文章目录
共享存储pv、pvc、StorageClass使用详解
共享存储
Kubernetes对于有状态的容器应用或者对数据需要持久化的应用,不仅需要将容器内的目录挂载到宿主机的目录或者emptyDir临时存储卷,而且需要更加可靠的存储来保存应用产生的重要数据,以便容器应用在重建之后仍然可以使用之前的数据。
不过,存储资源和计算资源(CPU/内存)的管理方式完全不同。为了能够屏蔽底层存储实现的细节,让用户方便使用,同时让管理员方便管理,Kubernetes从1.0版本就引入PersistentVolume(PV)和PersistentVolumeClaim(PVC)两个资源对象来实现对存储的管理子系统。
PV是对底层网络共享存储的抽象,将共享存储定义为一种“资源”,比如Node也是一种容器应用可以“消费”的资源。PV由管理员创建和配置,它与共享存储的具体实现直接相关,例如GlusterFS、iSCSI、RBD或GCE或AWS公有云提供的共享存储,通过插件式的机制完成与共享存储的对接,以供应用访问和使用。
PVC则是用户对存储资源的一个“申请”。就像Pod“消费”Node的资源一样,PVC能够“消费”PV资源。PVC可以申请特定的存储空间和访问模式。使用PVC“申请”到一定的存储空间仍然不能满足应用对存储设备的各种需求。
通常应用程序都会对存储设备的特性和性能有不同的要求,包括读写速度、并发性能、数据冗余等更高的要求,Kubernetes从1.4版本开始引入了一个新的资源对象StorageClass,用于标记存储资源的特性和性能。到1.6版本时,StorageClass和动态资源供应的机制得到了完善,实现了存储卷的按需创建,在共享存储的自动化管理进程中实现了重要的一步。
通过StorageClass的定义,管理员可以将存储资源定义为某种类别(Class),正如存储设备对于自身的配置描述(Profile),例如“快速存储”“慢速存储”“有数据冗余”“无数据冗余”等。用户根据StorageClass的描述就能够直观地得知各种存储资源的特性,就可以根据应用对存资源的需求去申请存储资源了。Kubernetes从1.9版本开始引入容器存储接口Container Storage Interface(CSI)机制,目标是在Kubernetes和外部存储系统之间建立一套标准的存储管理接口,通过该接口为容器提供存储服务,类似于CRI(容器运行时接口)和CNI(容器网络接口)。
PV
PV作为存储资源,主要包括存储能力、访问模式、存储类型、回收策略、后端存储类型等关键信息的设置。下面的例子声明的PV具有如下属性:5GiB存储空间,访问模式为ReadWriteOnce,存储类型为slow(要求在系统中已存在名为slow的StorageClass),回收策略为Recycle,并且后端存储类型为nfs(设置了NFS Server的IP地址和路径):
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs
spec:
storageClassName: slow
persistentVolumeReclaimPolicy: Recycle
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
server: 10.244.1.4
path: "/"
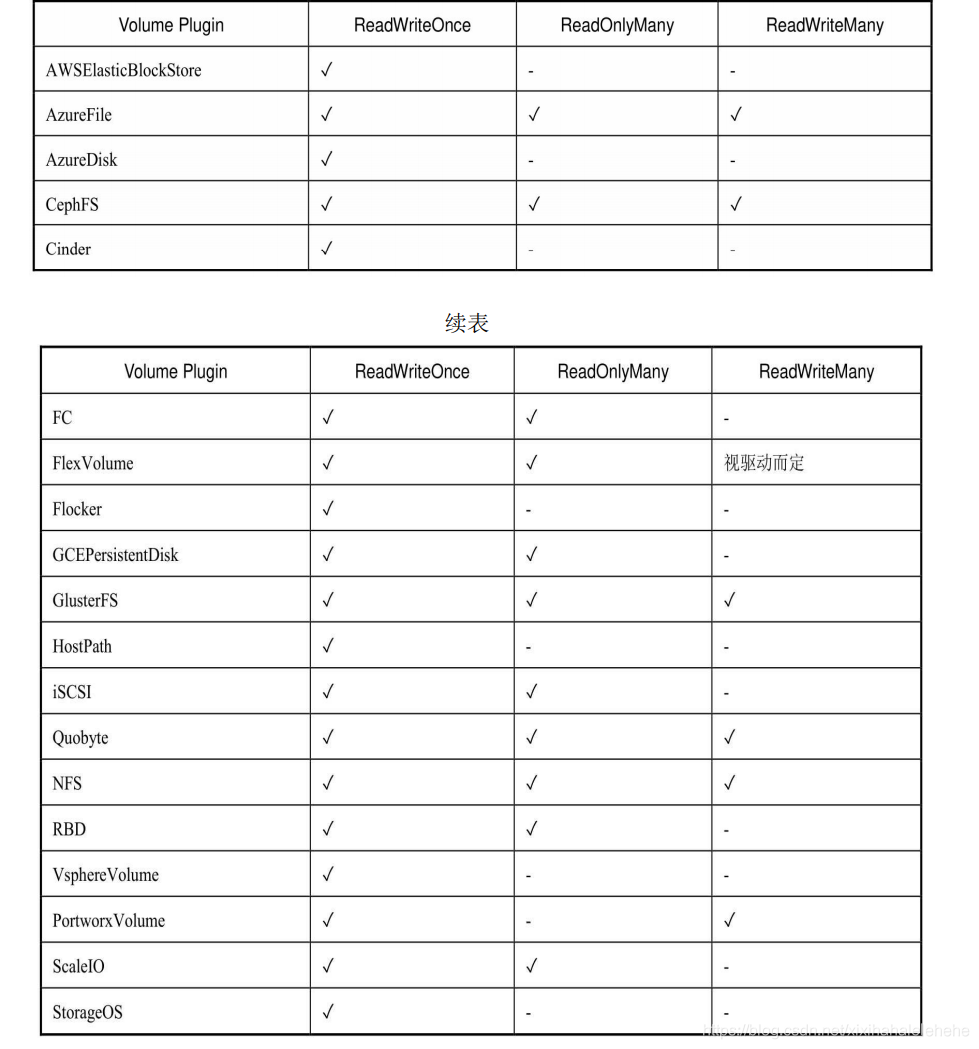
Kubernetes支持的PV类型如下。
◎ AWSElasticBlockStore:AWS公有云提供的ElasticBlockStore。
◎ AzureFile:Azure公有云提供的File。
◎ AzureDisk:Azure公有云提供的Disk。
◎ CephFS:一种开源共享存储系统。
◎ FC(Fibre Channel):光纤存储设备。
◎ FlexVolume:一种插件式的存储机制。
◎ Flocker:一种开源共享存储系统。
◎ GCEPersistentDisk:GCE公有云提供的PersistentDisk。
◎ Glusterfs:一种开源共享存储系统。
◎ HostPath:宿主机目录,仅用于单机测试。
◎ iSCSI:iSCSI存储设备。
◎ Local:本地存储设备,从Kubernetes 1.7版本引入,到1.14版本时更新为稳定版,目前可以通过指定块(Block)设备提供Local PV,或通过社区开发的sig-storage-local-static-provisioner插件(https://github.com/kubernetes-sigs/sigstorage-local-static-provisioner)来管理Local PV的生命周期。
◎ NFS:网络文件系统。
◎ Portworx Volumes:Portworx提供的存储服务。
◎ Quobyte Volumes:Quobyte提供的存储服务。
◎ RBD(Ceph Block Device):Ceph块存储。
◎ ScaleIO Volumes:DellEMC的存储设备。
◎ StorageOS:StorageOS提供的存储服务。
◎ VsphereVolume:VMWare提供的存储系统。
每种存储类型都有各自的特点,在使用时需要根据它们各自的参数进行设置 。
Kubernetes从1.13版本开始引入存储卷类型的设置(volumeMode=xxx),可选项包 Filesystem(文件系统)和Block(块设备),默认值为Filesystem。
目前有以下PV类型支持块设备类型:
◎ AWSElasticBlockStore
◎ AzureDisk
◎ FC
◎ GCEPersistentDisk
◎ iSCSI
◎ Local volume
◎ RBD(Ceph Block Device)
◎ VsphereVolume(alpha)
对PV进行访问模式的设置,用于描述用户的应用对存储资源的访问权限。访问模式如下。
◎ ReadWriteOnce(RWO):读写权限,并且只能被单个Node挂
载。
◎ ReadOnlyMany(ROX):只读权限,允许被多个Node挂载。
◎ ReadWriteMany(RWX):读写权限,允许被多个Node挂载。
某些PV可能支持多种访问模式,但PV在挂载时只能使用一种访问模式,多种访问模式不能同时生效。
通过PV定义中的persistentVolumeReclaimPolicy字段进行设置,可选项如下:
- 保留(Retain)
保留数据,需要手工处理。回收策略 Retain 使得用户可以手动回收资源。当 PersistentVolumeClaim 对象 被删除时,PersistentVolume 卷仍然存在,对应的数据卷被视为"已释放(released)"。 由于卷上仍然存在这前一申领人的数据,该卷还不能用于其他申领。 管理员可以通过下面的步骤来手动回收该卷:
删除 PersistentVolume 对象。与之相关的、位于外部基础设施中的存储资产 (例如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)在 PV 删除之后仍然存在。
根据情况,手动清除所关联的存储资产上的数据。
手动删除所关联的存储资产;如果你希望重用该存储资产,可以基于存储资产的 定义创建新的 PersistentVolume 卷对象。
- 删除(Delete)
对于支持 Delete 回收策略的卷插件,删除动作会将 PersistentVolume 对象从 Kubernetes 中移除,同时也会从外部基础设施(如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)中移除所关联的存储资产。 动态供应的卷会继承其 StorageClass 中设置的回收策略,该策略默认 为 Delete。 管理员需要根据用户的期望来配置 StorageClass;否则 PV 卷被创建之后必须要被 编辑或者修补。参阅更改 PV 卷的回收策略
- 回收(Recycle)
警告: 回收策略 Recycle 已被废弃。取而代之的建议方案是使用动态供应。
在将PV挂载到一个Node上时,根据后端存储的特点,可能需要设置额外的挂载参数,可以根据PV定义中的mountOptions字段进行设置。下面的例子为对一个类型为gcePersistentDisk的PV设置挂载参数:

目前,以下PV类型支持设置挂载参数:
◎ AWSElasticBlockStore
◎ AzureDisk
◎ AzureFile
◎ CephFS
◎ Cinder (OpenStack block storage)
◎ GCEPersistentDisk
◎ Glusterfs
◎ NFS
◎ Quobyte Volumes
◎ RBD (Ceph Block Device)
◎ StorageOS
◎ VsphereVolume
◎ iSCSI
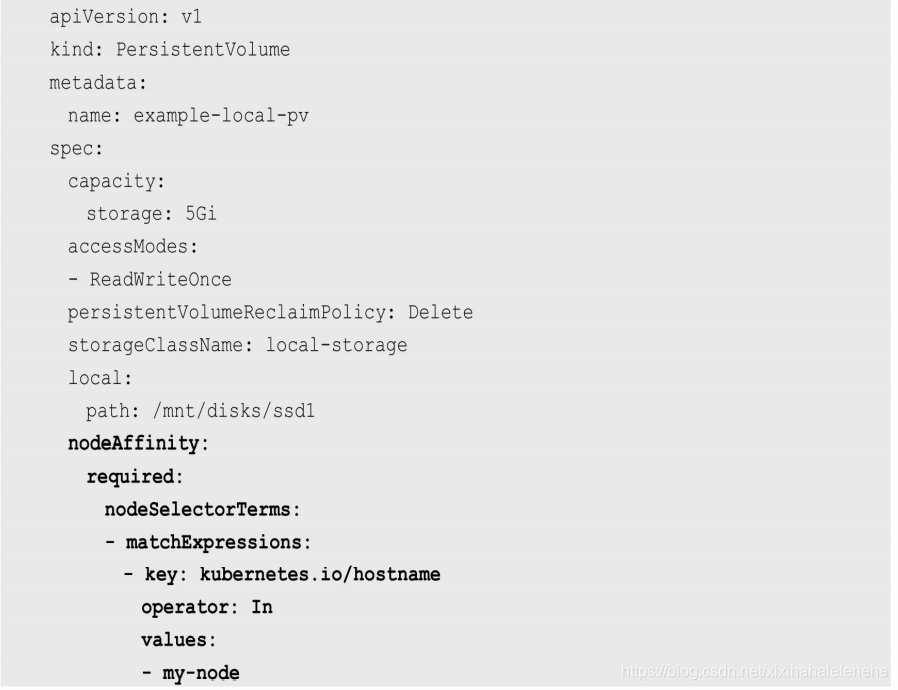
PV可以设置节点亲和性来限制只能通过某些Node访问Volume,可以在PV定义中的nodeAffinity字段进行设置。使用这些Volume的Pod将被调度到满足条件的Node上。
这个参数仅用于Local存储卷,例如:
公有云提供的存储卷(如AWS EBS、GCE PD、Azure Disk等)都由公有云自动完成节点亲和性设置,无须用户手工设置.
通过在 PersistentVolumeClaim 中指定 PersistentVolume,你可以声明该特定 PV 与 PVC 之间的绑定关系。如果该 PersistentVolume 存在且未被通过其 claimRef 字段预留给 PersistentVolumeClaim,则该 PersistentVolume 会和该 PersistentVolumeClaim 绑定到一起。
绑定操作不会考虑某些卷匹配条件是否满足,包括节点亲和性等等。 控制面仍然会检查 存储类、访问模式和所请求的 存储尺寸都是合法的。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: foo
spec:
storageClassName: "" # 此处须显式设置空字符串,否则会被设置为默认的 StorageClass
volumeName: foo-pv
...
此方法无法对 PersistentVolume 的绑定特权做出任何形式的保证。 如果有其他 PersistentVolumeClaim 可以使用你所指定的 PV,则你应该首先预留 该存储卷。你可以将 PV 的 claimRef 字段设置为相关的 PersistentVolumeClaim 以确保其他 PVC 不会绑定到该 PV 卷。
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-pv
spec:
storageClassName: ""
claimRef:
name: foo-pvc
namespace: foo
...
如果你想要使用 claimPolicy 属性设置为 Retain 的 PersistentVolume 卷 时,包括你希望复用现有的 PV 卷时,这点是很有用的。
某个PV在生命周期中可能处于以下4个阶段(Phaes)之一。
◎ Available:可用状态,还未与某个PVC绑定。
◎ Bound:已与某个PVC绑定。
◎ Released:绑定的PVC已经删除,资源已释放,但没有被集群回收。
◎ Failed:自动资源回收失败。
PVC 对象通常由开发人员创建;或者以 PVC 模板的方式成为 StatefulSet 的一部分,然后由 StatefulSet控制器负责创建带编号的 PVC。
那么,这个 PV 对象,又是如何变成容器里的一个持久化存储的呢?
所谓容器的 Volume,其实就是将一个宿主机上的目录,跟一个容器里的目录绑定挂载在了一起。
而所谓的“持久化 Volume”,指的就是这个宿主机上的目录,具备“持久性”。即:这个目录里面的内容,既不会因为容器的删除而被清理掉,也不会跟当前的宿主机绑定。这样,当容器被重启或者在其他节点上重建出来之后,它仍然能够通过挂载这个 Volume,访问到这些内容。
显然,我们前面使用的 hostPath 和 emptyDir 类型的 Volume 并不具备这个特征:它们既有可能被 kubelet 清理掉,也不能被“迁移”到其他节点上。所以,大多数情况下,持久化 Volume 的实现,往往依赖于一个远程存储服务,比如:远程文件存储(比如,NFS、GlusterFS)、远程块存储(比如,公有云提供的远程磁盘)等等。而 Kubernetes 需要做的工作,就是使用这些存储服务,来为容器准备一个持久化的宿主机目录,以供将来进行绑定挂载时使用。
而所谓“持久化”,指的是容器在这个目录里写入的文件,都会保存在远程存储中,从而使得这个目录具备了“持久性”。这个准备“持久化”宿主机目录的过程,我们可以形象地称为“两阶段处理”。
当一个 Pod 调度到一个节点上之后,kubelet 就要负责为这个 Pod 创建它的 Volume 目录。默认情况下,kubelet 为 Volume 创建的目录是如下所示的一个宿主机上的路径:
/var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>
接下来,kubelet 要做的操作就取决于你的 Volume 类型了。如果你的 Volume 类型是远程块存储,比如 Google Cloud 的 Persistent Disk(GCE 提供的远程磁盘服务),那么 kubelet 就需要先调用 Goolge Cloud 的 API,将它所提供的 Persistent Disk 挂载到 Pod 所在的宿主机上。
备注:你如果不太了解块存储的话,可以直接把它理解为:一块磁盘。
这一步为虚拟机挂载远程磁盘的操作,对应的正是“两阶段处理”的第一阶段。在 Kubernetes 中,我们把这个阶段称为 Attach。
Attach 阶段完成后,为了能够使用这个远程磁盘,kubelet 还要进行第二个操作,即:格式化这个磁盘设备,然后将它挂载到宿主机指定的挂载点上。
这个将磁盘设备格式化并挂载到 Volume 宿主机目录的操作,对应的正是“两阶段处理”的第二个阶段,我们一般称为:Mount。
Mount 阶段完成后,这个 Volume 的宿主机目录就是一个“持久化”的目录了,容器在它里面写入的内容,会保存在 Google Cloud 的远程磁盘中。而如果你的 Volume 类型是远程文件存储(比如 NFS)的话,kubelet 的处理过程就会更简单一些。因为在这种情况下,kubelet 可以跳过“第一阶段”(Attach)的操作,这是因为一般来说,远程文件存储并没有一个“存储设备”需要挂载在宿主机上。所以,kubelet 会直接从“第二阶段”(Mount)开始准备宿主机上的 Volume 目录。
在这一步,kubelet 需要作为 client,将远端 NFS 服务器的目录(比如:“/”目录),挂载到 Volume 的宿主机目录上。通过这个挂载操作,Volume 的宿主机目录就成为了一个远程 NFS 目录的挂载点,后面你在这个目录里写入的所有文件,都会被保存在远程 NFS 服务器上。所以,我们也就完成了对这个 Volume 宿主机目录的“持久化”。
对应地,在删除一个 PV 的时候,Kubernetes 也需要 Unmount 和 Dettach 两个阶段来处理。这个过程我就不再详细介绍了,执行“反向操作”即可。
实际上,你可能已经发现,这个 PV 的处理流程似乎跟 Pod 以及容器的启动流程没有太多的耦合,只要 kubelet 在向 Docker 发起 CRI 请求之前,确保“持久化”的宿主机目录已经处理完毕即可。
所以,在 Kubernetes 中,上述关于 PV 的“两阶段处理”流程,是靠独立于 kubelet 主控制循环(Kubelet Sync Loop)之外的两个控制循环来实现的。
其中,“第一阶段”的 Attach(以及 Dettach)操作,是由 Volume Controller 负责维护的,这个控制循环的名字叫作:AttachDetachController。而它的作用,就是不断地检查每一个 Pod 对应的 PV,和这个 Pod 所在宿主机之间挂载情况。从而决定,是否需要对这个 PV 进行 Attach(或者 Dettach)操作。
需要注意,作为一个 Kubernetes 内置的控制器,Volume Controller 自然是 kube-controller-manager 的一部分。所以,AttachDetachController 也一定是运行在 Master 节点上的。当然,Attach 操作只需要调用公有云或者具体存储项目的 API,并不需要在具体的宿主机上执行操作,所以这个设计没有任何问题。
而“第二阶段”的 Mount(以及 Unmount)操作,必须发生在 Pod 对应的宿主机上,所以它必须是 kubelet 组件的一部分。这个控制循环的名字,叫作:VolumeManagerReconciler,它运行起来之后,是一个独立于 kubelet 主循环的 Goroutine。
通过这样将 Volume 的处理同 kubelet 的主循环解耦,Kubernetes 就避免了这些耗时的远程挂载操作拖慢 kubelet 的主控制循环,进而导致 Pod 的创建效率大幅下降的问题。实际上,kubelet 的一个主要设计原则,就是它的主控制循环绝对不可以被 block。
PVC
PVC作为用户对存储资源的需求申请,主要包括存储空间请求、访问模式、PV选择条件和存储类别等信息的设置。下例声明的PVC具有如下属性:申请8GiB存储空间,访问模式 ReadWriteOnce,PV 选择条件为包含标签“release=stable”并且包含条件为“environment In [dev]”的标签,存储类别为“slow”(要求在系统中已存在名为slow的StorageClass):

PVC的关键配置参数说明如下。
◎ 资源请求(Resources):描述对存储资源的请求,目前仅支持request.storage的设置,即存储空间大小。
◎ 访问模式(Access Modes):PVC也可以设置访问模式,用于描述用户应用对存储资源的访问权限。其三种访问模式的设置与PV的设置相同。
◎ 存储卷模式(Volume Modes):PVC也可以设置存储卷模式,用于描述希望使用的PV存储卷模式,包括文件系统和块设备。
◎ PV选择条件(Selector):通过对Label Selector的设置,可使PVC对于系统中已存在的各种PV进行筛选。系统将根据标签选出合适的PV与该PVC进行绑定。
选择条件可以使用matchLabels和matchExpressions进行设置,如果两个字段都设置了,则Selector的逻辑将是两组条件同时满足才能完成匹配。
◎ 存储类别(Class):PVC 在定义时可以设定需要的后端存储的类别(通过storageClassName字段指定),以减少对后端存储特性的详细信息的依赖。只有设置了该Class的PV才能被系统选出,并与该PVC进行绑定。
PVC也可以不设置Class需求。如果storageClassName字段的值被设置为空(storageClassName=""),则表示该PVC不要求特定的Class,系统将只选择未设定Class的PV与之匹配和绑定。
PVC也可以完全不设置storageClassName字段,此时将根据系统是否启用了名为DefaultStorageClass的admission controller进行相应的操作。
◎ 未启用DefaultStorageClass:等效于PVC设置storageClassName的值为空(storageClassName=“”),即只能选择未设定Class的PV与之匹配和绑定。
◎ 启用DefaultStorageClass:要求集群管理员已定义默认的StorageClass。
如果在系统中不存在默认的StorageClass,则等效于不启用DefaultStorageClass的情况。如果存在默认的StorageClass,则系统将自动为PVC创建一个PV(使用默认StorageClass的后端存储),并将它们进行绑定。
集群管理员设置默认StorageClass的方法为,在StorageClass的定义中加上一个annotation“storageclass.kubernetes.io/isdefault-class= true”。
如果管理员将多个StorageClass都定义为default,则由于不唯一,系统将无法为PVC创建相应的PV。
注意,PVC和PV都受限于Namespace,PVC在选择PV时受到Namespace的限制,只有相同Namespace中的PV才可能与PVC绑定。Pod在引用PVC时同样受Namespace的限制,只有相同Namespace中的PVC才能挂载到Pod内。
当Selector和Class都进行了设置时,系统将选择两个条件同时满足的PV与之匹配另外,如果资源供应使用的是动态模式,即管理员没有预先定义PV,仅通过StorageClass交给系统自动完成PV的动态创建,那么PVC再设定Selector时,系统将无法为其供应任何存储资源。
在启用动态供应模式的情况下,一旦用户删除了PVC,与之绑定的PV也将根据其默认的回收策略“Delete”被删除。如果需要保留PV(用户数据),则在动态绑定成功后,用户需要将系统自动生成PV的回收策略从“Delete”改成“Retain”。
开发人员可以声明一个 1 GiB 大小的 PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs
spec:
accessModes:
- ReadWriteMany
storageClassName: manual
resources:
requests:
storage: 1Gi
而用户创建的 PVC 要真正被容器使用起来,就必须先和某个符合条件的 PV 进行绑定。这里要检查的条件,包括两部分:
第一个条件,当然是 PV 和 PVC 的 spec 字段。比如,PV 的存储(storage)大小,就必须满足 PVC 的要求。
而第二个条件,则是 PV 和 PVC 的 storageClassName 字段必须一样。
在成功地将 PVC 和 PV 进行绑定之后,Pod 就能够像使用 hostPath 等常规类型的 Volume 一样,在自己的 YAML 文件里声明使用这个 PVC 了,如下所示:
apiVersion: v1
kind: Pod
metadata:
labels:
role: web-frontend
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: nfs
mountPath: "/usr/share/nginx/html"
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs
PVC 和 PV 的设计,其实跟“面向对象”的思想完全一致。
PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;而这个持久化存储的实现部分则由 PV 负责完成。这样做的好处是,作为应用开发者,我们只需要跟 PVC 这个“接口”打交道,而不必关心具体的实现是 NFS 还是 Ceph。
PV和PVC的生命周期
我们可以将PV看作可用的存储资源,PVC则是对存储资源的需求,
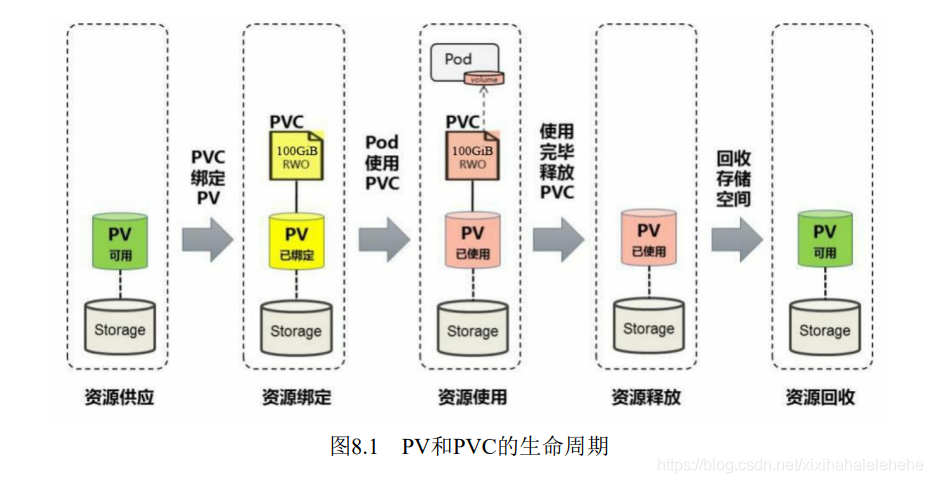
Kubernetes支持两种资源的供应模式:静态模式(Static)和动态模式(Dynamic)。资源供应的结果就是创建好的PV。
◎ 静态模式:集群管理员手工创建许多PV,在定义PV时需要将后端存储的特性进行设置。
◎ 动态模式:集群管理员无须手工创建PV,而是通过StorageClass的设置对后端存储进行描述,标记为某种类型。
此时要求PVC对存储的类型进行声明,系统将自动完成PV的创建及与PVC的绑定。PVC可以声明Class为"",说明该PVC禁止使用动态模式。
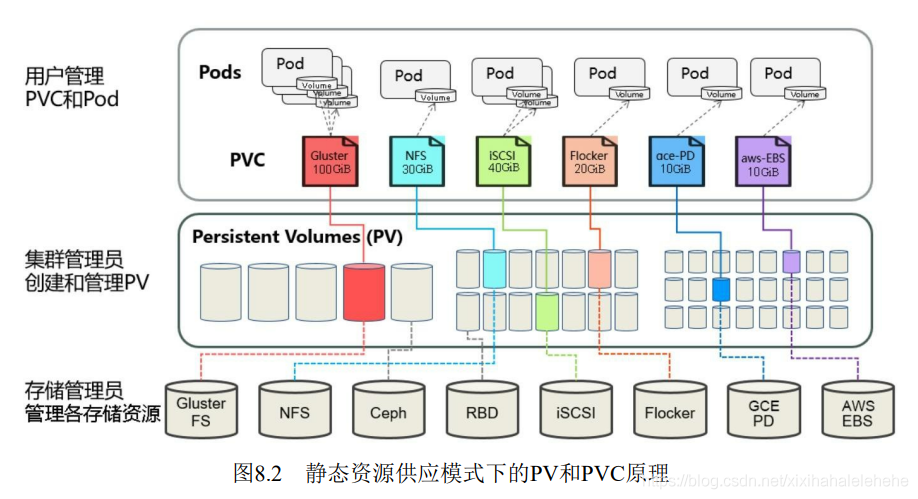
图8.3描述了在动态资源供应模式下,通过StorageClass和PVC完成资源动态绑定(系统自动生成PV),并供Pod使用的存储管理机制。
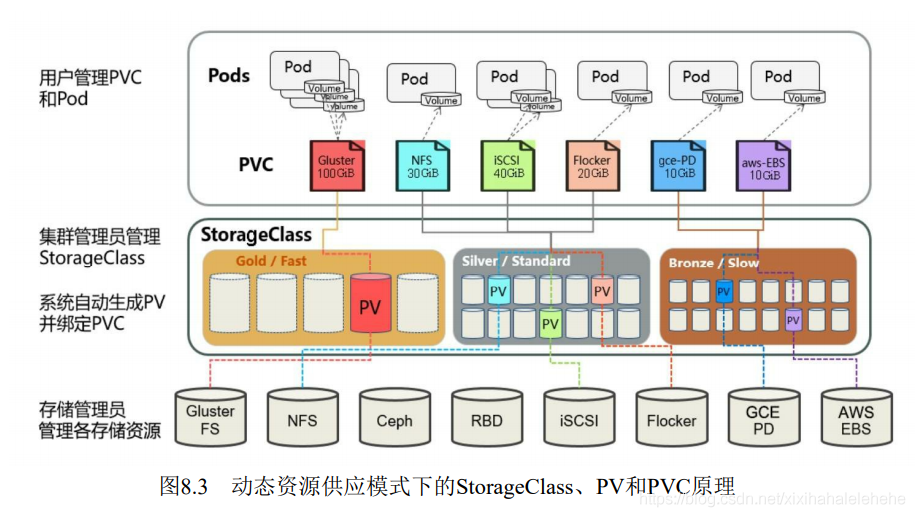
在 Kubernetes 中,实际上存在着一个专门处理持久化存储的控制器,叫作 Volume Controller。这个 Volume Controller 维护着多个控制循环,其中有一个循环,扮演的就是撮合 PV 和 PVC 的“红娘”的角色。它的名字叫作 PersistentVolumeController。PersistentVolumeController 会不断地查看当前每一个 PVC,是不是已经处于 Bound(已绑定)状态。如果不是,那它就会遍历所有的、可用的 PV,并尝试将其与这个“单身”的 PVC 进行绑定。这样,Kubernetes 就可以保证用户提交的每一个 PVC,只要有合适的 PV 出现,它就能够很快进入绑定状态,从而结束“单身”之旅。而所谓将一个 PV 与 PVC 进行“绑定”,其实就是将这个 PV 对象的名字,填在了 PVC 对象的 spec.volumeName 字段上。所以,接下来 Kubernetes 只要获取到这个 PVC 对象,就一定能够找到它所绑定的 PV。
StorageClass
在了解了 Kubernetes 的 Volume 处理机制之后,我再来为你介绍这个体系里最后一个重要概念:StorageClass。
我在前面介绍 PV 和 PVC 的时候,曾经提到过,PV 这个对象的创建,是由运维人员完成的。但是,在大规模的生产环境里,这其实是一个非常麻烦的工作。这是因为,一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV 而失败。在实际操作中,这几乎没办法靠人工做到。
所以,Kubernetes 为我们提供了一套可以自动创建 PV 的机制,即:Dynamic Provisioning。相比之下,前面人工管理 PV 的方式就叫作 Static Provisioning。Dynamic Provisioning 机制工作的核心,在于一个名叫 StorageClass 的 API 对象。
而 StorageClass 对象的作用,其实就是创建 PV 的模板。
具体地说,StorageClass 对象会定义如下两个部分内容:
第一,PV 的属性。比如,存储类型、Volume 的大小等等。
第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
有了这样两个信息之后,Kubernetes 就能够根据用户提交的 PVC,找到一个对应的 StorageClass 了。然后,Kubernetes 就会调用该 StorageClass 声明的存储插件,创建出需要的 PV。
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在 StorageClass 需要动态分配 PersistentVolume 时会使用到StorageClass作为对存储资源的抽象定义,对用户设置的PVC申请屏蔽后端存储的细节,一方面减少了用户对于存储资源细节的关注,另一方面减轻了管理员手工管理PV的工作,由系统自动完成PV的创建和绑定,实现了动态的资源供应。基于StorageClass的动态资源供应模式将逐步成为云平台的标准存储配置模式。
StorageClass的定义主要包括名称、后端存储的提供者(provisioner)和后端存储的相关参数配置。StorageClass一旦被创建出来,则将无法修改。如需更改,则只能删除原StorageClass的定义重建。
下例定义了一个名为standard的StorageClass,提供者为aws-ebs,其参数设置了一个type,值为gp2:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate
- 提供者(Provisioner)
描述存储资源的提供者,也可以看作后端存储驱动。目前Kubernetes支持的Provisioner都以“kubernetes.io/”为开头,用户也可以使用自定义的后端存储提供者。为了符合StorageClass的用法,自定义Provisioner需要符合存储卷的开发规范。
- 参数(Parameters)
后端存储资源提供者的参数设置,不同的Provisioner包括不同的参数设置。某些参数可以不显示设定,Provisioner将使用其默认值。接下来通过几种常见的Provisioner对StorageClass的定义进行详细说明。
- GCE
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
在这个 YAML 文件里,我们定义了一个名叫 block-service 的 StorageClass。这个 StorageClass 的 provisioner 字段的值是:kubernetes.io/gce-pd,这正是 Kubernetes 内置的 GCE PD 存储插件的名字。
而这个 StorageClass 的 parameters 字段,就是 PV 的参数。比如:上面例子里的 type=pd-ssd,指的是这个 PV 的类型是“SSD 格式的 GCE 远程磁盘”。
- ceph
如果你想使用我们之前部署在本地的 Kubernetes 集群以及 Rook 存储服务的话,你的 StorageClass 需要使用如下所示的 YAML 文件来定义:
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
#The value of "clusterNamespace" MUST be the same as the one in which your rook cluster exist
clusterNamespace: rook-ceph
在这个 YAML 文件中,我们定义的还是一个名叫 block-service 的 StorageClass,只不过它声明使的存储插件是由 Rook 项目。有了 StorageClass 的 YAML 文件之后,运维人员就可以在 Kubernetes 里创建这个 StorageClass 了:
$ kubectl create -f sc.yaml
这时候,作为应用开发者,我们只需要在 PVC 里指定要使用的 StorageClass 名字即可,如下所示:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: block-service
resources:
requests:
storage: 30Gi
可以看到,我们在这个 PVC 里添加了一个叫作 storageClassName 的字段,用于指定该 PVC 所要使用的 StorageClass 的名字是:block-service。
- AWS EBS存储卷
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "10"
fsType: ext4
type:io1,gp2,sc1,st1。详细信息参见 AWS 文档。默认值:gp2。
zone(弃用):AWS 区域。如果没有指定 zone 和 zones, 通常卷会在 Kubernetes集群节点所在的活动区域中轮询调度分配。 zone 和 zones 参数不能同时使用。
zones(弃用):以逗号分隔的 AWS 区域列表。 如果没有指定 zone 和 zones,通常卷会在 Kubernetes集群节点所在的 活动区域中轮询调度分配。zone和zones参数不能同时使用。
iopsPerGB:只适用于 io1 卷。每 GiB 每秒 I/O 操作。 AWS 卷插件将其与请求卷的大小相乘以计算 IOPS 的容量,并将其限制在 20000 IOPS(AWS 支持的最高值,请参阅 AWS 文档。 这里需要输入一个字符串,即 “10”,而不是 10。
fsType:受 Kubernetes 支持的文件类型。默认值:“ext4”。
encrypted:指定 EBS 卷是否应该被加密。合法值为 “true” 或者 “false”。 这里需要输入字符串,即 “true”,而非 true。
kmsKeyId:可选。加密卷时使用密钥的完整 Amazon 资源名称。 如果没有提供,但 encrypted 值为 true,AWS生成一个密钥。关于有效的 ARN 值,请参阅 AWS 文档。
- Glusterfs
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/glusterfs
parameters:
resturl: "http://127.0.0.1:8081"
clusterid: "630372ccdc720a92c681fb928f27b53f"
restauthenabled: "true"
restuser: "admin"
secretNamespace: "default"
secretName: "heketi-secret"
gidMin: "40000"
gidMax: "50000"
volumetype: "replicate:3"
resturl:制备 gluster 卷的需求的 Gluster REST 服务/Heketi 服务 url。 通用格式应该是 IPaddress:Port,这是 GlusterFS 动态制备器的必需参数。 如果 Heketi 服务在 OpenShift/kubernetes 中安装并暴露为可路由服务,则可以使用类似于http://heketi-storage-project.cloudapps.mystorage.com 的格式,其中 fqdn是可解析的 heketi 服务网址。
restauthenabled:Gluster REST 服务身份验证布尔值,用于启用对 REST 服务器的身份验证。 如果此值为’true’,则必须填写 restuser 和 restuserkey 或 secretNamespace + secretName。此选项已弃用,当在指定 restuser、restuserkey、secretName 或 secretNamespace时,身份验证被启用。
restuser:在 Gluster 可信池中有权创建卷的 Gluster REST服务/Heketi 用户。
restuserkey:Gluster REST 服务/Heketi 用户的密码将被用于对 REST 服务器进行身份验证。此参数已弃用,取而代之的是 secretNamespace + secretName。
secretNamespace,secretName:Secret 实例的标识,包含与 Gluster REST服务交互时使用的用户密码。 这些参数是可选的,secretNamespace 和 secretName 都省略时使用空密码。 所提供的Secret 必须将类型设置为 “kubernetes.io/glusterfs”,例如以这种方式创建:
kubectl create secret generic heketi-secret \
--type="kubernetes.io/glusterfs" --from-literal=key='opensesame' \
--namespace=default
设置默认的StorageClass
a. 修改kube-apiserver参数
要在系统中设置一个默认的StorageClass,则首先需要启用名为
DefaultStorageClass的admission controller,即在kube-apiserver的命令行
参数–admission-control中增加:
--admission-control=...,DefaultStorageClass
b. 标记默认 StorageClass 非默认
$ kubectl get storageclass
NAME PROVISIONER AGE
standard (default) kubernetes.io/gce-pd 1d
gold kubernetes.io/gce-pd 1d
kubectl patch storageclass standard -p '{
"metadata": {
"annotations":{
"storageclass.kubernetes.io/is-default-class":"false"}}}'
c. 标记一个 StorageClass 为默认
在StorageClass的定义中设置一个annotation:

或者
kubectl patch storageclass <your-class-name> -p '{
"metadata": {
"annotations":{
"storageclass.kubernetes.io/is-default-class":"true"}}}'
有了 Dynamic Provisioning 机制,运维人员只需要在 Kubernetes 集群里创建出数量有限的 StorageClass 对象就可以了。这就好比,运维人员在 Kubernetes 集群里创建出了各种各样的 PV 模板。这时候,当开发人员提交了包含 StorageClass 字段的 PVC 之后,Kubernetes 就会根据这个 StorageClass 创建出对应的 PV。
需要注意的是,StorageClass 并不是专门为了 Dynamic Provisioning 而设计的。
比如,在本篇一开始的例子里,我在 PV 和 PVC 里都声明了 storageClassName=manual。而我的集群里,实际上并没有一个名叫 manual 的 StorageClass 对象。这完全没有问题,这个时候 Kubernetes 进行的是 Static Provisioning,但在做绑定决策的时候,它依然会考虑 PV 和 PVC 的 StorageClass 定义。
而这么做的好处也很明显:这个 PVC 和 PV 的绑定关系,就完全在我自己的掌控之中。
这里,你可能会有疑问,我在之前讲解 StatefulSet 存储状态的例子时,好像并没有声明 StorageClass 啊?
实际上,如果你的集群已经开启了名叫 DefaultStorageClass 的 Admission Plugin,它就会为 PVC 和 PV 自动添加一个默认的 StorageClass;否则,PVC 的 storageClassName 的值就是“”,这也意味着它只能够跟 storageClassName 也是“”的 PV 进行绑定。
StorageClass 到底是干什么用的。这些概念之间的关系,可以用如下所示的一幅示意图描述:
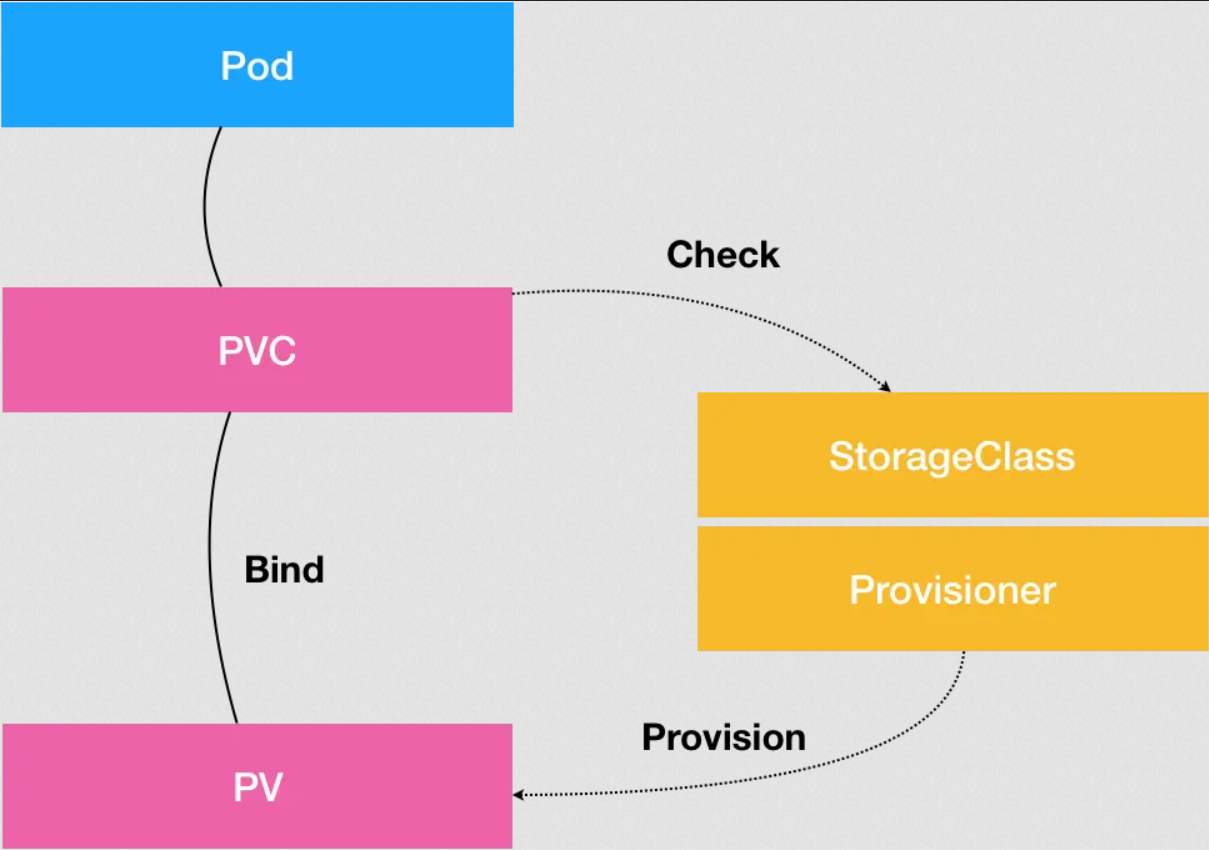
从图中我们可以看到,在这个体系中:
PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
当然,StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果你的存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动为你创建 PV 了。
Local Persistent Volume
在持久化存储领域,用户呼声最高的定制化需求,莫过于支持“本地”持久化存储了。也就是说,用户希望 Kubernetes 能够直接使用宿主机上的本地磁盘目录,而不依赖于远程存储服务,来提供“持久化”的容器 Volume。这样做的好处很明显,由于这个 Volume 直接使用的是本地磁盘,尤其是 SSD 盘,它的读写性能相比于大多数远程存储来说,要好得多。这个需求对本地物理服务器部署的私有 Kubernetes 集群来说,非常常见。
所以,Kubernetes 在 v1.10 之后,就逐渐依靠 PV、PVC 体系实现了这个特性。这个特性的名字叫作:Local Persistent Volume。
不过,首先需要明确的是,Local Persistent Volume 并不适用于所有应用。事实上,它的适用范围非常固定,比如:高优先级的系统应用,需要在多个不同节点上存储数据,并且对 I/O 较为敏感。典型的应用包括:分布式数据存储比如 MongoDB、Cassandra 等,分布式文件系统比如 GlusterFS、Ceph 等,以及需要在本地磁盘上进行大量数据缓存的分布式应用。
其次,相比于正常的 PV,一旦这些节点宕机且不能恢复时,Local Persistent Volume 的数据就可能丢失。这就要求使用 Local Persistent Volume 的应用必须具备数据备份和恢复的能力,允许你把这些数据定时备份在其他位置。
不难想象,Local Persistent Volume 的设计,主要面临两个难点。
第一个难点在于:如何把本地磁盘抽象成 PV。
可能你会说,Local Persistent Volume,不就等同于 hostPath 加 NodeAffinity 吗?
比如,一个 Pod 可以声明使用类型为 Local 的 PV,而这个 PV 其实就是一个 hostPath 类型的 Volume。如果这个 hostPath 对应的目录,已经在节点 A 上被事先创建好了。那么,我只需要再给这个 Pod 加上一个 nodeAffinity=nodeA,不就可以使用这个 Volume 了吗?
事实上,你绝不应该把一个宿主机上的目录当作 PV 使用。这是因为,这种本地目录的存储行为完全不可控,它所在的磁盘随时都可能被应用写满,甚至造成整个宿主机宕机。而且,不同的本地目录之间也缺乏哪怕最基础的 I/O 隔离机制。
所以,一个 Local Persistent Volume 对应的存储介质,一定是一块额外挂载在宿主机的磁盘或者块设备(“额外”的意思是,它不应该是宿主机根目录所使用的主硬盘)。这个原则,我们可以称为“一个 PV 一块盘”。
(原来我一直都做错了啊)
第二个难点在于:调度器如何保证 Pod 始终能被正确地调度到它所请求的 Local Persistent Volume 所在的节点上呢?
造成这个问题的原因在于,对于常规的 PV 来说,Kubernetes 都是先调度 Pod 到某个节点上,然后,再通过“两阶段处理”来“持久化”这台机器上的 Volume 目录,进而完成 Volume 目录与容器的绑定挂载。
可是,对于 Local PV 来说,节点上可供使用的磁盘(或者块设备),必须是运维人员提前准备好的。它们在不同节点上的挂载情况可以完全不同,甚至有的节点可以没这种磁盘。
所以,这时候,调度器就必须能够知道所有节点与 Local Persistent Volume 对应的磁盘的关联关系,然后根据这个信息来调度 Pod。
这个原则,我们可以称为“在调度的时候考虑 Volume 分布”。在 Kubernetes 的调度器里,有一个叫作 VolumeBindingChecker 的过滤条件专门负责这个事情。在 Kubernetes v1.11 中,这个过滤条件已经默认开启了。
基于上述讲述,在开始使用 Local Persistent Volume 之前,你首先需要在集群里配置好磁盘或者块设备。在公有云上,这个操作等同于给虚拟机额外挂载一个磁盘,比如 GCE 的 Local SSD 类型的磁盘就是一个典型例子。而在我们部署的私有环境中,你有两种办法来完成这个步骤。
第一种,当然就是给你的宿主机挂载并格式化一个可用的本地磁盘,这也是最常规的操作;
第二种,对于实验环境,你其实可以在宿主机上挂载几个 RAM Disk(内存盘)来模拟本地磁盘。
接下来,我会使用第二种方法,在我们之前部署的 Kubernetes 集群上进行实践。首先,在名叫 node-1 的宿主机上创建一个挂载点,比如 /mnt/disks;然后,用几个 RAM Disk 来模拟本地磁盘,如下所示:
# 在node-1上执行
$ mkdir /mnt/disks
$ for vol in vol1 vol2 vol3; do
mkdir /mnt/disks/$vol
mount -t tmpfs $vol /mnt/disks/$vol
done
需要注意的是,如果你希望其他节点也能支持 Local Persistent Volume 的话,那就需要为它们也执行上述操作,并且确保这些磁盘的名字(vol1、vol2 等)都不重复。
接下来,我们就可以为这些本地磁盘定义对应的 PV 了,如下所示:
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/vol1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node-1
可以看到,这个 PV 的定义里:local 字段,指定了它是一个 Local Persistent Volume;而 path 字段,指定的正是这个 PV 对应的本地磁盘的路径,即:/mnt/disks/vol1。
当然了,这也就意味着如果 Pod 要想使用这个 PV,那它就必须运行在 node-1 上。所以,在这个 PV 的定义里,需要有一个 nodeAffinity 字段指定 node-1 这个节点的名字。这样,调度器在调度 Pod 的时候,就能够知道一个 PV 与节点的对应关系,从而做出正确的选择。这正是 Kubernetes 实现“在调度的时候就考虑 Volume 分布”的主要方法。
接下来,我们就可以使用 kubect create 来创建这个 PV,如下所示:
$ kubectl create -f local-pv.yaml
persistentvolume/example-pv created
而正如前文所建议的那样,使用 PV 和 PVC 的最佳实践,要创建一个 StorageClass 来描述这个 PV,如下所示:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
这个 StorageClass 的名字,叫作 local-storage。需要注意的是,在它的 provisioner 字段,我们指定的是 no-provisioner。这是因为 Local Persistent Volume 目前尚不支持 Dynamic Provisioning,所以它没办法在用户创建 PVC 的时候,就自动创建出对应的 PV。也就是说,我们前面创建 PV 的操作,是不可以省略的。
与此同时,这个 StorageClass 还定义了一个 volumeBindingMode=WaitForFirstConsumer 的属性。它是 Local Persistent Volume 里一个非常重要的特性,即:延迟绑定。
我们知道,当你提交了 PV 和 PVC 的 YAML 文件之后,Kubernetes 就会根据它们俩的属性,以及它们指定的 StorageClass 来进行绑定。只有绑定成功后,Pod 才能通过声明这个 PVC 来使用对应的 PV。
可是,如果你使用的是 Local Persistent Volume 的话,就会发现,这个流程根本行不通。比如,现在你有一个 Pod,它声明使用的 PVC 叫作 pvc-1。并且,我们规定,这个 Pod 只能运行在 node-2 上。
而在 Kubernetes 集群中,有两个属性(比如:大小、读写权限)相同的 Local 类型的 PV。其中,第一个 PV 的名字叫作 pv-1,它对应的磁盘所在的节点是 node-1。而第二个 PV 的名字叫作 pv-2,它对应的磁盘所在的节点是 node-2。
假设现在,Kubernetes 的 Volume 控制循环里,首先检查到了 pvc-1 和 pv-1 的属性是匹配的,于是就将它们俩绑定在一起。然后,你用 kubectl create 创建了这个 Pod。这时候,问题就出现了。
调度器看到,这个 Pod 所声明的 pvc-1 已经绑定了 pv-1,而 pv-1 所在的节点是 node-1,根据“调度器必须在调度的时候考虑 Volume 分布”的原则,这个 Pod 自然会被调度到 node-1 上。
可是,我们前面已经规定过,这个 Pod 根本不允许运行在 node-1 上。所以。最后的结果就是,这个 Pod 的调度必然会失败。这就是为什么,在使用 Local Persistent Volume 的时候,我们必须想办法推迟这个“绑定”操作。
那么,具体推迟到什么时候呢?答案是:推迟到调度的时候。
所以说,StorageClass 里的 volumeBindingMode=WaitForFirstConsumer 的含义,就是告诉 Kubernetes 里的 Volume 控制循环(“红娘”):虽然你已经发现这个 StorageClass 关联的 PVC 与 PV 可以绑定在一起,但请不要现在就执行绑定操作(即:设置 PVC 的 VolumeName 字段)。
而要等到第一个声明使用该 PVC 的 Pod 出现在调度器之后,调度器再综合考虑所有的调度规则,当然也包括每个 PV 所在的节点位置,来统一决定,这个 Pod 声明的 PVC,到底应该跟哪个 PV 进行绑定。这样,在上面的例子里,由于这个 Pod 不允许运行在 pv-1 所在的节点 node-1,所以它的 PVC 最后会跟 pv-2 绑定,并且 Pod 也会被调度到 node-2 上。
所以,通过这个延迟绑定机制,原本实时发生的 PVC 和 PV 的绑定过程,就被延迟到了 Pod 第一次调度的时候在调度器中进行,从而保证了这个绑定结果不会影响 Pod 的正常调度。
当然,在具体实现中,调度器实际上维护了一个与 Volume Controller 类似的控制循环,专门负责为那些声明了“延迟绑定”的 PV 和 PVC 进行绑定工作。通过这样的设计,这个额外的绑定操作,并不会拖慢调度器的性能。而当一个 Pod 的 PVC 尚未完成绑定时,调度器也不会等待,而是会直接把这个 Pod 重新放回到待调度队列,等到下一个调度周期再做处理。在明白了这个机制之后,我们就可以创建 StorageClass 了,如下所示:
$ kubectl create -f local-sc.yaml
storageclass.storage.k8s.io/local-storage created
接下来,我们只需要定义一个非常普通的 PVC,就可以让 Pod 使用到上面定义好的 Local Persistent Volume 了,如下所示:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage
可以看到,这个 PVC 没有任何特别的地方。唯一需要注意的是,它声明的 storageClassName 是 local-storage。所以,将来 Kubernetes 的 Volume Controller 看到这个 PVC 的时候,不会为它进行绑定操作。现在,我们来创建这个 PVC:
$ kubectl create -f local-pvc.yaml
persistentvolumeclaim/example-local-claim created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-local-claim Pending local-storage 7s
可以看到,尽管这个时候,Kubernetes 里已经存在了一个可以与 PVC 匹配的 PV,但这个 PVC 依然处于 Pending 状态,也就是等待绑定的状态。然后,我们编写一个 Pod 来声明使用这个 PVC,如下所示:
kind: Pod
apiVersion: v1
metadata:
name: example-pv-pod
spec:
volumes:
- name: example-pv-storage
persistentVolumeClaim:
claimName: example-local-claim
containers:
- name: example-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: example-pv-storage
这个 Pod 没有任何特别的地方,你只需要注意,它的 volumes 字段声明要使用前面定义的、名叫 example-local-claim 的 PVC 即可。而我们一旦使用 kubectl create 创建这个 Pod,就会发现,我们前面定义的 PVC,会立刻变成 Bound 状态,与前面定义的 PV 绑定在了一起,如下所示:
$ kubectl create -f local-pod.yaml
pod/example-pv-pod created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-local-claim Bound example-pv 5Gi RWO local-storage 6h
也就是说,在我们创建的 Pod 进入调度器之后,“绑定”操作才开始进行。这时候,我们可以尝试在这个 Pod 的 Volume 目录里,创建一个测试文件,比如:
$ kubectl exec -it example-pv-pod -- /bin/sh
# cd /usr/share/nginx/html
# touch test.txt
然后,登录到 node-1 这台机器上,查看一下它的 /mnt/disks/vol1 目录下的内容,你就可以看到刚刚创建的这个文件:
# 在node-1上
$ ls /mnt/disks/vol1
test.txt
而如果你重新创建这个 Pod 的话,就会发现,我们之前创建的测试文件,依然被保存在这个持久化 Volume 当中:
$ kubectl delete -f local-pod.yaml
$ kubectl create -f local-pod.yaml
$ kubectl exec -it example-pv-pod -- /bin/sh
# ls /usr/share/nginx/html
# touch test.txt
这就说明,像 Kubernetes 这样构建出来的、基于本地存储的 Volume,完全可以提供容器持久化存储的功能。所以,像 StatefulSet 这样的有状态编排工具,也完全可以通过声明 Local 类型的 PV 和 PVC,来管理应用的存储状态。
需要注意的是,我们上面手动创建 PV 的方式,即 Static 的 PV 管理方式,在删除 PV 时需要按如下流程执行操作:
删除使用这个 PV 的 Pod;
从宿主机移除本地磁盘(比如,umount 它);
删除 PVC;
删除 PV。
如果不按照这个流程的话,这个 PV 的删除就会失败。当然,由于上面这些创建 PV 和删除 PV 的操作比较繁琐,Kubernetes 其实提供了一个 Static Provisioner 来帮助你管理这些 PV。
比如,我们现在的所有磁盘,都挂载在宿主机的 /mnt/disks 目录下。
那么,当 Static Provisioner 启动后,它就会通过 DaemonSet,自动检查每个宿主机的 /mnt/disks 目录。然后,调用 Kubernetes API,为这些目录下面的每一个挂载,创建一个对应的 PV 对象出来。这些自动创建的 PV,如下所示:
$ kubectl get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
local-pv-ce05be60 1024220Ki RWO Delete Available local-storage 26s
$ kubectl describe pv local-pv-ce05be60
Name: local-pv-ce05be60
...
StorageClass: local-storage
Status: Available
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1024220Ki
NodeAffinity:
Required Terms:
Term 0: kubernetes.io/hostname in [node-1]
Message:
Source:
Type: LocalVolume (a persistent volume backed by local storage on a node)
Path: /mnt/disks/vol1
这个 PV 里的各种定义,比如 StorageClass 的名字、本地磁盘挂载点的位置,都可以通过 provisioner 的配置文件指定。当然,provisioner 也会负责前面提到的 PV 的删除工作。
而这个 provisioner 本身,其实也是一个我们前面提到过的External Provisioner,它的部署方法,在对应的文档里有详细描述。
可以看到,正是通过 PV 和 PVC,以及 StorageClass 这套存储体系,这个后来新添加的持久化存储方案,对 Kubernetes 已有用户的影响,几乎可以忽略不计。作为用户,你的 Pod 的 YAML 和 PVC 的 YAML,并没有任何特殊的改变,这个特性所有的实现只会影响到 PV 的处理,也就是由运维人员负责的那部分工作。而这,正是这套存储体系带来的“解耦”的好处。其实,Kubernetes 很多看起来比较“繁琐”的设计(比如“声明式 API”,以及我今天讲解的“PV、PVC 体系”)的主要目的,都是希望为开发者提供更多的“可扩展性”,给使用者带来更多的“稳定性”和“安全感”。这两个能力的高低,是衡量开源基础设施项目水平的重要标准。