线上某核心mongodb集群数据量不大,单表数据量十亿级,但是该集群比较核心,影响公司收入流水。本文通过分享本次踩坑来分享整个故障经过,该故障为一次经典的mongodb分片sharding集群踩坑故障,包括变更通知不到位、部署架构不到位、变更考虑不仔细等。
关于作者
前滴滴出行专家工程师,现任OPPO文档数据库mongodb负责人,负责数万亿级数据量文档数据库mongodb内核研发、性能优化及运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。后续持续分享《MongoDB内核源码设计、性能优化、最佳运维实践》,Github账号地址:https://github.com/y123456yz
序言
本文是oschina专栏《mongodb 源码实现、调优、最佳实践系列》的第20篇文章,其他文章可以参考如下链接:
Qcon-万亿级数据库 MongoDB 集群性能数十倍提升及机房多活容灾实践
Qcon 现代数据架构 -《万亿级数据库 MongoDB 集群性能数十倍提升优化实践》核心 17 问详细解答
百万级高并发 mongodb 集群性能数十倍提升优化实践 (上篇)
百万级高并发 mongodb 集群性能数十倍提升优化实践 (下篇)
Mongodb特定场景性能数十倍提升优化实践(记一次mongodb核心集群雪崩故障)
盘点 2020 | 我要为分布式数据库 mongodb 在国内影响力提升及推广做点事

话题讨论 | mongodb 拥有十大核心优势,为何国内知名度远不如 mysql 高?
mongodb 详细表级操作及详细时延统计实现原理 (快速定位表级时延抖动)
[图、文、码配合分析]-Mongodb write 写 (增、删、改) 模块设计与实现
Mongodb集群搭建一篇就够了-复制集模式、分片模式、带认证、不带认证等(带详细步骤说明)
300条数据变更引发的血案-记某十亿级核心mongodb集群部分请求不可用故障踩坑记
- 问题背景
某核心mongodb历史集群(入职前就有的一个集群),在对现在所有mongodb集群进行风险梳理过程中,发现该集群存在一些潜在的集群抖动风险,该集群架构及流量时延曲线如下:


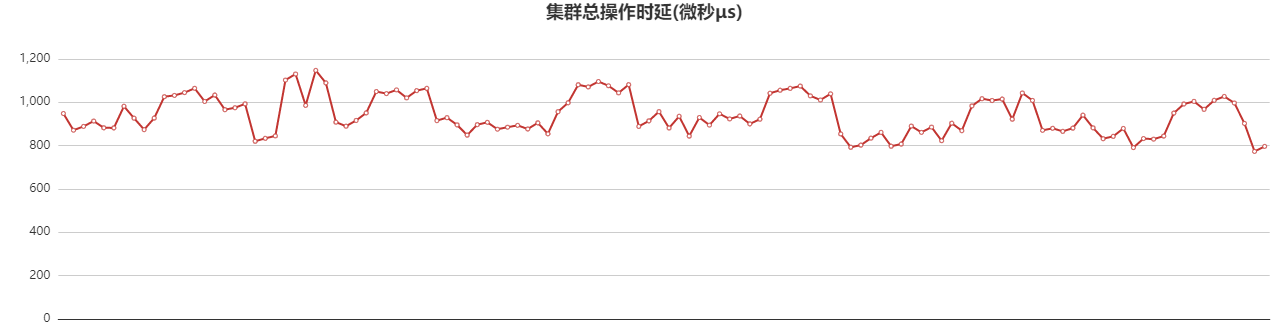
如上图所示,该分片集群由3个分片组成,集群读写流量很低,峰值QPS约4-6W/s,平均时延1ms,每个分片采用mongodb复制集架构实现高可用。通过巡检发现该集群存在如下几个问题:
- 该集群只包含两个用户库,userbucket库和feeds_content库,两个库中只有feeds_xxxxxxx.collection1启用了分片功能;第一个userbucket库存储集群路由信息,第二个feeds_xxxxxxx库存储约十亿数据信息;
- 由于该集群主要是读多写少集群,读流量都是读取feeds_xxxxxxx库中的数据,并且客户端做了读写分离,所以几乎大部分读流量都在分片1。分片2和分片3只有少量数据。
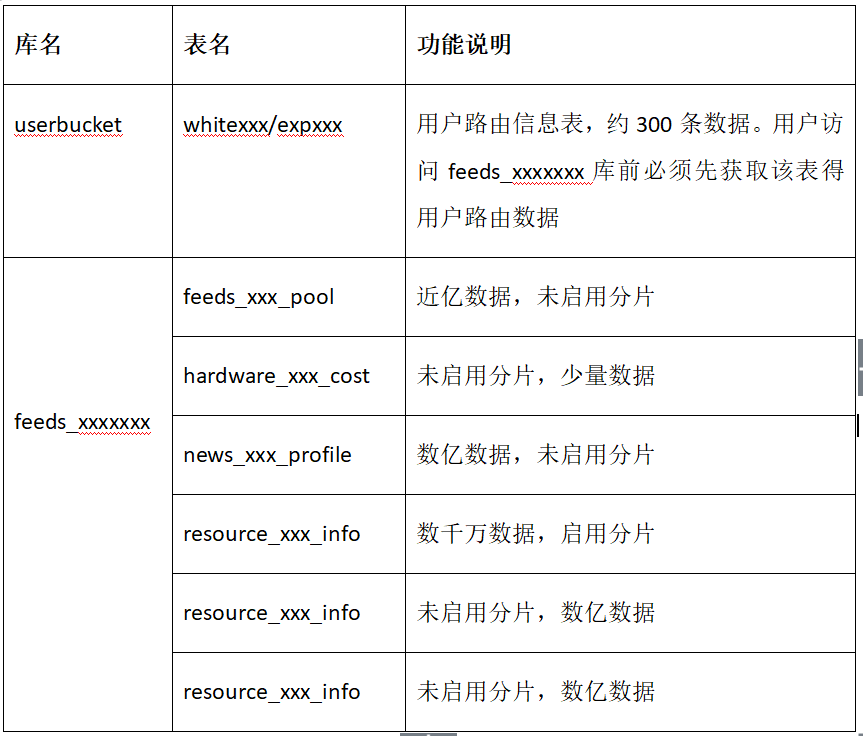
库表信息如下表所示:
上面的描述可以总结为下图:
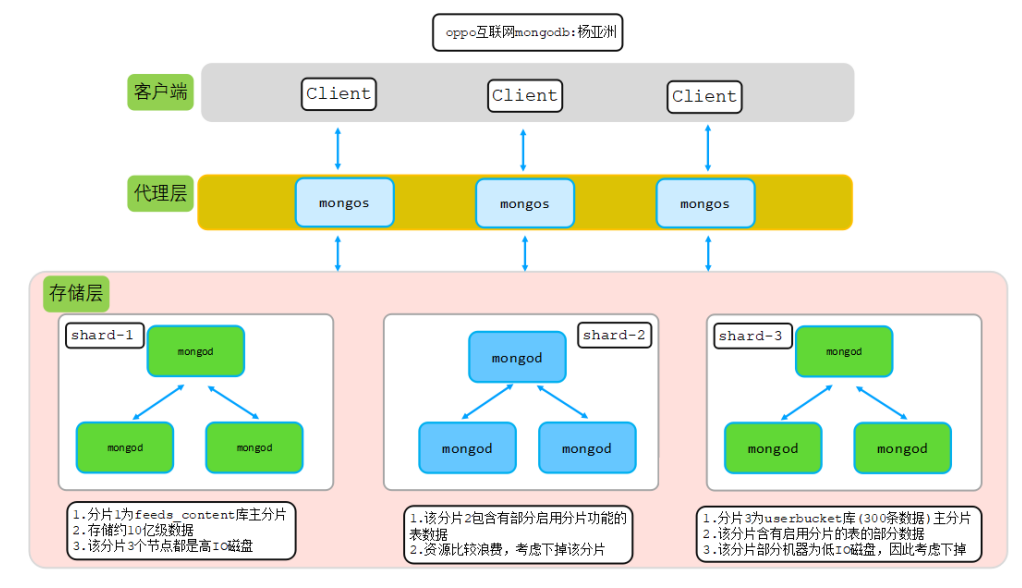
从上图可以看出,分片2和分片3几乎没起到任何作用;由于分片3有两个节点为低IO的sata盘,可能影响userbucket库的读写,因此考虑直接removeShard从集群中剔除分片3和分片2。
2. 操作过程
由于分片3为低IO服务器,有潜在抖动集群抖动分享;同时分片2和分片3几乎都是浪费的分片,因此打散直接通过如下removeshad命令删除分片3和分片2信息,腾出无用服务器资源,如下图所示:
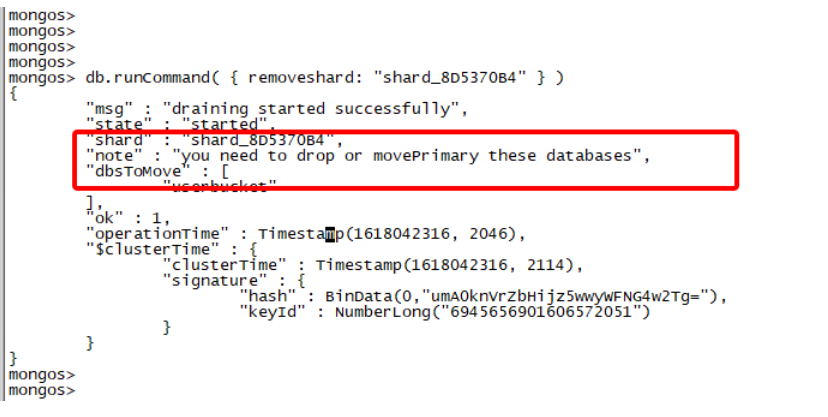
- 步骤1:登陆任一一个代理,假设是代理mongos1。
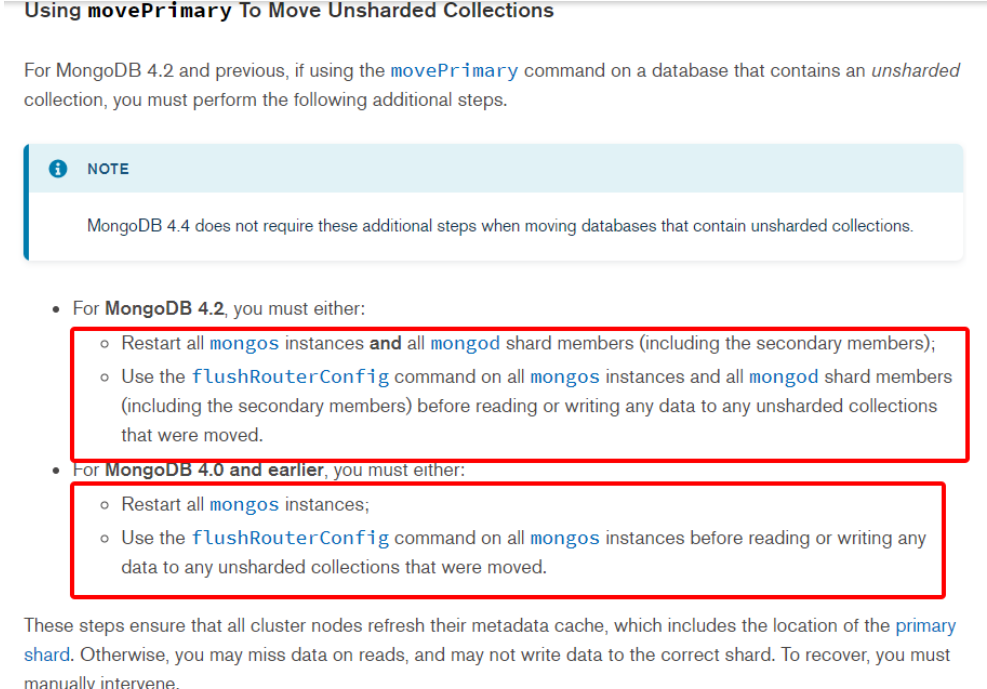
- 步骤2:由于分片3(也就是shard_8D5370B4分片)为userbucket库的主分片,因此报错了,提示"you need to drop or movePrimary these databases",意思是我们需要提前把该库的主分片信息迁移到其他分片。
- 步骤3:通过movePrimary命令把userbucket库的主分片从分片3迁移到分片1。
- 登陆监控列表中的其他两个代理mongos2、mongos3,通过db.adminCommand({"flushRouterConfig":1}) 强制刷新路由信息。
注意事项:由于movePrimary过程,其他代理不会感知到该库的主分片变化,因此需要强制刷新路由信息或者重启其他节点的mongos,参考如下:
3. 用户反馈大部分请求业务请求不可用
对含有300条数据的userbucket库变更后,当我还在若无其事的处理其他集群性能调优的时候,用户突然很急的电话我反馈该核心集群整个访问不可用(注意:是整个10亿数据的集群不可用)。
收到电话后很突然,和业务人员详细对接后可以基本上确定是因为这300条数据变更引起。业务获取这300条数据的时候,部分请求获取成功,部分请求获取失败,说明肯定和movePrimary有关系。
于是,除了对监控列表中的所有代理做flushRouterConfig强制路由刷新外,还重启了所有的代理,但是业务反馈,还是有部分请求获取不到数据。比较棘手,我自己通过所有的mongos代理查看userbucket库下面的300条数据,完全可以获取到数据。
于是怀疑是不是还有未刷新路由的mongos代理,于是登陆任一mongos代理获取config.mongos表,查看结果如下:

上面的config.mongos表记录了该集群所有的代理信息,同时记录了这些代理和集群最后一次ping通信的详细时间信息。很明显,该表中记录的代理原不止集群监控列表中的代理个数,比监控列表中的个数要多。
最终,把config.mongos表中罗列的当前在线的所有代理强制通过flushRouterConfig刷新路由后,业务恢复。
4. 问题总结
通过前面的分析可以得出,由于早期集群监控中漏掉了部分代理,造成这部分代理对应的userbucket路由信息是movePrimary前的路由信息,也就是指向了错误的分片,因此出现了路由不到数据的情况,如下图所示:
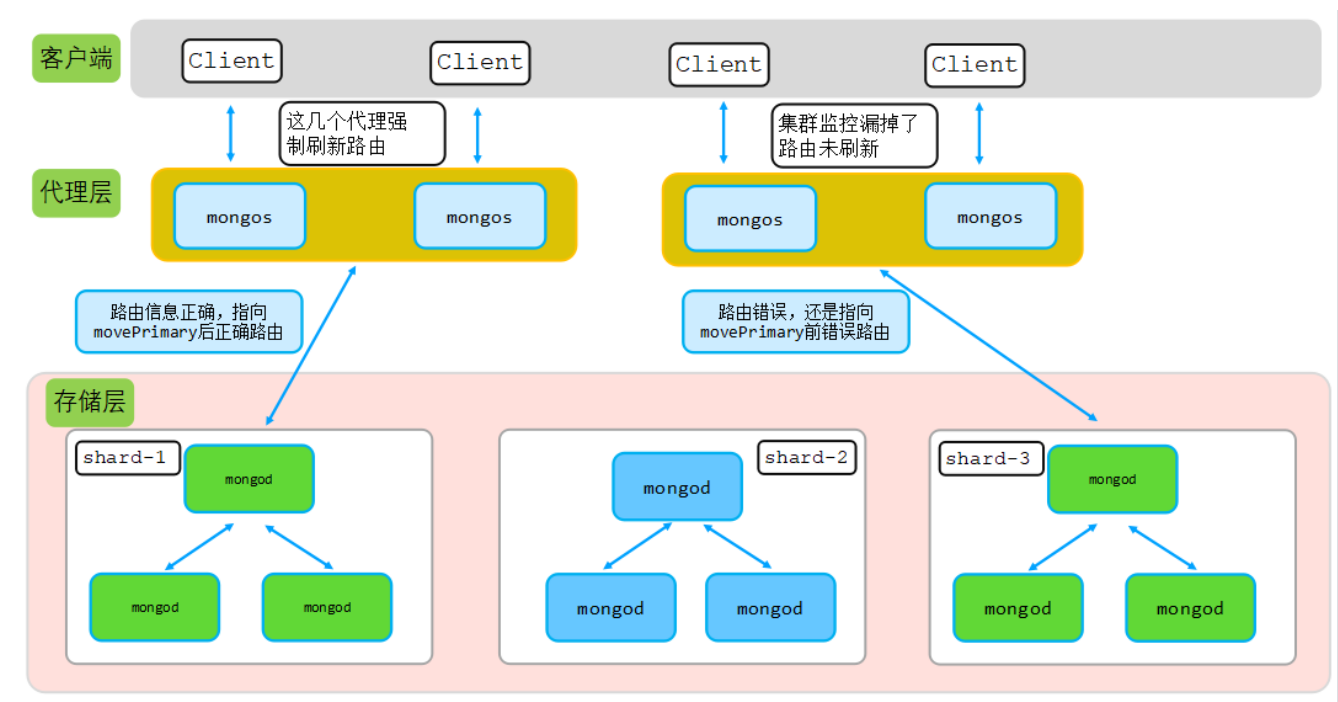
- 为何用户userbucket库对应表中数据有的成功有的失败?
因为部分代理在moveprimary后,没有强制刷新该表路由信息,造成部分代理路由获取数据的时候路由错误。
- 为何该300条数据部分路由信息错误会造成整个10亿集群部分访问不可用?
和业务实现逻辑有关系,因为业务在获取这10亿条数据前首先需要获取业务的路由信息,刚好业务路由信息存在了userbucket库对应表中,业务在获取数据前必须要获取到业务的路由信息数据,如果userbucket数据获取不到,用户就无法确定指向feeds_xxxxxxx数据。
- 为何会遗漏部分代理重启或者强制路由刷新?
历史原因,造成部分代理业务代码有配置,但是服务端集群监控元数据遗漏了,也就是服务端集群监控漏掉了部分代理,这部分代理没有监控起来。也有可能是mongos代理扩容,但是集群监控列表中没有加入元数据。
- movePrimary操作最安全的操作方法?
官方建议movePrimary操作成功后需要强制路由刷新或者重启mongos,但是movePrimary操作成功和mongos重启这个过程中有个中间状态,如果中间状态业务读或者些该迁移的库下面的表,还是可能路由错误。因此,最佳安全的moveprimary可以通过如下两个方法操作:
法一:shutdown所有代理,只留下一个代理,等该代理moveprimary成功后在重启其他mongos代理。切记别遗漏代理,出现本文踩坑类似情况,提前检查config.mongos表。
法二:对主分片在该需要removeShard的分片的库中的所有表启用分片功能,启用分片功能后会有chunk信息,mongodb会自动迁移该分片的chunk到其他分片,整个过程可以保证路由信息一致。