目录
一,JDK8之后HashMap的新特性
JDK8之后的hashMap,采用 数组+链表+红黑树 的结构
当链表冲突严重时,会将链表转换成红黑树的结构,提高查询效率。
冲突严重:是指
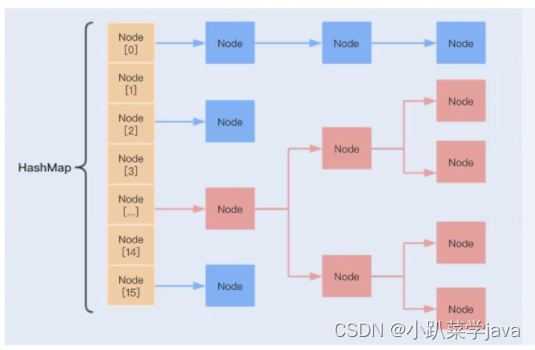
JDK8之前,hashMap采用 数组 + 链表的结构
二,hashMap源码属性解读
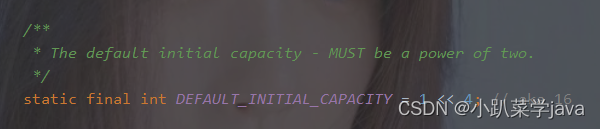
(一),默认初始化容量数量:16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
(二),最大数组容量:2^30
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16

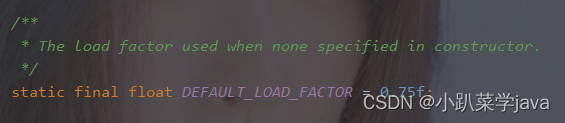
(三),默认负载因子:0.75f
static final float DEFAULT_LOAD_FACTOR = 0.75f;
(四),触发树化条件1,链表阈值:
链表的长度超过8,并且桶的个数达到64,就会触发链表转为树结构,否则只是数组扩容。
static final int TREEIFY_THRESHOLD = 8;

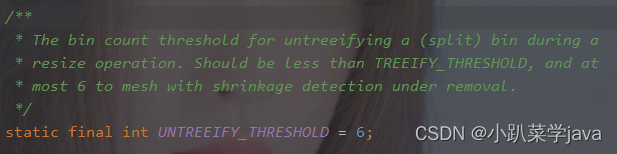
(五),解树化的阈值:
当树的节点个数为6时,就会触发解树化转为链表。
static final int UNTREEIFY_THRESHOLD = 6;
(六),触发树化条件二,hash桶阈值(数组元素个数):
static final int MIN_TREEIFY_CAPACITY = 64;
当数组个超过64,并且某个链表的节点个数 > 8 时,同时满足这两个条件,才会触发树化。

三,HashMap的put方法
(一)put方法

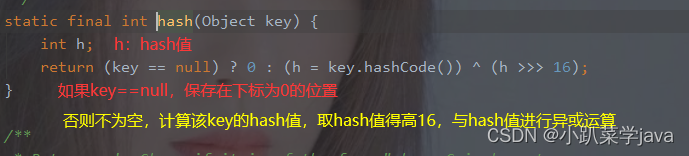
(二),hash方法()
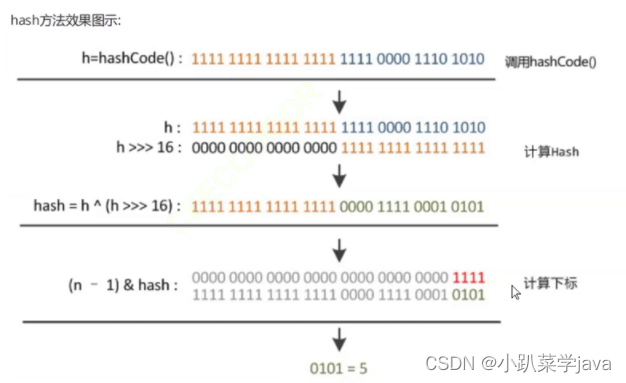
例如:

此时计算下来得结果并不是hash索引,长江此时计算得值传入到putVal中进一步运算才能得到真正得下标。
(三),putVal方法

采用&运算得原因:
这里hash表得长度为2^i,采用&是为压榨性能,
原因:n = 16 任意正整数 x , x & (n - 1) == x % n; 并且得到得结果 res < n,保证了索引在hash表的范围之内。
&&位运算得速率远大于数学运算。
put方法的核心逻辑:

equals相同的两个对象,那么他们的hashCode一定相同,原因:两个对象时相同的,那么经过hash运算,得到的hashCode一定相同,
hashCode相同的两个对象,equals不一定相同,原因:当发生了hash冲突,他们的hash值相同,但对象不同。
四,hashMap的构造方法
(一),无参构造

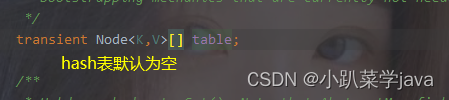
懒加载模式:在创建时,不开辟空间,只有在第一次添加元素时,才开始对表扩容。
resize()方法既是扩容方法,也是初始化方法。
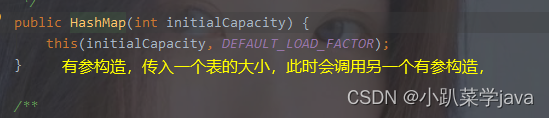
(二),有参构造

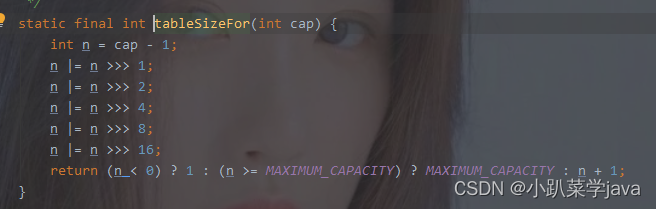
五,resize()方法
resize()方法既是扩容方法,也是初始化方法。
六,关于Map和Set的关系
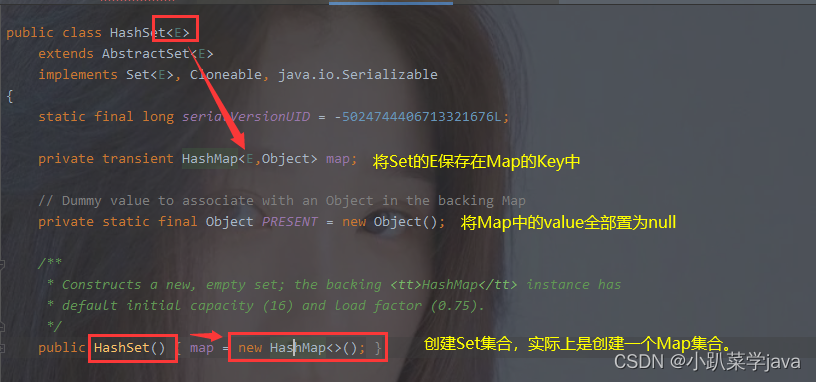
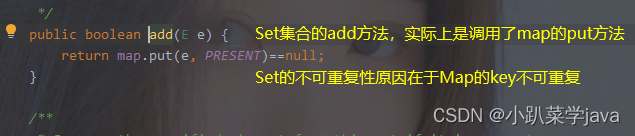
Set集合实际上就是用Map集合的key保存的,这也就保证了Set的不可重复性。
HashSet使用HashMap的key保存,这就保证了HashSet可以为空,null全部保存在map的0位置。
TreeSet使用TreeMap的key保存的,也就保证了TreeSet不可以为空。