
A题是经典的数据问题,那对这类问题我们首先要做的就是数据预处理,至于怎么处理,删除或者填补都是可以的。
问题1:请你从这64项数据中整理出适合的投入产出数据,并对各银行的效率展开对应评价,同时提供银行倒闭效率的分界线;
银行效率是银行竞争能力的综合反映,也是银行核心竞争力的重要体现,因此,提升银行效率是预防金融风险,促进银行业可持续发展的基础。
针对存在的问题提出建议,并运用数据包络分析法(DEA)构建了银行效率评价指标体系。 来源于下面这个论文。
《基于DEA模型的商业银行经营效率实证研究》
再进阶一点在传统两阶段DEA模型中引入交叉效率,并对两阶段生产系统的内部结构进行优化,构建了考虑共享投入和非期望产出的两阶段交叉效率模型。来源于下面这个论文。
《基于两阶段交叉效率模型的中国商业银行效率评价》
下面给出DEA算法的程序:
a=input('请输入投入数据:','s');
X=str2num(a);%用户输入多指标输入矩阵X
b=input('请输入产出数据:','s');
Y=str2num(b);%用户输入多指标输出矩阵Y
n=size(X', 1)
m=size(X,1);
s=size(Y,1);
epsilon=10^-10;
f=[zeros(1,n) -epsilon*ones(1,m+s) 1];
A=zeros(1,n+m+s+1);b=0;
LB=zeros(n+m+s+1,1);
UB=[];
LB(n+m+s+1)=-inf;
for i=1:n;
Aeq=[X eye(m) zeros(m,s) -X(:,i)
Y zeros(s,m) -eye(s) zeros(s,1)
ones(1,n) zeros(1,m+s+1)];
beq=[zeros(m,1)
Y(:,i)
1];
w(:,i)=linprog(f, A, b, Aeq, beq, LB, UB);
end
w
Lambda=w([1:n],:)
s_minus=w([n+1:n+m],:)
s_plus=w([n+m+1:n+m+s],:)
theta=w(n+m+s+1,:)转载于:https://www.cnblogs.com/hydbk/p/6675703.html
问题2:请利用该 64 项指标对银行倒闭的原因进行挖掘,并提供最为重要的 5 项指标数据及其对应的权重;
针对这个问题,针对这个问题,确定权重和评价的方法有很多,熵权法、Tosis、灰色评价等。第一问还是比较简单的,可以参考2020年的国赛C题。
function y=guiyi(x,type,ymin,ymax)
[n,m]=size(x);
y=zeros(n,m);
for i=1:n
for j=1:m
y(i,j)=x(i,j)/sum(x(:,j));%归一化方法
end
end
function [s,w]=shang(x,ind)
%s返回各行(样本)得分,w返回各列权重
[n,m]=size(x); % n个样本, m个指标
X=guiyi(x,1,0.002,0.996);
%%计算第j个指标下,第i个样本占该指标的比重p(i,j)
for i=1:n
for j=1:m
p(i,j)=X(i,j)/sum(X(:,j));
end
end
%%计算第j个指标的熵值e(j)
k=1/log(n);
e=ones(1,m);
for j=1:m
e(j)=-k*sum(p(:,j).*log(p(:,j)));
end
d=ones(1,m)-e; %计算信息熵冗余度
w=d./sum(d); %求权值w
s=100*w*X'; %求综合得分转载于:数学建模——熵权法Matlab编程计算权重_TyaTi的博客-CSDN博客_matlab求权重代码
问题3:对任务 1 和任务 2 中的银行倒闭分析结果展开比对分析,同时提出 一个精确的倒闭风险预测模型;
针对这个问题,这个问题可以考虑用机器学习结合0-1分类。无非就是倒闭或者没倒闭,0-1分类还是很好做的。
问题4:你能否从 2021 年银行数据中筛选出最具代表意义的 20 家现存银行 和 20 家倒闭银行,并利用这些银行数据对其它银行倒闭风险进行预测;
针对这个问题,套用前一问的模型即可。
问题5:你能否通过相关理论分析出 2017 年至 2021 年的银行数据中哪些数 据可能来自同一家银行,并结合同一家银行的时间序列数据预测哪些银行呈现出 了倒闭的趋势。
针对这个问题的话,目前我还没想到很好的做法,后面想到了我再更新。
对于数据题来说,数据预处理是必须的!!!
以上只是我个人拙见,不一定是正确的。后续有新思路或者修改,我会继续更新。
更新一下算法思路
对这种题,机器学习是比较好的选择。而且机器学习花点时间琢磨琢磨,上手还是比较容易的。
先进行数据预处理(必须要做的)确定权重分析主要指标,方便后续计算。PCA、LDA、LLE、Lapacian Eigenmaps这四个是机器学习的降维算法。
再确定权重,上述算法都可以,当然还有很多。上面的也不是最好的选择,只是个人的一点拙见。
至于风险预测,Logistic回归这个算法是很经典的机器学习二分类,简单易用。
关于数据预处理:
先简单介绍一下,数据是否缺失,是否异常(离群点,或者是超过数据的范围比如考试分数0-100,出现负数和大于100的。)还有就是是否有特殊符号,这个数据有大量的?号。
对于数据缺失我们的办法是补齐,即用均值或其他值填补。
对于数据异常值,可以是删除或者是补齐。(注意删除是把整行删除)特殊符号也如此,但这个文件来说,有两个指标明显大量特殊符号,这个时候可以考虑直接舍弃这两个指标。
至于这个处理方法,我个人推荐Python>MATLAB>SPSS>Excel>SPSSPRO
python清洗数据绝对是好手,如果编程不太行就用spss吧傻瓜式软件,Excel就是笨方法了。至于spsspro,我个人不太推荐,第一这个误差还是比较大的,第二这个对建模真的没一点提升,实在没办法的时候再用吧。
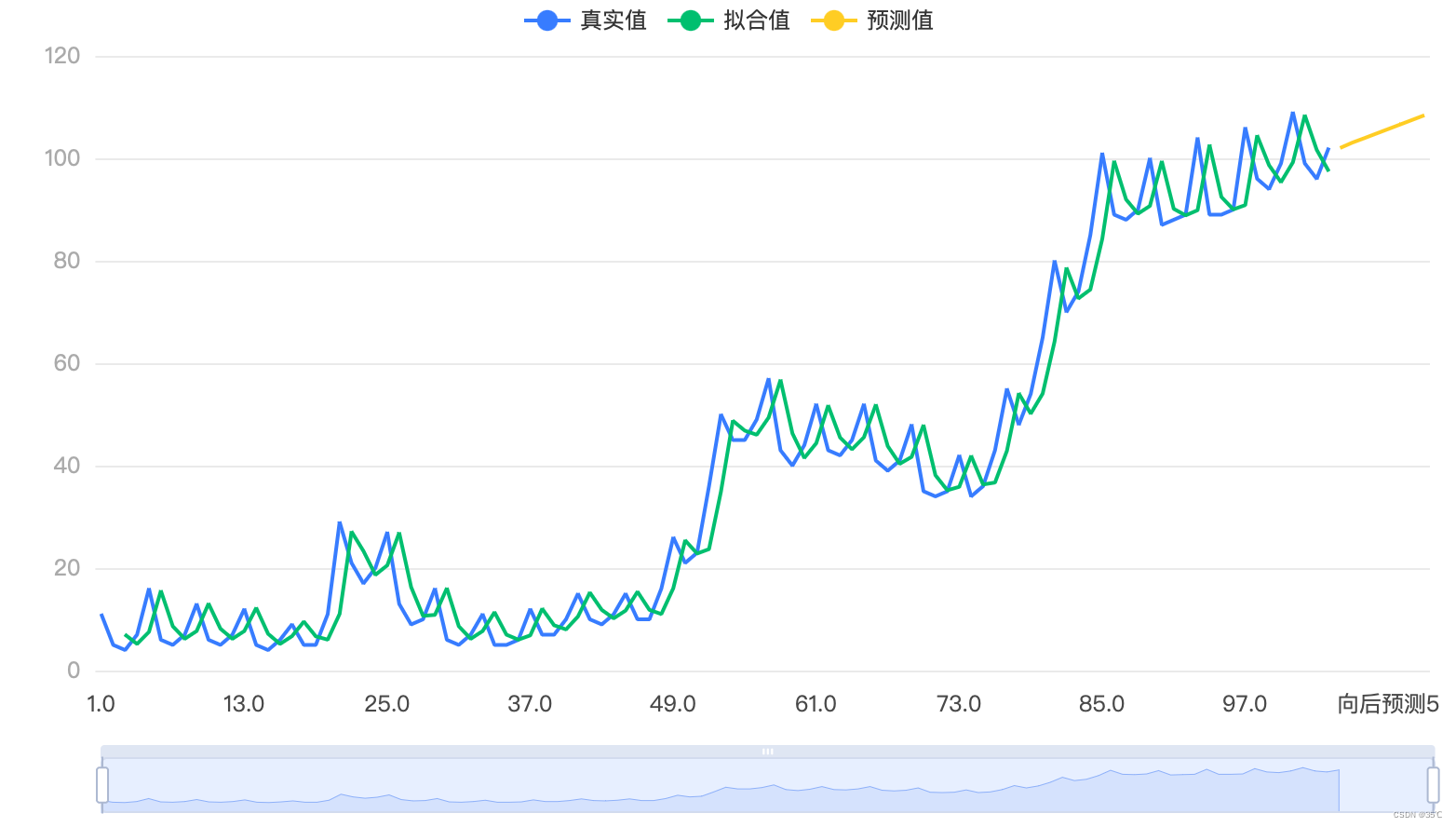
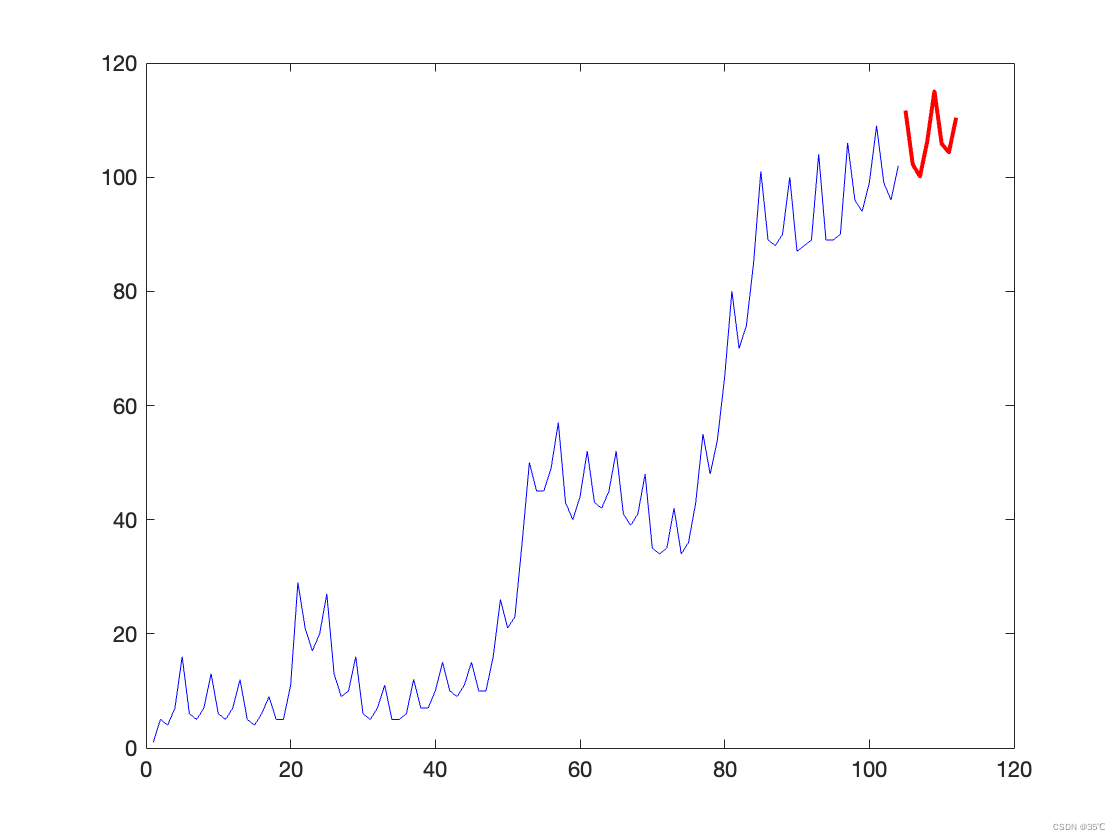
拿时间序列举例,左图是spsspro处理结果,右图是matlab处理的结果,可以看出这个软件并不太可靠。只是方便而已
关于第一问补充:
关于第一问,有人反应用这个模型的运行时间复杂度高,我提一提新思路。
方法一:首先进行数据的预处理,预处理之后依旧是很多指标,这个时候就得好好想想还是拿这么多指标进行计算权重吗?
先进行数据的降维处理吧,降维方法不唯一。再进行熵权—TOPSIS,这个算法在国赛是非常受欢迎的,计算每个指标的权重和每个银行的得分,权重高的就是合适的指标,银行得分高的就是不会倒闭。再找出倒闭和没倒闭之间的交界分数,就像是找及格分那样,过了这个分就是不倒闭,没过就是倒闭。以这个作为分界线。
方法二:直接机器学习聚类吧,当然需要做前期数据准备工作。之后再聚类,K-means聚类是先提出聚几类的算法,这个问题明显两类即可。以两个聚类中心作为分解线。
关于第二问补充:
这问,我前面说和第一问类似,现在看来还是有点点不同,可能做相关性分析的效果会更好点。
后续会继续更新。
注意!!!算权重的时候不要将所有的指标全部拿来计算!
思路补充:
数据处理,仔细看前面!数据预处理是必须的,之后进行数据的降维,首先筛选出一些比较好的指标,再用这些指标进行计算权重。
关于第一问:
前面的方法已经说的很清楚了,算法也给了好几个,总有一个适合你。
关于第二问:
前面的相关性分析依旧是可以用的,用所有的指标对是否破产进行相关性分析,取前五名即可。
或计算相关系数,取前五。
实现方法太多了,能编程的编程,编程不了的就用spss。编程对自己提升更大,而且更加精准。
关于三、四两问:
这两问,依旧用前文提及的算法即可,效果应该是比较好的。
关于第五问:
这问的前部分,通过相关理论分析出 银数据中哪些 据可能来自同一家银行这部分是比较难的,K-means聚类的话估计误差比较大,你连有几类都不知道咋做K-means聚类?
因为同一家银行来说,各项数据的变化应该不大,即欧式距离的变化幅度不大。
我这里建议用层次聚类,层次通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树,距离越小,相似度越高。也可以了解一下BIRCH算法,难度肯定是比层次聚类难的。
总结来说,这个题其实并不难,很多都是经典的数据类数模问题。很多人卡在第一问上,因为数据的处理方式没整好,这就导致计算会出很大的纰漏。所以如果有人数据没处理好的,我建议用K-means聚类方法做。
加油各位,目前距离比赛结束不到30个小时。
如果还是卡在第一问的,可以私聊我,我给出主要的输入产出指标(同学做的,不一定正确),然后开始水第一问的论文吧。
第二问的代码特别简单,不会的就用spss吧。
第三问的Logistic回归代码:
clear all
clc
%数据格式
format long
%前20组数据
X0=xlsread('D:\资料库区\大三上\HUAWEI\MATLAB\11Logistic.xls','E4:G23');
%全部25组数据:验证和回归
XE=xlsread('D:\资料库区\大三上\HUAWEI\MATLAB\11Logistic.xls','E4:G28');
%前20组评估的数据值:P
Y0=xlsread('D:\资料库区\大三上\HUAWEI\MATLAB\11Logistic.xls','H4:H23');
n=size(Y0,1);
%π和P的映射关系
for i=1:n
if Y0(i)==0
Y1(i,1)=0.25;
else
Y1(i,1)=0.75;
end
end
%构建常系数
X1=ones(size(X0,1),1);
X=[X1,X0];
Y=log(Y1./(1-Y1));
b=regress(Y,X);
%模型验证的应用
for i=1:size(XE,1)
pai0=exp(b(1)+b(2)*XE(i,1)+b(3)*XE(i,2)+b(4)*XE(i,3))/(1+exp(b(1)+b(2)*XE(i,1)+b(3)*XE(i,2)+b(4)*XE(i,3)));
if(pai0<=0.5)
P(i)=0;
else
P(i)=1;
end
end
%回归结果
disp(['回归系数:' num2str(b') ' ']);
disp(['评估结果:' num2str(P) ' ']);
来源于:matlab Logistic回归模型_alex1997222的博客-CSDN博客_matlab逻辑回归模型
上述代码自己改改,如果代码有问题可以私聊我或者评论。(不一定能及时回复)
第五问的层次聚类代码:
%% 读取数据
clc;clear all,close all
pre_data=xlsread('StockFinance.xlsx','Sheet1','E2:N4735');
%% 数据归一化
[rn,cn]=size(pre_data);
step1_data=zeros(rn,cn);
for k=1:cn
%基于均值方差的离群点数据归一化
xm=mean(pre_data(:,k));
xs=std(pre_data(:,k));
for j=1:rn
if (pre_data(j,k))>xm+2*xs
step1_data(j,k)=1;
elseif (pre_data(j,k))<xm-2*xs
step1_data(j,k)=0;
else
step1_data(j,k)=(pre_data(j,k)-(xm-2*xs))/(4*xs);
end
end
end
xlswrite('norm_data.xlsx',step1_data);
%% 层次聚类
numClust=3;
dist_h='spearman';
link='weighted';
hidx=clusterdata(step1_data,'maxclust',numClust,'distance',dist_h,'linkage',link);
来源于:聚类分析(三) 层次聚类及matlab程序_坚持,再坚持一下的博客-CSDN博客_matlab层次聚类
上述代码也一样,有问题可以联系我。
思路方面应该是不会更新了,你们代码有问题评论或私聊就行(不一定及时)。
如果有算法或者其他问题,评论或者私聊。
最后祝大家取得理想成绩!!!

关注微信公众号,后续会有数模资料。