文章目录
分库
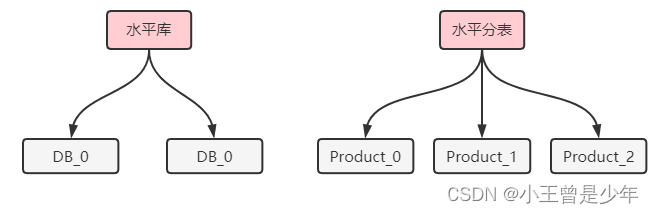
分库分表具有相似的思路,假设商品ID = 100,按照所有表的个数进行取模
100 / (3*2) = 4
首先计算要选择哪个库:
4 / 3 = 1
每个库有3个表,所以要除以3
其次再计算落在哪个表:
4 % 3 = 1
分表
垂直分表:
每个表存储一部分字段:
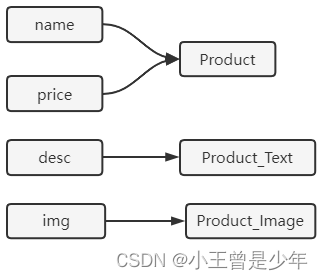
对于大部分业务来说,只用到商品主表中就能获得到对应的信息
水平分表:
不同的数据落在不同的表中

hash手段:
- 商品
ID % 3- 缺点:不容易做水平扩展,每次水平扩展都要伴随着数据迁移
- 缺点:不容易做水平扩展,每次水平扩展都要伴随着数据迁移
- 订单时间片
- 缺点:数据分布不均匀
从业务层面进一步探讨分库分表
用户、订单、商品数据库都要做分库分表,如果没有做那就是业务量还不大或公司比较有钱用的是ORACLE的数据库。
在真正的业务里,比如订单表根据订单id做了分库分表,但如果还想查询某个用户下面所有的订单就比较麻烦了,很可能要在所有表里做扫描查询。
这就要借助数据异构,除了对订单id分库分表外,还把所有数据对用户id也做了分库分表,所以相同的数据可能不止一条,但数据异构同时涉及到同步的问题,甚至要跨存储介质进行同步(如MySQL和Redis之间)
备库转正法
假设最开始时有两个库:

之后流量增大时会先采取读写分离的操作

备库中所有数据都和主库一致,路由到主库的请求在备库中也会有相应的数据记录,同时也可以修改路由规则把备库转正:

同时还要解除原先的主从备份,之后再给转正的机器配备备库
注意: 这种方式必须成倍数增加机器数量2->4->8…,这样才能不影响之前机器的路由规则
增量存量同步法

首先上线两台没有数据的机器,将新生成的数据首先同步给新上线的两台数据库,之后再由DBA将原先的存量数据同步至新上线的数据库中

迁移好了之后还需要更改一下路由规则,把相应的请求同步到新添加的机器上
**注意:**这种方式必须成倍数增加机器数量2->4->8…,等所有数据同步完成之后才能更改路由表