单层感知器
1、单层感知器介绍
受到生物神经网络的启发,计算机学家 Frank Rosenblatt 在 20 世纪 60 年代提出了一种 模拟生物神经网络的的人工神经网络结构,称为感知器(Perceptron)。单层感知器 结构图如下。

图中x1,x2,x3为输入信号,类似于生物神经网络中的树突
w1,w2,w3分别为x1,x2,x3的权值,它可以调节输入信号的值的大小,让输入信号变大 (w>0),不变(w=0)或者减小(w<0)。可以理解为生物神经网络中的信号作用,信号经过树突 传递到细胞核的过程中信号会发生变化。
公式 ∑ i = 1 W i X i + b \sum_{i=1}{W_iX_i} +b ∑i=1WiXi+b表示细胞的输入信号在细胞核的位置进行汇总 ∑ i = 1 W i X i \sum_{i=1}{W_iX_i} ∑i=1WiXi,然后再加上该细 胞本身自带的信号 b。b 一般称为偏置值(Bias),相当于是神经元内部自带的信号。
f(x)称为激活函数,可以理解为信号在轴突上进行的线性或非线性变化。在单层感知器中 最开始使用的激活函数是 sign(x)激活函数。该函数的特点是当 x>0 时,输出值为 1;当 x= 0 时,输出值为 0,;当 x<0 时,输出值为-1。sign(x)函数图像如图所示(图潘来源于百度百科)

y 就是 ∑ i = 1 W i X i + b \sum_{i=1}{W_iX_i} +b ∑i=1WiXi+b,为单层感知器的输出结果。
2、单层感知器计算示例
假如有一个单层感知器有 3 个输入x1,x2,x3,同时已知b=-0.6,w1=w2=w3=0.5,那 么根据单层感知器的计算公式 f ( ∑ i = 1 W i X i + b ) f(\sum_{i=1}{W_iX_i} +b) f(∑i=1WiXi+b)我们就可以得到 计算结果。
| x1 | x2 | x3 | Y |
|---|---|---|---|
| 0 | 0 | 0 | -1 |
| 0 | 0 | 1 | -1 |
| 0 | 1 | 0 | -1 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | -1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
x 1 = 0 , x 2 = 0 , x 3 = 0 : s i g n ( 0.5 × 0 + 0.5 × 0 + 0.5 × 0 − 0.6 ) = − 1 x 1 = 0 , x 2 = 0 , x 3 = 1 : s i g n ( 0.5 × 0 + 0.5 × 0 + 0.5 × 1 − 0.6 ) = − 1 x 1 = 0 , x 2 = 1 , x 3 = 0 : s i g n ( 0.5 × 0 + 0.5 × 1 + 0.5 × 0 − 0.6 ) = − 1 x 1 = 0 , x 2 = 1 , x 3 = 1 : s i g n ( 0.5 × 0 + 0.5 × 1 + 0.5 × 1 − 0.6 ) = 1 x 1 = 1 , x 2 = 0 , x 3 = 0 : s i g n ( 0.5 × 1 + 0.5 × 0 + 0.5 × 0 − 0.6 ) = − 1 x 1 = 1 , x 2 = 0 , x 3 = 1 : s i g n ( 0.5 × 1 + 0.5 × 0 + 0.5 × 1 − 0.6 ) = 1 x 1 = 1 , x 2 = 1 , x 3 = 0 : s i g n ( 0.5 × 1 + 0.5 × 1 + 0.5 × 0 − 0.6 ) = 1 x 1 = 1 , x 2 = 1 , x 3 = 1 : s i g n ( 0.5 × 1 + 0.5 × 1 + 0.5 × 1 − 0.6 ) = 1 x1=0,x2=0,x3=0:sign(0.5\times 0+0.5\times 0+0.5\times 0 -0.6)=-1\\ x1=0,x2=0,x3=1:sign(0.5\times 0+0.5\times 0+0.5\times 1 -0.6)=-1\\ x1=0,x2=1,x3=0:sign(0.5\times 0+0.5\times 1+0.5\times 0 -0.6)=-1\\ x1=0,x2=1,x3=1:sign(0.5\times 0+0.5\times 1+0.5\times 1 -0.6)=1\\ x1=1,x2=0,x3=0:sign(0.5\times 1+0.5\times 0+0.5\times 0 -0.6)=-1\\ x1=1,x2=0,x3=1:sign(0.5\times 1+0.5\times 0+0.5\times 1 -0.6)=1\\ x1=1,x2=1,x3=0:sign(0.5\times 1+0.5\times 1+0.5\times 0 -0.6)=1\\ x1=1,x2=1,x3=1:sign(0.5\times 1+0.5\times 1+0.5\times 1 -0.6)=1\\ x1=0,x2=0,x3=0:sign(0.5×0+0.5×0+0.5×0−0.6)=−1x1=0,x2=0,x3=1:sign(0.5×0+0.5×0+0.5×1−0.6)=−1x1=0,x2=1,x3=0:sign(0.5×0+0.5×1+0.5×0−0.6)=−1x1=0,x2=1,x3=1:sign(0.5×0+0.5×1+0.5×1−0.6)=1x1=1,x2=0,x3=0:sign(0.5×1+0.5×0+0.5×0−0.6)=−1x1=1,x2=0,x3=1:sign(0.5×1+0.5×0+0.5×1−0.6)=1x1=1,x2=1,x3=0:sign(0.5×1+0.5×1+0.5×0−0.6)=1x1=1,x2=1,x3=1:sign(0.5×1+0.5×1+0.5×1−0.6)=1
3、单层感知器的另一种表达形式
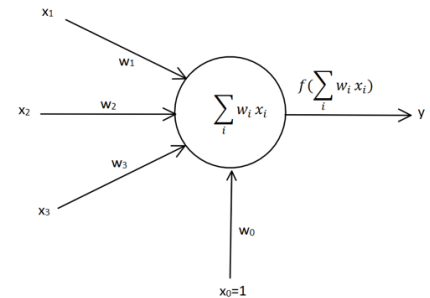
其实这种表达形式跟上面的单层感知器是一样的。只不过是把偏置值 b 变成了输入 w 0 × x 0 w_0\times x_0 w0×x0,其中x0=1。所以 w 0 × x 0 w_0\times x_0 w0×x0实际上就是w0,把 ∑ i = 1 W i X i \sum_{i=1}{W_iX_i} ∑i=1WiXi公式展开得到: w 1 × x 1 + w 2 × x 2 + w 3 × x 3 + w 0 w_1\times x_1+w_2\times x_2+w_3\times x_3+w_0 w1×x1+w2×x2+w3×x3+w0。所以这两个单层感知器的表达不一样,但是计算结果是一样的。上图的表 达形式更加简洁,更适合使用矩阵来进行运算。
4、单层感知器的学习规则
4.1 学习规则介绍
感知器的学习规则就是指感知器的权值参数训练的方法。
我们在上面已知单层感知器的表达式可以写成:
y = f ( ∑ i = 0 n w i x i ) y=f(\sum_{i=0}^{n}{w_ix_i} ) y=f(i=0∑nwixi)
公式 y = f ( ∑ i = 0 n w i x i ) y=f(\sum_{i=0}^{n}{w_ix_i} ) y=f(∑i=0nwixi)中,y表示感知器的输出,f是sign激活函数;n是输入信号的个数i=0,1,2…
△ w i = η ( t − y ) x i \bigtriangleup w_i=\eta (t-y)x_i △wi=η(t−y)xi
公式 △ w i = η ( t − y ) x i \bigtriangleup w_i=\eta (t-y)x_i △wi=η(t−y)xi中, △ w i \bigtriangleup w_i △wi表示第 i 个权值的变化, η \eta η表示学习率(Learning Rate),用来调节权值 变化的大小;t 是正确的标签(target)。
因为单层感知器的激活函数为 sign 函数,所以 t 和 y 的取值都为±1
t=y 时, △ w i \bigtriangleup w_i △wi为 0;t=1,y=-1 时, △ w i \bigtriangleup w_i △wi为 2;t=-1,y=1 时, △ w i \bigtriangleup w_i △wi为-2。由式 △ w i = η ( t − y ) x i \bigtriangleup w_i=\eta (t-y)x_i △wi=η(t−y)xi可以推 出: △ w i = ± 2 η x i \bigtriangleup w_i=\pm 2\eta x_i △wi=±2ηxi
权值调整公式为: w i = w i + △ w i w_i=w_i+ \bigtriangleup w_i wi=wi+△wi
4.2 单层感知器的学习规则计算
假设有一个单层感知器 ,已知有三个输入 x0=1,x1=0,x2=-1,权值 w0=-5,w1=0,w2=0,学习率 η \eta η=1,正确的标签 t=1。(注意在这个例子中偏置值 b 用 w 0 × x 0 w_0\times x_0 w0×x0来表示,x0 的值固定为 1)
第一步,计算感知器的输出
y = f ( ∑ i = 0 n w i x i ) = s i g n ( − 5 ∗ 1 + 0 ∗ 0 + 0 ∗ − 1 + 0 ) = s i g n ( − 5 ) = − 1 \begin{aligned} y&=f(\sum_{i=0}^{n}{w_ix_i} )\\ &=sign(-5*1+0*0+0*-1+0)\\ &=sign(-5)\\ &=-1 \end{aligned} y=f(i=0∑nwixi)=sign(−5∗1+0∗0+0∗−1+0)=sign(−5)=−1
由于 y=-1 与正确的标签 t=1 不相同,所以需要对感知器中的权值进行调节。

第二步,重新计算感知器的输出
y = f ( ∑ i = 0 n w i x i ) = s i g n ( − 3 ∗ 1 + 0 ∗ 0 + 0 ∗ − 2 + 0 ) = s i g n ( − 1 ) = − 1 \begin{aligned} y&=f(\sum_{i=0}^{n}{w_ix_i} )\\ &=sign(-3*1+0*0+0*-2+0)\\ &=sign(-1)\\ &=-1 \end{aligned} y=f(i=0∑nwixi)=sign(−3∗1+0∗0+0∗−2+0)=sign(−1)=−1
由于 y=-1 与正确的标签 t=1 不相同,所以需要对感知器中的权值进行调节。
△ w 0 = η ( t − y ) x 0 = 1 ∗ ( 1 + 1 ) ∗ 1 = 2 △ w 1 = η ( t − y ) x 1 = 1 ∗ ( 1 + 1 ) ∗ 0 = 2 △ w 2 = η ( t − y ) x 2 = 1 ∗ ( 1 + 1 ) ∗ ( − 1 ) = 2 w 0 = w 0 + △ w 0 = − 3 + 2 = − 1 w 1 = w 1 + △ w 1 = 0 + 0 = 0 w 2 = w 2 + △ w 2 = − 2 − 2 = − 4 \bigtriangleup w_0=\eta (t-y)x_0=1*(1+1)*1=2\\ \bigtriangleup w_1=\eta (t-y)x_1=1*(1+1)*0=2\\ \bigtriangleup w_2=\eta (t-y)x_2=1*(1+1)*(-1)=2\\ w_0=w_0+\bigtriangleup w_0=-3+2=-1\\ w_1=w_1+\bigtriangleup w_1=0+0=0\\ w_2=w_2+\bigtriangleup w_2=-2-2=-4\\ △w0=η(t−y)x0=1∗(1+1)∗1=2△w1=η(t−y)x1=1∗(1+1)∗0=2△w2=η(t−y)x2=1∗(1+1)∗(−1)=2w0=w0+△w0=−3+2=−1w1=w1+△w1=0+0=0w2=w2+△w2=−2−2=−4
第三步:重新计算感知器的输出
y = f ( ∑ i = 0 n w i x i ) = s i g n ( − 1 ∗ 1 + 0 ∗ 0 + ( − 4 ) ∗ ( − 1 ) + 0 ) = s i g n ( 3 ) = 1 \begin{aligned} y&=f(\sum_{i=0}^{n}{w_ix_i} )\\ &=sign(-1*1+0*0+(-4)*(-1)+0)\\ &=sign(3)\\ &=1 \end{aligned} y=f(i=0∑nwixi)=sign(−1∗1+0∗0+(−4)∗(−1)+0)=sign(3)=1
由于 y=1 与正确的标签 t=1 相同,说明感知器经过训练后得到了我们想要的结果,我们就可以结束训练了。
5、代码实战
下面的所有代码都使用Jupyter Notebook调试。
5.1 单层感知器学习规则计算举例
5.1.1 简单的实现方式
# 导入numpy 科学计算包
import numpy as np
# 定义输入
x0 = 1
x1 = 0
x2 = -1
# 定义权值
w0 = -5
w1 = 0
w2 = 0
# 定义正确的标签
t = 1
# 定义学习率lr(learning rate)
lr = 1
# 定义偏置值
b = 0
# 循环一个比较大的次数,比如100
for i in range(100):
# 打印权值
print(w0,w1,w2)
# 计算感知器的输出
y = np.sign(w0 * x0 + w1 * x1 + w2*x2)
# 如果感知器输出不等于正确的标签
if(y != t):
# 更新权值
w0 = w0 + lr * (t-y) * x0
w1 = w1 + lr * (t-y) * x1
w2 = w2 + lr * (t-y) * x2
# 如果感知器输出等于正确的标签
else:
# 训练结束
print('done')
# 退出循环
break

5.1.2 用矩阵计算实现
# 导入numpy 科学计算包
import numpy as np
# 定义输入,用大写字母表示矩阵
# 一般我们习惯用一行来表示一个数据,如果存在多个数据就用多行来表示
X = np.array([[1,0,-1]])
# 定义权值,用大写字母表示矩阵
# 神经网络中权值的定义可以参考神经网络的输入是输出神经元的个数
# 在本例子中输入神经元个数为3个,输出神经元个数为1个,所以可以定义3行1列的W
W = np.array([[-5],
[0],
[0]])
# 定义正确的标签
t = 1
# 定义学习率lr(learning rate)
lr = 1
# 定义偏置值
b = 0
# 循环一个比较大的次数,比如100
for i in range(100):
# 打印权值
print(W)
# 计算感知器的输出,np.dot可以看做是矩阵乘法
y = np.sign(np.dot(X,W))
# 如果感知器输出不等于正确的标签
if(y != t):
# 更新权值
# X.T表示X矩阵的转置
# 这里一个步骤可以完成代码3-1中下面3行代码完成的事情
# w0 = w0 + lr * (t-y) * x0
# w1 = w1 + lr * (t-y) * x1
# w2 = w2 + lr * (t-y) * x2
W = W + lr * (t - y) * X.T
# 如果感知器输出等于正确的标签
else:
# 训练结束
print('done')
# 退出循环
break
