学习来源:日撸 Java 三百行(61-70天,决策树与集成学习)_闵帆的博客-CSDN博客
一、决策树
决策树是一种机器学习的方法. 决策树的生成算法有 ID3, C4.5 和 C5.0 等. 本文主要介绍 ID3 生成算法.
决策树是一种树形结构, 其中每个内部节点表示一个属性上的判断, 每个分支代表一个判断结果的输出, 最后每个叶节点代表一种分类结果.
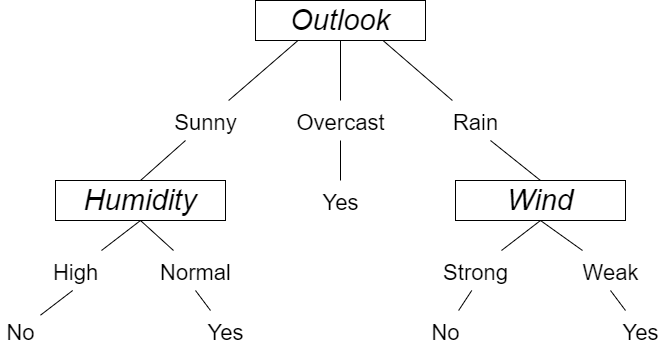
例如在下图中, 使用 Yes 和 No 来表示出去玩和不出去玩两个分类结果. 首先对属性 Outlook 判断, Outlook 表示天气, 具有 Sunny, Overcast, Rain三个判断值. 如果属性 Outlook 判断值是 Sunny, 接下来就要对 Humidity 属性判断. 如果 Outlook 的判断值是 Overcast, 就可以直接输出分类结果为 Yes.
以此类推可以通过叶节点得到所有情况下对于是否出去玩这一事件的分类结果.
二、构建步骤
1.节点的分裂:一般当一个节点所代表的属性无法给出判断时, 则选择将这一节点分成2个子节点(如不是二叉树的情况会分成 n 个子节点). 在上面的示例中对 Outlook 属性的判断就将其分裂成了三个子节点.
2.谁做父节点:这个的意思就是为什么要选 Outlook 属性做为这棵决策树的根节点.这就是之前所提到的 ID3 生成算法.
ID3: 由增熵 (Entropy) 原理来决定哪个做父节点, 哪个节点需要分裂. 对于一组数据, 熵越小说明分类结果越好. 熵定义如下:
E n t r o p y = − ∑ i = 1 n p ( x i ) log p ( x i ) Entropy = - \sum_{i=1}^{n}p(x_i)\log{p(x_i)} Entropy=−i=1∑np(xi)logp(xi)
其中 p ( x i ) p(x_i) p(xi) 表示随机事件为 x i x_i xi 的概率.
例如在数据集 weather.arff 中
@relation weather
@attribute Outlook {Sunny, Overcast, Rain}
@attribute Temperature {Hot, Mild, Cool}
@attribute Humidity {High, Normal, Low}
@attribute Windy {FALSE, TRUE}
@attribute Play {N, P}
@data
Sunny,Hot,High,FALSE,N
Sunny,Hot,High,TRUE,N
Overcast,Hot,High,FALSE,P
Rain,Mild,High,FALSE,P
Rain,Cool,Normal,FALSE,P
Rain,Cool,Normal,TRUE,N
Overcast,Cool,Normal,TRUE,P
Sunny,Mild,High,FALSE,N
Sunny,Cool,Normal,FALSE,P
Rain,Mild,Normal,FALSE,P
Sunny,Mild,Normal,TRUE,P
Overcast,Mild,High,TRUE,P
Overcast,Hot,Normal,FALSE,P
Rain,Mild,High,TRUE,N
含有 Sunny 的实例有 5 个, 其中 Play 结果为 N 的有 3 个, 结果为 P 的有 2 个. 那么就有
在出太阳时候不出去玩的概率为:
p ( P l a y = N ∣ O u t l o o k = S u n n y ) = 3 5 (1) p(Play = N | Outlook = Sunny) = \frac{3}{5} \tag{1} p(Play=N∣Outlook=Sunny)=53(1)
在出太阳时候出去玩的概率为:
p ( P l a y = P ∣ O u t l o o k = S u n n y ) = 2 5 (2) p(Play = P | Outlook = Sunny) = \frac{2}{5} \tag{2} p(Play=P∣Outlook=Sunny)=52(2)
(1) (2) 式子就是之前所提到的 p ( x i ) p(x_i) p(xi)
三、具体实现
1. 想法思路
和一般构建一颗树是一样的, 先要确立一个父节点. 在决策树中父节点的选择是通过之前增熵对每个属性处理后来选择. 当一个属性选择后就会从整体中删除表示不能够再使用.那么实际步骤就是一个递归的过程.
需要注意的是这里表示树形结构使用的是数组的双亲表示法.
2. 具体代码
package decisiontree;
import java.io.FileReader;
import java.util.Arrays;
import weka.core.*;
/**
* The ID3 decision tree inductive algorithm.
*
* @author Shi-Huai Wen Email: [email protected].
*/
public class ID3 {
/**
* The data.
*/
Instances dataset;
/**
* Is this dataset pure (only one label)?
*/
boolean pure;
/**
* The number of classes. For binary classification it is 2.
*/
int numClasses;
/**
* Available instances. Other instances do not belong this branch.
*/
int[] availableInstances;
/**
* Available attributes. Other attributes have been selected in the path
* from the root.
*/
int[] availableAttributes;
/**
* The selected attribute.
*/
int splitAttribute;
/**
* The children nodes.
*/
ID3[] children;
/**
* My label. Inner nodes also have a label. For example, <outlook = sunny,
* humidity = high> never appear in the training data, but <humidity = high>
* is valid in other cases.
*/
int label;
/**
* Small block cannot be split further.
*/
static int smallBlockThreshold = 3;
/**
* *******************
* The constructor.
*
* @param paraFilename The given file.
* *******************
*/
public ID3(String paraFilename) {
dataset = null;
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
fileReader.close();
} catch (Exception ee) {
System.out.println("Cannot read the file: " + paraFilename + "\r\n" + ee);
System.exit(0);
} // Of try
dataset.setClassIndex(dataset.numAttributes() - 1);
numClasses = dataset.classAttribute().numValues();
availableInstances = new int[dataset.numInstances()];
for (int i = 0; i < availableInstances.length; i++) {
availableInstances[i] = i;
} // Of for i
availableAttributes = new int[dataset.numAttributes() - 1];
for (int i = 0; i < availableAttributes.length; i++) {
availableAttributes[i] = i;
} // Of for i
// Initialize.
children = null;
// Determine the label by simple voting.
label = getMajorityClass(availableInstances);
// Determine whether or not it is pure.
pure = pureJudge(availableInstances);
}// Of the first constructor
/**
* *******************
* The constructor.
*
* @param paraDataset The given dataset.
* *******************
*/
public ID3(Instances paraDataset, int[] paraAvailableInstances, int[] paraAvailableAttributes) {
// Copy its reference instead of clone the availableInstances.
dataset = paraDataset;
availableInstances = paraAvailableInstances;
availableAttributes = paraAvailableAttributes;
// Initialize.
children = null;
// Determine the label by simple voting.
label = getMajorityClass(availableInstances);
// Determine whether or not it is pure.
pure = pureJudge(availableInstances);
}// Of the second constructor
/**
* *********************************
* Is the given block pure?
*
* @param paraBlock The block.
* @return True if pure.
* *********************************
*/
public boolean pureJudge(int[] paraBlock) {
pure = true;
// Just compare with 0
for (int i = 1; i < paraBlock.length; i++) {
if (dataset.instance(paraBlock[i]).classValue() != dataset.instance(paraBlock[0]).classValue()) {
pure = false;
break;
} // Of if
} // Of for i
return pure;
}// Of pureJudge
/**
* *********************************
* Compute the majority class of the given block for voting.
*
* @param paraBlock The block.
* @return The majority class.
* *********************************
*/
public int getMajorityClass(int[] paraBlock) {
int[] tempClassCounts = new int[dataset.numClasses()];
for (int i : paraBlock) {
tempClassCounts[(int) dataset.instance(i).classValue()]++;
} // Of foreach
int resultMajorityClass = -1;
int tempMaxCount = -1;
for (int i = 0; i < tempClassCounts.length; i++) {
if (tempMaxCount < tempClassCounts[i]) {
resultMajorityClass = i;
tempMaxCount = tempClassCounts[i];
} // Of if
} // Of for i
return resultMajorityClass;
}// Of getMajorityClass
/**
* *********************************
* Select the best attribute.
*
* @return The best attribute index.
* *********************************
*/
public int selectBestAttribute() {
splitAttribute = -1;
double tempMinimalEntropy = 10000;
double tempEntropy;
for (int availableAttribute : availableAttributes) {
tempEntropy = conditionalEntropy(availableAttribute);
if (tempMinimalEntropy > tempEntropy) {
tempMinimalEntropy = tempEntropy;
splitAttribute = availableAttribute;
} // Of if
} // Of foreach
return splitAttribute;
}// Of selectBestAttribute
/**
* *********************************
* Compute the conditional entropy of an attribute.
*
* @param paraAttribute The given attribute.
* @return The entropy.
* *********************************
*/
public double conditionalEntropy(int paraAttribute) {
// Step 1. Statistics.
int tempNumClasses = dataset.numClasses();
int tempNumValues = dataset.attribute(paraAttribute).numValues();
int tempNumInstances = availableInstances.length;
double[] tempValueCounts = new double[tempNumValues];
double[][] tempCountMatrix = new double[tempNumValues][tempNumClasses];
int tempClass, tempValue;
for (int availableInstance : availableInstances) {
tempClass = (int) dataset.instance(availableInstance).classValue();
tempValue = (int) dataset.instance(availableInstance).value(paraAttribute);
tempValueCounts[tempValue]++;
tempCountMatrix[tempValue][tempClass]++;
} // Of for i
// Step 2.
double resultEntropy = 0;
double tempEntropy, tempFraction;
for (int i = 0; i < tempNumValues; i++) {
if (tempValueCounts[i] == 0) {
continue;
} // Of if
tempEntropy = 0;
for (int j = 0; j < tempNumClasses; j++) {
tempFraction = tempCountMatrix[i][j] / tempValueCounts[i];
if (tempFraction == 0) {
continue;
} // Of if
// 信息熵越小, 信息的纯度越高, 信息量就越少
// H(X) = -p(x) * log p(x)
tempEntropy += -tempFraction * Math.log(tempFraction);
} // Of for j\
// 最小化条件信息熵
resultEntropy += tempValueCounts[i] / tempNumInstances * tempEntropy;
} // Of for i
return resultEntropy;
}// Of conditionalEntropy
/**
* *********************************
* Split the data according to the given attribute.
*
* @return The blocks.
* *********************************
*/
public int[][] splitData(int paraAttribute) {
int tempNumValues = dataset.attribute(paraAttribute).numValues();
int[][] resultBlocks = new int[tempNumValues][];
int[] tempSizes = new int[tempNumValues];
// First scan to count the size of each block.
int tempValue;
for (int availableInstance : availableInstances) {
tempValue = (int) dataset.instance(availableInstance).value(paraAttribute);
tempSizes[tempValue]++;
} // Of for i
// Allocate space.
for (int i = 0; i < tempNumValues; i++) {
resultBlocks[i] = new int[tempSizes[i]];
} // Of for i
// Second scan to fill.
Arrays.fill(tempSizes, 0);
for (int availableInstance : availableInstances) {
tempValue = (int) dataset.instance(availableInstance).value(paraAttribute);
// Copy data.
resultBlocks[tempValue][tempSizes[tempValue]] = availableInstance;
tempSizes[tempValue]++;
} // Of for i
return resultBlocks;
}// Of splitData
/**
* *********************************
* Build the tree recursively.
* *********************************
*/
public void buildTree() {
// Is pure return.
if (pureJudge(availableInstances)) {
return;
} // Of if
// Less than or equal to small block just return
if (availableInstances.length <= smallBlockThreshold) {
return;
} // Of if
selectBestAttribute();
int[][] tempSubBlocks = splitData(splitAttribute);
children = new ID3[tempSubBlocks.length];
// Construct the remaining attribute set.
int[] tempRemainingAttributes = new int[availableAttributes.length - 1];
for (int i = 0; i < availableAttributes.length; i++) {
if (availableAttributes[i] < splitAttribute) {
tempRemainingAttributes[i] = availableAttributes[i];
} else if (availableAttributes[i] > splitAttribute) {
tempRemainingAttributes[i - 1] = availableAttributes[i];
} // Of if
} // Of for i
// Construct children.
for (int i = 0; i < children.length; i++) {
if ((tempSubBlocks[i] == null) || (tempSubBlocks[i].length == 0)) {
children[i] = null;
} else {
// System.out.println("Building children #" + i + " with
// instances " + Arrays.toString(tempSubBlocks[i]));
children[i] = new ID3(dataset, tempSubBlocks[i], tempRemainingAttributes);
// Important code: do this recursively
children[i].buildTree();
} // Of if
} // Of for i
}// Of buildTree
/**
* *********************************
* Classify an instance.
*
* @param paraInstance The given instance.
* @return The prediction.
* *********************************
*/
public int classify(Instance paraInstance) {
if (children == null) {
return label;
} // Of if
ID3 tempChild = children[(int) paraInstance.value(splitAttribute)];
if (tempChild == null) {
return label;
} // Of if
return tempChild.classify(paraInstance);
}// Of classify
/**
* *********************************
* Test on a testing set.
*
* @param paraDataset The given testing data.
* @return The accuracy.
* *********************************
*/
public double test(Instances paraDataset) {
double tempCorrect = 0;
for (int i = 0; i < paraDataset.numInstances(); i++) {
if (classify(paraDataset.instance(i)) == (int) paraDataset.instance(i).classValue()) {
tempCorrect++;
} // Of i
} // Of for i
return tempCorrect / paraDataset.numInstances();
}// Of test
/**
* *********************************
* Test on the training set.
*
* @return The accuracy.
* *********************************
*/
public double selfTest() {
return test(dataset);
}// Of selfTest
/**
* ******************
* Overrides the method claimed in Object.
*
* @return The tree structure.
* ******************
*/
public String toString() {
StringBuilder resultString = new StringBuilder();
String tempAttributeName = dataset.attribute(splitAttribute).name();
if (children == null) {
resultString.append("class = ").append(label);
} else {
for (int i = 0; i < children.length; i++) {
if (children[i] == null) {
resultString.append(tempAttributeName)
.append(" = ")
.append(dataset.attribute(splitAttribute).value(i))
.append(":")
.append("class = ")
.append(label)
.append("\r\n");
} else {
resultString.append(tempAttributeName)
.append(" = ")
.append(dataset.attribute(splitAttribute).value(i))
.append(":")
.append(children[i])
.append("\r\n");
} // Of if
} // Of for i
} // Of if
return resultString.toString();
}// Of toString
/**
* ************************
* Test this class.
* ************************
*/
public static void id3Test() {
ID3 tempID3 = new ID3("D:/Work/sampledata/weather.arff");
ID3.smallBlockThreshold = 3;
tempID3.buildTree();
System.out.println("The tree is: \r\n" + tempID3);
double tempAccuracy = tempID3.selfTest();
System.out.println("The accuracy is: " + tempAccuracy);
}// Of id3Test
/**
* ************************
* Test this class.
*
* @param args Not used now.
* ************************
*/
public static void main(String[] args) {
id3Test();
}// Of main
} // Of class ID3
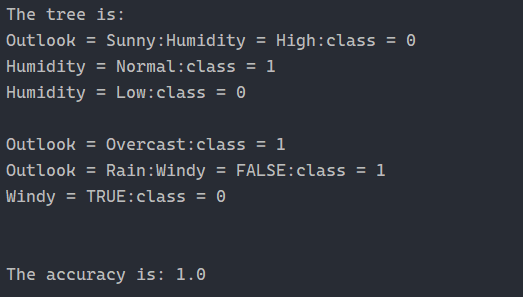
3. 运行截图
四、总结
对建决策树的大致过程了解了, 相比起简单的 if-else, 决策树的精髓就在与 ID3 生成算法, 采用了信息熵这一个通信方面的知识. 果然研究要集百家之长才能得到更好的解决方法.