初级问题
主键用数字 or UUID?
UUID 是通用唯一识别码的缩写,其目的是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。在数据库集群中,为了避免每个MySQL各自生成的主键产生重复,所以有人考虑采用UUID方式。
使用UUID的好处
- 使用UUID,分布式生成主键,降低了全局节点的压力,使得主键生成速度更快
- 使用UUID生成的主键值全局唯一
- 跨服务器合并数据很方便
UUID主键的缺点
- UUID占用16个字节,比4字节的INT类型和8字节的BIGINT类型更加占用存储空间
- UUID是字符串类型,查询速度很慢
- UUID不是顺序增长,作为主键,数据写入IO随机性很大
主键自动增长的优点
- INT和BIGINT类型占用存储空间较小
- MySQL检索数字类型速度远快过字符串
- 主键值是自动增长的,所以IO写入连续性较好
无论什么场合,都不推荐使用UUID作为数据表的主键,而是要利用数据库中间件来生成全局主键
在线修改表结构
使用PerconaTookit工具
安装依赖包

使用方法
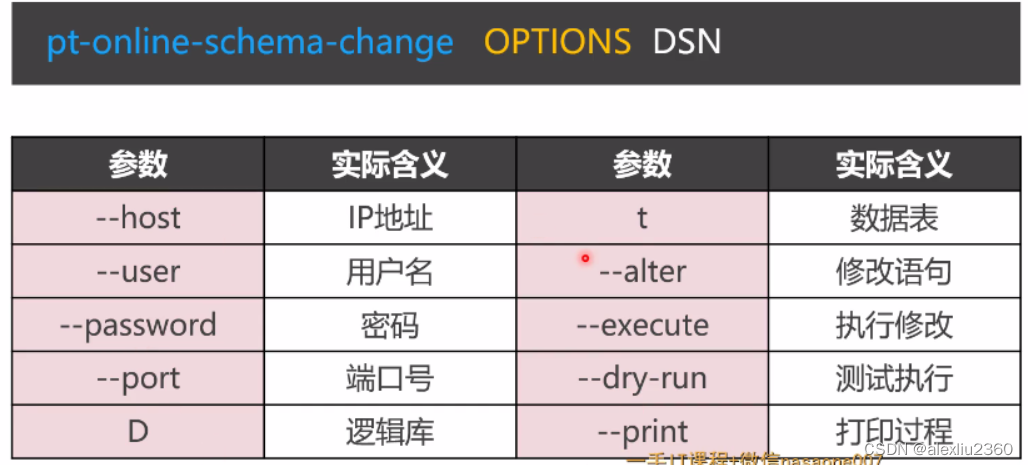
pt-online-schema-change OPTIONS DNS

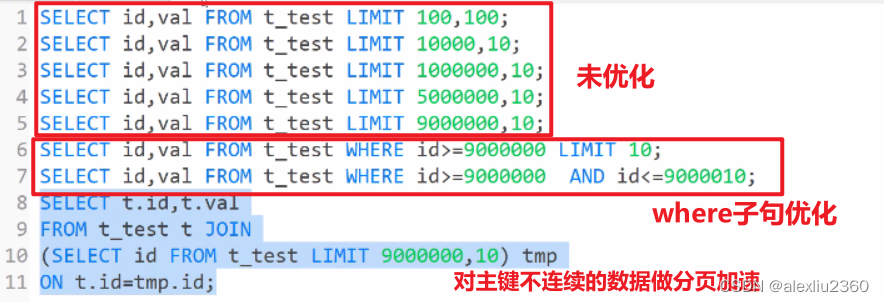
分页加速方法
订单号和流水号区别
- 订单号既是订单的唯一编号,而且经常被用来检索,所以应当是数字类型的主键
- 流水号是打印在购物单据上的字符串,便于阅读,但是不用做查询
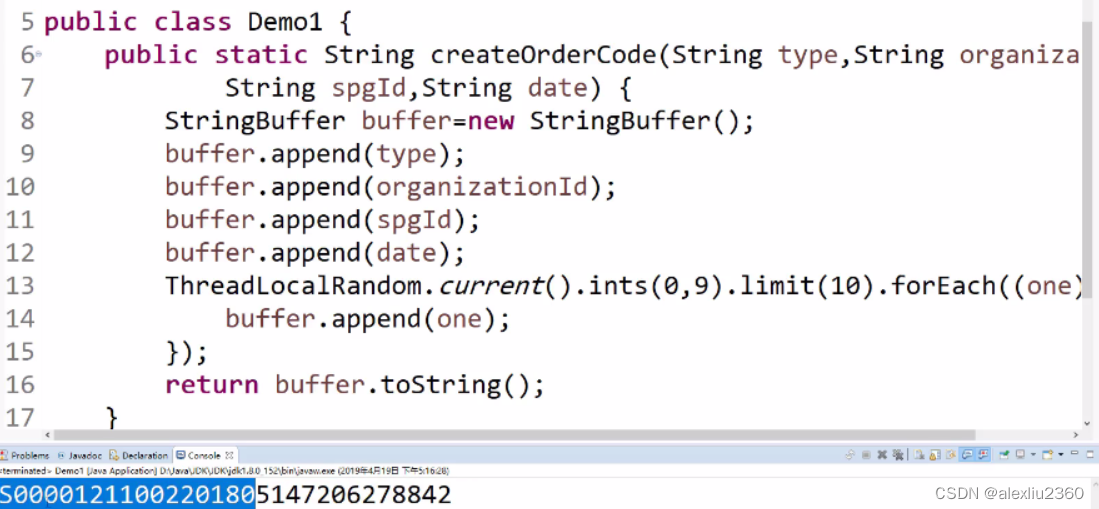
package dev.demo.test1;
import java.util.concurrent.ThreadLocalRandom;
public class Demo1 {
public static String createOrderCode(String type,String organizationId,
String spgId,String date) {
StringBuffer buffer=new StringBuffer();
buffer.append(type);
buffer.append(organizationId);
buffer.append(spgId);
buffer.append(date);
ThreadLocalRandom.current().ints(0,9).limit(10).forEach((one)->{
buffer.append(one);
});
return buffer.toString();
}
public static void main(String[] args) {
String code=createOrderCode("S", "000012", "11002", "20180514");
System.out.println(code);
}
}
逻辑删除or物理删除
物理删除
- 物理删除就是用DELETE、TRUNCATE、DROP语句删除数据。
- 物理删除是把数据从硬盘中删除,可以释放存储空间,缩小数据表的体积,对性能提升有帮助
- 物理删除会造成主键的不连续,导致分页查询变慢
核心业务表的数据不建议做物理删除,只做状态变更。
比如订单作废、账号禁用、优惠券作废等等。既不删除数据,又能缩小数据表体积,可以把记录转移到历史表。
逻辑删除就是在数据表添加一个字段(is_deleted),用字段值标记该数据已经逻辑删除,查询的时候跳过这些数据
创建历史表(克隆)
create table t_emp_history like t_emp;
读多写少 & 读少写多
读多写少:看的多,写的少
- 电商
- 新闻
- 论坛
- 在线教育
读少写多:看的少,写的多
- 滴滴专车
写多读多:使用NoSQL
- 微信
读多写少的解决方案
- 可以把MySQL组建集群,并且设置上读写分离
写多读少的解决方案
- 如果是低价值的数据,可以采用NoSQL数据库来存储这些数据,比如每天的打卡信息
- 如果是高价值的数据,可以用TokuDB来保存,比如刷卡消费,是innoDB的9~20倍
数据库集群
- 支持更大规模的并发访问,并且存放更多的数据
- 但是增加开销时间,节点访问较慢
删除数据避免锁表
共享锁
排他锁
-- sql console1
begin;
select * from t_test where id<=10 lock in share mode; -- 共享锁
commit;
-- sql console2
begin;-- 开始事务
updata t_test sel val="abc" where id < 10;
commit; -- 提交事务
rollback; -- 回滚事务
在并发环境下,如果多个客户端访问同一条数据,此时就会产生数据不一致的问题,如何解决,通过加锁的机制,常见的有两种锁,乐观锁和悲观锁,可以在一定程度上解决并发访问。
乐观锁,顾名思义,对加锁持有一种乐观的态度,即先进行业务操作,不到最后一步不进行加锁,"乐观"的认为加锁一定会成功的,在最后一步更新数据的时候在进行加锁,乐观锁的实现方式一般为每一条数据加一个版本号,更新数据的时候,比较版本号,系统就知道有没有出现数据的并发更新。如果小于等于当前版本号的更新,都会被放弃。
进阶问题
商品秒杀过程
预防超售现象
-
设置数据库事务的隔离级别serializable

-
在数据表上设置乐观锁字段
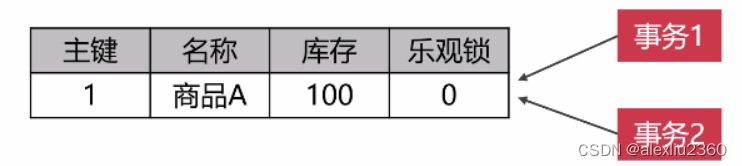
- 事务1在update前,事务2抢先update,导致乐观锁变为1
- 事务1在update时,比较乐观锁是否为0,如果不为0,则不进行update
- 设置乐观锁的场景
- 同时修改同一条记录的业务,相应的数据表要设置乐观锁,如库存表
- 不会出现修改同一条记录的话,就不需要,如:用户表、商品表、订单表、地址表
-
利用redis预防
- redis读写性能2w/s,mysql读5k/s,写3k/s
- 单线程的NoSQL,采用非阻塞执行
- redis引入批处理机制,一次性把命令给执行完
redis事务机制
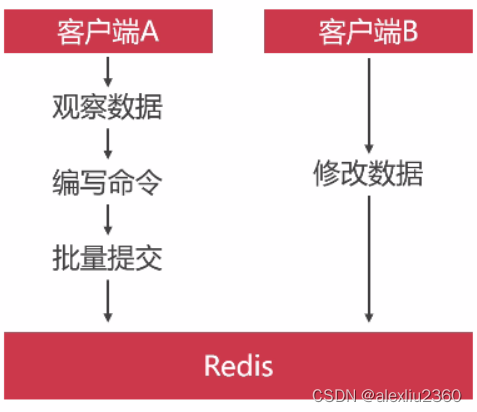
- 开启事务之前,需要使用watch命令监视要操作的记录:
wacth kill_num kill_user - 开启事务,
multi - 开启事务后的所有操作不会立即执行,只有执行EXEC才会批处理执行:
DESC kill_num
RPUSH kill_user 9502
EXEC
redis事务成功
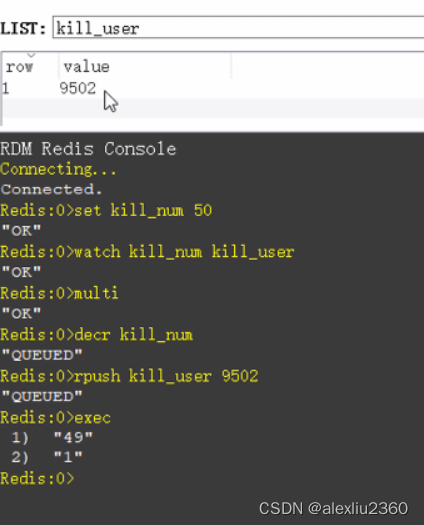
redis事务失败
![https://img-blog.csdnimg.cn/img_convert/d25f8bbf9eba294e8ed1a35a1790d3b1.png#clientId=u14c920c0-1c5a-4&crop=0&crop=0&crop=1&crop=1&from=paste&height=303&id=ude2edc33&margin=[object Object]&name=image.png&originHeight=351&originWidth=355&originalType=binary&ratio=1&rotation=0&showTitle=false&size=102833&status=done&style=none&taskId=u4003e530-7dff-4f5c-b747-86263742e64&title=&width=306](https://img-blog.csdnimg.cn/a4c1e3116ba849a48b24b60f04852c83.png)
数据库编程
存储过程
函数
触发器
放弃SQL编程
因为在数据库集群的场景里,由于存储过程、触发器和自定义函数都是在本地数据库节点上运行,它们与数据库集群业务产生了冲突,所以为了顾全大局,放弃使用数据库本地编程,甚至连数据库本地生成主键的机制也都放弃了。
避免偷换交易商品信息
- B2B电商平台,通常采用保存历次商品修改信息、降低搜索排名
- B2C电商平台,只需要保存历次商品修改信息即可
- 保存历次商品信息方法,添加sku_old,spu_old表 ,然后进行归档
- 保存历次商品信息方法,添加sku_old,spu_old表 ,然后进行归档
抵御XSS攻击
XSS攻击,是通过在网页上嵌入恶意的JavaScript代码,然后当浏览器渲染DOM组件的时候,这段恶意的脚本就执行了,然后盗取个人账号信息。
第一种,大家都已经知道了,那就是在网页里面植入恶意代码即可。植入过的过程就是你到网站上发帖与回帖。别人看到这个网页,他的账号就被你窃取到了。为什么说XSS攻击跟数据库有关系呢?毕竟发帖回帖的内容,是保存到数据库上的。如果我们对保存到MySQL的数据,先做一下转义,那么将来输出到页面上,那么浏览器就不会当它是标签了,因此也就不会执行恶意代码。
第二种XSS攻击的常用方式,就是发送HTML格式的邮件。因为邮件本身就是一个HTML页面,所以往里面挂恶意代码非常容易。当用户在浏览器上登陆网易邮箱,然后点开这个邮件,那么恶意脚本就开始执行,马上就窃取到你的账户信息。抵御这种XSS攻击,就只能靠电子信箱的运营商,加强邮件内容的过滤,筛选出恶意的脚本。
高阶问题
数据库缓存(查询缓存)、程序缓存
MySQL的查询缓存结构的是KV的,数据库会把执行过的SELECT结果集缓存到内存里面,KEY是SQL语句,VALUE是结果集。
查询缓存最大的缺点就是,只要用户对数据表修改一条记录,就会让这个数据表的缓存大面积的失效,这就造成的IO压力突然增大,所以最好的办法就是不使用查询缓存,而改用数据缓存,数据缓存是把InnoDB数据表和索引中的一部分记录缓存到内存中。用户更新数据的时候,更新了数据表多少条记录,响应个缓存就更改多少条,并不会出现缓存大面积失效的情况。
数据库的查询缓存因为不可以细颗粒度的设置哪张数据表结果集被缓存,但是程序查询缓存可以详细设置哪一条的SQL的结果集被缓存。所以我们可以避开内容经常变化的数据表,对哪些数据不经常变化的数据表设置查询缓存。
SpringCache技术是Java领域里面比较成熟的缓存方案,使用注解就能管理缓存。结合Redis,可以充分发挥查询缓存的优势。show variables like '%query_cache%';