* 1. 新建一个项目
* 2. 修改 tempaltes路径问题
'DIRS' : [ BASE_DIR, 'templates' ]
* 3. 在app01下创建表模型
from django. db import models
class Book ( models. Model) :
id = models. AutoField( primary_key= True , verbose_name= '主键' )
title = models. CharField( max_length= 32 , verbose_name= '书名' )
price = models. DecimalField( max_digits= 5 , decimal_places= 3 )
author = models. CharField( max_length= 32 , verbose_name= '作者' )
publish = models. CharField( max_length= 32 , verbose_name= '出版社' )
* 4. 生成表
生成操作记录 python manage . py makemigrations
数据库迁移 python manage . py migrate
* 5. 在项目app01下的tests . py中添加两条数据
import os
import sys
if __name__ == "__main__" :
os. environ. setdefault( "DJANGO_SETTINGS_MODULE" , "DRF1_serializers.settings" )
import django
django. setup( )
from app01. models import Book
book_list = [
{
'title' : '穿越诸天万界' ,
'price' : 12.3 ,
'author' : 'aa' ,
'publish' : '飞卢小说网'
} ,
{
'title' : '洪荒道尊' ,
'price' : 32.1 ,
'author' : 'bb' ,
'publish' : '飞卢小说网'
} ]
queryset_list = [ ]
for dic in book_list:
queryset_list. append( Book( ** dic) )
Book. objects. bulk_create( queryset_list)
序列化组件Serializer是rest_framework的 .
导入序列化组件 :
from rest_framework . serializers import Serializer
1. 序列化 : 序列化器会把模型对象转为字典 , 经过response之后变成json格式字符串 , 发送给客户端 .
2. 反序列化 : 序列化器可以将字典转为模型对象 , 客户端发送的数据 , 经过request以后变成字典 .
3. 反序列化完成数据校验功能 .
1. 写一个序列化类 , 这个类需要继承Serializer
2. 在类中写需要序列化的字段 , 字段 = serializers . 转换的类型 ( ) , 将表字段对应的数据转为指定格式数据
3. 在视图中导入序列化类 , 实例化得到一个序列化器对象 , 需要转化的数据对象作为第一个参数 , 传入序列化类中
4. 序列化类实例化得到一个对象 , 序列列化的数据是一个字典 , 被封装到对象的 . data方法中
5. 字典数据使用rest_framework提供的Response函数放回
rest_framework提供的Response , 会根据不同的客户端返回不同的信息 , 如浏览器访问 , 返回一个页面 .
使用JsonResponse返回的数据就都是json格式的字符串 .
对于DRF框架中序列化器所有的字段类型,我们可以到 rest_framework . fields 模块中进行查看
序列化器类定义字段类型和Django框架中ORM的字段类型是一样 .
序列化器中常用的字段类型如下
字段
字段构造方式
BooleanField
BooleanField()
CharField
CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
EmailField
EmailField(max_length=None, min_length=None, allow_blank=False)
IntegerField
IntegerField(max_value=None, min_value=None)
FloatField
FloatField(max_value=None, min_value=None)
DecimalField
DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None)max_digits: 最多位数decimal_palces: 小数点位置
DateTimeField
DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
DateField
DateField(format=api_settings.DATE_FORMAT, input_formats=None)
TimeField
TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
ChoiceField
ChoiceField(choices)choices与Django的用法相同
ImageField
ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
* 1. 在app01项目下新建一个res . py文件
from rest_framework import serializers
from rest_framework. serializers import Serializer
class BookSerializer ( Serializer) :
id = serializers. CharField( )
title = serializers. CharField( )
price = serializers. CharField( )
author = serializers. CharField( )
* 2. 定义一个路由
url( r'^book/(?P<pk>\d+)/' , views. Book. as_view( ) )
* 3. 定义视图类 使用APIView
from django. shortcuts import render, redirect, HttpResponse
from rest_framework. views import APIView
class BookView ( APIView) :
def get ( self, request, pk) :
from app01. models import Book
book_obj = Book. objects. filter ( pk= pk) . first( )
print ( book_obj)
from app01. res import BookSerializer
book_dic = BookSerializer( book_obj)
print ( book_dic. data)
from rest_framework. response import Response
return Response( book_dic. data)
将导入模块提出
from django. shortcuts import render, redirect, HttpResponse
from rest_framework. views import APIView
from app01. models import Book
from app01. res import BookSerializer
from rest_framework. response import Response
class BookView ( APIView) :
def get ( self, request, pk) :
book_obj = Book. objects. filter ( pk= pk) . first( )
print ( book_obj)
book_dic = BookSerializer( book_obj)
print ( book_dic. data)
return Response( book_dic. data)
* 4. 启动项目
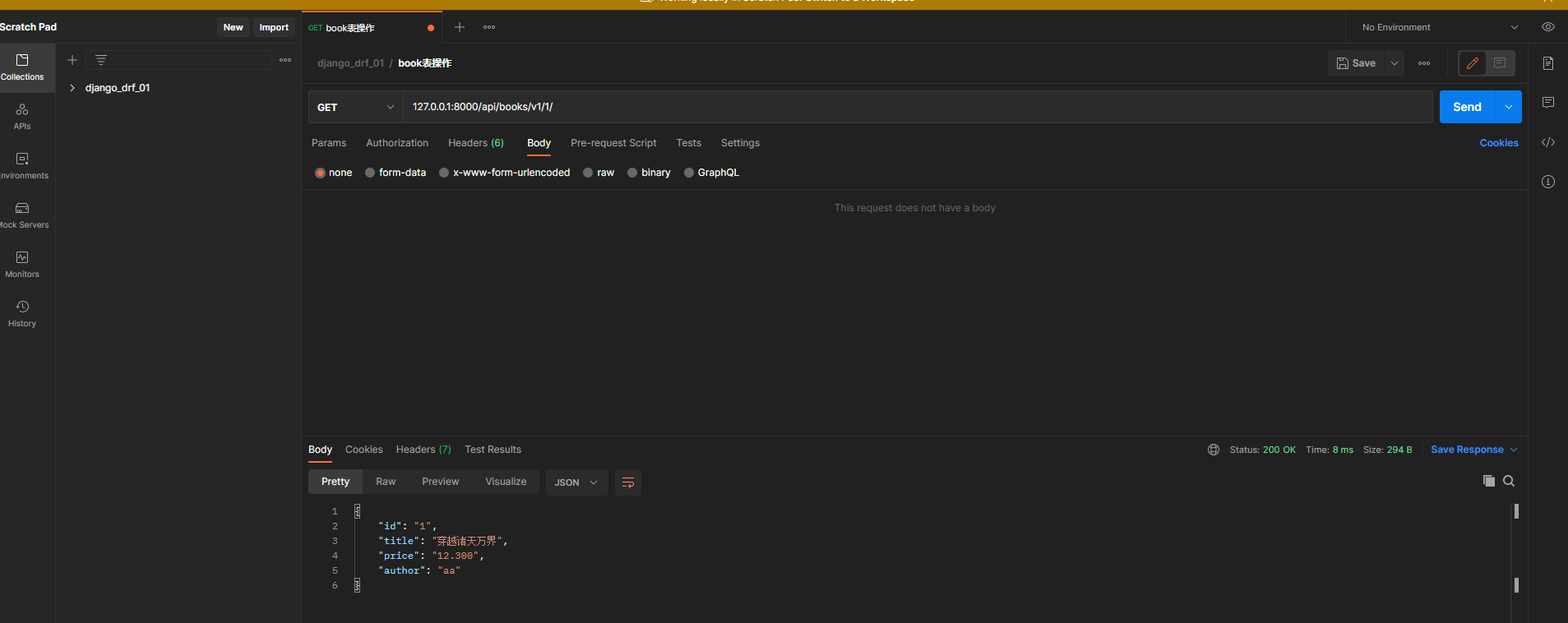
* 5. 在Postman中测试
GET 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
定义的字段都处理了 , 作者字段没有处理
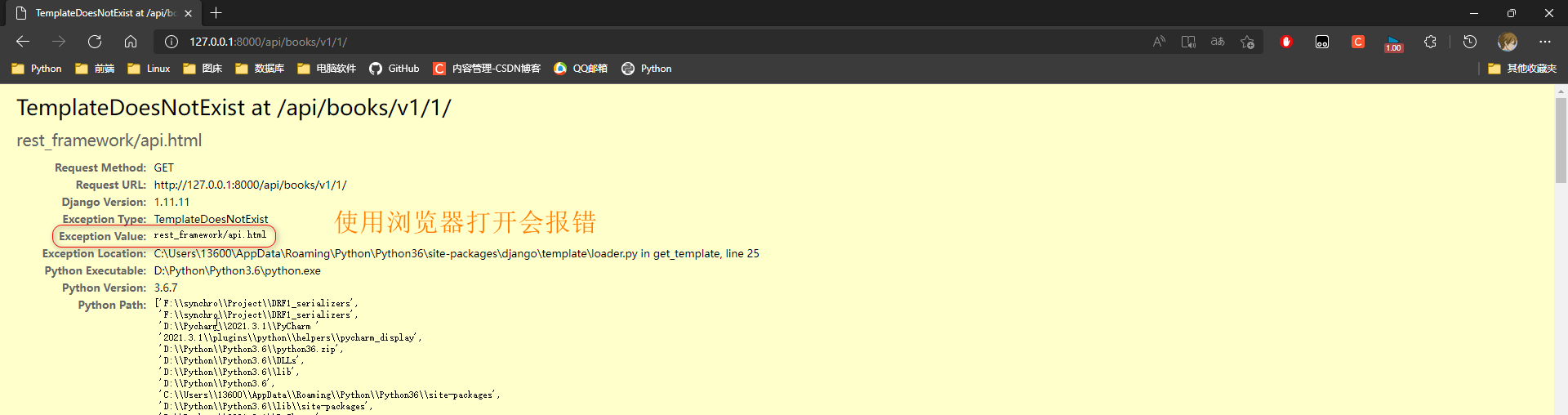
* 6. 在浏览器中访问 : 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
使用srest_framework的Response返回数据的时候 , 针对浏览器 , 会渲染一个页面返回 ,
这个页面使用通过srest_framework模块的app去生成的 , 需要对这个app进行注册 .
出现这个错误之后 , 去app列表中注册rest_framework即可 .
* 7. 应用列表中注册 rest_framework app
INSTALLED_APPS = [
. . .
'rest_framework' ,
]
* 8. 重新访问
1. 写一个序列化类 , 这个类需要继承Serializer
2. 在类中写需要反序列化的字段 , 字段 = serializers . 转换的类型 ( 限制条件 )
2.1 将请求的数据转为指定类型数据 , json格式字符串 ( 字典 ) -- > Python字典
2.2 转换数据的时候做数据的校验 , 默认的参数达不到要求 , 可以自定义钩子函数
参数名称
作用
max_length
字符串最大长度
min_length
字符串最小长度
max_value
数字最大值
min_value
数字最小值
allow_blank
是否允许为空
trim_whitespace
是否截切空白字符
3. 在视图中导入序列化类 , 实例化得到一个序列化器对象 ,
需要转化的数据对象作为第一个参数 , 修改的数据作为第二个参数 , 传入序列化类中 .
对象 = xxserializer ( 数据对象 , request . data )
推荐 对象 xxserializer ( instance = 数据对象 , data = request . data )
4. 数据校验
对象 . is_valid , 判断数据是否合法
is_valid ( raise_exception = True ) : 数据校验不通过直接return返回错误提示
对象 . errors 校验不通过的异常信息
对象 . error_messages 异常的提示信息
5. 检验成功就保存数据
对象 . sava ( ) , 需要在序列化类重新updata方法 .
6. 检验不成功 , 写错误的逻辑
修改的数据的请求put 与 patch 虽然被区分为局部修改和全局修改 , 倒是在使用时 , 没人严格区分 , 使用那个都行 .
1. 修改app01下的res . py 中的序列化类 , 添加校验条件
class BookSerializer ( Serializer) :
id = serializers. CharField( )
title = serializers. CharField( min_length= 3 , max_length= 5 )
price = serializers. CharField( )
author = serializers. CharField( )
* 2. 写视图类的put方法
def put ( self, request, pk) :
"""
对数据修改需要对数据做检验
"""
book_obj = Book. objects. filter ( pk= pk) . first( )
book_dic = BookSerializer( instance= book_obj, data= request. data)
if book_dic. is_valid( ) :
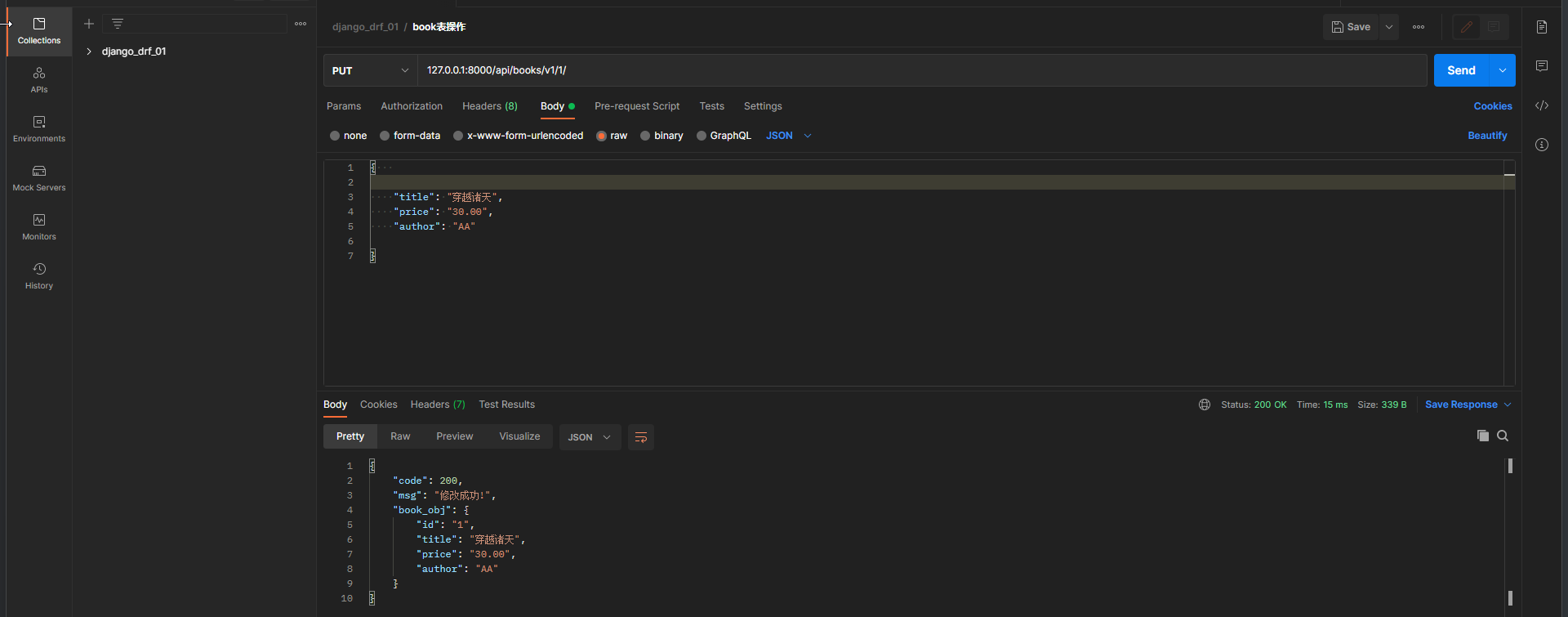
book_dic. save( )
back_dic = {
'code' : 200 ,
'msg' : '修改成功!' ,
'book_obj' : book_dic. data
}
else :
back_dic = {
'code' : 404 ,
'msg' : f'修改失败: {
book_dic. errors} ' }
return Response( back_dic)
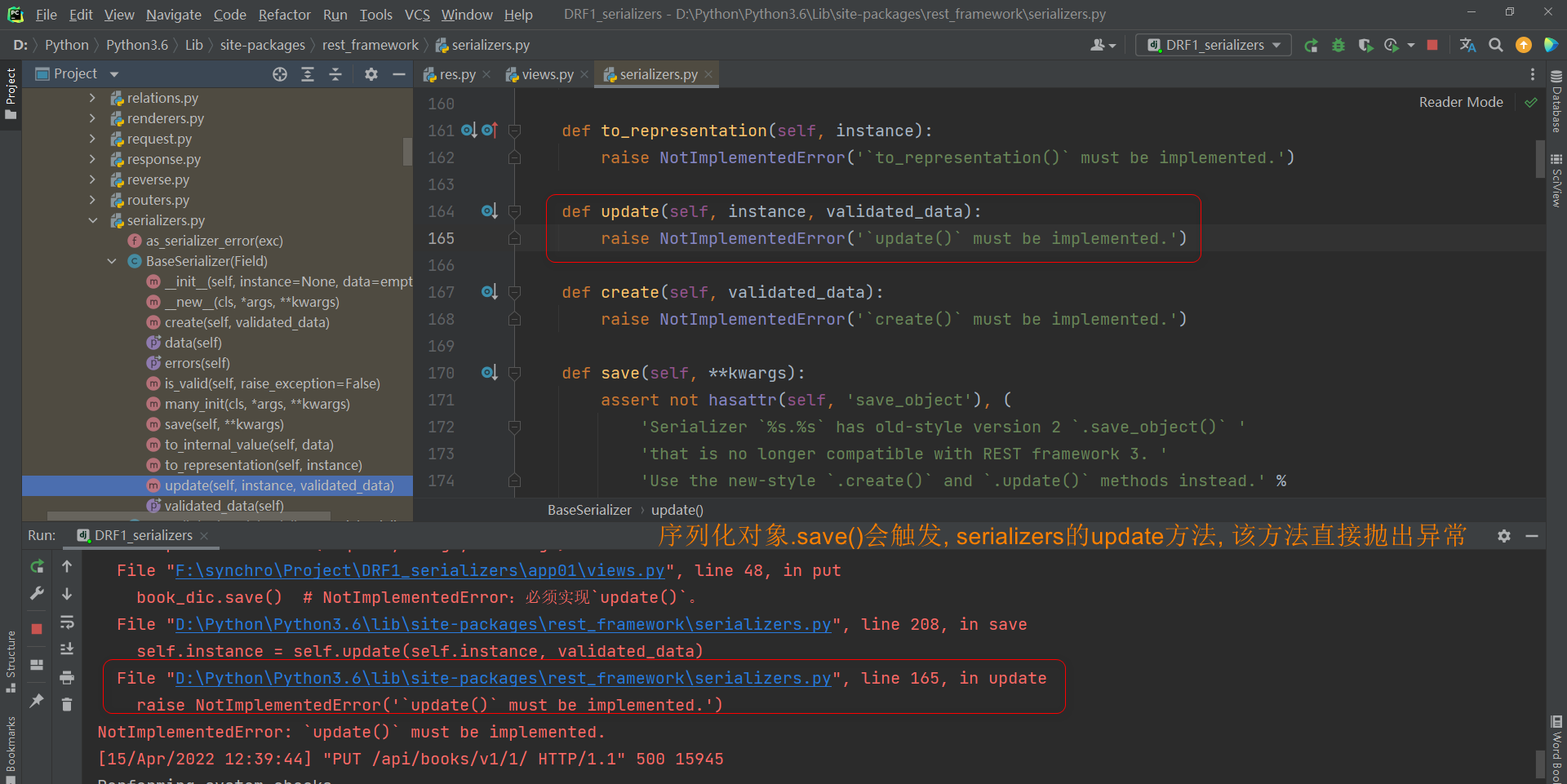
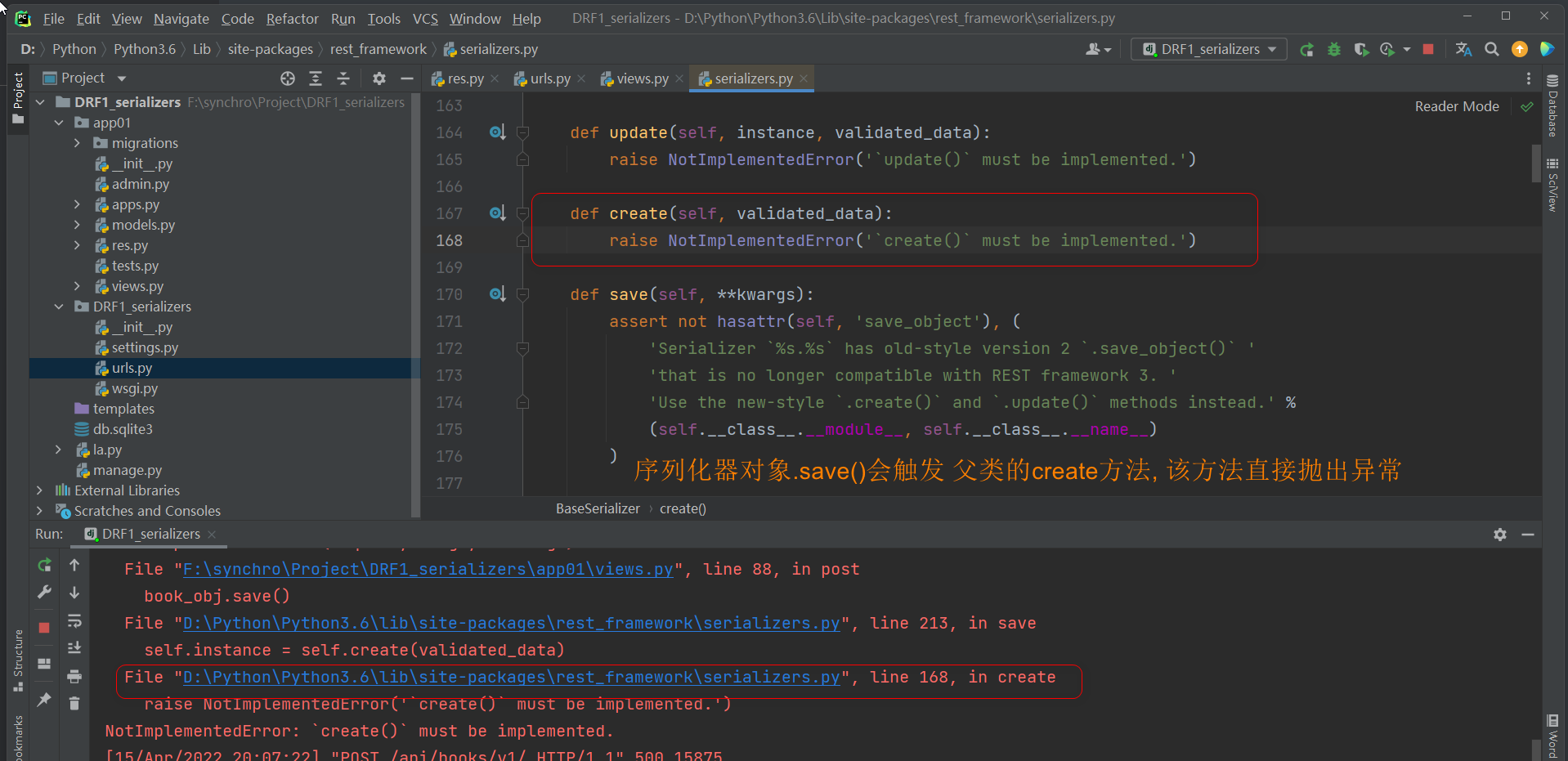
序列化器的对象 , 自己是没有save方法的 , 父类中定义了该方法 . 它判断当前需要更新数据就会调用update方法
update方法利用Python面向对象的多态特性 , 在父类中限制子类必须有某个方法 , 实现某个功能 .
* 3. 在序列化类定义update方法 .
每个表的数据都是不一样的 , 写这个模板的作者刚脆不提供数据更新到数据库的方法 ,
在父类中限制该方法必须实现 , 让使用者自己写update , 将数据更新到数据库
class BookSerializer ( Serializer) :
id = serializers. CharField( )
title = serializers. CharField( min_length= 3 , max_length= 5 )
price = serializers. CharField( )
author = serializers. CharField( )
def update ( self, instance, validated_data) :
for key in validated_data:
setattr ( instance, key, validated_data. get( key) )
instance. save( )
return instance
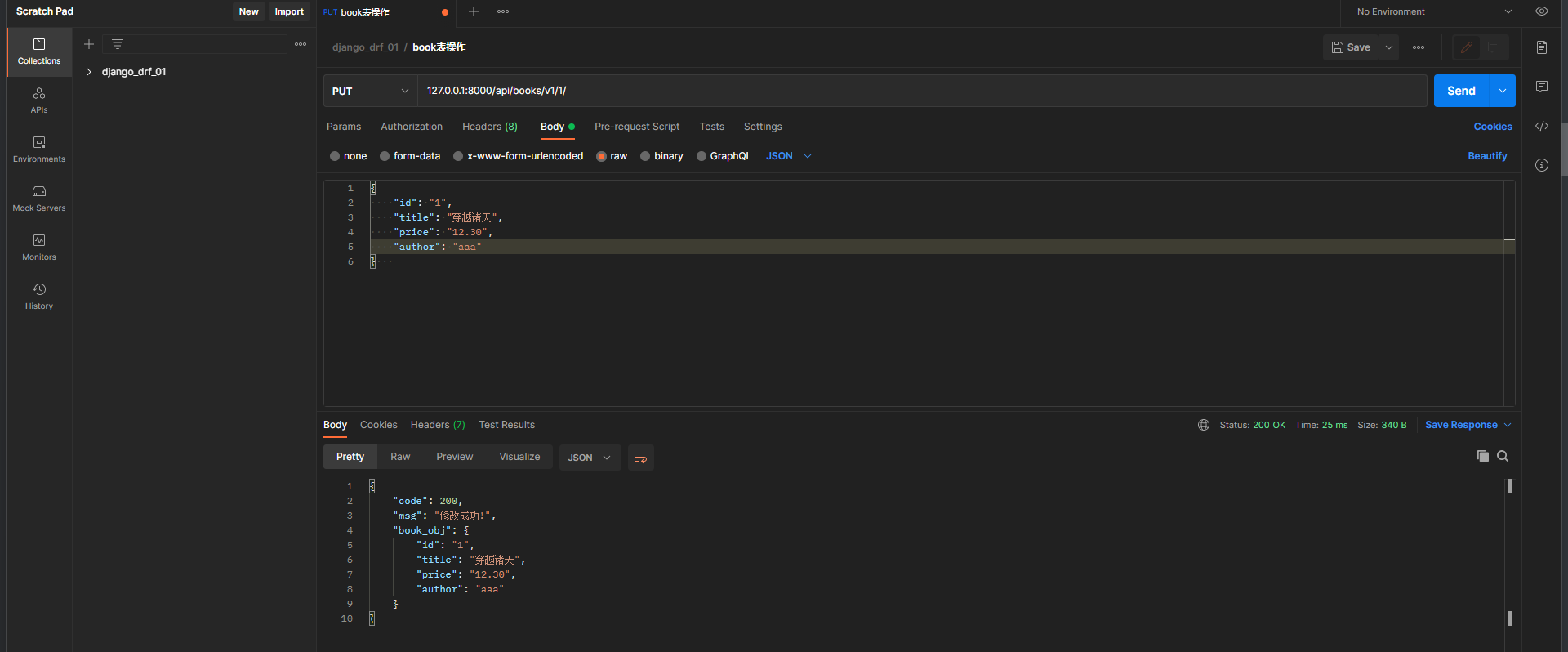
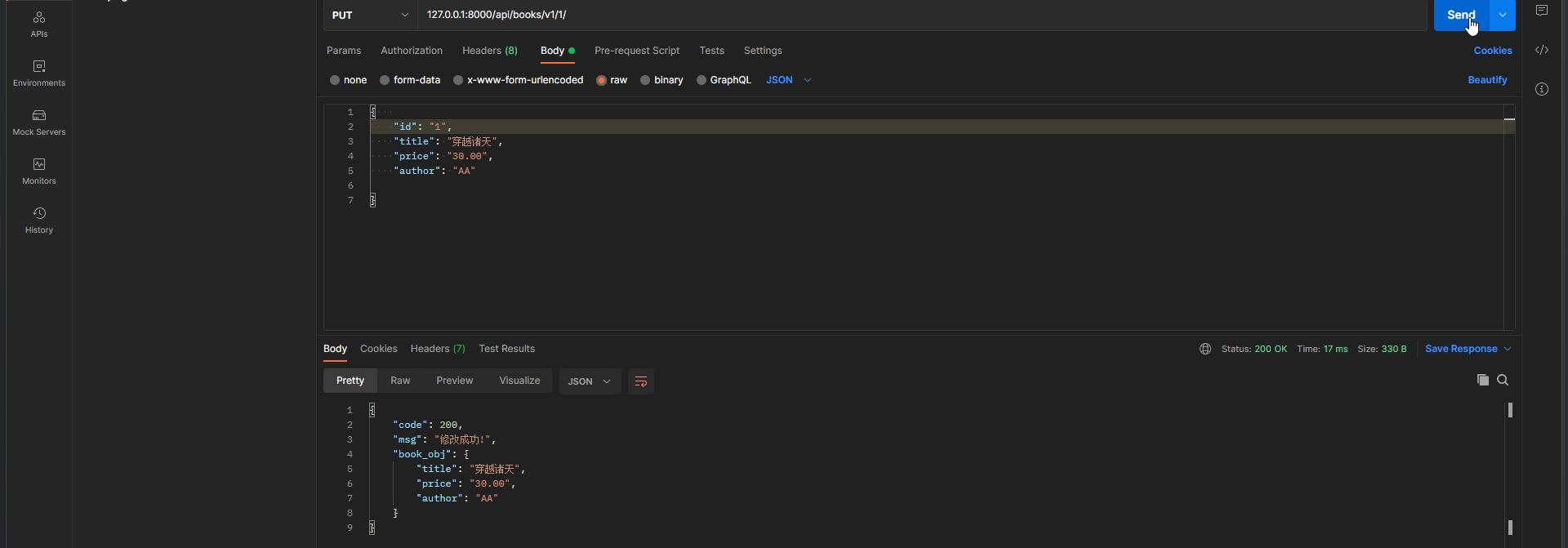
* 5. 在Postman中测试 : ( * 序列化器类中定义的字段必须传数据 , 不然 , 反序列化该字段就会报错 , 不能为空 )
请求方式 : put
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
请求格式 : raw-JSON
请求数据 :
{
"id" : "1" ,
"title" : "穿越诸天" ,
"price" : "12.30" ,
"author" : "aaa" ,
}
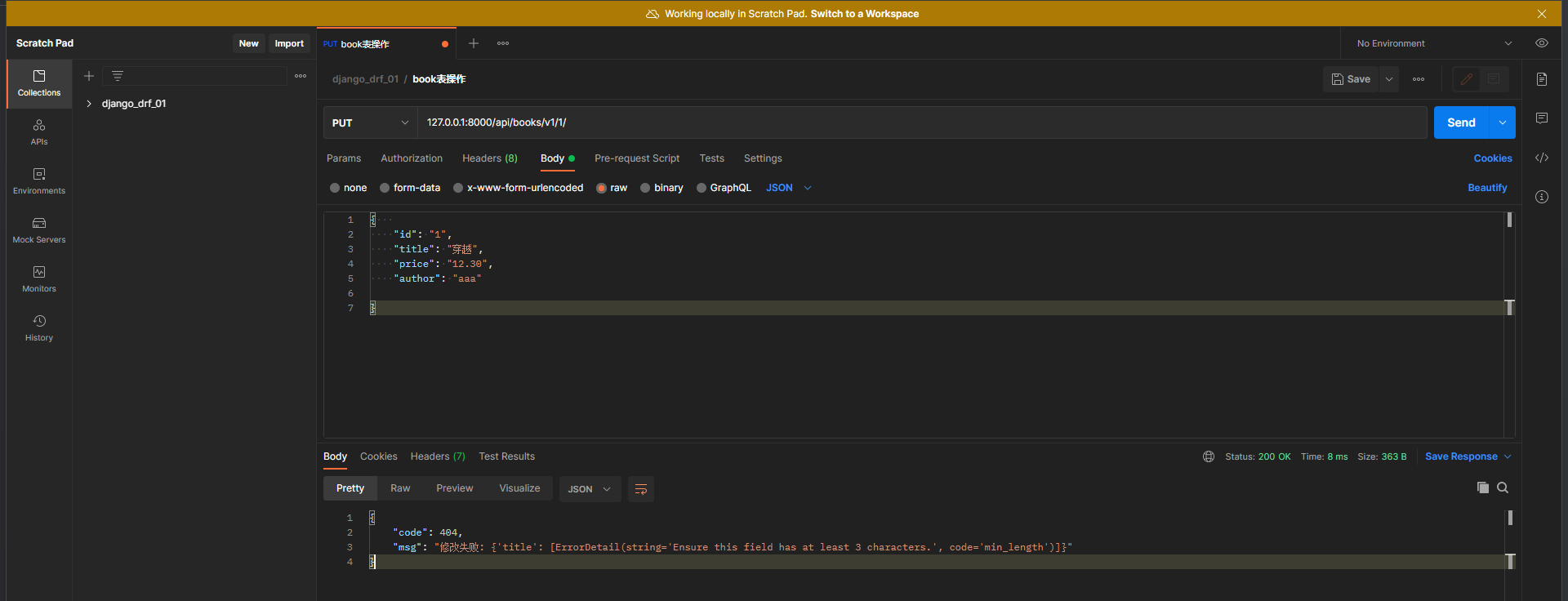
* 6. 检验测试
tilte字段的修改限制条件 : 字符串 最长 5 位 , 最少 3 为
请求数据 :
{
"title" : "穿越" ,
"price" : "12.30" ,
"author" : "aaa" ,
}
book_dic. is_valid( raise_exception= True )
校验的顺序 , 是一个一个字段验证的 , 先验证参数规则 , 马上检查自己对应的局部钩子 .
在局部钩子中使用 raise ValidationError ( 'xx' ) , 抛出的异常被捕获 , 并封装到对象 . errors中 .
# 导入抛异常模板
from rest_framework . exceptions import ValidationError
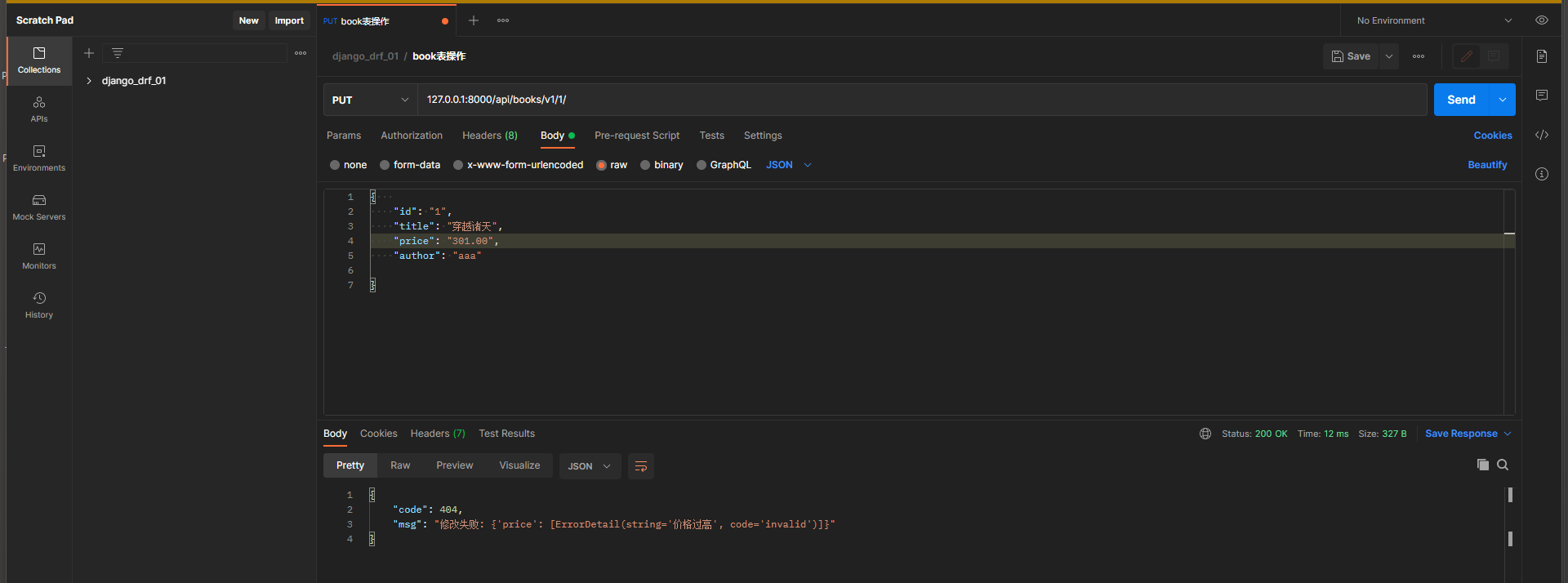
检验书的价格不能超过 300.00
* 1. 在序列化类中写局部钩子函数 , 局部钩子的函数名 validdate_需要校验的字段名称
必须接收一个date参数 , 这个参数就是 , 该字段提交的值 , 在经过第一层serializers . xx ( x ) 校验之后的数据 .
from rest_framework import serializers
from rest_framework. serializers import Serializer
from rest_framework. exceptions import ValidationError
class BookSerializer ( Serializer) :
id = serializers. CharField( )
title = serializers. CharField( min_length= 3 , max_length= 5 )
price = serializers. CharField( )
author = serializers. CharField( )
def update ( self, instance, validated_data) :
for key in validated_data:
setattr ( instance, key, validated_data. get( key) )
instance. save( )
return instance
def validate_price ( self, data) :
print ( data, type ( data) )
if float ( data) < 300.00 :
return data
else :
return ValidationError( '价格过高' )
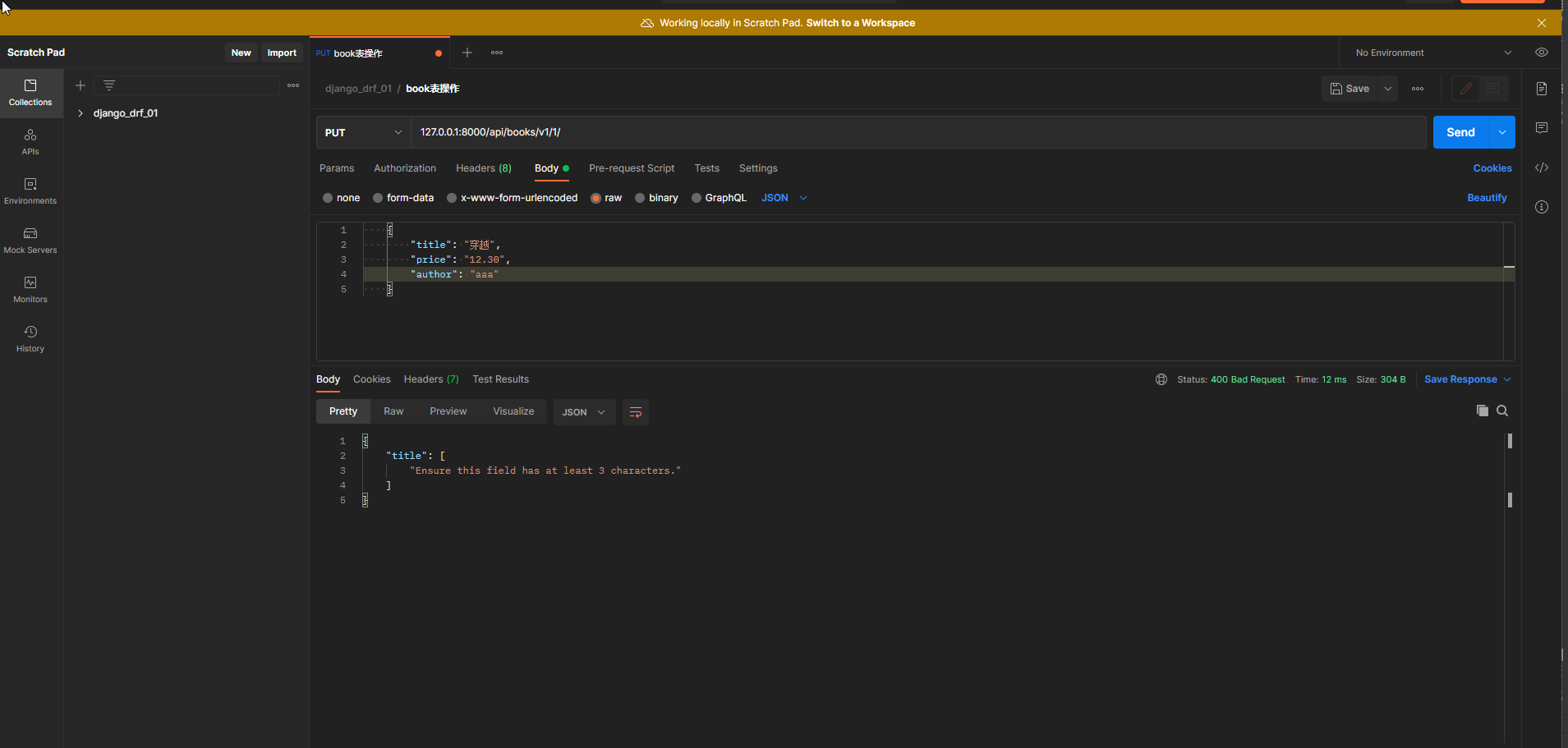
* 2. 在Postman中测试 :
请求方式 : put
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
请求格式 : raw-JSON
请求数据 :
{
"id" : "1" ,
"title" : "穿越诸天" ,
"price" : "301.00" ,
"author" : "aaa"
}
校验的顺序 , 等所有的字段检验了参数规则和局部钩子之后 , 得到了所有校验合格的数据 , 才执行全局钩子 .
字段多了 , 少了 , 没有经过检验的都会被排除 .
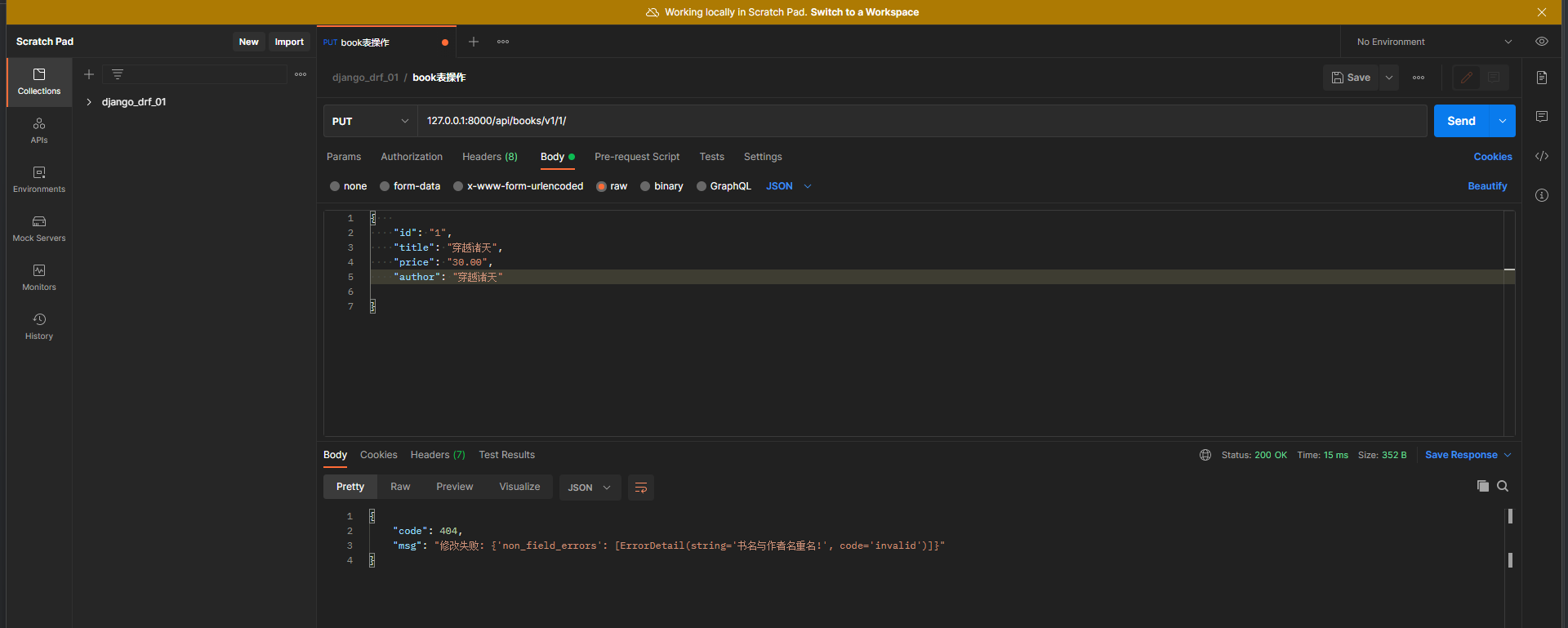
检验书名不能与作者社重名
* 2. 在序列化类中写全局钩子函数 , 全局钩子的函数名 validdate
必须接收一个validdate_tate参数 , 这个参数就是 , 经过第一层serializers . xx ( x ) 校验后所有合格的数据 .
def validate ( self, validate_data) :
print ( validate_data, type ( validate_data) )
title = validate_data. get( 'title' )
author = validate_data. get( 'author' )
if author != title:
return validate_data
else :
raise ValidationError( '书名与作者名重名!' )
* 2. 在Postman中测试 :
请求方式 : put
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
请求格式 : raw-JSON
请求数据 :
{
"id" : "1" ,
"title" : "穿越诸天" ,
"price" : "30.00" ,
"author" : "穿越诸天"
}
第一层数据检验之后合格之后被封装成一个有序字典存 , 在定义全局钩子的时候 , 会被作为一个参数进行传递 .
OrderedDict ( [
( 'id' , '1' ) ,
( 'title' , '穿越诸天' ) ,
( 'price' , '30.00' ) ,
( 'author' , 'aaa' ) ] )
< class 'collections.OrderedDict' >
使用使用字段的validators指定一个校验函数 , xxx . CharField ( validators = [ 函数名 1 , 函数名 2 ] )
可以通过函数的形式去检验数据 , 使用和局部钩子一样 , 写成函数形式 , 不多见 .
定义多个序列化器类的时候 , 校验多个表中的字段时使用 .
可以指定多个检验的函数 .
from rest_framework import serializers
from rest_framework. serializers import Serializer
from rest_framework. exceptions import ValidationError
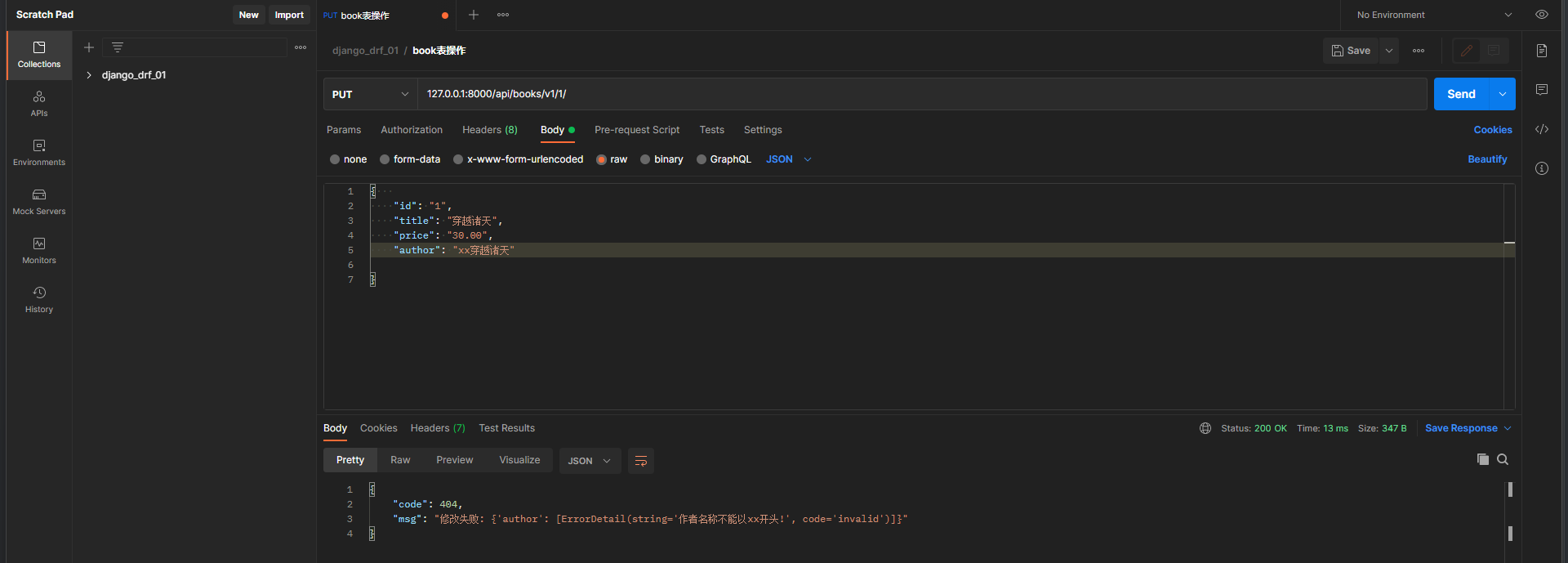
def check_keyword ( data) :
if data. startswith( 'xx' ) :
raise ValidationError( '作者名称不能以xx开头!' )
else :
return data
class BookSerializer ( Serializer) :
id = serializers. CharField( )
title = serializers. CharField( min_length= 3 , max_length= 5 )
price = serializers. CharField( )
author = serializers. CharField( validators= [ check_keyword] )
def update ( self, instance, validated_data) :
for key in validated_data:
setattr ( instance, key, validated_data. get( key) )
instance. save( )
return instance
参数名称
说明
read_only
表明该字段仅用于序列化数据, 默认为False
write_only
表明该字段仅用于反序列化数据, 默认为False
required
表明该字段在反序列化时必须输入, 默认为True,
default
反序列化时使用设置的默认值
allow_null
表明该字段是否允许传入None, 默认为False
validators
该字段可以指定使用的验证器, [func]
error_messages
包含错误编号与错误信息的字典
在序列化字段的时候 , 读写都是同一个序列化类 , 这样就会出现某个字段在读的时候需要 , 某写字段在写的时候需要 .
read_only = True 在查询到数据序列化成字典的时候 , 该字段会展示 , 在传数据的时候不需要写该字段的值 .
write_only = True 在写入数据反序列化的成模型对象的时候 , 该字段需要传值 , 在查询该数据的时候不会展示 .
class BookSerializer ( Serializer) :
id = serializers. CharField( read_only= True )
. . .
class BookSerializer ( Serializer) :
id = serializers. CharField( write_only= True )
. . .
查询所有可以新建一个路由 , 也可以在原来的get请求上 , 对pk的值进行判断 ,
有值则是单条数据查询 , 没值则是查询全部 .
多个数据序列化的时候序列化类 ( 需要设置many = True )
url( r'^api/books/v1/$' , views. BooksView. as_view( ) ) ,
class BooksView ( APIView) :
def get ( self, request) :
all_books_obj = Book. objects. all ( )
all_books = BookSerializer( instance= all_books_obj, many= True )
back_dic = {
'code' : 200 ,
'msg' : '查询成功!' ,
'book_obj' : all_books. data
}
return Response( back_dic)
url( r'^api/books/v1/$' , views. BooksView. as_view( ) ) ,
添加数据是没有数据对象的值 , 只需要将request . data的值创建即可 , 需要使用关键的形式传递 .
序列化类的第一个位置形参是instance , 如果以位置参数进行传递就出错了 .
def post ( self, request) :
book_obj = BookSerializer( data= request. data)
if book_obj. is_valid( ) :
book_obj. save( )
back_dic = {
'code' : 201 ,
'msg' : '创建成功!' ,
'book_obj' : book_obj. data
}
else :
back_dic = {
'code' : 101 ,
'msg' : f'数据检验不通过 {
book_obj. errors} ' }
return Response( back_dic)
序列化器的对象 , 自己是没有save方法的 , 父类中定义了该方法 , 它判断当前需要创建数据就会调用create方法
create方法利用Python面向对象的多态特性 , 在父类中限制子类必须有某个方法 , 实现某个功能 .
在序列化类定义create方法 .
每个表的数据都是不一样的 , 写这个模板的作者刚脆不提供创建数据到数据库的方法 ,
在父类中限制该方法必须实现 , 让使用者自己写create , 创建数据到数据库 .
from app01. models import Book
def create ( self, validated_data) :
instance = Book. objects. create( ** validated_data)
return instance
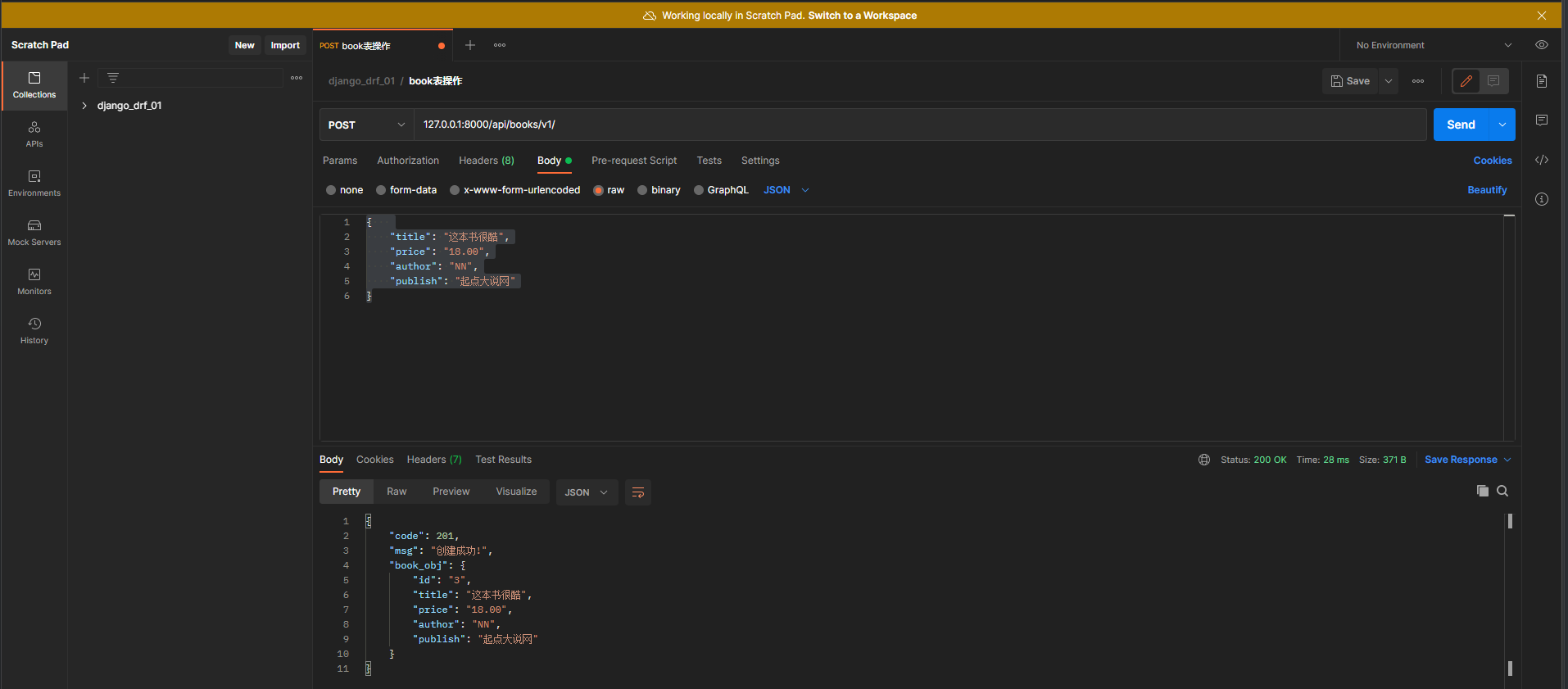
* 2. 在Postman中测试 :
请求方式 : put
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/
请求格式 : raw-JSON
请求数据 : ( id设置为只读模式 , 在写入数据的时候 , 该字段不要参数 )
{
"title" : "这本书很酷" ,
"price" : "18.00" ,
"author" : "NN" ,
"publish" : "起点大说网"
}
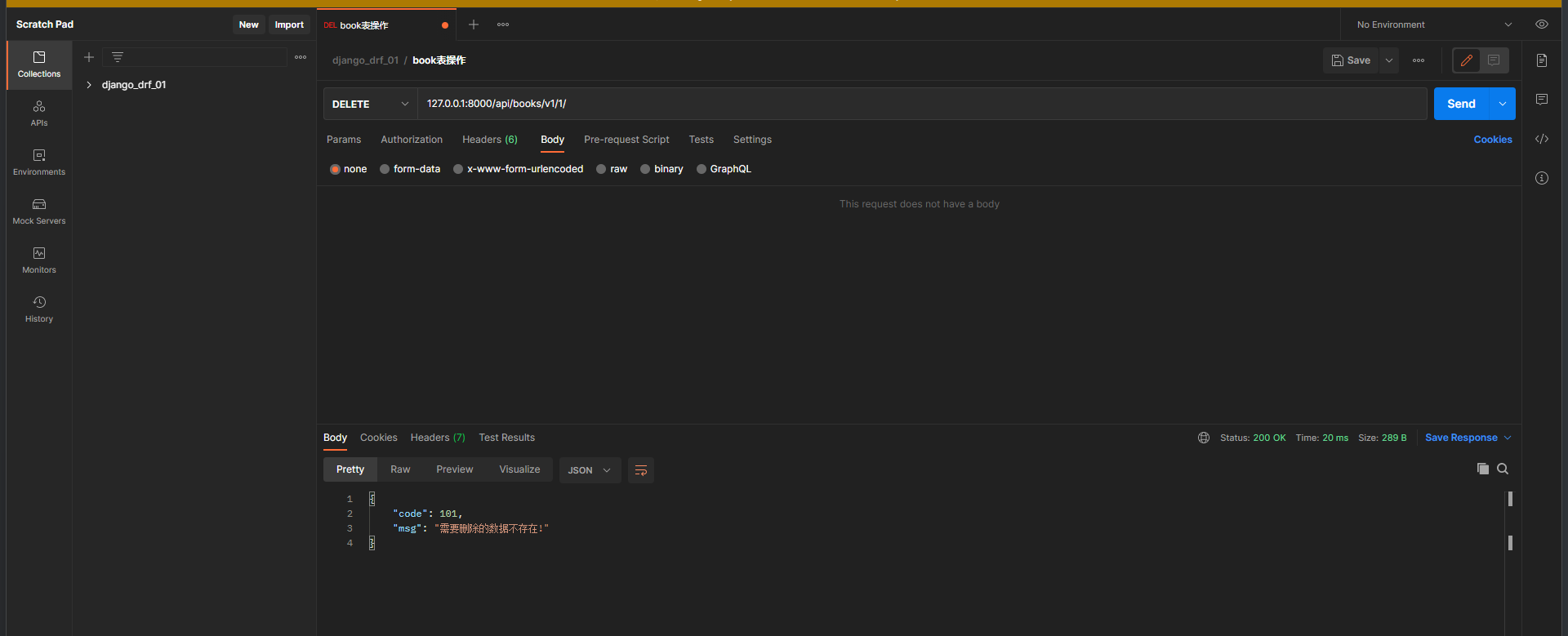
删除在有名分组获取主键的的视图类中写 ,
删除数据之间过滤数据删除即可 , 不需要使用序列化器 , 不需要返回什么数据 , 返回响应信息即可 .
url( r'^api/books/v1/(?P<pk>\d+)/' , views. BookView. as_view( ) ) ,
def delete ( self, request, pk) :
num = Book. objects. filter ( pk= pk) . delete( )
print ( num)
if num[ 0 ] :
back_dic = {
'code' : 100 ,
'msg' : '删除成功'
}
else :
back_dic = {
'code' : 101 ,
'msg' : '需要删除的数据不存在!'
}
return Response( back_dic)
再次删除
每个接口都需要返回响应信息 , 可以加响应信息利用类来实现 .
* 1. 在app001下创建一个request_msg . py
* 2. 写一个MyResponse类
class MyResponse ( ) :
def __init__ ( self) :
self. code = 200
self. msg = '成功'
@property
def get_dict ( self) :
return self. __dict__
* 3. 在接口中调用MyResponse生成响应信息
如果有数据对象需要返回 , 对象 . book_obj = 序列化对象 . data 即可
def delete ( self, request, pk) :
num = Book. objects. filter ( pk= pk) . delete( )
print ( num)
if num[ 0 ] :
res = MyResponse( )
back_dic = res. get_dict
else :
res = MyResponse( )
res. code = 101
res. msg = '需要删除的数据不存在!'
back_dic = res. get_dict
return Response( back_dic)
模型序列化组件可以省去定义字段的转换的过程 . 模型序列化器需要继承ModelSerializer类 .
它的使用方法与序列化器是一样的 .
* 模型序列化组件对应上了模型表 , create与update方法就不需要自己写了 .
# 导入模型序列化类
from rest_framework . serializers import ModelSerializer
模型类中必须定义Meta类 , 在Meta类中必须定义field属性或exclude属性 , 两者只能出现一个 .
field = '__all__' 所有字段都转换
field = [ '字段1' , '字段2' , . . . ] 指定转换的字段
exclude = [ '字段1' , '字段2' , . . . ] 排除指定字段
extra_kwargs = {
'字段1' : {
'read_only' : True } } 为字段添加条件 , 设置id字段默认开启了只读 !
局部钩子和全局钩子直接后面添加即可 , 使用方法与序列化器时一模一样的 .
class Meta :
model = xxx
# 定义局部钩子
. . .
# 定义全局钩子
. . .
* 1. 定义一个模型序列化类
from rest_framework. serializers import ModelSerializer
class BookModelsSerializer ( ModelSerializer) :
class Meta :
model = Book
fields = '__all__'
* 2. 新建一个路由 , 查询所有的数据
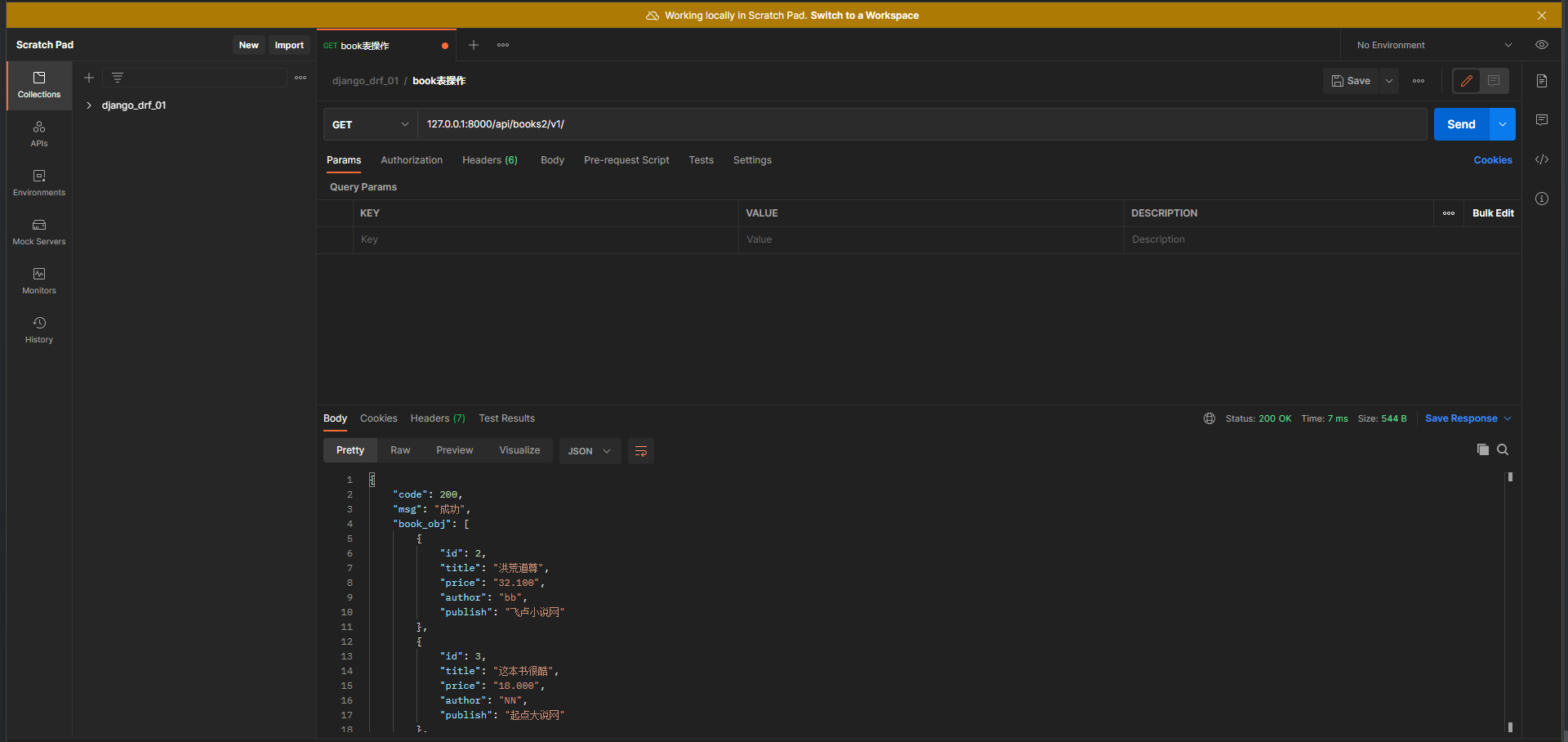
url( r'api/books2/v1/' , views. Book2View. as_view( ) )
* 3. 定义视图类中 , 在请求的方法中使用模型序列化器 .
class Book2View ( APIView) :
def get ( self, request) :
all_book_obj = Book. objects. all ( )
from app01. res import BookModelsSerializer
book_dic = BookModelsSerializer( instance= all_book_obj)
print ( book_dic)
res = MyResponse( )
back_dic = res. get_dict
back_dic. book_obj = book_dic. data
return Response( back_dic)
* 5. 在Postman中测试 :
请求方式 : get
请求地址 : 127.0 .0 .1 : 8000 /api/books2/v1/
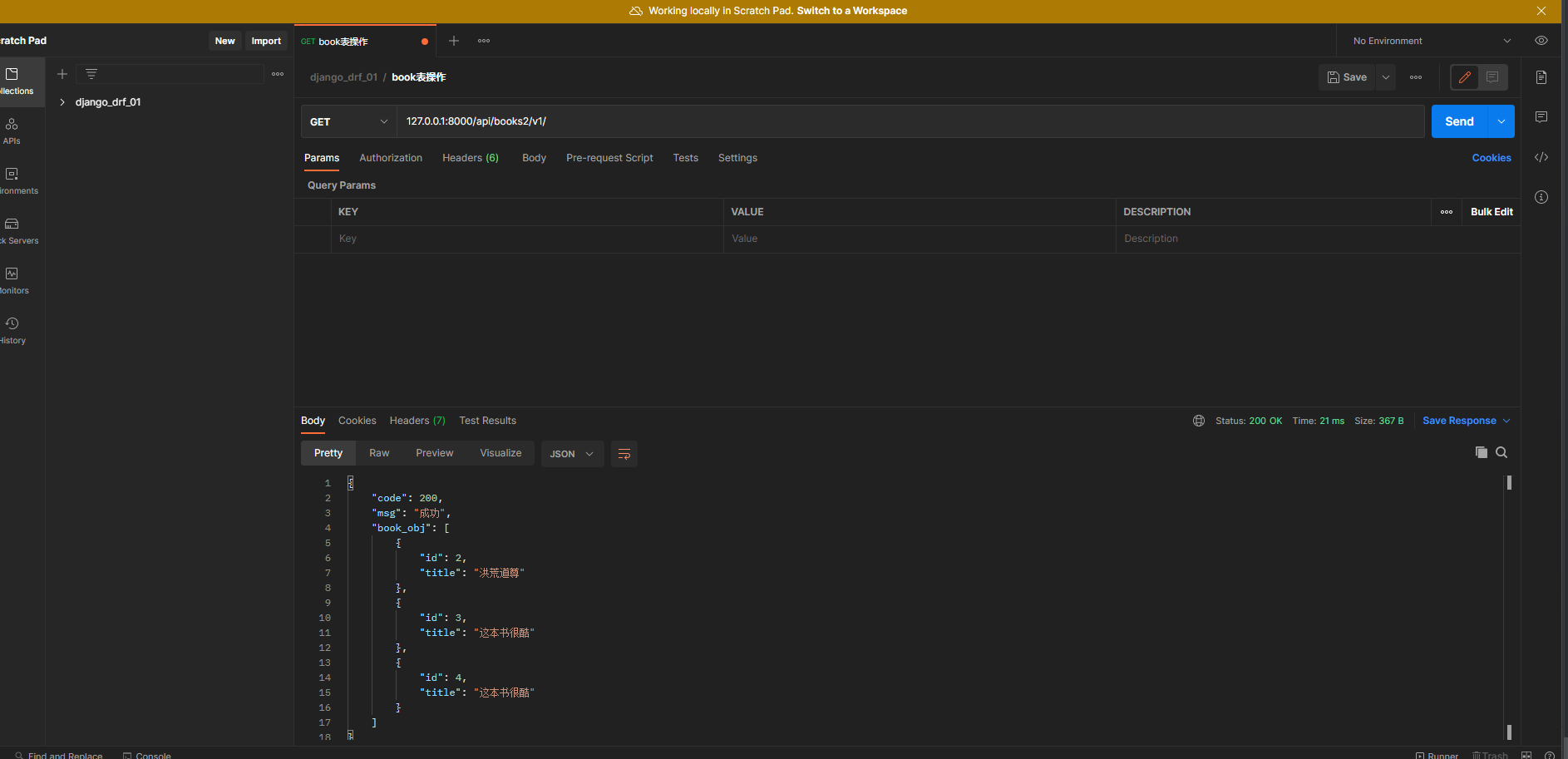
* 6. 指定字段转换
class BookModelsSerializer ( ModelSerializer) :
class Meta :
model = Book
fields = [ 'id' , 'title' ]
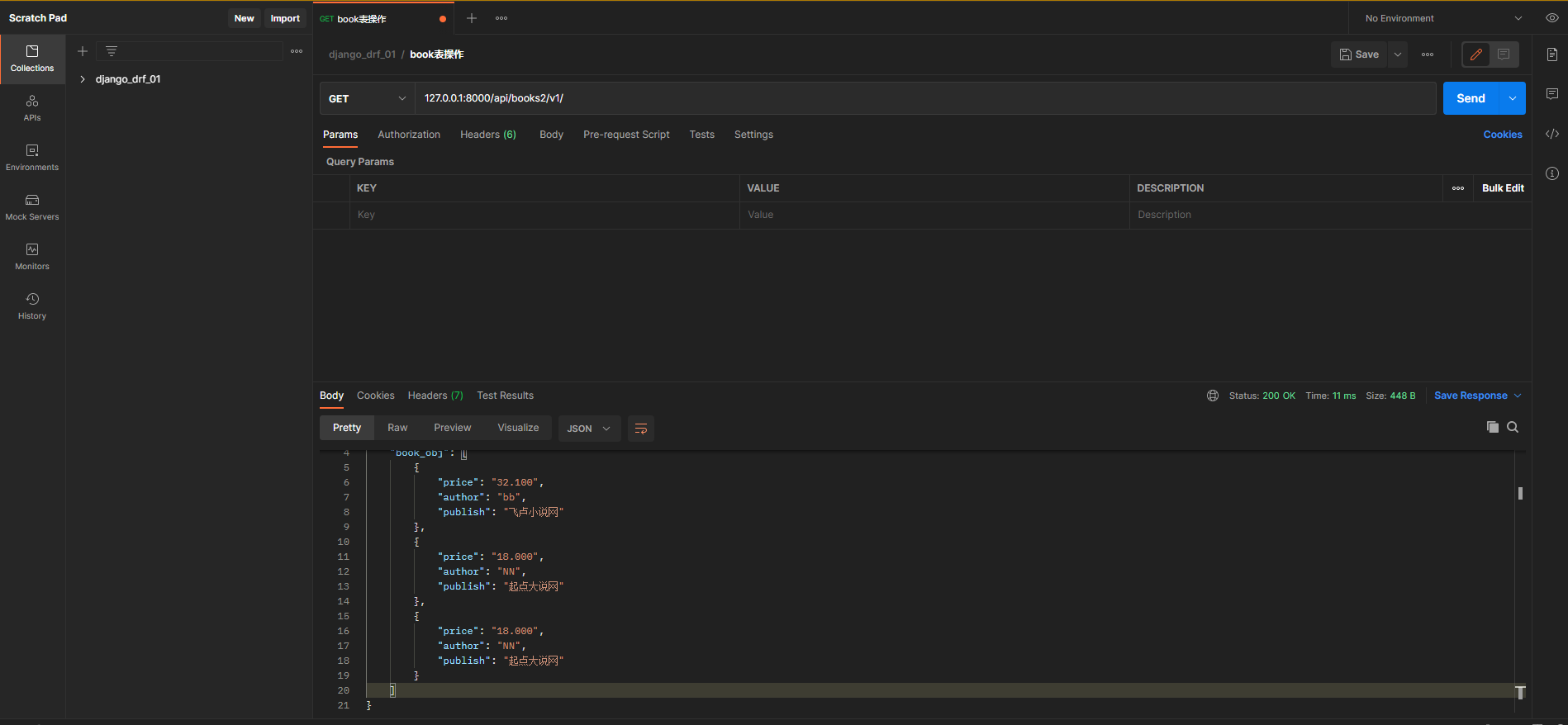
* 7. 排除字段
class BookModelsSerializer ( ModelSerializer) :
class Meta :
model = Book
exclude = [ 'id' , 'title' ]
* 8. 给字段添加限制条件
老版本是可以 write_only_fields = [ '字段1' , '字段2' ] 现在已经被禁用了 , 设置了不生效
id字段默认是开启了只读 , 就是在传给数据的时候id字段不需要传递参数 .
AssertionError : 不能同时设置 ` read_only ` 和 ` write_only `
class BookModelsSerializer ( ModelSerializer) :
class Meta :
model = Book
fields = '__all__'
extra_kwargs = {
'title' : {
'write_only' : True } ,
'price' : {
'write_only' : True }
}
* 9. 混合使用
class BookModelsSerializer ( ModelSerializer) :
title = serializers. CharField( write_only= True )
class Meta :
model = Book
fields = '__all__'
extra_kwargs = {
'title' : {
'write_only' : False } }
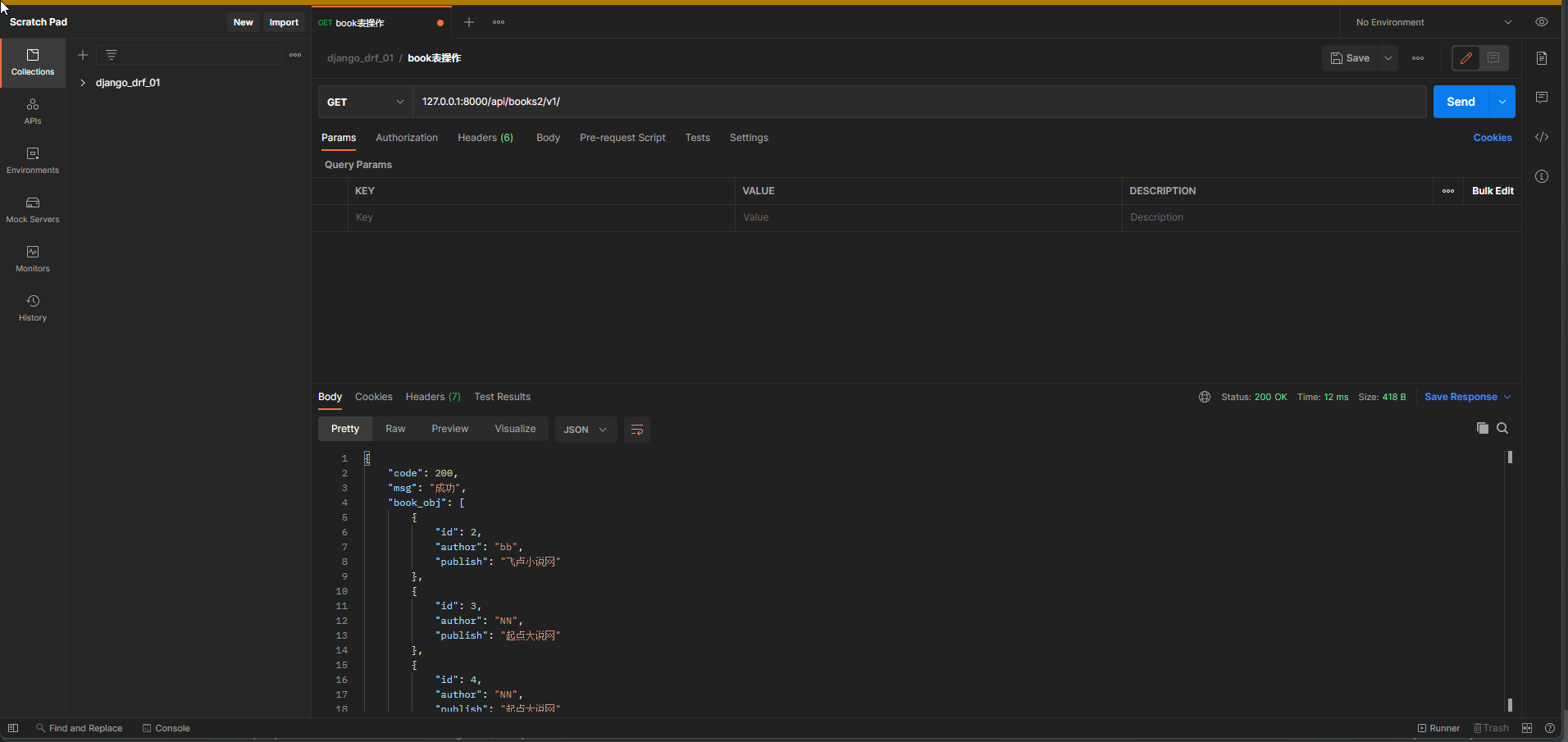
序列化组件的many关键字参数分析
* 1. 修改视图类 , 分类查单条数据和所有数据
class Book2View ( APIView) :
def get ( self, request) :
all_book_obj = Book. objects. all ( )
from app01. res import BookModelsSerializer
all_dic = BookModelsSerializer( instance= all_book_obj, many= True )
only_obj = Book. objects. first( )
only_dic = BookModelsSerializer( instance= only_obj)
print ( type ( all_dic) , type ( only_dic) )
res = MyResponse( )
res. book_obj = all_dic. data
back_dic = res. get_dict
return Response( back_dic)
mant = True < class 'rest_framework.serializers.ListSerializer' >
mant = False < class 'app01.res.BookModelsSerializer' >
类名加 ( )
1. 先调用__net__方法 , 生成空对象 ,
2. 在调用__init__方法 , 实例化为空对象添加属性
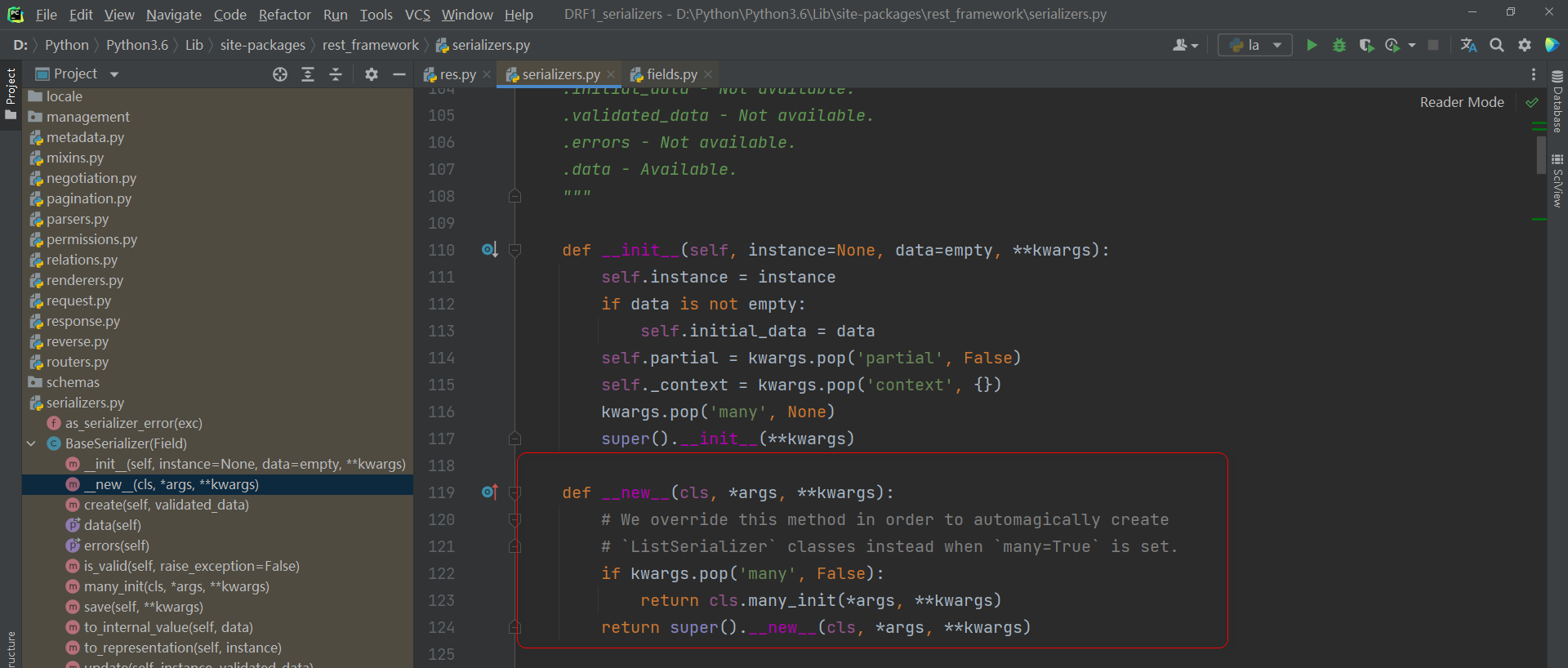
* 类的__net__方法控制了对象的生成
追溯__net__ ,
BaseSerializer有__new__
Serializer ( BaseSerializer )
ModelsSerializer ( Serializer )
BookModelsSerializer ( ModelsSerializer )
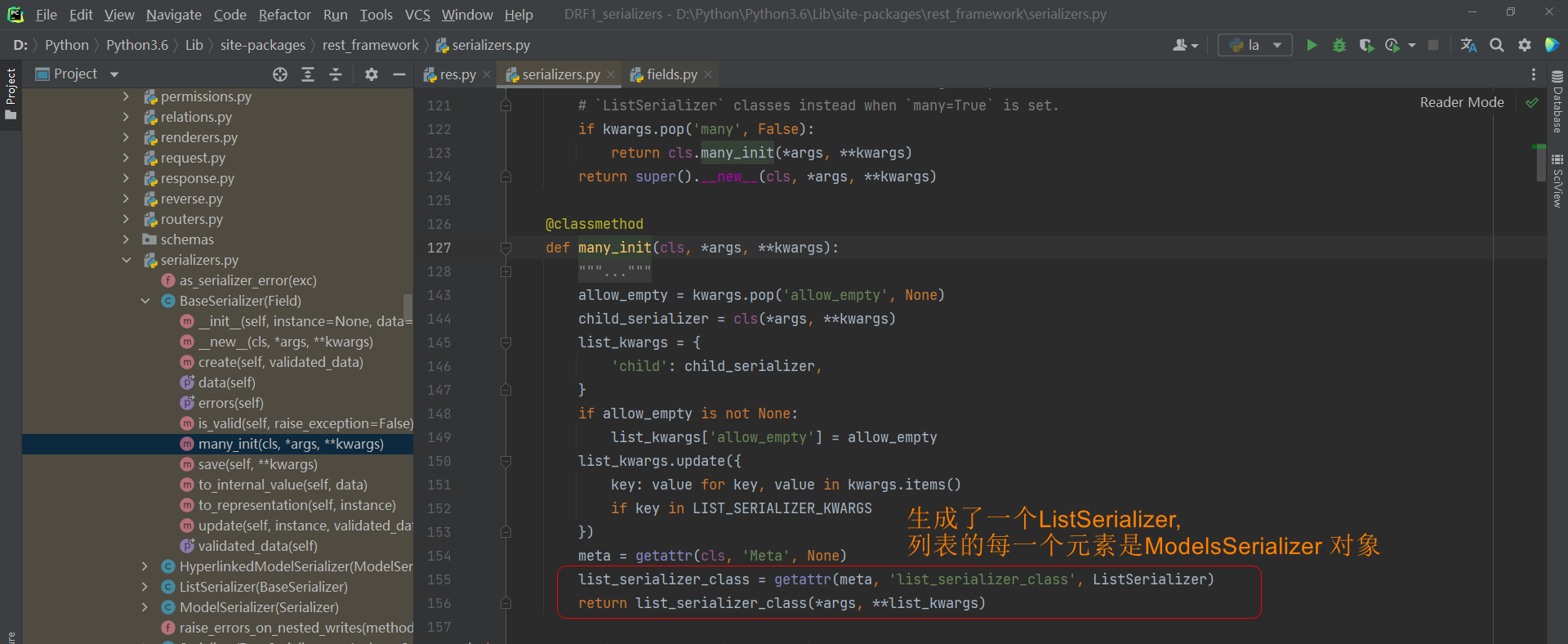
def __new__ ( cls, * args, ** kwargs) :
if kwargs. pop( 'many' , False ) :
return cls. many_init( * args, ** kwargs)
return super ( ) . __new__( cls, * args, ** kwargs)
* 1. 创建app02
python manage . py startapp app02
* 2. 注册app02
INSTALLED_APPS = [
. . .
'app02.apps.App02Config' ]
* 3. 路由分发
from django. conf. urls import url
from django. contrib import admin
from app01 import views
from django. conf. urls import include
from app02 import urls
urlpatterns = [
. . .
url( r'^api/app2/(?P<pk>\d+)/' , include( urls) )
]
* 4. app02项目下创建urls . py
from django. shortcuts import render
from rest_framework. views import APIView
from rest_framework. response import Response
class App2Book ( APIView) :
def get ( self, request, pk) :
return Response( {
'code' : 200 } )
* 5 . 创建表模型
from django. db import models
class Book ( models. Model) :
title = models. CharField( max_length= 32 , verbose_name= '书名' )
price = models. CharField( max_length= 32 , verbose_name= '价格' )
pub_date = models. DateField( )
publish = models. ForeignKey( 'Publish' , on_delete= models. CASCADE,
null= True , verbose_name= '关联出版社表' )
author = models. ManyToManyField( 'Author' , verbose_name= '关联作者表' )
def __str__ ( self) :
return self. title
class Publish ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '出版社名字' )
email = models. EmailField( verbose_name= '出版社邮箱' )
def __str__ ( self) :
return self. name
class Author ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '作者名字' )
email = models. EmailField( verbose_name= '作者邮箱' )
* 6. 生成表
生成表记录 python3 . 6 manage . py makemigrations app02
数据库迁移 python3 . 6 manage . py migrate app02
* 7. 在app02的texts . py中为表条件数据
from django. test import TestCase
import os
import sys
if __name__ == "__main__" :
os. environ. setdefault( "DJANGO_SETTINGS_MODULE" , "DRF1_serializers.settings" )
import django
django. setup( )
from app02 import models
models. Publish. objects. create( name= '起点小说网' , email= '[email protected] ' )
models. Publish. objects. create( name= '飞卢小说网' , email= '[email protected] ' )
models. Author. objects. create( name= 'kid' , email= '[email protected] ' )
models. Author. objects. create( name= 'qq' , email= '[email protected] ' )
import datetime
date = datetime. date( 2021 , 4 , 2 )
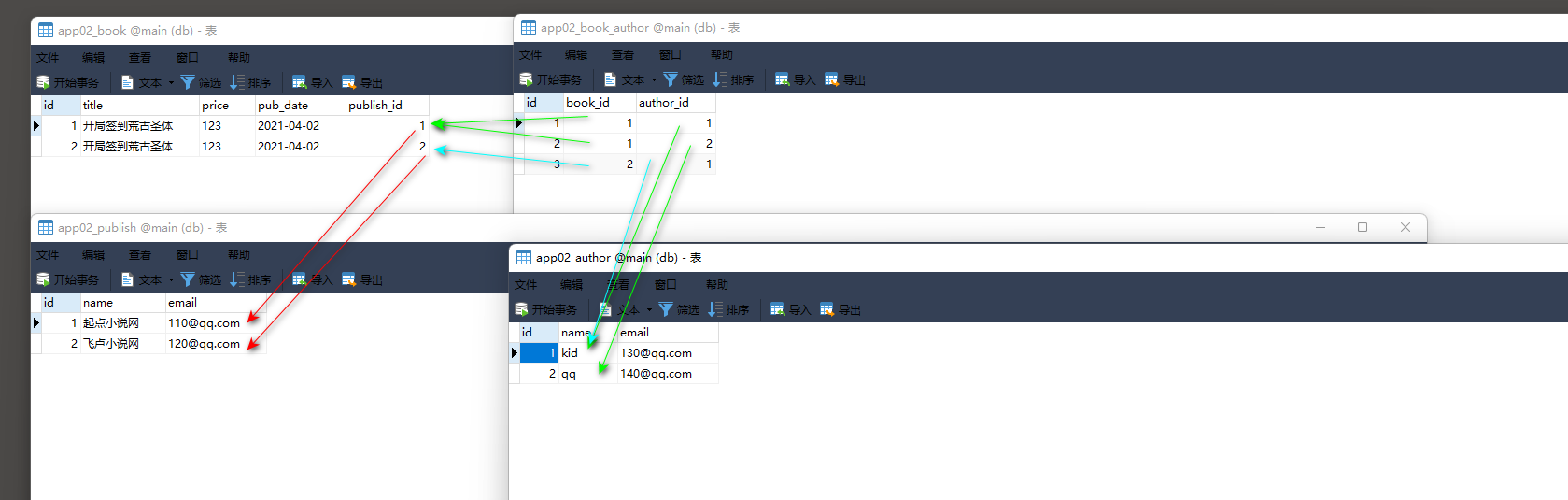
models. Book. objects. create( title= '开局签到荒古圣体' , price= 123 , pub_date= date, publish_id= 1 )
models. Book. objects. create( title= '开局签到荒古圣体' , price= 123 , pub_date= date, publish_id= 2 )
book1_obj = models. Book. objects. filter ( pk= 1 ) . first( )
book1_obj. author. add( 1 , 2 )
book2_obj = models. Book. objects. filter ( pk= 2 ) . first( )
book1_obj. author. add( 1 )
* 8. 创建序列化器
from rest_framework import serializers
from rest_framework. serializers import Serializer
class BookSerializer ( Serializer) :
id = serializers. CharField( )
title = serializers. CharField( )
price = serializers. CharField( )
pub_date = serializers. CharField( )
publish = serializers. CharField( )
* 9. 使用序列化器
from django. shortcuts import render
from rest_framework. views import APIView
from rest_framework. response import Response
from app02. res import BookSerializer
from app02 import models
from app01. request_msg import MyResponse
class App2Book ( APIView) :
def get ( self, request, pk) :
book_obj = models. Book. objects. filter ( pk= pk) . first( )
print ( book_obj)
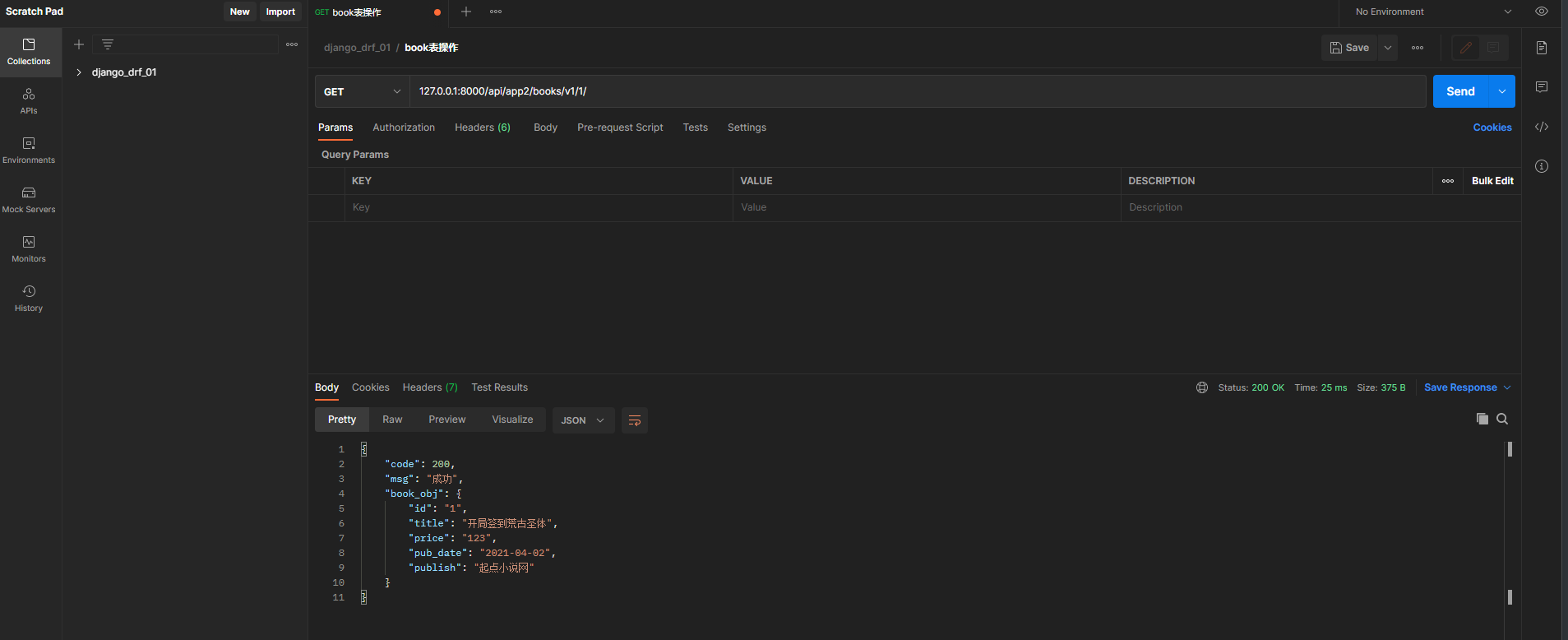
book_dic = BookSerializer( instance= book_obj)
res = MyResponse( )
res. book_obj = book_dic. data
back_dic = res. get_dict
print ( back_dic)
return Response( back_dic)
* 10. 在Postman中测试 :
请求方式 : get
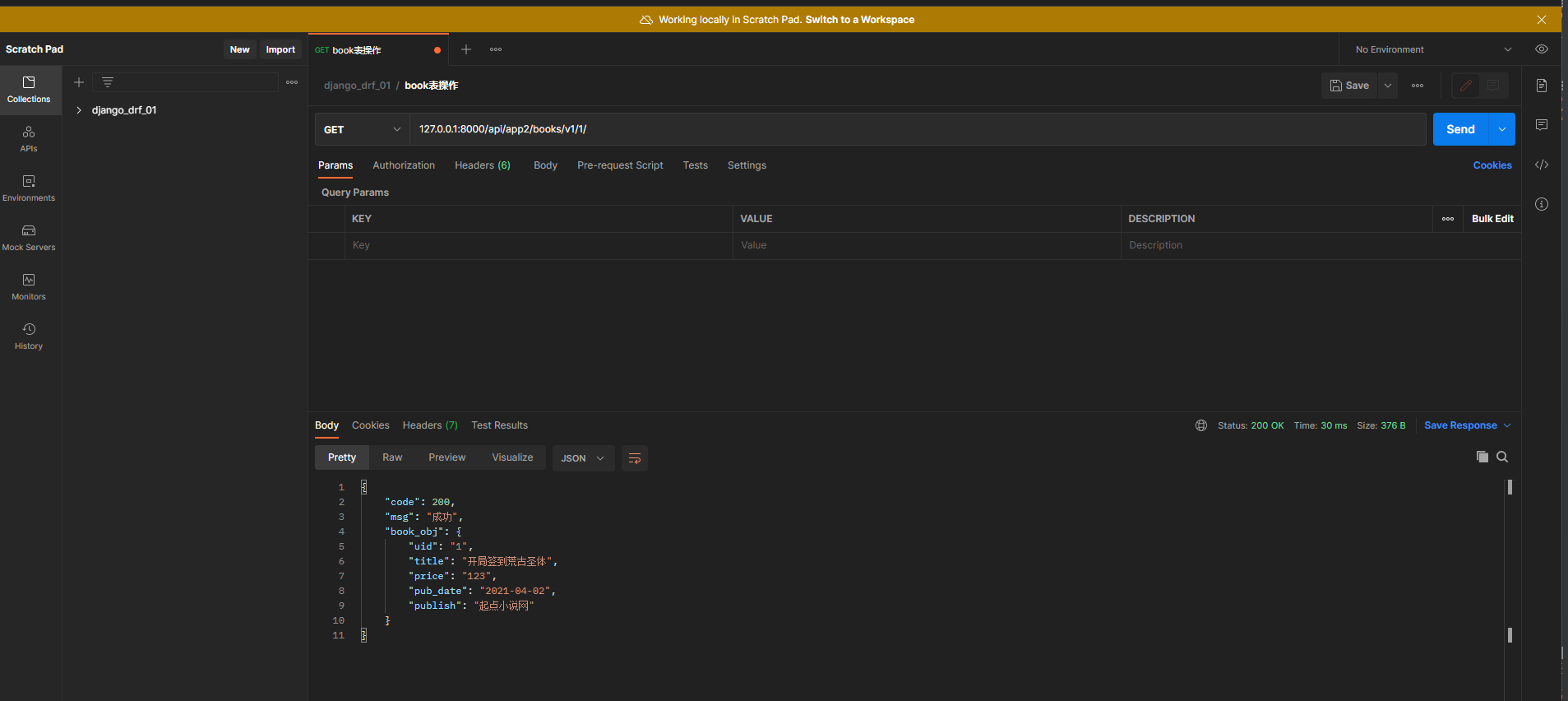
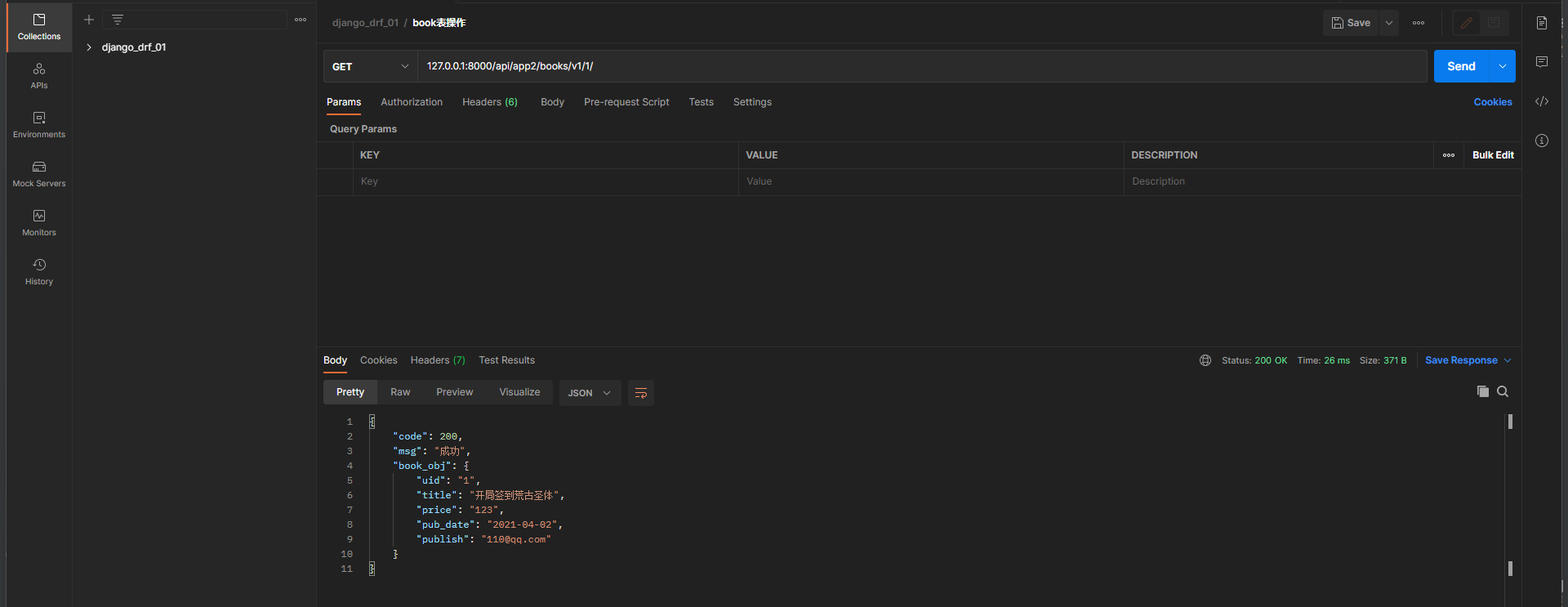
请求地址 : 127.0 .0 .1 : 8000 /api/app2/books/v1/ 1 /
转换Publish外键字段触发了Publisk的__str__方法
source字段作用 :
1. 起别名 : 返回的数据key值与数据库的不一致 .
2. 跨表查询 : 通过外键字段查询关联表的数据
3. 使用模型表的方法 : 使用表模型的方法 , 会自动加括号执行
自己返回的字段名不能和数据的字段名一样 , 这样很容易被被人攻击获取到数据 .
需要一种方式来处理 , 在字段类型后面的括号中设置source属性 ,
eg : 别名 = serializer . CharField ( source = '数据库存在的字段名' )
uid = serializers. CharField( source= 'id' )
跨表查询 , eg : pbulsh = serializers . CharField ( source = '外键字段.关联表的字段' )
publish = serializers. CharField( source= 'publish.email' )
在模型层的Book表中定义一个方法
class Book ( models. Model) :
. . .
def get_title ( self) :
return f'<< {
self. title} >>'
title = serializers. CharField( source= 'get_title' )
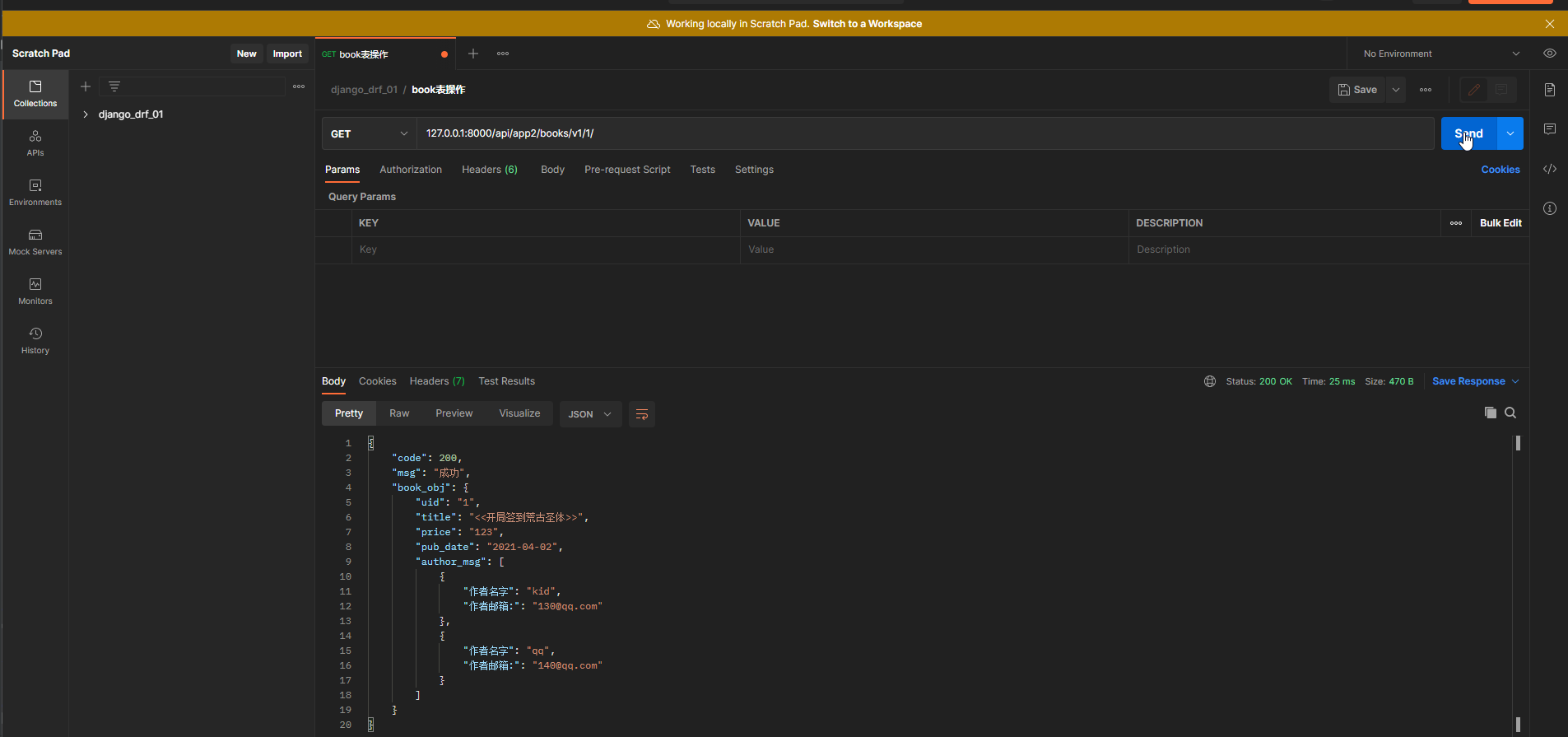
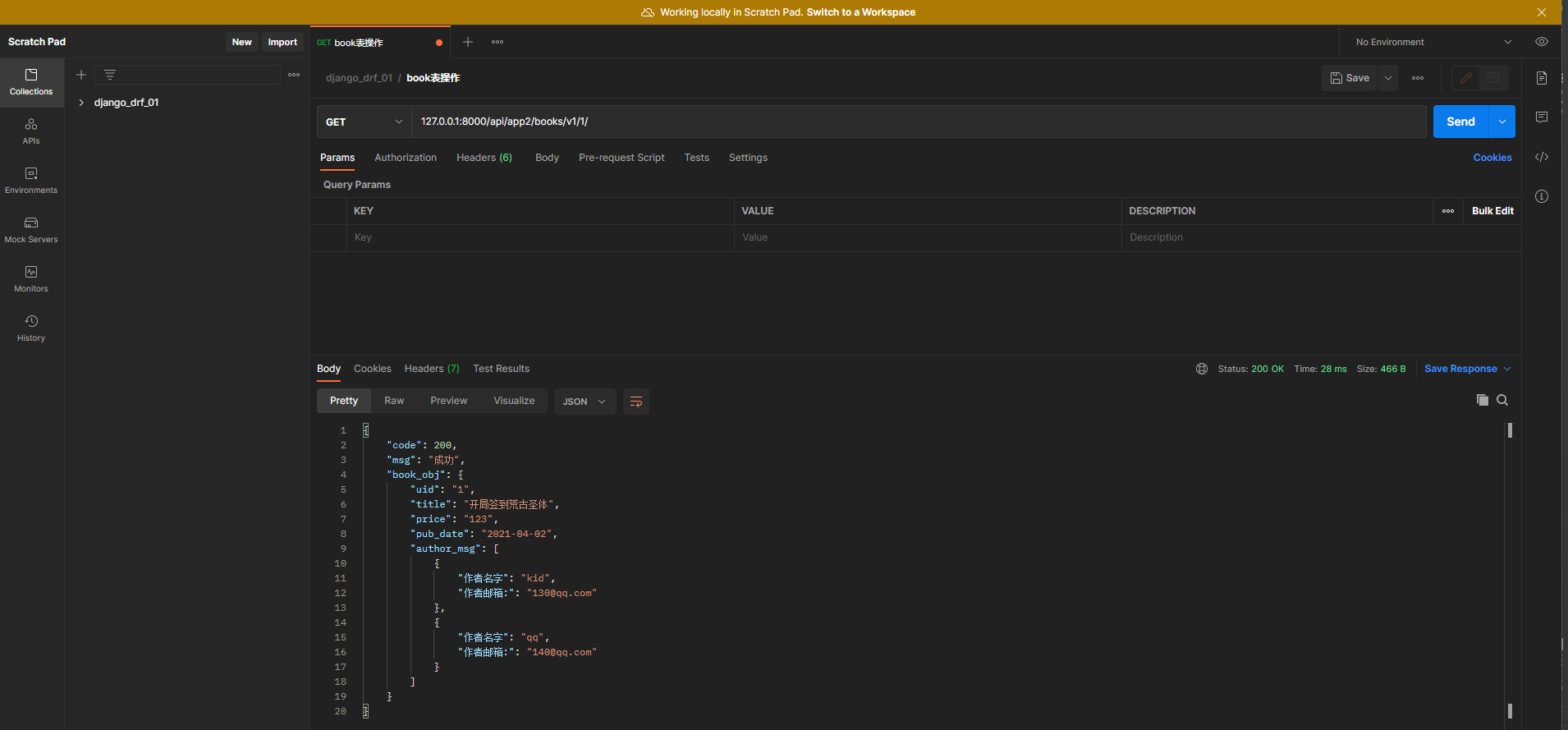
SerializerMethodField的使用配套一个方法 , 在该方法定义返回的数据 .
eg : 别名 = serializers . SerializerMethodField ( source = '外键字段/虚拟字段' )
绑定方法名字 : get_字段名 ( self , instance接收数据对象 ) , 字段名可以是别名 .
返回的数据 : return 该字段展示的信息 .
from rest_framework import serializers
from rest_framework. serializers import Serializer
class BookSerializer ( Serializer) :
uid = serializers. CharField( source= 'id' )
title = serializers. CharField( )
price = serializers. CharField( )
pub_date = serializers. CharField( )
author_msg = serializers. SerializerMethodField( source= 'author' )
def get_author_msg ( self, instance) :
all_author_obj = instance. author. all ( )
l1 = [ ]
for author_obj in all_author_obj:
l1. append( {
'作者名字' : author_obj. name, '作者邮箱:' : author_obj. email} )
return l1
修改app01中res . py的模型序列化类 .
单独对字段经常操作 , 在上面定义字段之后 , 将Meta中的字段覆盖 .
class BookModelsSerializer ( ModelSerializer) :
title1 = serializers. CharField( source= 'author' )
class Meta :
model = Book
fields = '__all__'
* 1. 新建项目编写查增改删四个接口 .
* 2. 表模型 & 创建表
class Book ( models. Model) :
id = models. AutoField( primary_key= True , verbose_name= '主键' )
title = models. CharField( max_length= 32 , verbose_name= '书名' )
author = models. CharField( max_length= 32 , verbose_name= '作者' )
python3 . 6 manage . py makemigrations
python3 . 6 manage . py migrate
删 , 改 , 查单个数据都需要一个携带一个主键 , 查全部 , 增不需要 .
增 , 查全部使用一个路由 , 删改查单条数据使用一个路由 .
from django. conf. urls import url
from django. contrib import admin
from app01 import views
urlpatterns = [
url( r'^admin/' , admin. site. urls) ,
url( r'^api/books/v1/$' , views. BookAPI1. as_view( ) ) ,
url( r'^api/books/v1/(?P<pk>\d+)/' , views. BookAPI2. as_view( ) ) ,
]
在app01下创建一个 response_msg . py文件
class BackMsg ( object ) :
def __init__ ( self, code, msg, data) :
self. code = code
self. msg = msg
self. data = data
@property
def get_data ( self) :
return self. __dict__
from django. shortcuts import render
from rest_framework. views import APIView
from rest_framework. response import Response
from app01. response_msg import BackMsg
class BookAPI1 ( APIView) :
def get ( self, request) :
back_msg = BackMsg( 200 , '查询成功' , None )
return Response( back_msg. get_data)
def post ( self, request) :
back_msg = BackMsg( 200 , '增加成功' , None )
return Response( back_msg. get_data)
class BookAPI2 ( APIView) :
def get ( self, request, pk) :
back_msg = BackMsg( 200 , '查询成功' , None )
return Response( back_msg. get_data)
def put ( self, request, pk) :
back_msg = BackMsg( 200 , '修改成功' , None )
return Response( back_msg. get_data)
def delete ( self, request, pk) :
back_msg = BackMsg( 200 , '删除成功' , None )
return Response( back_msg. get_data)
127.0.0.1:8000/api/books/v1/
在app01下创建一个 my_serialize . py文件
from rest_framework import serializers
class BookSerializer ( serializers. Serializer) :
book_id = serializers. IntegerField( source= 'id' )
book_title = serializers. CharField( source= 'title' )
author_name = serializers. CharField( source= 'author' )
获取用户提交的数据 , 将用户提交的数据反序列化检验数据 .
0. 数据不能为空 , 默认的
1. 局部钩子函数检验 已经存在的书籍不能添加 .
1. 全局钩子函数检验 书名不能与作者名一样 .
局部钩子的名字以别名为主 ,
全局函数的接收检验合格是数据是一个有序字段 , 字段的键还是表的字段 .
OrderedDict ( [ ( '字段名1' , '值' ) , ( '字段名2' , '字段' ) ] )
在写creat方法与update方法 , 检验合格是数据一个普通的字典
{
'字段名1' : '值' , '字段名2' : '值' }
最后返回数据的时候序列化器对象的 . data数据就是一个普通的字典 .
{
'字段名1' : '值' , '字段名2' : '值' }
如果是创建值 , 或修改值 , 是需要返回数据对象的 , 这个值被列化器对象的 . data接收 ,
在没有写这两个方法且没有返回数据对象会报错 , . save之前不能使用 . data
使用序列化器时 :
序列化类 ( data = request . data ) 会触发校验 . 必须执行is_vaild ( ) 方法 ,
在使用 . save ( ) 会触发父类规范子类的行为 , 序列化类中必须实现create方法 .
序列化类 ( instance = obj , data = request . data ) 会触发校验 . 必须执行is_vaild ( ) 方法 ,
在使用 . save ( ) 会触发父类规范子类的行为 , 序列化类中必须实现update方法 .
* 1. 视图函数
class BookAPI1 ( APIView) :
. . .
def post ( self, request) :
post_dic = BookSerializer( data= request. data)
if post_dic. is_valid( ) :
post_dic. save( )
back_msg = BackMsg( 200 , '增加成功' , post_dic. data)
else :
error_msg = post_dic. errors
back_msg = BackMsg( 100 , error_msg, None )
return Response( back_msg. get_data)
from rest_framework import serializers
from rest_framework. exceptions import ValidationError
from app01 import models
class BookSerializer ( serializers. Serializer) :
book_id = serializers. IntegerField( source= 'id' , read_only= True )
book_title = serializers. CharField( source= 'title' )
author_name = serializers. CharField( source= 'author' )
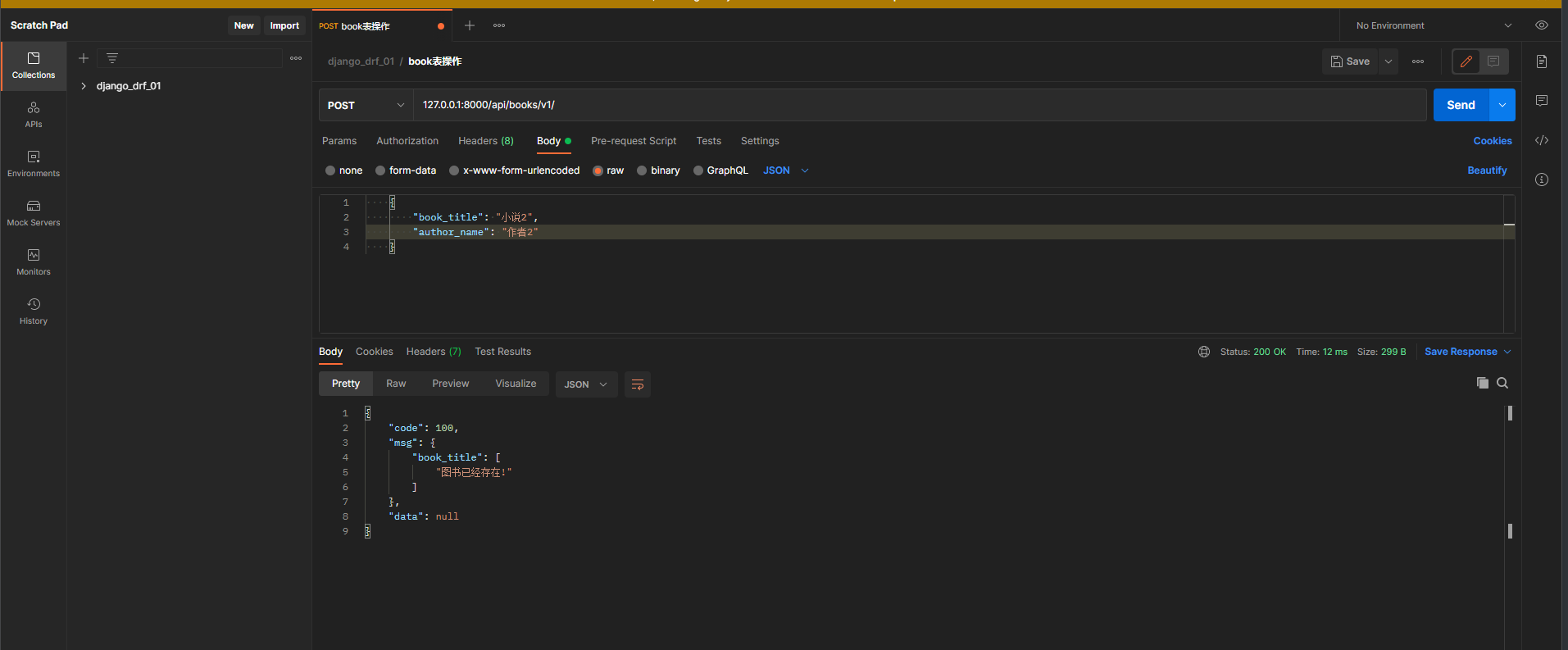
def validate_book_title ( self, data) :
book_obj = models. Book. objects. filter ( title= data) . first( )
if book_obj:
raise ValidationError( '图书已经存在!' )
return data
def validate ( self, validate_data) :
print ( validate_data)
title = validate_data. get( 'title' )
author = validate_data. get( 'author' )
if title != author:
return validate_data
else :
raise ValidationError( '书名与作者名同名' )
def create ( self, instance) :
print ( instance)
book_obj = models. Book. objects. create( ** instance)
return book_obj
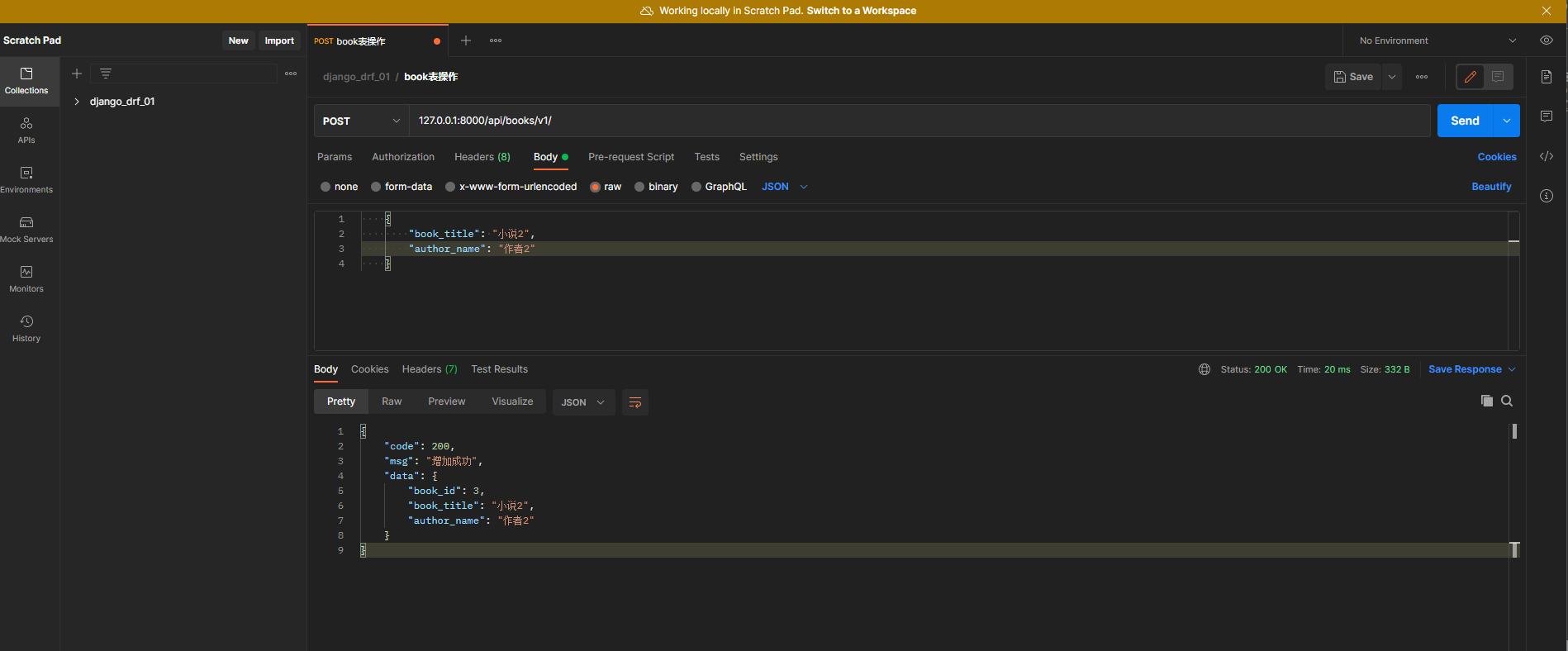
在Postman中测试 :
请求方式 : POST
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/
数据格式 : raw-JSON
提交数据 :
{
"book_title" : "小说2" ,
"author_name" : "作者2"
}
重复提交
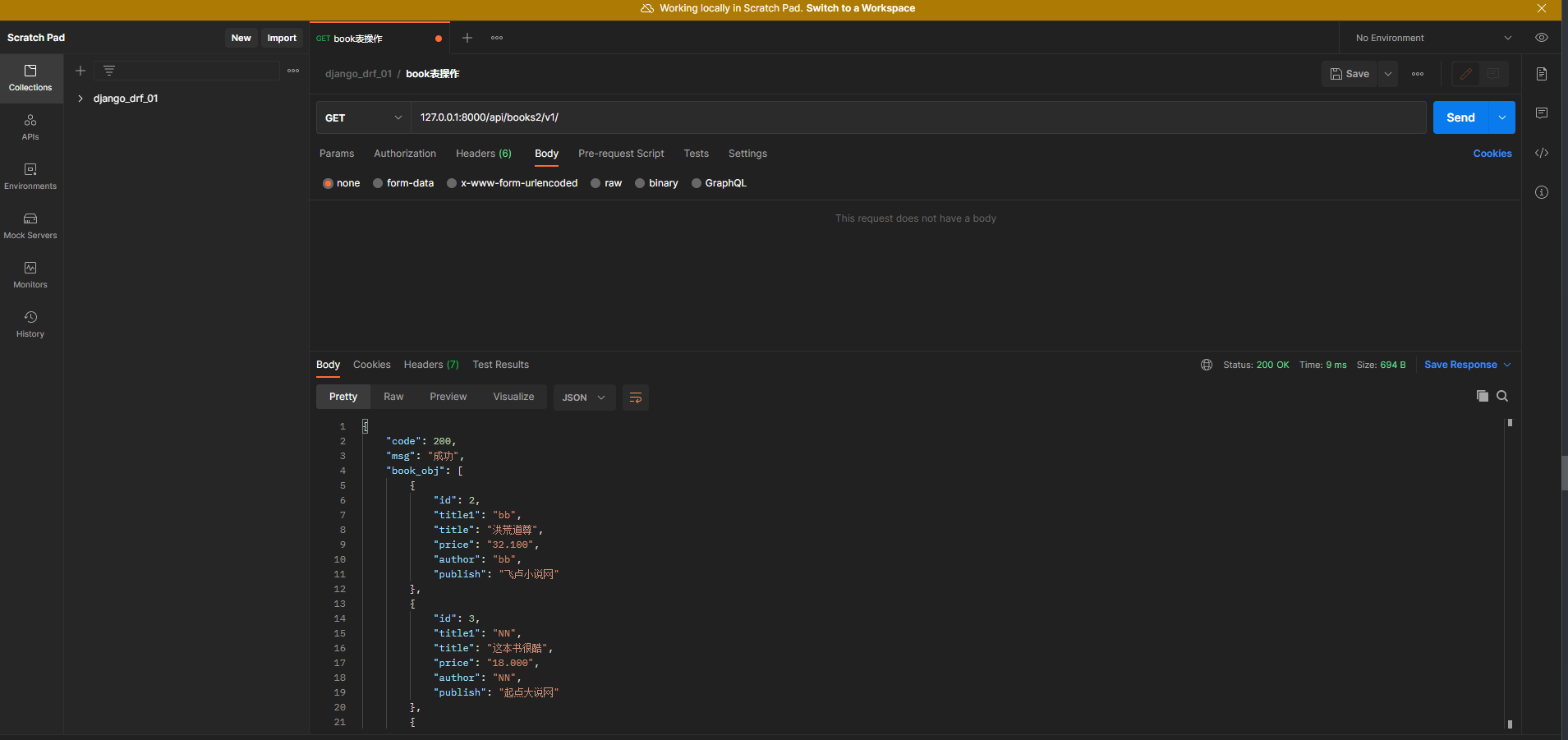
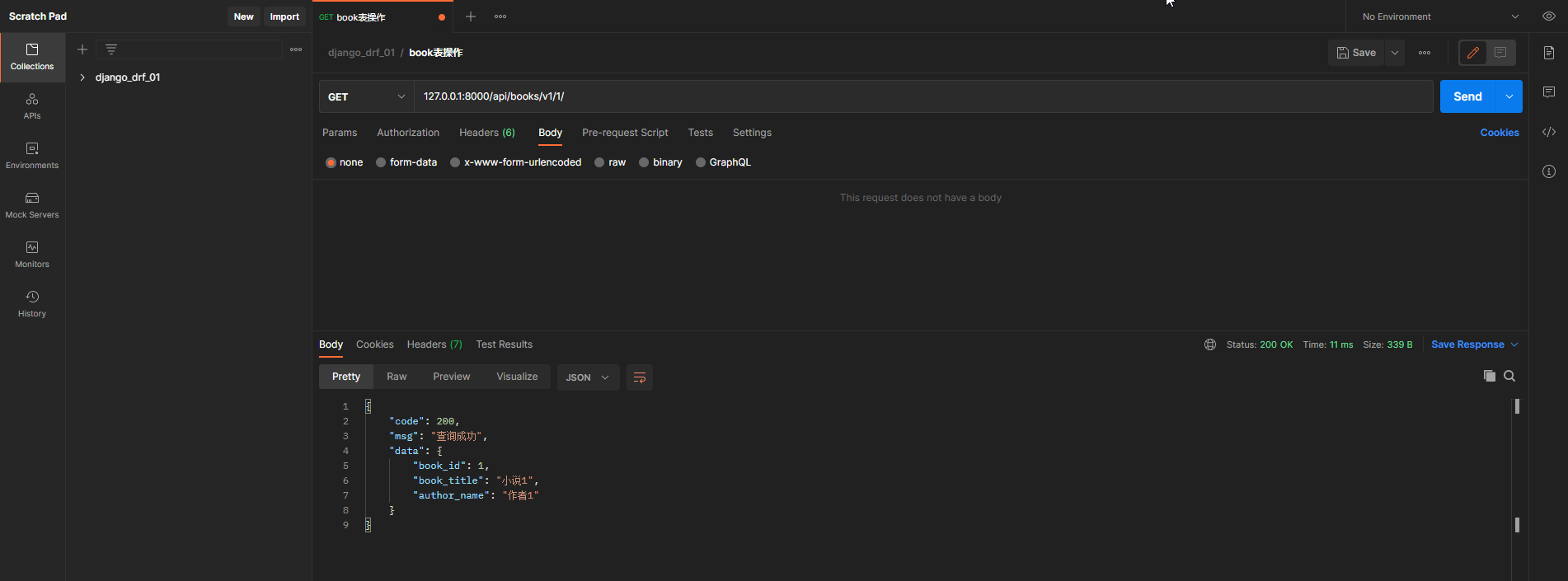
查所有
from app01. models import Book
class BookAPI1 ( APIView) :
def get ( self, request) :
all_obj = Book. objects. all ( )
if all_obj:
get_dic = BookSerializer( instance= all_obj, many= True )
back_msg = BackMsg( 200 , '查询成功' , get_dic. data)
else :
back_msg = BackMsg( 200 , '查询成功' , '没有值' )
return Response( back_msg. get_data)
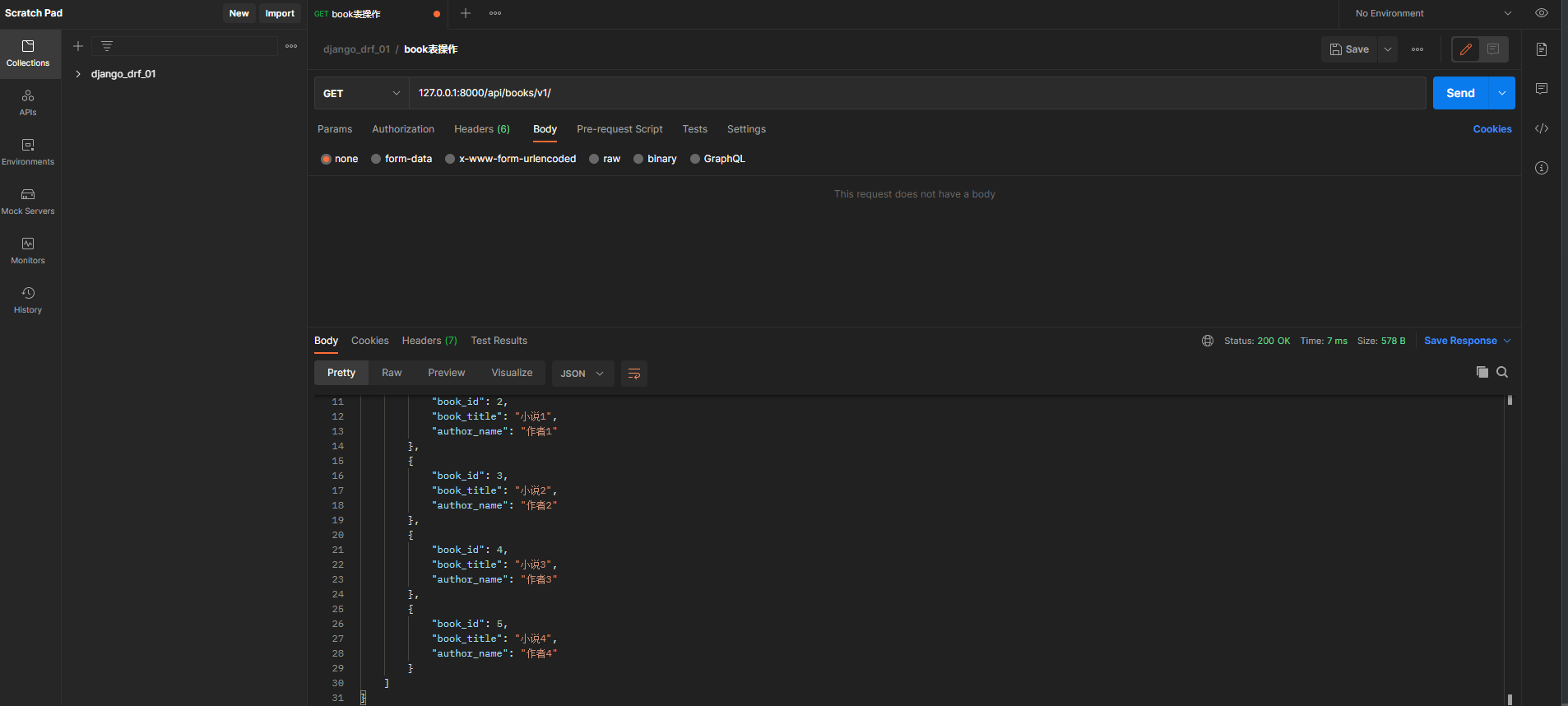
在Postman中测试 :
请求方式 : GET
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/
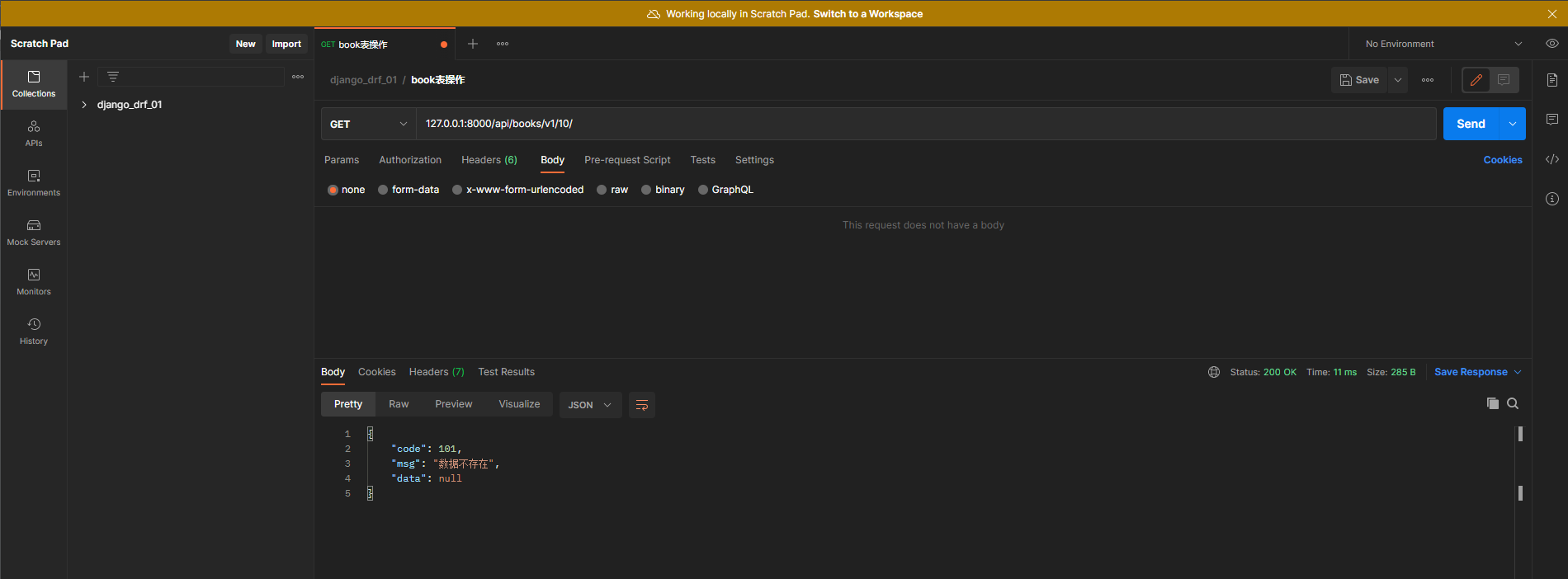
单独查
class BookAPI2 ( APIView) :
def get ( self, request, pk) :
book_obj = Book. objects. filter ( pk= pk) . first( )
if book_obj:
book_dic = BookSerializer( instance= book_obj)
back_msg = BackMsg( 200 , '查询成功' , book_dic. data)
else :
back_msg = BackMsg( 101 , '数据不存在' , None )
return Response( back_msg. get_data)
在Postman中测试 :
请求方式 : GET
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
查询不存在的书籍
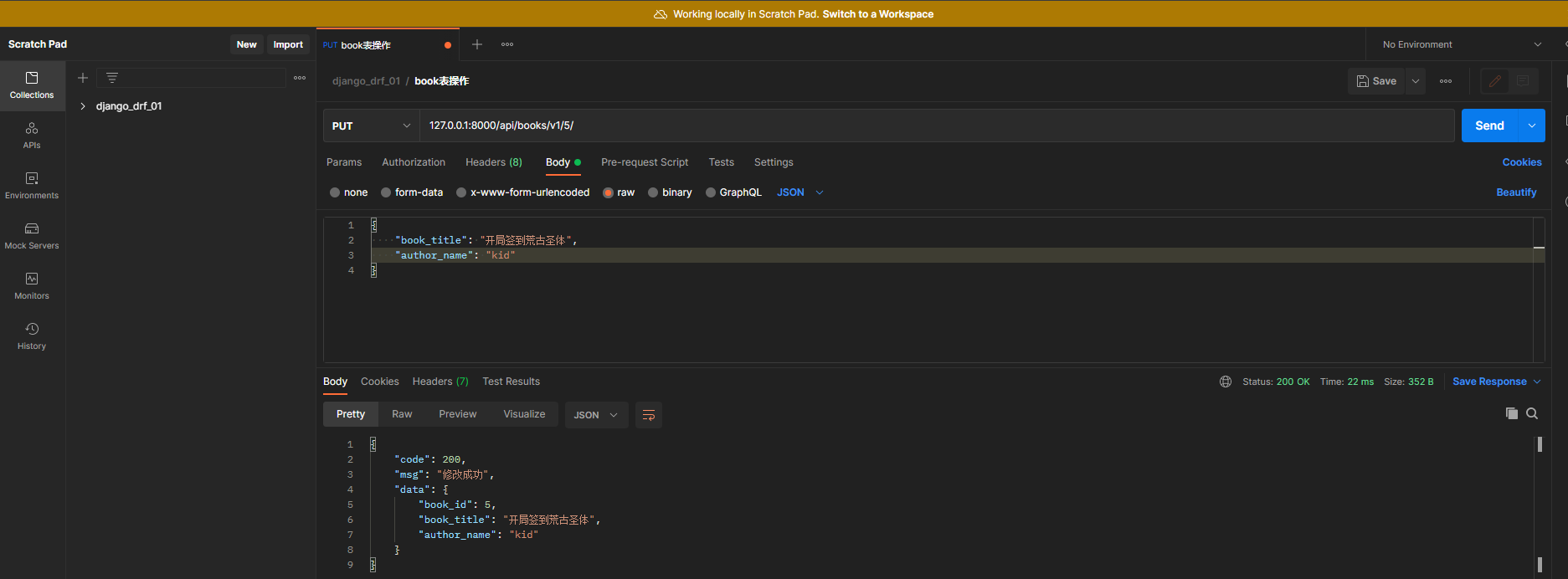
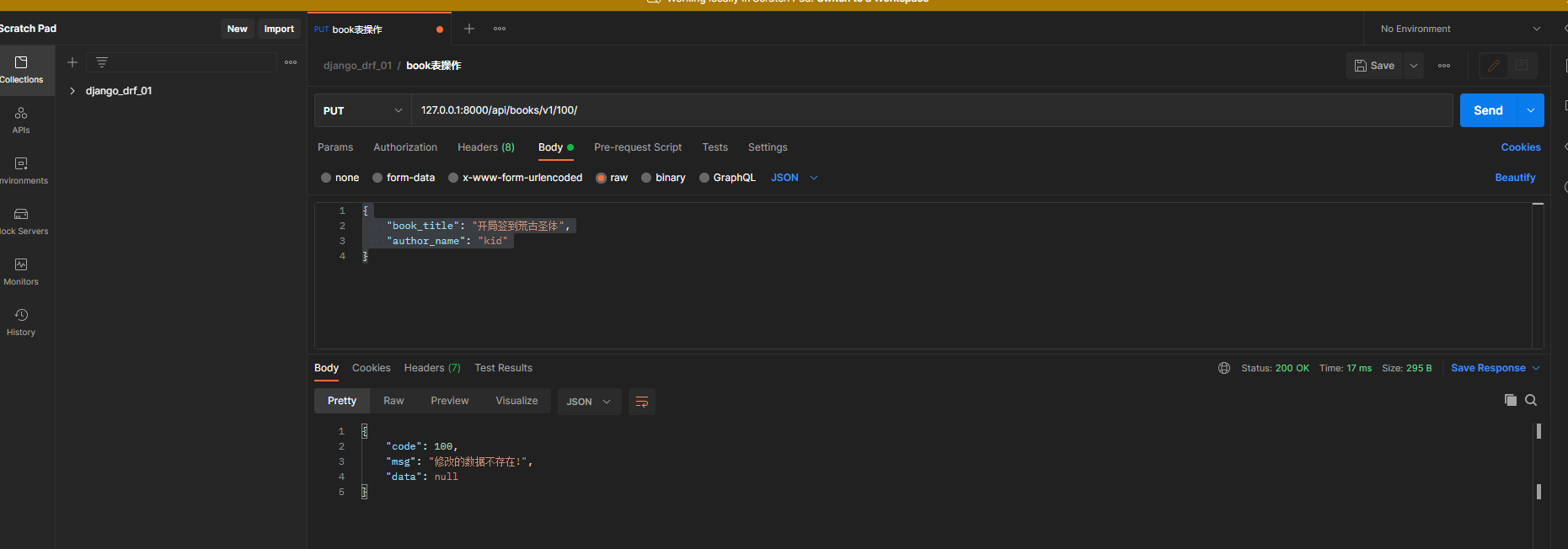
def put ( self, request, pk) :
book_obj = Book. objects. filter ( pk= pk) . first( )
if book_obj:
book_dic = BookSerializer( instance= book_obj, data= request. data)
if book_dic. is_valid( ) :
book_dic. save( )
back_msg = BackMsg( 200 , '修改成功' , book_dic. data)
else :
back_msg = BackMsg( 100 , book_dic. errors, None )
else :
back_msg = BackMsg( 100 , '修改的数据不存在!' , None )
return Response( back_msg. get_data)
def update ( self, instance, validated_data) :
print ( instance, validated_data)
for key, value in validated_data. items( ) :
setattr ( instance, key, value)
instance. save( )
return instance
在Postman中测试 :
请求方式 : put
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 5 /
数据格式 : raw-JSON
提交数据 :
{
"book_title" : "开局签到荒古圣体" ,
"author_name" : "kid"
}
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 100 /
def delete ( self, request, pk) :
del_num = Book. objects. filter ( pk= pk) . delete( )
if del_num[ 0 ] :
back_msg = BackMsg( 200 , '删除成功' , None )
else :
back_msg = BackMsg( 100 , '删除的值不存在!' , None )
return Response( back_msg. get_data)
在Postman中测试 :
请求方式 : delete
请求地址 : 127.0 .0 .1 : 8000 /api/books/v1/ 1 /
删除不存在的值