大家好,今天和各位分享一下如何使用 TensorFlow 构建 多项式学习率衰减策略、单周期余弦退火学习率衰减策略、多周期余弦退火学习率衰减策略,并使用Mnist数据集来验证构建的方法是否可行。
在上一篇中和大家分享了指数衰减、分段衰减、余弦衰减,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/article/details/124471098
下面创建的自定义学习率的类,都继承 tf.keras.optimizers.schedules.LearningRateSchedule
1. 多项式衰减
1.1 方法介绍
学习率的多项式有两种情况,如下图所示。首先设置学习率的最高值和最低值,当学习率从最高点下降到最低点后。(1)cycle==False,接下去的所有学习率都保持最低值;(2)cycle==True,学习率从最低点上升到一个新的较高的值,并重新开始下降,以固定周期的形式,下降到最低点后又再次上升。
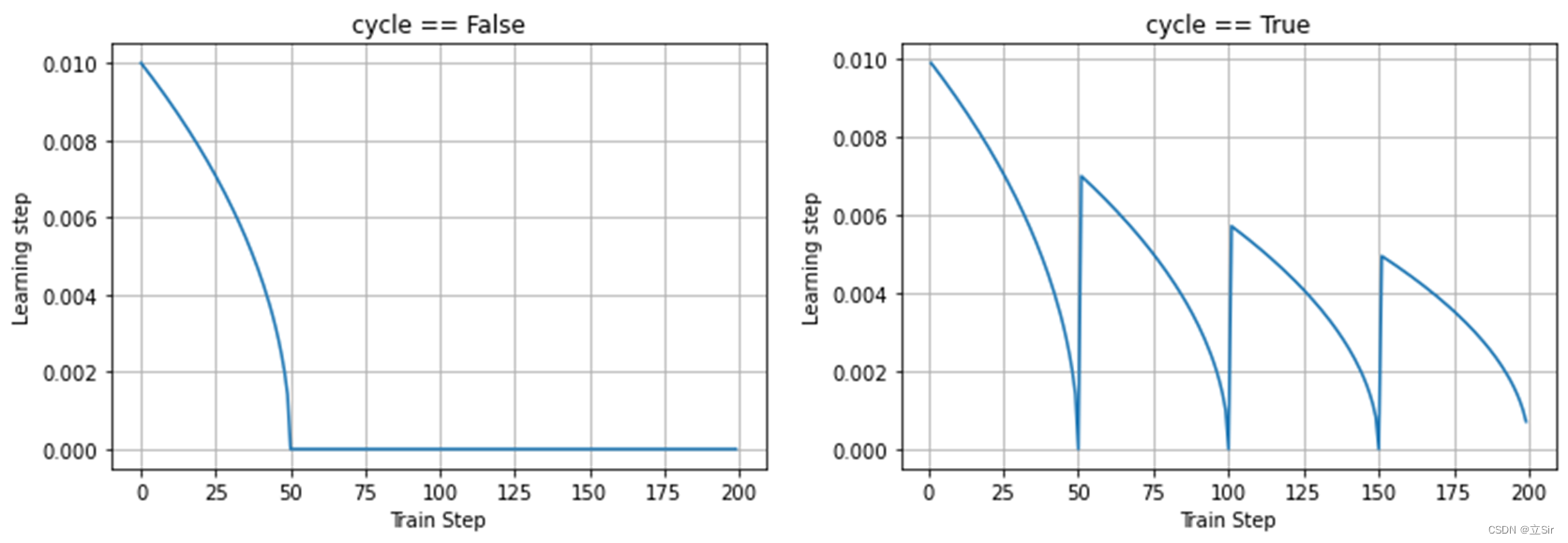
(1)cycle==False 的衰减公式
首先判断当前的 step 是否处于衰减周期 decay_period 中。如果在这个周期中,让用于计算的当前步数 current_step = step,表明学习率处于衰减过程之中;如果不在这个周期中,即已经下降到最低值,让用于计算当前步数 current_step = decay_period,表明已经结束了衰减过程。
计算公式如下:
lr 代表调整后的学习率;initial_lr 代表初始学习率,即最大学习率;min_lr 代表最小学习率;power 代表多项式的幂;其余同上
lr = (initial_lr - min_lr) * (1 - current_step / decay_period) ** (power) + min_lr(2)cycle==True 的衰减公式
首先判断当前 step 处于第几个周期,计算公式如下。current_period 代表当前 step 处于第几个周期内;decay_period 代表一个衰减周期的 step 数;ceil 代表向上取整
current_period = decay_period * ceil(step / decay_period)接下来就是计算衰减后的学习率,lr 代表调整后的学习率;initial_lr 代表初始学习率,即最大学习率;min_lr 代表最小学习率;power 代表多项式的幂
公式中的 step / current_period 一定是一个大于0小于1的数, 随着 step 增加,step越来越接近当前周期的step数,这一项就越来越接近1,那么整个 lr 就越来越接近0
lr = (initial_lr - min_lr) * (1 - step / current_period) ** (power) + min_lr1.2 代码展示
这里的 cycle==True 衰减方式的计算,有一点和公式中不一样,在分母 current_period 后面增加了一项无限接近于0的数 keras.backend.epsilon(),防止分母为0,整个学习率变成无穷大。
lr = (initial_lr - min_lr) * (1 - step / (current_period + keras.backend.epsilon())) ** (power) + min_lr我自定义的类,是继承至 keras.optimizers.schedules.LearningRateSchedule 自定义学习率调度器。为了清晰的展示训练过程中学习率的变化,如果当前的 step 是外部指定的 print_step 的整数倍,就打印一次学习率。并且使用列表 self.learning_rate_list 保存训练过程中每个 step 的学习率,训练完成之后,可调用查看。
# ----------------------------------------------------------------------- #
# 学习率多项式衰减
# ----------------------------------------------------------------------- #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ----------------------------------------------------------------------- #
# 继承自定义学习率的类
class PolynomialDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
decay_period: 一次多项式衰减的周期
power: 多项式的幂
min_lr: 学习率的最小值
cycle: 是否进行多个多项式衰减
print_step: 训练时多少个step打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, decay_period, power, min_lr, cycle, print_step):
# 继承父类的初始化方法
super(PolynomialDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)
self.decay_period = tf.cast(decay_period, dtype=tf.float32)
self.power = power
self.min_lr = tf.cast(min_lr, dtype=tf.float32)
self.cycle = cycle
self.print_step = print_step
# 保存每个step的学习率
self.learning_rate_list = []
# 前向传播
def __call__(self, step):
#(1)学习率达到最低学习率后,就一直保持最低学习率
if self.cycle is False:
# 比较找出当前step是否超出了一个周期
current_step = tf.where(step<self.decay_period, step, self.decay_period)
# 计算衰减后的学习率
decayed_learning_rate = (self.initial_lr - self.min_lr) * \
(1 - current_step / self.decay_period) ** (self.power) + \
self.min_lr
# 保存每个step的学习率
self.learning_rate_list.append(decayed_learning_rate.numpy().item())
# 训练时每个epoch打印一次学习率
if step % self.print_step == 0:
# 打印当前epoch的学习率
print('learning_rate has changed to: ', decayed_learning_rate.numpy().item())
# 返回调整后的学习率
return decayed_learning_rate
#(2)学习率达到最低后,再上升一个较高的学习率再下降
if self.cycle is True:
# 计算目前处于第几个周期, tf.math.ceil向上取整
current_period = self.decay_period * tf.math.ceil(step / self.decay_period)
# 计算衰减后的学习率, 分母加上一个很小的数keras.backend.epsilon()防止分母为0
decayed_learning_rate = (self.initial_lr - self.min_lr) * \
(1 - step / (current_period + keras.backend.epsilon())) ** \
(self.power) + self.min_lr
# 保存每个step的学习率
self.learning_rate_list.append(decayed_learning_rate.numpy().item())
# 训练时每个epoch打印一次学习率
if step % self.print_step == 0:
# 打印当前epoch的学习率
print('learning_rate has changed to: ', decayed_learning_rate.numpy().item())
return decayed_learning_rate2. 单周期的余弦退火衰减
2.1 方法介绍
在传统的训练过程中,设置学习率的策略往往是阶梯式的或者指数衰减式的。若要是使用恒定的学习率进行训练,会使得模型在临近最优解的时候开始震荡,进而无法达到损失函数最低点的最优解。故而使用衰减的学习率,在靠近最优解的附近,梯度逐渐减小,对应减小学习率,使得模型能够顺利收敛到正确的期望位置。
然而在实际过程中,由于模型的复杂,很难正确的描述最优解位置以及损失函数的结构,这使得模型往往会收敛到一个局部的最优解。最终由于学习率的衰减,使得模型最终陷入一个局部的最优解,而非全局的最优解。
而对训练过程的学习率使用余弦退火方法则是通过不断的调整学习率,在衰减到一定值之后,重新调整恢复学习率,跳出当前的局部最优解而重新去寻找全局的最优解。
单周期余弦退火图像如下:

余弦曲线部分的计算公式如下,其中 initial_lr 代表最大学习率,min_lr 代表最小学习率,step_warmup 代表线性上升部分需要对step,total_step 代表一个周期的step
lr = min_lr + 0.5 * (initial_lr - min_lr) * (1 + cos(pi * (step-warmup_step) \ (total_step-warmup_step)))该计算公式得出的结果在可视化后的曲线图如下,余弦曲线峰值点的位置就是线性上升部分的终点。

线性上升部分的计算公式如下,可理解为 y=kx+b 的形式。然后以 warmup 为界限,左侧为线性上升部分,右侧为余弦下降部分
# 增长系数k
k = (initial_lr - min_lr) / warmup_step
# 增长线段 y=kx+b
warmup = k * step + min_lr2.2 代码展示
重点的计算公式我已经在上面说明了,这里需要注意的就是 tf.where(step<self.warmup_step, warmup, decayed_learning_rate) 这个函数的目的就是,如果当前step处于warmup阶段,那么就取线性部分,如果step超出了warmup阶段,就取余弦衰减部分。最终以warmup作为两种学习率的分界。
我自定义的类,是继承至 keras.optimizers.schedules.LearningRateSchedule 自定义学习率调度器。为了清晰的展示训练过程中学习率的变化,如果当前的 step 是外部指定的 print_step 的整数倍,就打印一次学习率。并且使用列表 self.learning_rate_list 保存训练过程中每个 step 的学习率,训练完成之后,可调用查看。
# ----------------------------------------------------------------------- #
# 单周期余弦退火衰减
# ----------------------------------------------------------------------- #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------ #
import math
# 继承自定义学习率的类
class CosineWarmupDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率, 即最大学习率
min_lr: 学习率的最小值
warmup_step: 线性上升部分需要的step
total_step: 整个余弦退火需要对总step
print_step: 多少个step打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, min_lr, warmup_step, total_step, print_step):
# 继承父类的初始化方法
super(CosineWarmupDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)
self.min_lr = tf.cast(min_lr, dtype=tf.float32)
self.warmup_step = warmup_step
self.total_step = total_step
self.print_step = print_step
# 保存训练过程中每个step的学习率
self.learning_rate_list = []
# 前向传播
def __call__(self, step):
# 余弦曲线计算公式
decayed_learning_rate = self.min_lr + 0.5 * (self.initial_lr - self.min_lr) * \
(1 + tf.math.cos(math.pi * (step-self.warmup_step) / \
(self.total_step-self.warmup_step)))
# 线性上升线段计算公式
# 增长系数k
k = (self.initial_lr - self.min_lr) / self.warmup_step
# 增长线段 y=kx+b
warmup = k * step + self.min_lr
# 将余弦部分和增长线段组合,以warmup_step为界限
decayed_learning_rate = tf.where(step<self.warmup_step, warmup, decayed_learning_rate)
# 保存每个step的学习率
self.learning_rate_list.append(decayed_learning_rate.numpy().item())
# 训练时每个epoch打印一次学习率
if step % self.print_step == 0:
# 打印当前epoch的学习率
print('learning_rate has changed to: ', decayed_learning_rate.numpy().item())
# 返回更新后的学习率
return decayed_learning_rate3. 多周期余弦退火衰减
3.1 方法介绍
在看多周期之前,请先把上面的单周期掌握了。
这可以理解为是一种带重启的随机梯度下降算法。在网络模型更新时,由于存在很多局部最优解,这就导致模型会陷入局部最优解,即优化函数存在多个峰值。这就要求,当模型陷入局部最优解时,能够跳出去,并且继续寻找下一个最优解,直到找到全局最优解。要使得模型跳出局部最优解,就需要在模型陷入局部最优解时突然提高学习率,即重启学习率。
多周期的余弦退火衰减示意图如下:
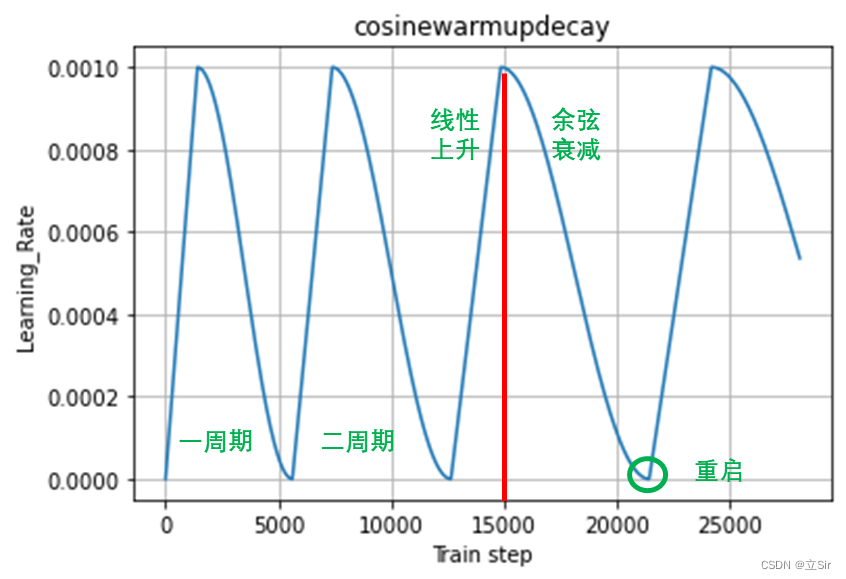
多周期余弦退火算法的公式和单周期的一样,只需要在代码中稍做改动就可以了。改动的地方,新增了一个变量 self.step,并且在 __call__() 方法中,我增加了一个 if 条件判断。
我的思路是,如果当前的 step 到达了一个周期末尾的 step,那么就将当前 step 重置为 0,重新开始线性上升,并增加 warmup 段长度和整个周期的长度。如果有更好的方法,请大家在评论区指出来。
# ----------------------------------------------------------------------- #
# 多周期余弦退火衰减
# ----------------------------------------------------------------------- #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------ #
import math
# 继承自定义学习率的类
class CosineWarmupDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
min_lr: 学习率的最小值
max_lr: 学习率的最大值
warmup_step: 线性上升部分需要的step
total_step: 第一个余弦退火周期需要对总step
multi: 下个周期相比于上个周期调整的倍率
print_step: 多少个step并打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, min_lr, warmup_step, total_step, multi, print_step):
# 继承父类的初始化方法
super(CosineWarmupDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)
self.min_lr = tf.cast(min_lr, dtype=tf.float32)
self.warmup_step = warmup_step # 初始为第一个周期的线性段的step
self.total_step = total_step # 初始为第一个周期的总step
self.multi = multi
self.print_step = print_step
# 保存每一个step的学习率
self.learning_rate_list = []
# 当前步长
self.step = 0
# 前向传播, 训练时传入当前step,但是上面已经定义了一个,这个step用不上
def __call__(self, step):
# 如果当前step达到了当前周期末端就调整
if self.step>=self.total_step:
# 乘上倍率因子后会有小数,这里要注意
# 调整一个周期中线性部分的step长度
self.warmup_step = self.warmup_step * (1 + self.multi)
# 调整一个周期的总step长度
self.total_step = self.total_step * (1 + self.multi)
# 重置step,从线性部分重新开始
self.step = 0
# 余弦部分的计算公式
decayed_learning_rate = self.min_lr + 0.5 * (self.initial_lr - self.min_lr) * \
(1 + tf.math.cos(math.pi * (self.step-self.warmup_step) / \
(self.total_step-self.warmup_step)))
# 计算线性上升部分的增长系数k
k = (self.initial_lr - self.min_lr) / self.warmup_step
# 线性增长线段 y=kx+b
warmup = k * self.step + self.min_lr
# 以学习率峰值点横坐标为界,左侧是线性上升,右侧是余弦下降
decayed_learning_rate = tf.where(self.step<self.warmup_step, warmup, decayed_learning_rate)
# 每个epoch打印一次学习率
if step % self.print_step == 0:
# 打印当前step的学习率
print('learning_rate has changed to: ', decayed_learning_rate.numpy().item())
# 每个step保存一次学习率
self.learning_rate_list.append(decayed_learning_rate.numpy().item())
# 计算完当前学习率后step加一用于下一次
self.step = self.step + 1
# 返回调整后的学习率
return decayed_learning_rate4. 实践验证
下面以Mnist手写数据集为例,来验证一下上面定义的多周期余弦退火学习率衰减能不能用。预处理和网络构建我就不讲了,都比较基础,我们直接看到下面代码中的第(6)部分。
首先对我们自定义的学习率类实例化,传入必要的初始化参数 cosinewarmupdecay = CosineWarmupDecay(...),然后将我们定义的学习率方法传入至Adam优化器中,keras.optimizers.Adam(cosinewarmupdecay),那么在训练时,每次都会给这个类方法传入一个当前 step 值,经过计算学习率后,将调整后的学习率返回给模型。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# ----------------------------------------------------------------------- #
# (1)fashion_mnist数据预加载及预处理
# ----------------------------------------------------------------------- #
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
print('x_train.shape:', x_train.shape, 'y_train.shape:', y_train.shape) # (60000, 28, 28) , (60000,)
print('x_test.shape:', x_test.shape) # (10000, 28, 28)
# 记录训练集的数量
total_train_num = x_train.shape[0]
# ----------------------------------------------------------------------- #
# 学习率多周期余弦退火衰减
# ----------------------------------------------------------------------- #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------ #
import math
# 继承自定义学习率的类
class CosineWarmupDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
min_lr: 学习率的最小值
max_lr: 学习率的最大值
warmup_step: 线性上升部分需要的step
total_step: 第一个余弦退火周期需要对总step
multi: 下个周期相比于上个周期调整的倍率
print_step: 多少个step并打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, min_lr, warmup_step, total_step, multi, print_step):
# 继承父类的初始化方法
super(CosineWarmupDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)
self.min_lr = tf.cast(min_lr, dtype=tf.float32)
self.warmup_step = warmup_step # 初始为第一个周期的线性段的step
self.total_step = total_step # 初始为第一个周期的总step
self.multi = multi
self.print_step = print_step
# 保存每一个step的学习率
self.learning_rate_list = []
# 当前步长
self.step = 0
# 前向传播, 训练时传入当前step,但是上面已经定义了一个,这个step用不上
def __call__(self, step):
# 如果当前step达到了当前周期末端就调整
if self.step>=self.total_step:
# 乘上倍率因子后会有小数,这里要注意
# 调整一个周期中线性部分的step长度
self.warmup_step = self.warmup_step * (1 + self.multi)
# 调整一个周期的总step长度
self.total_step = self.total_step * (1 + self.multi)
# 重置step,从线性部分重新开始
self.step = 0
# 余弦部分的计算公式
decayed_learning_rate = self.min_lr + 0.5 * (self.initial_lr - self.min_lr) * \
(1 + tf.math.cos(math.pi * (self.step-self.warmup_step) / \
(self.total_step-self.warmup_step)))
# 计算线性上升部分的增长系数k
k = (self.initial_lr - self.min_lr) / self.warmup_step
# 线性增长线段 y=kx+b
warmup = k * self.step + self.min_lr
# 以学习率峰值点横坐标为界,左侧是线性上升,右侧是余弦下降
decayed_learning_rate = tf.where(self.step<self.warmup_step, warmup, decayed_learning_rate)
# 每个epoch打印一次学习率
if step % self.print_step == 0:
# 打印当前step的学习率
print('learning_rate has changed to: ', decayed_learning_rate.numpy().item())
# 每个step保存一次学习率
self.learning_rate_list.append(decayed_learning_rate.numpy().item())
# 计算完当前学习率后step加一用于下一次
self.step = self.step + 1
# 返回调整后的学习率
return decayed_learning_rate
# ----------------------------------------------------------------------- #
# (3)参数设置
# ----------------------------------------------------------------------- #
# 每个step处理多少张图像
batch_size = 32
# 迭代次数
num_epochs = 15
# 初始学习率
initial_lr = 0.001
# 学习率下降的最小值
min_lr = 1e-7
# 余弦退火的周期调整倍率
multi = 0.25
# 一个epoch包含多少个batch也是多少个steps, 即1875
one_epoch_batchs = int(total_train_num / batch_size)
# 第一个余弦退火周期需要的总step,以三个epoch为一个周期
total_step = one_epoch_batchs * 3
# 线性上升部分需要的step, 一个周期的四分之一的epoch用于线性上升
warmup_step = int(total_step * 0.25)
# 多少个step打印一次学习率, 一个epoch打印一次
print_step = one_epoch_batchs
# ----------------------------------------------------------------------- #
# (4)划分数据集
# ----------------------------------------------------------------------- #
# 预处理
def preprocessing(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.0 # 像素归一化
x = tf.expand_dims(x, axis=-1) # 增加通道维度
y = tf.cast(y, dtype=tf.int32) # 标签转为tensor类型
return x,y
# 训练集
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_ds = train_ds.map(preprocessing).batch(batch_size).shuffle(10000)
# 测试集
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_ds = test_ds.map(preprocessing).batch(batch_size)
# 迭代器查看数据是否正确
sample = next(iter(train_ds))
print('x_batch:', sample[0].shape, 'y_batch:', sample[1].shape) # (32, 28, 28, 1), (32,)
# ----------------------------------------------------------------------- #
# (5)网络构建
# ----------------------------------------------------------------------- #
inputs = keras.Input(sample[0].shape[1:]) # 构造输入层
# [28,28,1]==>[28,28,32]
x = layers.Conv2D(32, kernel_size=3, padding='same', activation='relu')(inputs)
# [28,28,32]==>[14,14,32]
x = layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same')(x)
# [14,14,32]==>[14,14,64]
x = layers.Conv2D(64, kernel_size=3, padding='same', activation='relu')(x)
# [14,14,64]==>[7,7,64]
x = layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same')(x)
# [7,7,64]==>[None,7*7*64]
x = layers.Flatten()(x)
# [None,7*7*64]==>[None,128]
x = layers.Dense(128)(x)
# [None,128]==>[None,10]
outputs = layers.Dense(10, activation='softmax')(x)
# 构建模型
model = keras.Model(inputs, outputs)
# ------------------------------------------------------------------ #
# (6)模型训练
# ------------------------------------------------------------------ #
# 接收学习率调整方法
cosinewarmupdecay = CosineWarmupDecay(initial_lr=initial_lr, # 初始学习率,即最大学习率
min_lr=min_lr, # 学习率下降的最小值
warmup_step=warmup_step, # 线性上升部分的step
total_step=total_step, # 训练的总step
multi=multi, # 周期调整的倍率
print_step=print_step) # 每个epoch打印一次学习率值
# 设置adam优化器,指定学习率
opt = keras.optimizers.Adam(cosinewarmupdecay)
# 网络编译
model.compile(optimizer=opt, # 学习率
loss='sparse_categorical_crossentropy', # 损失
metrics=['accuracy']) # 监控指标
# 网络训练
model.fit(train_ds, epochs=num_epochs, validation_data=test_ds)
# 绘制学习率变化曲线
plt.plot(cosinewarmupdecay.learning_rate_list)
plt.xlabel("Train step")
plt.ylabel("Learning_Rate")
plt.title('cosinewarmupdecay')
plt.grid()
plt.show()我设置了在训练过程中,每个epoch打印一次学习率,训练过程如下:
Epoch 1/15
learning_rate has changed to: 1.0000000116860974e-07
1875/1875 [==============================] - 27s 14ms/step - loss: 0.9364 - accuracy: 0.6849 - val_loss: 0.3792 - val_accuracy: 0.8629
Epoch 2/15
learning_rate has changed to: 0.0009698210633359849
1875/1875 [==============================] - 25s 13ms/step - loss: 0.3030 - accuracy: 0.8920 - val_loss: 0.2907 - val_accuracy: 0.8989
------------------------------------------------------------
------------------------------------------------------------
Epoch 14/15
learning_rate has changed to: 0.0009987982921302319
1875/1875 [==============================] - 29s 15ms/step - loss: 0.1430 - accuracy: 0.9470 - val_loss: 0.2871 - val_accuracy: 0.9107
Epoch 15/15
learning_rate has changed to: 0.0008539927075617015
1875/1875 [==============================] - 29s 15ms/step - loss: 0.1213 - accuracy: 0.9563 - val_loss: 0.2902 - val_accuracy: 0.9156我设置了在训练过程中每一个step都保存一次当前学习率值,保存于 self.learning_rate_list ,训练完成之后可以通过 cosinewarmupdecay.learning_rate_list 读取这个列表,绘制学习率变化曲线
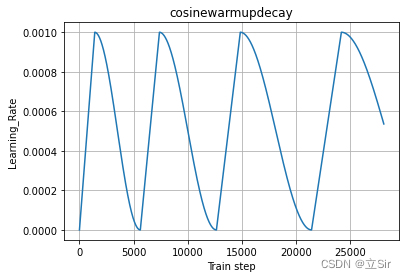
使用余弦退火学习率衰减方法和传统的学习率连续衰减方法的对比图
