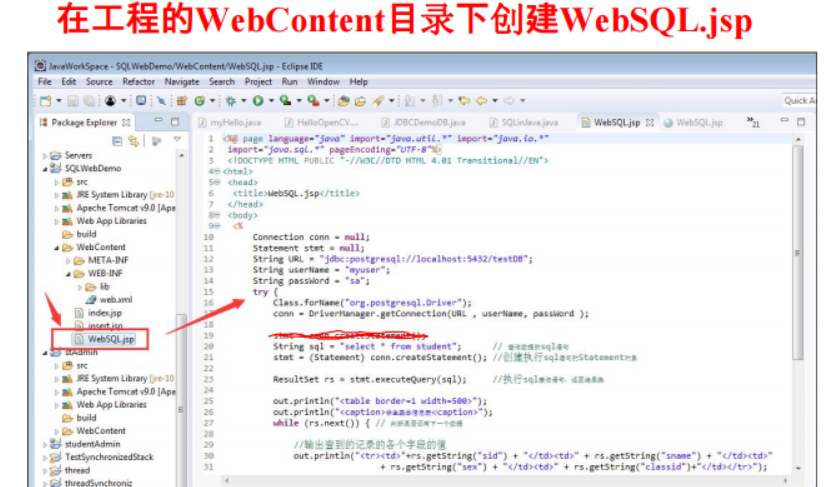
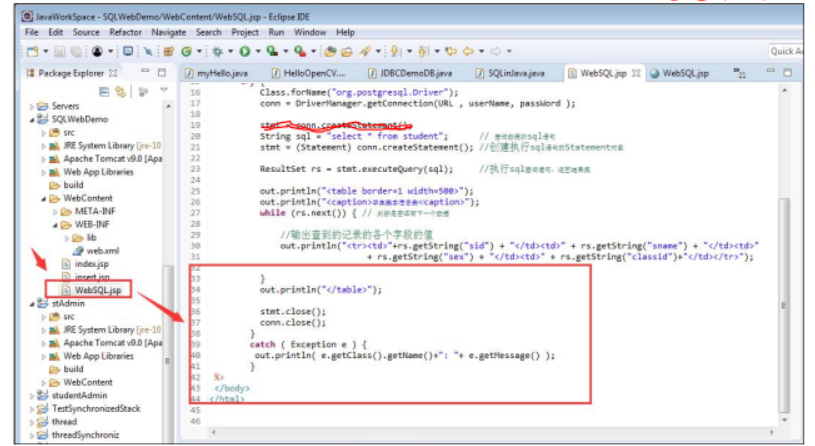
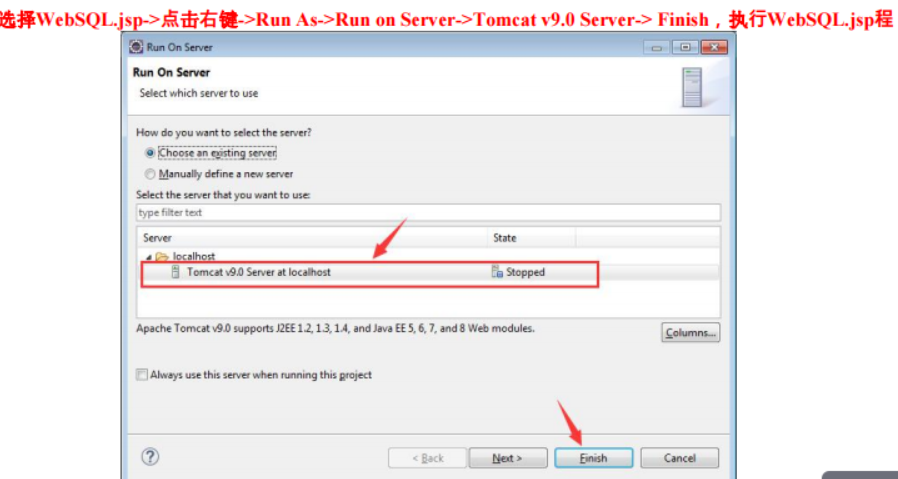
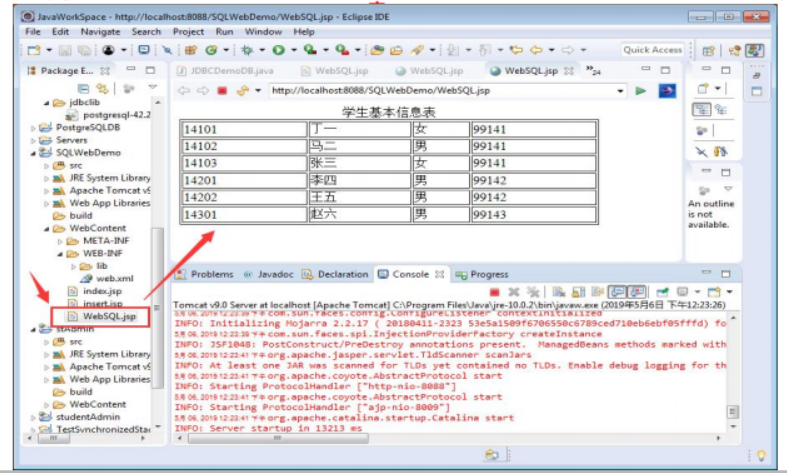

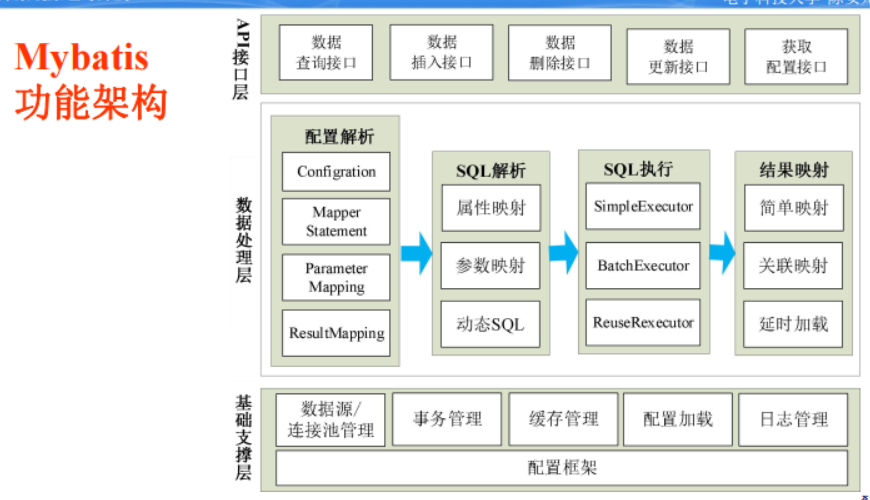
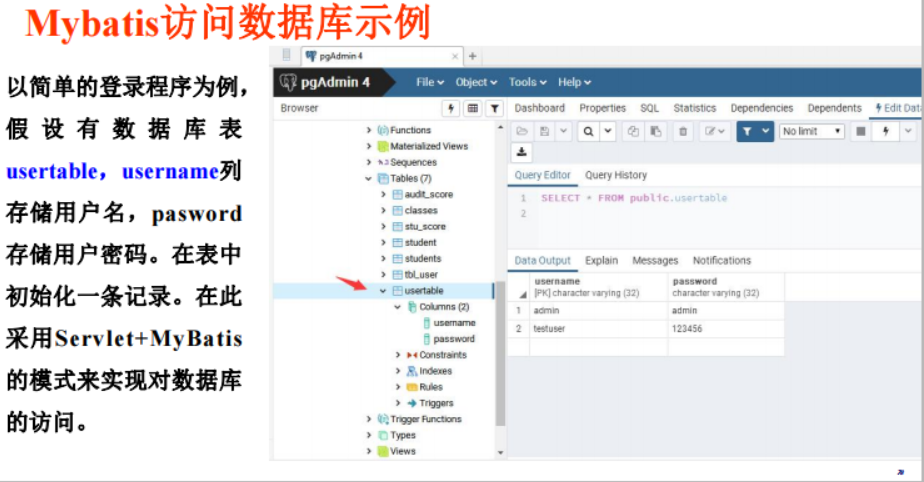
MyBatis访问数据库技术
① MyBatis 是Apache的开源项目iBatis,基于Java的持久层框架,提供的持久层框架包括SQL Maps和Data Access Objects(DAOs)。
② MyBatis 是支持普通 SQL查询、存储过程和高级映射的优秀持久层框架。MyBatis 使用简单的XML或注解用于配置和原始映射,将接口和 Java 的POJOs(Plain Ordinary Java Objects,普通的 Java对象)映射 成数据库中的记录,而不是使用 JDBC代码和参数实现对数据的检索。
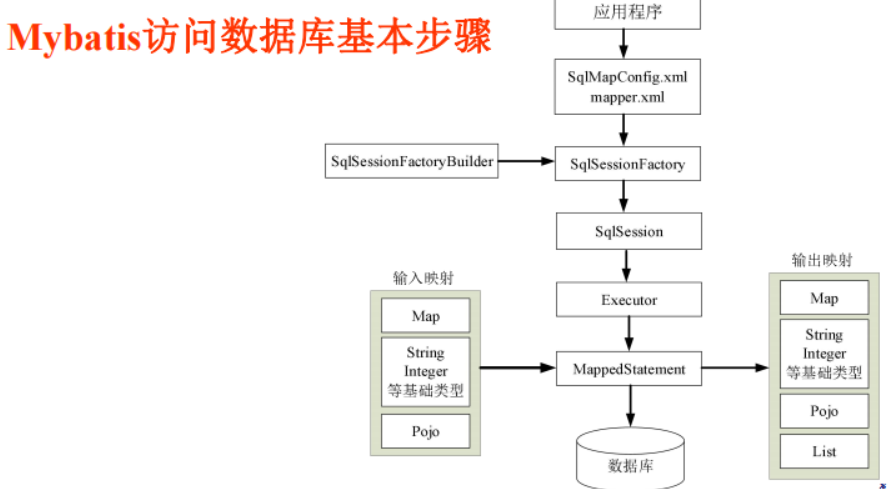
Mybatis访问数据库基本步骤
① 第一步:读取配置文件SqlMapConfig.xml,此文件作为Mybatis的全局配置文件,配置了Mybatis的运行环境等信息。mapper.xml文件即SQL映射文件,文件中配置了操作数据库的SQL语句,此文件需要在SqlMapConfig.xml中加载;
② 第二步:SqlSessionFactoryBuilder通过Configuration生成sqlSessionFactory对象。
③ 第三步:通过sqlSessionFactory打开一个数据库会话sqlSession会话,操作数据库需要通过sqlSession进行。
④ 第四步:Mybatis底层自定义了Executor执行器接口操作数据库,Executor接口负责动态SQL的生成和查询缓存的维护,将MappedStatement对象进行解析,SQL参数转化、动态SQL拼接,生成JDBC Statement对象。
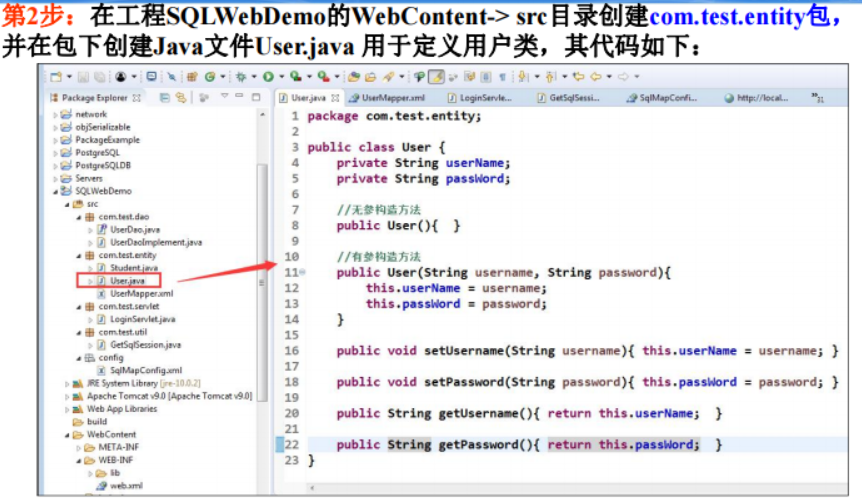
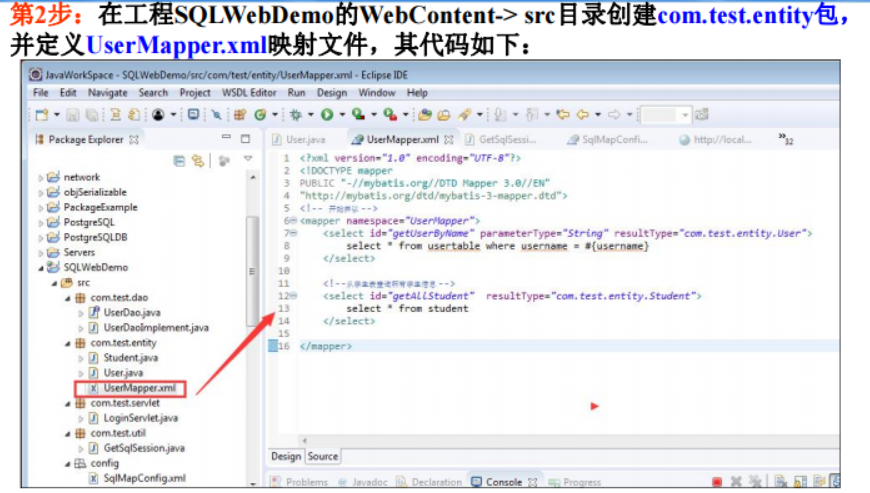
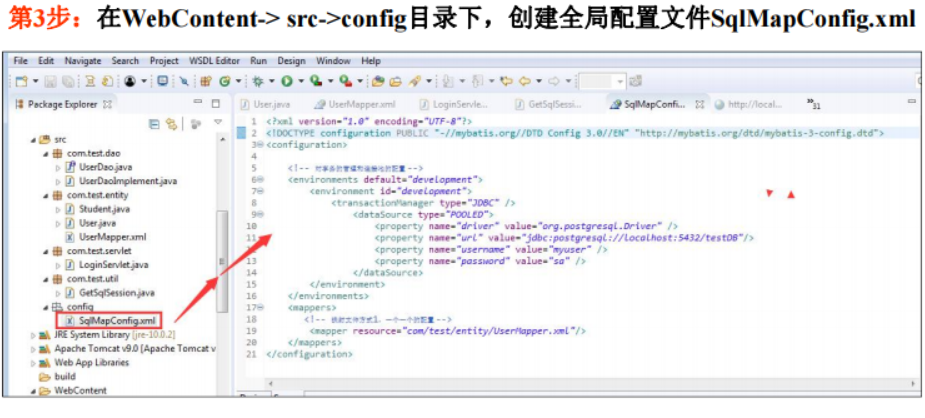

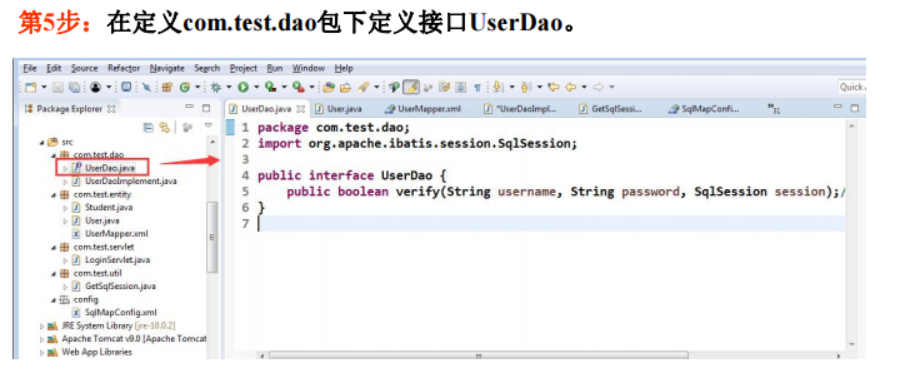
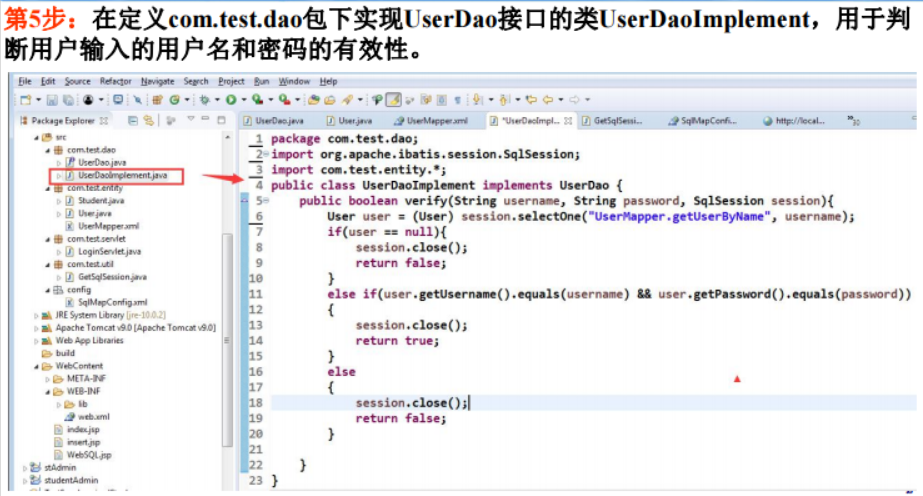
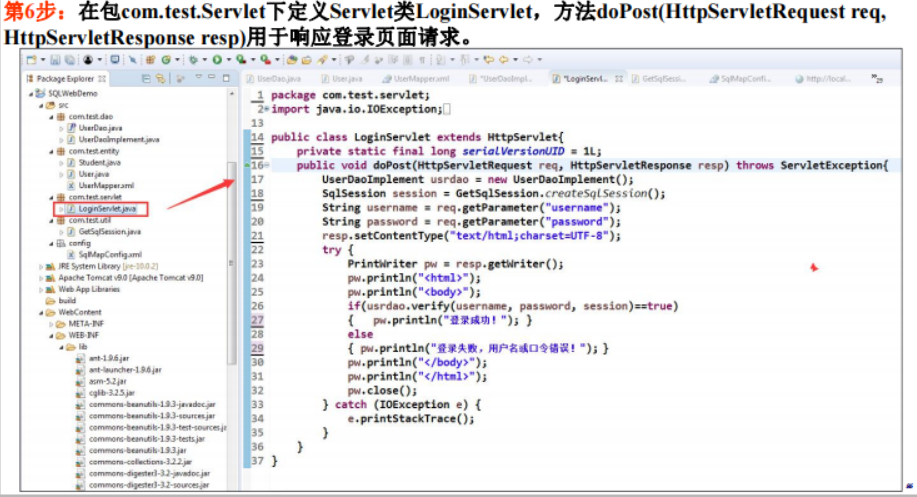
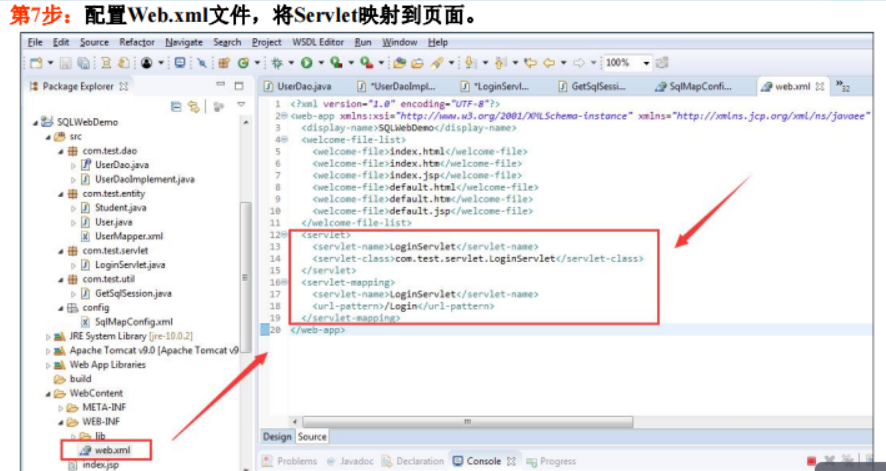
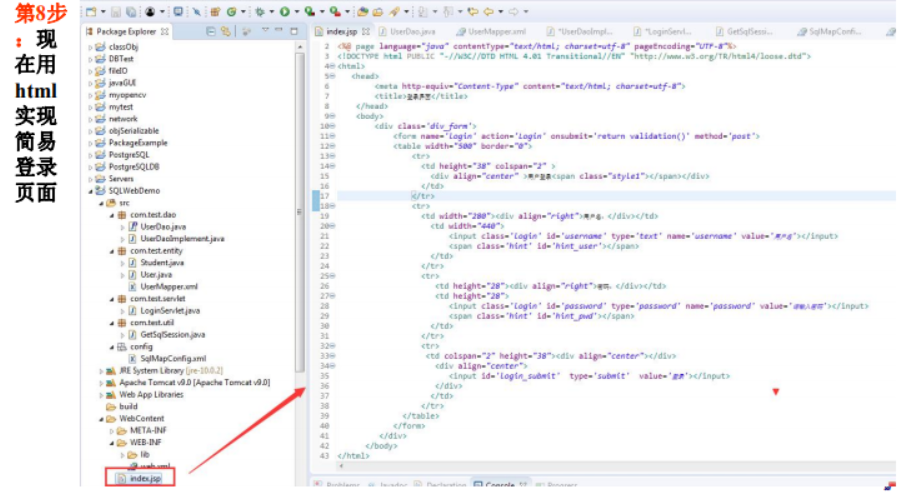
6.4数据库存储过程
• 了解存储过程的概念
• 掌握存储过程创建、删除的方法
• 掌握存储过程的执行方法
• 掌握PostgreSQL的PL/SQL基本语法
• 理解存储过程的优缺点
一、什么是存储过程
• 存储过程(Stored Procedure)是一种数据库的对象;
• 由一组能完成特定功能的SQL 语句集构成;
• 是把经常会被重复使用的SQL语句逻辑块封装起来,经编译后,存储在数据库服务器端;
• 当被再次调用时,而不需要再次编译;
• 当客户端连接到数据库时,用户通过指定存储过程的名字并给出参数,数据库就可以找到相应的存储过程予以调用。
二、创建存储过程
• 不同的数据库系统创建存储过程的语法存在差异;
• 许多数据库为创建存储过程和函数提供不同命令;
• 如ORACLE、MySQL、SQL SERVER等数据库,使用CREATE PRECEDURE命令创建存储过程,使用CREATE FUNCTION命令创建函数。
• PostgreSQL使用CREATE FUNCTION命令创建存储过程。
三、创建存储过程的语法
CREATE [ OR REPLACE ] FUNCTION name
( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
[ RETURNS retype | RETURNS TABLE ( column_name column_type [, ...] ) ]
AS $$ //$$用于声明存储过程的实际代码的开始
DECLARE
-- 声明段
BEGIN
--函数体语句
END;
$$ LANGUAGE lang_name; //$$ 表明代码的结束, LANGUAGE后面指明所用的编程语言
(1)name:要创建的存储过程名;
(2)OR REPLACE :覆盖同名的存储过程;
(3)argmode:存储过程参数的模式可以为IN、OUT或INOUT,缺省值是IN。
(4)argname:形式参数的名字。
(5)RETURNS:返回值;RETURNS TABLE:返回二维表
注意:Oracle、MySQL、SQL Server以PostgreSQL 11版等数据库使用CREATE OR REPLACE PROCEDURE创建存储过程
四、创建存储过程的示例
创建一个名为countRecords()的存储过程统计STUDENT表的记录数。
CREATE OR REPLACE FUNCTION countRecords ()
RETURNS integer AS $count$
declare
count integer;
BEGIN
SELECT count(*) into count FROM STUDENT;
RETURN count;
END;
$count$ LANGUAGE plpgsql;五、执行存储过程
如果程序员需要在查询窗口执行存储过程,语法形式如下:
select 存储过程名(参数);
或者: select * from 存储过程名(参数);
例如: select countRecords ( );
或者:select * from countRecords ( );如果程序员需要存储过程调用其它存储过程,语法形式如下:
select into 自定义变量 from 存储过程名(参数);
CREATE OR REPLACE FUNCTION testExec()
returns integer AS $$
declare
rec integer;
BEGIN
select into rec countRecords();
//如果不关心countRecords()的返回值,则可用 PERFORM countRecords() 代替;
return rec;
END;
$$ LANGUAGE plpgsql;六、删除存储过程
如果程序员需要删除存储过程,语法形式如下:
DROP FUNCTION [ IF EXISTS ] name ( [ [ argmode ] [ argname ] argtype [, ...] ] ) [ CASCADE | RESTRICT ]主要参数:
(1)IF EXISTS:如果指定的存储过程不存在,那么发出提示信息。
(2)name :现存的存储过程名称。
(3)argmode:参数的模式:IN(缺省), OUT, INOUT, VARIADIC。请注意,实际并不注意OUT参数,因为判断存储过程的身份只需要输入参数。
(4)argname:参数的名字。请注意,实际上并不注意参数的名字,因为判断函数的身份只需要输入参数的数据类型。
(5)argtype:如果有的话,是存储过程参数的类型。
(6)CASCADE:级联删除依赖于存储过程的对象(如触发器)。
(7)RESTRICT:如果有任何依赖对象存在,则拒绝删除该函数;这个是缺省值。
例子:假如需要删除前面定义的存储过程 testExec()
DROP FUNCTION IF EXISTS testExec()
七、PL/SQL基本语法
1、声明局部变量。
变量声明的语法如下:
declare
变量名 变量类型;
如果声明变量为记录类型,变量声明格式为: variable_name RECORD;
注:RECORD不是真正的数据类型,只是一个占位符。
例如:declare
count intger;
rec RECORD ;
2、条件语句
在PL/pgSQL中有以下三种形式的条件语句,与其他高级语言的条件语句意义相同。
1). IF-THEN
IF boolean-expression THEN
statements
END IF;
2). IF-THEN-ELSE
IF boolean-expression THEN
statements
ELSE
3). IF-THEN-ELSIF-ELSE
IF boolean-expression THEN
statements
ELSIF boolean-expression THEN
statements
ELSIF boolean-expression THEN
statements
ELSE
statements
END IF;3、循环语句
1). LOOP 语句
LOOP
statements
END LOOP [ label ];
2). EXIT
EXIT [ label ] [ WHEN expression ];
例如: LOOP
count=count+1;
EXIT WHEN count >100;
END LOOP;
3). CONTINUE
CONTINUE [ label ] [ WHEN expression ];
例如: LOOP
count=count+1;
EXIT WHEN count > 100;
CONTINUE WHEN count < 50;
count=count+1;
END LOOP;
4). WHILE
WHILE expression LOOP
statements
END LOOP ;
例如:
WHILE amount_owed > 0 AND balance > 0 LOOP
--do something
END LOOP;
5). FOR
FOR name IN [ REVERSE ] expression ... expression
LOOP
statements
END LOOP;
例如: FOR i IN 1...10 LOOP
RAISE NOTICE 'i IS %', i;
END LOOP;
FOR i IN REVERSE 10...1 LOOP
--do something
END LOOP;
4、遍历命令结果
FOR record_or_row IN query LOOP
statements
END LOOP ;
FOR循环可以遍历命令的结果并操作相应的数据,例如:
declare
rec RECORD ;
FOR rec IN SELECT sid , sname FROM student LOOP
raise notice ‘%-,%-’,rec.sid, rec.sname;
END LOOP;八、存储过程的优缺点
1、使用存储过程的优点
(1) 减少网络通信量
(2) 执行速度更快
(3) 更强的适应性
(4) 降低了业务实现与应用程序的耦合
(5) 降低了开发的复杂性
(6) 保护数据库元信息
(7) 增强了数据库的安全性
2、使用存储过程的缺点
(1) SQL本身是一种结构化查询语言,而存储过程本质上是过程化的程序;面对复
杂的业务逻辑,过程化处理逻辑相对比较复杂;而SQL语言的优势是面向数据查询
而非业务逻辑的处理。
(2) 如果存储过程的参数或返回数据发生变化,一般需要修改存储过程的代码,同
时还需要更新主程序调用存储过程的代码。
(3) 开发调试复杂,由于缺乏支持存储过程的集成开发环境,存储过程的开发调试
要比一般程序困难。
(4) 可移植性差
6.5数据库触发器
本节的主要内容
• 了解触发器的基本概念
• 掌握postgreSQL触发器创建、修改、删除的方法
• 理解触发器的执行过程
一、触发器的基本概念
触发器是特殊类型的存储过程,主要由操作事件(INSERT、UPDATE、DELETE) 触发而被自动执行。
触发器可以实现比约束更复杂的数据完整性,经常用于加强数据的完整性约束和业务规则。
触发器本身是一个特殊的事务单位。
触发器的特点
- 与表相关联:必须定义在表或视图上。
- 自动触发:由执行INSERT、DELETE、UPDATE操作时触发
- 不能直接调用,也不能传递或接受参数
- 是事务的一部分:触发器和触发语句作为可在触发器内回滚的单个事务。
触发器的分类
按触发的语句分为: INSERT触发器、DELETE触发器、UPDATE触发器
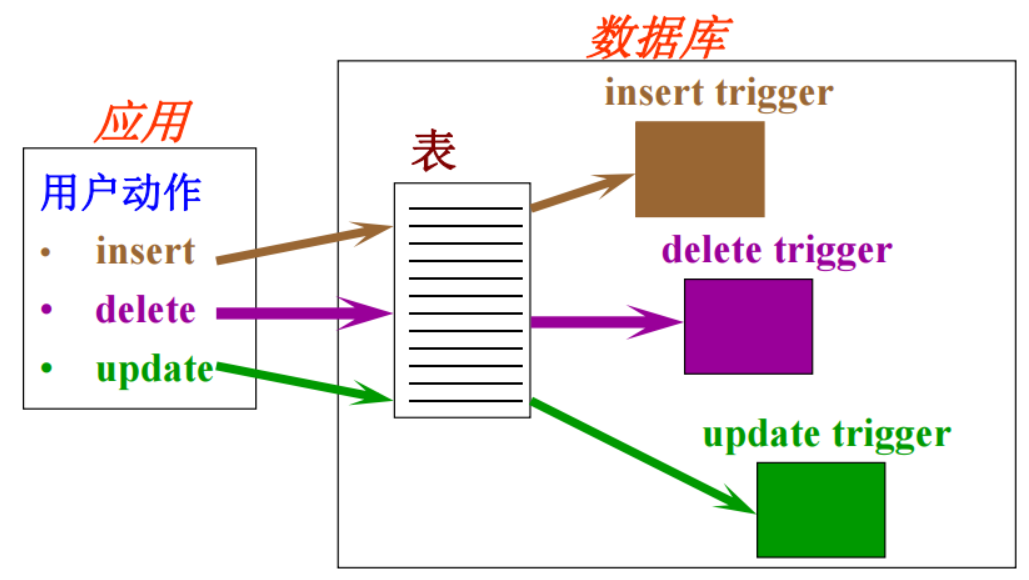
触发器执行的次数可分:
(1)语句级触发器:由关键字FOR EACH STATEMENT声明,在触发器作用的表上执行一条SQL语句时,该触发器只执行一次,即使是修改了零行数据的SQL,也会导致相应的触发器执行。如果都没有被指定,FOR EACH STATEMENT会是默认值。
(2)行级触发器:由关键字FOR EACH ROW标记的触发器,当触发器作用的表的数据发生变化时,每变化一行就会执行一次触发器。例如,假设学生成绩表有DELETE触发器,当在该表执行DELETE语句删除记录时,如果删除了20条记录,则将导致 DELETE触发器被执行20 次。
按触发的时间分为三类:
(1)BEFORE触发器:在触发事件之前执行触发器。
(2)AFTER触发器:在触发事件之后执行触发器。
(3)INSTEAD OF触发器:当触发事件发生后,执行触发器中指定的函数,而不是执行产生触发事件的SQL 语句,从而替代产生触发事件的SQL操作。在表或视图上,对于INSERT、UPDATE 或 DELETE 三种触发事件,每种最多可以定义INSTEAD OF 触发器
INSTEAD OF 触发器
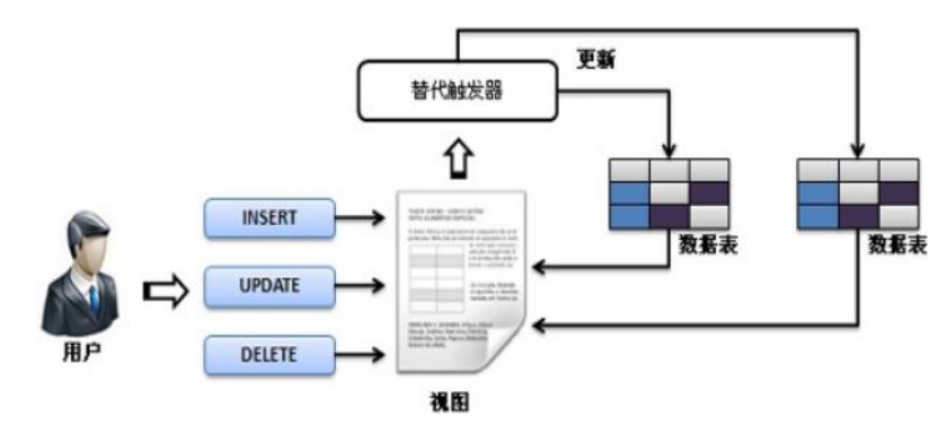
触发器相关的特殊变量
(1)NEW
数据类型是RECORD。对于行级触发器,它存有INSERT或UPDATE操作产生的新的数据行。对于语句级触发器,它的值是NULL。
(2)OLD
数据类型是RECORD。对于行级触发器,它存有被UPDATE或DELETE操作修改或删除的旧的数据行。对于语句级触发器,它的值是NULL。
(3)TG_OP
数据类型是text;是值为INSERT、UPDATE、DELETE 的一个字符串,它说明触发器是为哪个操作引发。
二、PostgreSQL创建触发器的基本语法
CREATE TRIGGER 触发器名
{ BEFORE | AFTER | INSTEAD OF }
ON 表名
[ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE 存储过程名 ( 参数列表 )
(1)指明所定义的触发器名
(2) BEFORE | AFTER | INSTEAD OF 指明触发器被触发的时间
(3) ON 表名 指明触发器所依附的表
(4) FOR EACH { ROW | STATEMENT } 指明触发器被触发的次数
(5) EXECUTE PROCEDURE 存储过程名 ( 参数列表 ) 指明触发时所执行的存储过程
三、PostgreSQL创建触发器的基本步骤:
(1)检查数据库中将要创建的触发器所依附的表或视图是否存在,如果不存在,必须首先创建该表或视图。
(2)创建触发器被触发时所要执行的触发器函数,该函数的类型必须是TRIGGER型,是触发器的执行函数。但要注意,有些数据库不需要独立定义触发器函数,而是在创建触发器时,定义触发器的过程体。
(3)创建触发器,一般需要指明触发器依附的表,触发器被触发执行的时间,触发器是行级触发器还是语句级触发器,触发器执行需要满足的条件。
四、创建触发器的示例
假设有stu_score表存储学生的课程成绩,其表结构如下,同时插入如下数据:
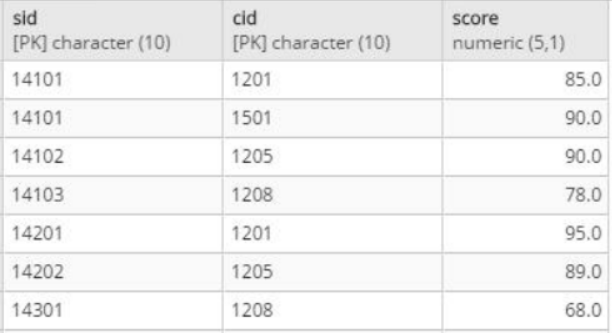
CREATE TABLE stu_score
(
sid character(10) NOT NULL,
cid character(10) NOT NULL,
score numeric(5,1),
CONSTRAINT stu_score_pkey PRIMARY KEY (sid, cid)
)为了防止非法修改stu_score表的课程成绩,创建audit_score表记录stu_score表
的成绩变化,其表结构如下:
CREATE TABLE audit_score
(
username character(20) , --用户名
sid character(10) ,
cid character(10) ,
updatetime text ,--修改的时间
oldscore numeric(5,1), --修改前的成绩
newscore numeric(5,1) --修改后的成绩
)现在创建触发器函数score_audit()
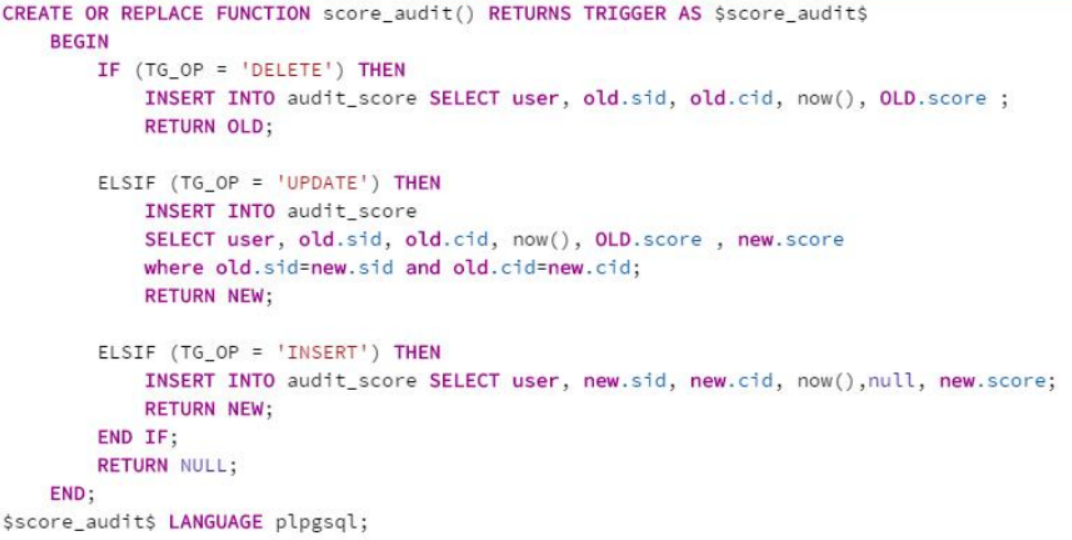
接下来在stu_score表上创建触发器score_audit_triger
CREATE TRIGGER score_audit_triger
AFTER INSERT OR UPDATE OR DELETE ON stu_score
FOR EACH ROW EXECUTE PROCEDURE score_audit();五、验证触发器的执行
将课程号为1201的课程成绩增加1分
update stu_score set score=score+1 where cid='1201';
stu_score
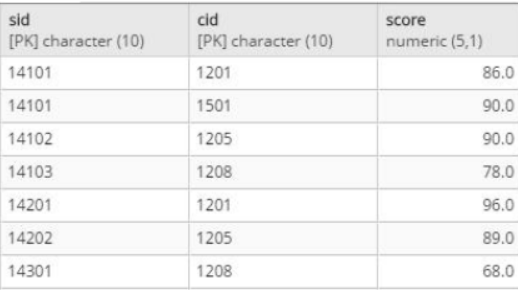
audit_score

将删除课程号为1501的课程成绩
delete from stu_score where cid='1501';
stu_score
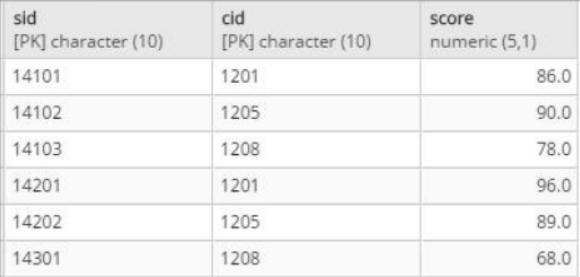
audit_score

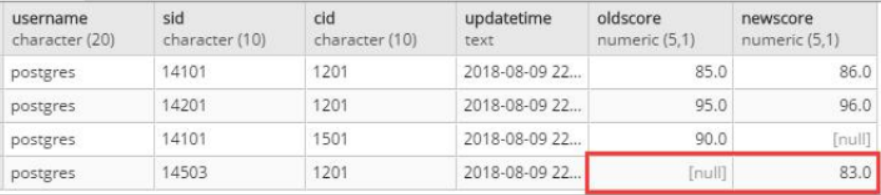
录入学号14503的同学的1201号课程成绩
INSERT INTO stu_score(sid, cid, score) VALUES ('14503','1201',83);
stu_score
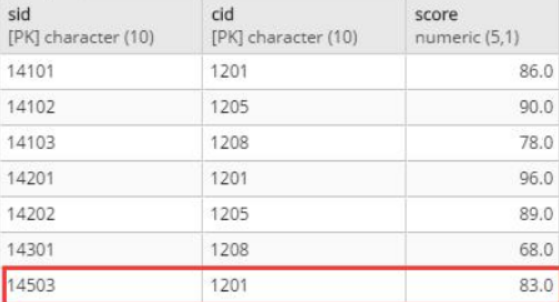
audit_score
五、触发器的修改
ALTER TRIGGER name ON table_name RENAME TO new_name
主要参数说明:
(1)name:需要修改的现有触发器的名称。
(2)table_name:该触发器作用的表的名字。
(3)new_name:现有触发器的新名字。
例如:将上述定义的触发器改名为score_audit_trig
ALTER TRIGGER score_audit_trigger ON stu_score RENAME TO score_audit_trig;
六、触发器的删除
DROP TRIGGER [ IF EXISTS ] name ON table_name [ CASCADE | RESTRICT ]
主要参数说明:
(1)IF EXISTS:如果指定的触发器不存在,那么发出提示而不是抛出错误。
(2)name:要删除的触发器名。
(3)table_name:触发器定义所依附的表的名称。
(5)CASCADE:级联删除依赖于触发器的对象;没有明确哪类对象依赖触发器。
(6)RESTRICT:如果有依赖对象存在,那么拒绝删除。该参数缺省是拒绝删除。
例如:将上述触发器score_audit_trig删除,同时级联删除依赖触发器的对象。
DROP TRIGGER IF EXISTS score_audit_trig ON stu_score CASCADE;
6.6 数据库游标
本节的主要内容
• 了解游标的基本概念
• 掌握游标声明、打开、读取、关闭的方法
• 掌握游标的编程
一、游标的基本概念
(1)游标(Cursor)是一种临时的数据库对象;
(2)用来存放从数据库表中查询返回的数据记录;
(3)提供了从结果集中提取并分别处理每一条记录的机制;
(4)游标总是与一条SQL查询语句相关联;
(5)游标包括:SQL语言的查询结果,指向特定记录的指针。
二、声明游标
(1)在存储过程中游标类型的变量。例如:游标变量 refcursor;
refcursor是关键字;
此时,游标变量还没有绑定查询语句,因此不能访问游标变量。
(2) 使用游标专有的声明语法,如:
游标名 CURSOR [ ( arguments ) ] FOR query;
其中arguments为由逗号分隔的参数列表,用于打开游标时向游标传递参数,类似于存储过程或函数的形式参数;
query是select数据查询语句,返回的值存储在游标变量中。
游标声明的示例
(1)curStudent CURSOR FOR SELECT * FROM student;
(2)curStudentOne CURSOR (key integer) IS
SELECT * FROM student WHERE SID = key;三、打开游标
(1)OPEN FOR:
其声明形式为:
OPEN unbound_cursor FOR query;
打开未绑定的游标变量,其query查询语句是返回记录的SELECT语句。
例如: OPEN curVars1 FOR SELECT * FROM student WHERE SID = mykey;
(2)OPEN FOR EXECUTE
其声明形式为: OPEN unbound_cursor FOR EXECUTE query-string;
打开未绑定的游标变量。EXECUTE将动态执行查询字符串。例如:
OPEN curVars1 FOR EXECUTE 'SELECT * FROM ' || quote_ident($1);
注意:$1是指由存储过程传递的第1个参数。
(3)打开一个绑定的游标,其声明形式为:
OPEN bound_cursor [ ( argument_values ) ];
仅适用于绑定的游标变量,只有当该变量在声明时包含接收参数,才能以传递
参数的形式打开该游标,参数将传入到游标声明的查询语句中,例如:
OPEN curStudent;
OPEN curStudentOne (‘20160230302001’);
四、使用游标
其声明形式为:
FETCH cursor INTO target;
FETCH命令从游标中读取下一行记录的数据到目标中,读取成功与否,可通过
PL/SQL内置系统变量FOUND来判断。
例如:
FETCH curVars1 INTO rowvar; --rowvar为行变量
FETCH curStudent INTO SID, Sname, sex;
请注意:游标的属性列必须与 目标列的数量一致,并且类型兼容。
五、关闭游标
CLOSE cursorName;
当游标数据不再需要时,需要关闭游标,以释放其占有的系统资源,主要是释放游标数据所占用的内存资源,cursorName是游标名。
例如:
CLOSE curStudent;
需要注意:当游标被关闭后,如果需要再次读取游标的数据,需要重新使用open打开游标,这时游标重新查询返回新的结果。
六、在存储过程中使用游标的示例1
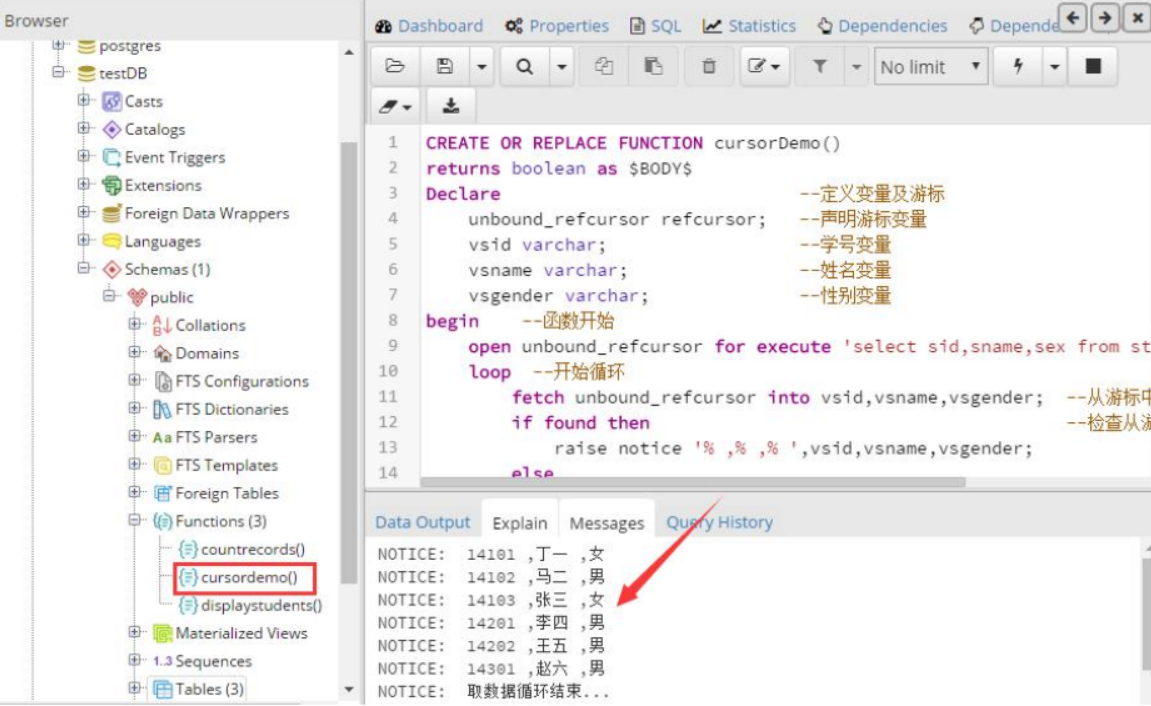
1、下面例子使用不带参数的游标,查询student表的学号、学生姓名和性别。

执行存储过程的结果
六、在存储过程中使用游标的示例2
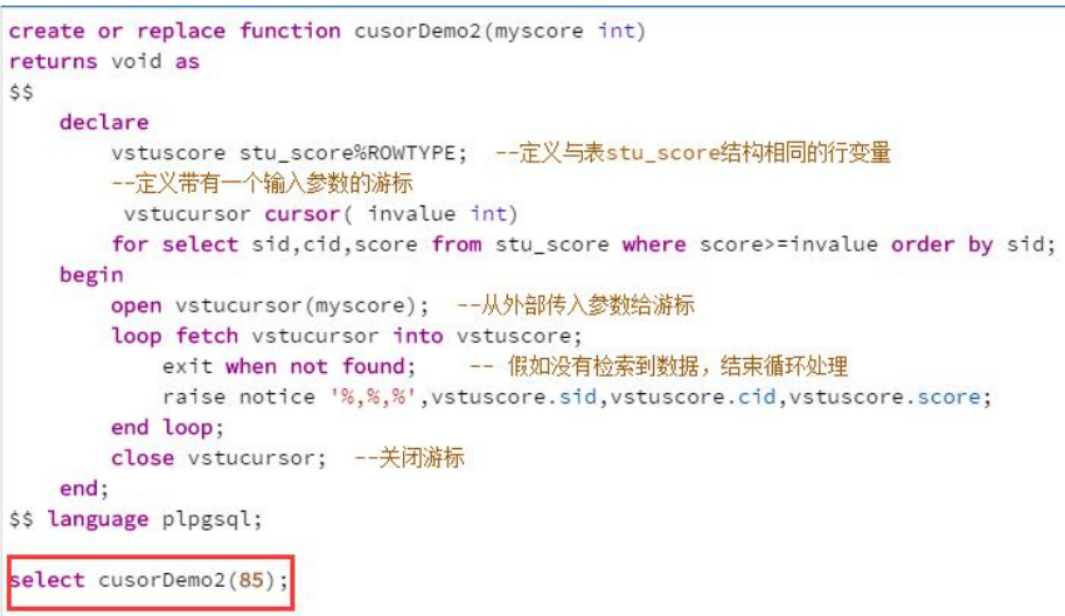
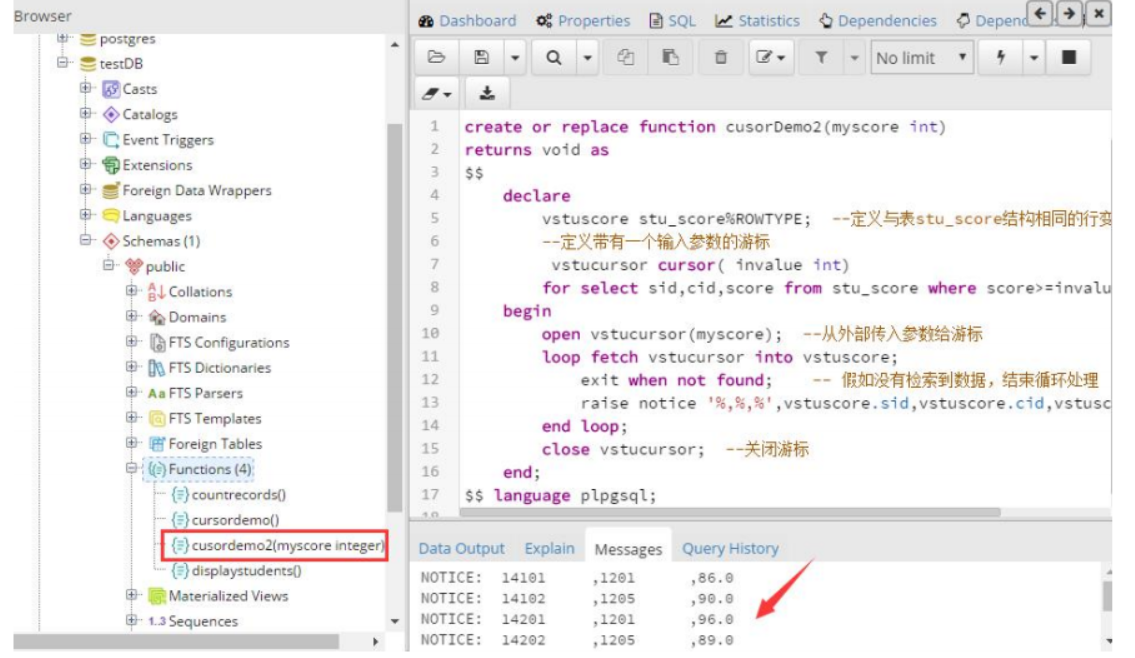
2、下面示例使用带参数的游标,从成绩表中查询分数大于某给定值的学号和课程号。
执行存储过程的结果
6.7 嵌入式SQL编程
本节的主要内容
• 了解SQL与宿主语言的关系
• 理解嵌入式SQL的处理过程
• 理解嵌入式SQL与主语言之间的通信
• 理解嵌入SQL的使用方式
• 理解并掌握在Java语言中嵌入执行SQL语句
一、嵌入式SQL与宿主语言
(1)SQL语言具有很强的查询处理能力,而逻辑表达的能力很弱,界面编程能力也很弱。
(2)如JAVA,C/C++等高级语言具有很强逻辑表达能力,能实现复杂的处理逻辑,同时具有较强的用户界面实现功能。
(3)为了使程序语言同时具有它的优点,在JAVA、C/C++等高级语言中嵌入SQL语句,称高级语言为宿主语言。
(4)由DBMS的预编译器扫描识别处理SQL语句,把SQL语句转换成主语言调用语句,以使主语言编译程序能识别它,最后由主语言的编译程序将整个源程序编译成目标码,然后连接(Link)处理生成装载模块。
二、嵌入式SQL的处理过程
(1)嵌入式SQL是一个语句级接口,通过程序访问的数据库模式必须在编写程序时已知,以便构造SQL语句。例如,程序员必须知道数据表名称、列名称及它的域。
(2)对于嵌入式SQL,RDBMS一般采用预编译方法处理,即由RDBMS的预处理程序对源程序进行扫描,识别出嵌入的SQL语句,把它们转换成主语言调用语句,以使主语言编译程序能识别它们,然后由主语言的编译程序将纯的主语言编译成目标码。
三、嵌入式SQL与主语言之间的通信
将SQL嵌入到高级语言中混合编程,SQL语句负责操纵数据库,高级语言语句负责控制流程。这时程序中会含有两种不同的计算模型的语句,从而需要二者之间建立通信。数据库工作单元与源程序工作单元之间的通信主要包括:
(1)向主语言传递SQL语句的执行状态信息,使主语言能够根据此信息控制程序流程,主要用SQL通信区实现
(2)主语言向SQL语句提供参数,主要用主变量实现
(3)将SQL语句查询数据库的结果传回主语言处理,主要用主变量和游标实现
三、嵌入SQL的使用规定(下面以C语言为例)
(1)在程序中要区分SQL语句和宿主语言语句
在C语言嵌入式SQL语句,为了能够区分SQL语句与宿主语言语句,所有的SQL语句都必须加前缀标识“EXEC SQL”,并以“END_EXEC”作为语句的结束标志。嵌入式SQL语句的格式如:
EXEC SQL <SQL语句> END_EXEC
结束标志在不同的宿主语言中可能是不同的,在C和PASCAL语言程序中规定结束标志为“;”,而不是“END_EXEC”。
(2)SQL的集合处理方式与宿主语言单记录处理方式之间的协调由于SQL语句处理的是记录集合,而宿主语言语句一次只能处理一条记录,因此需要使用游标(Cursor)机制,把集合操作转换为单记录处理方式。与游标有关的
SQL语句如下:
1)游标定义语句(DECLARE)。游标是与某一查询结果相联系的符号名,游标用SQL的DECLARE语句定义,其格式如下:
EXEC SQL DECLARE <游标名> CURSOR FOR
< SELECT 语句>
END EXEC
游标定义语句是一个说明语句,定义中的SELECT并不立即执行。
2)游标打开语句(OPEN)。该语句在执行游标定义中的SELECT语句,同时游标处于活动状态。游标是一个指针,此时指向查询结果的第一行之前。
OPEN语句的格式如下:
EXEC SQL OPEN <游标名>
END_EXEC
3)游标读取数据语句(FETCH)。此时游标推进一行,并把游标指向的行(即当前行)中的值取出并送到共享变量,其格式如下:
EXEC SQL FETCH FROM <游标名> INTO <变量表>
END_EXEC
变量表由逗号分开的共享变量组成。FETCH语句通常置于宿主语言程序的循环结构中,并借助宿主语言的处理语句逐一处理查询结果中的每一个元组。
四、Java语言嵌入式SQL语句的步骤
(1)Class.forName("org.postgresql.Driver")加载PostgreSQL驱动程序。
(2)使用DriverManager.getConnection(String url, String user, String pwd) 建立与数据库的连接,返回表示连接的Connection对象,url指明数据库服务器名、端口号及数据库名, user 指明具有连接权限的用户名,pwd是指明用户user的口令。
(3)使用Connection对象的下列方法之一创建查询语句对象:
① Connection.createStatement()创建Statement对象,静态SQL语句查询;
② Connection.prepareStatement(String sql)创建PreparedStatement对象,实现动态SQL语句查询;
③ Connection.prepareCall(String sql)创建CallableStatement对象来调用数据库存储过程;
执行查询
(1)Statement.execute(String sql) 执行各种SQL语句,返回一个boolean类型值,true表示执行的SQL语句具备查询结果,可通过Statement.getResultSet()方法获取;
(2) Statement.executeUpdate(String sql)执行SQL中的insert/update/delete语句,返回一个int值,表示受影响的记录的数目;
(3) Statement.executeQuery(String sql)执行SQL中的select语句,返回一个表示查询结果的ResultSet对象。
在Java语言操作数据库查询返回结果
数据库查询一般需要返回多条记录,则ResultSet接口对象用于返回查询结果集,该结果集本质上是内存中用于存储多条记录的游标,主要有以下几种方法访问访问
游标的记录信息:
1)ResultSet.next()将游标由当前位置移动到下一行;
2)ResultSet.getString(String columnName) 获取指定字段的String类型值;
3)ResultSet.getString(int columnIndex) 获取指定索引的String类型值;
4)ResuleSet.previous(将游标由当前位置移动到上一行。
向SQL语句传递参数
如果Java宿主语言需要向SQL语句传递参数,则使用动态查询prepareStatement对象,preparedStatement预编译SQL语句,并支持批处理,执行查询有类似Statement对象的三种执行方式,且执行方法中没有参数。
1)prepareStatement.executeUpdate()执行更新;
2)prepareStatement对象使用addBatch()向批处理中加入更新语句,
3)executeBatch()方法用于成批地执行SQL语句。
Java语言嵌入式SQL语句的示例