点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:集智书童 RandomMix: A mixed sample data augmentation method with multiple mixed modes
RandomMix: A mixed sample data augmentation method with multiple mixed modes
论文:https://arxiv.org/abs/2205.08728
数据增强是一种非常实用的技术,可以用来提高神经网络的泛化能力,防止过拟合。最近,混合样本数据增强受到了很多关注并取得了巨大的成功。为了提高混合样本数据增强的性能,最近的一系列工作致力于获取和分析图像的显著区域,并使用显著区域来指导图像混合。然而,获取图像的显著信息需要大量额外的计算。
与通过显著性分析提高性能不同,提出的方法
RandomMix主要增加混合样本的多样性,以增强神经网络的泛化能力和性能。而且,RandomMix可以提高模型的鲁棒性,不需要太多额外的计算,很容易插入到训练管道中。最后在CIFAR-10/100、Tiny-ImageNet、ImageNet和Google Speech Commands上进行实验数据集表明RandomMix的性能优于其他最先进的混合样本数据增强方法。
1简介
深度神经网络成功的重要原因之一是它具有海量的可学习参数。但是,可以从Vapnik-Chervonenkis(VC)理论推断,当训练数据有限或不足时,更多可学习的参数更容易过拟合训练数据。此外,模型对训练数据分布之外的数据的泛化能力极其有限。为了提高神经网络的泛化能力,防止过拟合,数据增强是一种非常实用的技术。
最近,一系列混合样本数据增强方法被提出并广泛应用于深度神经网络的训练。与传统的数据增强只考虑同一类样本的邻近性不同,混合样本数据增强考虑了不同类样本之间的邻近关系。
Mixup是混合样本数据增强的开创性工作,它使用线性插值来混合训练样本。CutMix通过将一张图像的patch粘贴到另一张图像上而不是插值来使混合样本多样化。为了提高混合样本数据增强的性能,一些最新的作品如SaliencyMix、Puzzle Mix和Co-Mixup都专注于图像显著性分析。然而,获取图像的显著信息需要大量的额外计算。
与通过显著性分析提高性能的方法不同,本文的方法考虑通过增加混合样本的多样性来提高神经网络的性能。在前人工作的基础上提出了RandomMix,它使混合样本更加多样化,具有更好的性能。此外,RandomMix使模型更加稳健和方便使用。
作者评估了提出的方法在CIFAR-10/100、Tiny-ImageNet、ImageNet和Google Speech Commands数据集上的性能。实验表明,RandomMix比其他最先进的混合样本数据增强方法具有更好的性能。除了泛化性能实验外,鲁棒性实验表明,在训练期间使用RandomMix可以同时提高模型对对抗性噪声、自然噪声和样本遮挡的稳健性。
2本文方法
2.1 准备工作
Mixup是第一个混合样本数据增强方法。它结合了先验知识,即输入特征向量的线性插值应该导致相关目标的线性插值。在Mixup中,混合操作如下:

其中和是2个训练样本,是生成的训练样本,混合比λ是从beta分布中采样的, , 对于α∈(0,∞)。
结合Mixup和Cutout的思想,CutMix提出了一种新的数据增强策略,其中在训练图像之间剪切和粘贴块,并且GT标签也与块区域按比例混合。在CutMix中,混合操作定义为:
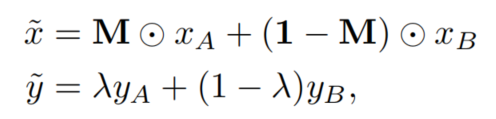
其中M表示二进制矩形掩码,指示从2个样本中退出和填充的位置,1是填充有1的二进制掩码,表示元素乘积,混合比λ从均匀分布中采样,λ∼U(0,1)。
为了解决CutMix中标签分配错误和对象信息丢失的问题,ResizeMix通过直接将源图像调整为更小的块,然后将其粘贴到另一张图像上来混合训练数据。
对于Fmix,它使用通过对从傅里叶空间采样的低频图像应用阈值获得的随机二进制掩码,从而进一步改善CutMix混合区域的形状。
2.2 RandomMix
RandomMix的主要目标是通过整合以前的工作来提高模型的鲁棒性并增加训练数据的多样性。此外,RandomMix可以实现更好的性能,并且可以很容易地插入到现有的训练管道中。图1给出了所提方法的说明性表示。
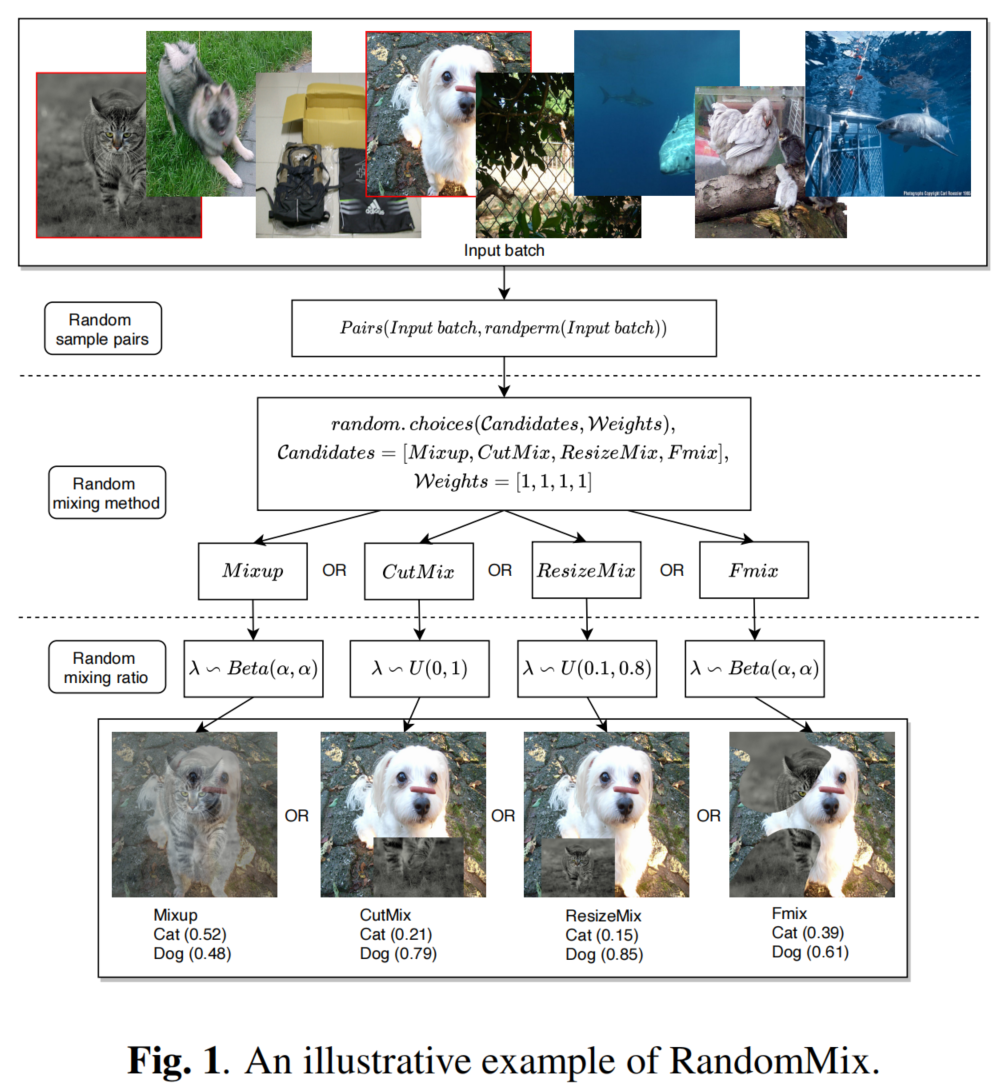
如图1所示,首先,对输入Batch进行随机样本配对。配对操作定义如下

其中randperm(·)表示随机排列。接下来,为了获得更多样化的混合样本,通过从候选中随机选择一种混合方法来混合配对样本。随机选择的定义如下,
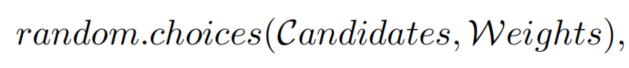
其中Candidates和Weights是超参数。例如,可以将Candidates设置为[Mixup,CutMix,ResizeMix,Fmix],将Weights设置为[1,1,1,1]。通过相应的随机抽样得到混合比λ。最后,使用混合样本来训练模型。
3实验
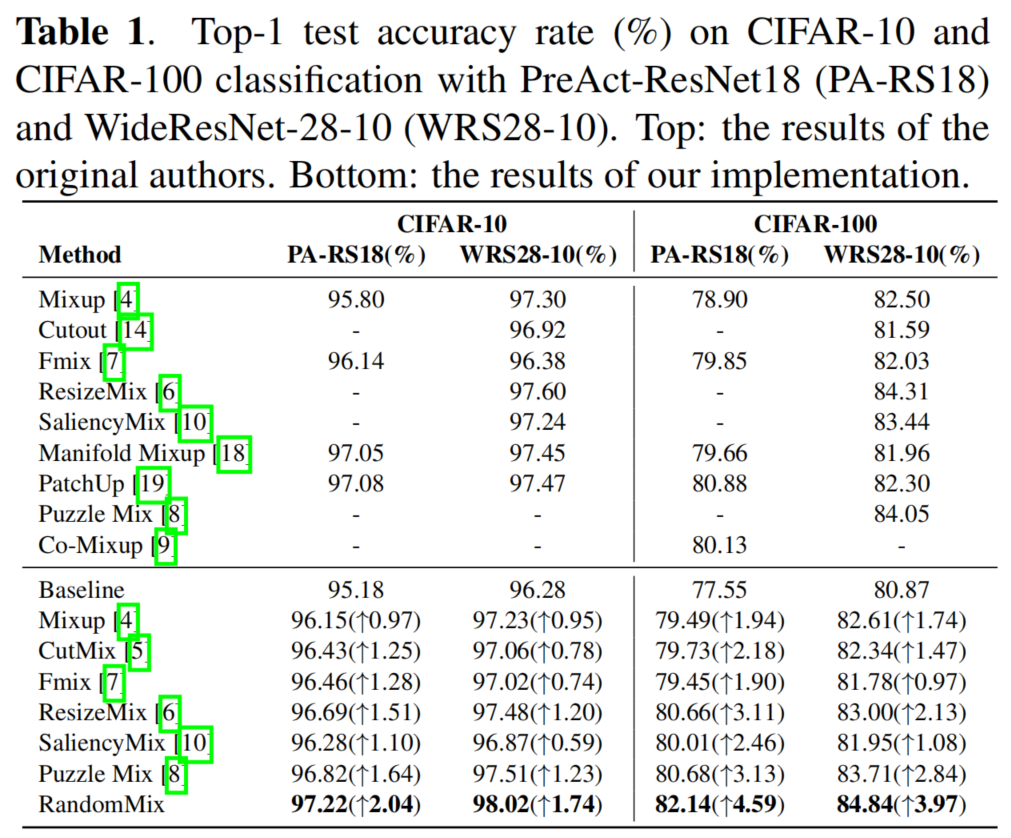
3.1 CIFAR-10 and CIFAR-100
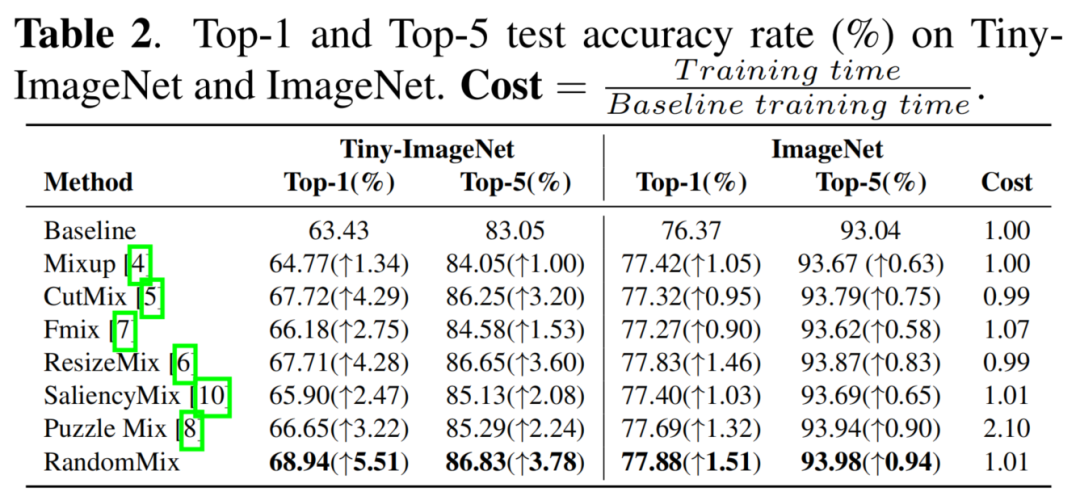
3.2 Tiny-ImageNet and ImageNet
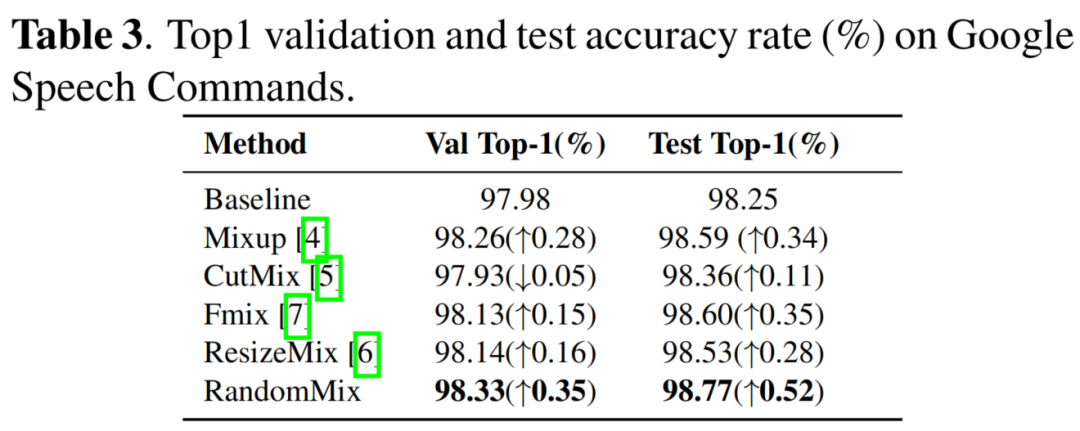
3.3 Google Speech Commands
点击进入—> CV 微信技术交流群
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()