工具
编程语言: Node.JS
工具包: XSLT
SNL程序示例
program p
type t1 = integer;
var integer v1, v2;
procedure
q(integer i);
var integer a;
begin
a := i;
write(a)
end
begin
read(v1);
if v1 < 10
then v1 := v1 + 10
else v1 := v1 - 10
fi;
q(v1)
end.
具体分析流程
1.将源代码读入为字符流
2.通过状态机进行分词,状态转换图如下所示

识别SNL单词的DFA表示
3.对从状态机中读出来的单词进一步处理,形成token列表,放在数组中,供下一步语法分析使用
示例如下:
{ lex: 'PROGRAM', sem: 'program', row: 1 },
{ lex: 'ID', sem: 'p', row: 1 },
{ lex: 'TYPE', sem: 'type', row: 2 },
{ lex: 'ID', sem: 't1', row: 2 },
{ lex: '=', sem: null, row: 2 },
{ lex: 'INTEGER', sem: 'integer', row: 2 },
{ lex: ';', sem: null, row: 2 },
{ lex: 'VAR', sem: 'var', row: 3 },
{ lex: 'INTEGER', sem: 'integer', row: 3 },
{ lex: 'ID', sem: 'v1', row: 3 },
{ lex: ',', sem: null, row: 3 },
{ lex: 'ID', sem: 'v2', row: 3 },
{ lex: ';', sem: null, row: 3 },
{ lex: 'PROCEDURE', sem: 'procedure', row: 4 },
{ lex: 'ID', sem: 'q', row: 5 },
{ lex: '(', sem: null, row: 5 },
{ lex: 'INTEGER', sem: 'integer', row: 5 },
{ lex: 'ID', sem: 'i', row: 5 },
{ lex: ')', sem: null, row: 5 },
{ lex: ';', sem: null, row: 5 },
{ lex: 'VAR', sem: 'var', row: 6 },
{ lex: 'INTEGER', sem: 'integer', row: 6 },
{ lex: 'ID', sem: 'a', row: 6 },
{ lex: ';', sem: null, row: 6 },
{ lex: 'BEGIN', sem: 'begin', row: 7 },
{ lex: 'ID', sem: 'a', row: 8 },
{ lex: ':=', sem: null, row: 8 },
{ lex: 'ID', sem: 'i', row: 8 },
{ lex: ';', sem: null, row: 8 },
{ lex: 'WRITE', sem: 'write', row: 9 },
{ lex: '(', sem: null, row: 9 },
{ lex: 'ID', sem: 'a', row: 9 },
{ lex: ')', sem: null, row: 9 },
{ lex: 'END', sem: 'end', row: 10 },
{ lex: 'BEGIN', sem: 'begin', row: 11 },
{ lex: 'READ', sem: 'read', row: 12 },
{ lex: '(', sem: null, row: 12 },
{ lex: 'ID', sem: 'v1', row: 12 },
{ lex: ')', sem: null, row: 12 },
{ lex: ';', sem: null, row: 12 },
{ lex: 'IF', sem: 'if', row: 13 },
{ lex: 'ID', sem: 'v1', row: 13 },
{ lex: '<', sem: null, row: 13 },
{ lex: 'INTC', sem: '10', row: 13 },
{ lex: 'THEN', sem: 'then', row: 14 },
{ lex: 'ID', sem: 'v1', row: 14 },
{ lex: ':=', sem: null, row: 14 },
{ lex: 'ID', sem: 'v1', row: 14 },
{ lex: '+', sem: null, row: 14 },
{ lex: 'INTC', sem: '10', row: 14 },
{ lex: 'ELSE', sem: 'else', row: 15 },
{ lex: 'ID', sem: 'v1', row: 15 },
{ lex: ':=', sem: null, row: 15 },
{ lex: 'ID', sem: 'v1', row: 15 },
{ lex: '-', sem: null, row: 15 },
{ lex: 'INTC', sem: '10', row: 15 },
{ lex: 'FI', sem: 'fi', row: 16 },
{ lex: ';', sem: null, row: 16 },
{ lex: 'ID', sem: 'q', row: 17 },
{ lex: '(', sem: null, row: 17 },
{ lex: 'ID', sem: 'v1', row: 17 },
{ lex: ')', sem: null, row: 17 },
{ lex: 'END', sem: 'end', row: 18 } ]
4.进行语法分析,采用的方法为LL(1)分析法
5.录入原始形式的生成式,存放在对象(哈希表)中,如下所示:
Program: 'ProgramHead DeclarePart ProgramBody',
ProgramHead: 'PROGRAM ProgramName',
ProgramName: 'ID',
DeclarePart: 'TypeDecpart VarDecpart ProcDecpart',
TypeDecpart: 'ε | TypeDec',
TypeDec: 'TYPE TypeDecList',
TypeDecList: 'TypeId = TypeDef ; TypeDecMore',
TypeDecMore: 'ε | TypeDecList',
TypeId: 'ID',
TypeDef: 'BaseType | StructureType | ID',
BaseType: 'INTEGER | CHAR',
StructureType: 'ArrayType | RecType',
ArrayType: 'ARRAY [ Low .. Top ] OF BaseType',
Low: 'INTC',
Top: 'INTC',
RecType: 'RECORD FieldDecList END',
FieldDecList: 'BaseType IdList ; FieldDecMore | ArrayType IdList ; FieldDecMore',
FieldDecMore: 'ε | FieldDecList',
IdList: 'ID IdMore',
IdMore: 'ε | , IdList',
VarDecpart: 'ε | VarDec',
VarDec: 'VAR VarDecList',
VarDecList: 'TypeDef VarIdList ; VarDecMore',
VarDecMore: 'ε | VarDecList',
VarIdList: 'ID VarIdMore',
VarIdMore: 'ε | , VarIdList',
ProcDecpart: 'ε | ProcDec',
ProcDec: 'PROCEDURE ProcName ( ParamList ) ; ProcDecPart ProcBody ProcDecMore',
ProcDecMore: 'ε | ProcDec',
ProcName: 'ID',
ParamList: 'ε | ParamDecList',
ParamDecList: 'Param ParamMore',
ParamMore: 'ε | ; ParamDecList',
Param: 'TypeDef FormList | VAR TypeDef FormList',
FormList: 'ID FidMore',
FidMore: 'ε | , FormList',
ProcDecPart: 'DeclarePart',
ProcBody: 'ProgramBody',
ProgramBody: 'BEGIN StmList END',
StmList: 'Stm StmMore',
StmMore: 'ε | ; StmList',
Stm: 'ConditionalStm | LoopStm | InputStm | OutputStm | ReturnStm | ID AssCall',
AssCall: 'AssignmentRest | CallStmRest',
AssignmentRest: 'VariMore := Exp',
ConditionalStm: 'IF RelExp THEN StmList ELSE StmList FI',
LoopStm: 'WHILE RelExp DO StmList ENDWH',
InputStm: 'READ ( Invar ) ',
Invar: 'ID',
OutputStm: 'WRITE ( Exp ) ',
ReturnStm: 'RETURN',
CallStmRest: '( ActParamList )',
ActParamList: 'ε | Exp ActParamMore',
ActParamMore: 'ε | ,ActParamList',
RelExp: 'Exp OtherRelE',
OtherRelE: 'CmpOp Exp',
Exp: 'Term OtherTerm',
OtherTerm: 'ε | AddOp Exp',
Term: 'Factor OtherFactor',
OtherFactor: 'ε | MultOp Term',
Factor: '( Exp ) | INTC | Variable',
Variable: 'ID VariMore',
VariMore: 'ε | [ Exp ] | . FieldVar',
FieldVar: 'ID FieldVarMore',
FieldVarMore: 'ε | [ Exp ]',
CmpOp: '< | =',
AddOp: '+ | -',
MultOp: '* | /'
6.构建LL1分析表,如下所示

7.根据LL1的分析方法,构建相应的符号栈,输入流栈,终极符列表,非终极符列表,生成式列表,LL1分析表对象,按照LL1的分析流程进行分析,如果出错,则抛出错误,告诉用户分析失败,同时给出出错的行数,此时分析栈中的具体内容,如果分析通过,则显示分析通过。
成功的运行结果

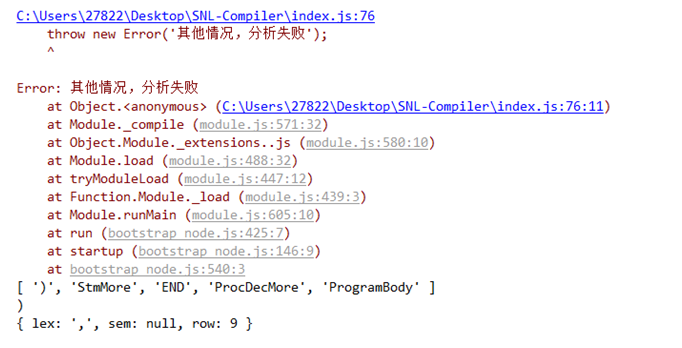
失败的运行结果
结论
此程序实现了SNL的词法分析和语法分析的基本功能,可以通过用例产生预期效果。在程序编写的过程中借鉴了教材《编译程序的设计与实现》。此次编写程序使我更加了解到编译器的重要性,并且提高了自己编程能力,希望以后自己有时间多多学习一下这方面。