设备跟踪和管理正成为机器学习工程的中心焦点。这个任务的核心是在模型训练过程中跟踪和报告gpu的使用效率。
有效的GPU监控可以帮助我们配置一些非常重要的超参数,例如批大小,还可以有效的识别训练中的瓶颈,比如CPU活动(通常是预处理图像)占用的时间很长,导致GPU需要等待下一批数据的交付,从而处于空闲状态。
什么是利用率?
过去的一个采样周期内GPU 内核执行时间的百分比,就称作GPU的利用率。
如果这个值很低,则意味着您的 GPU 并没有全速的工作,可能是受到 CPU或者IO 操作的瓶颈,如果你使用的按小时付费的云服务器,那么就是在浪费时间和金钱!
使用终端命令监控
nvidia-smi显示如下:
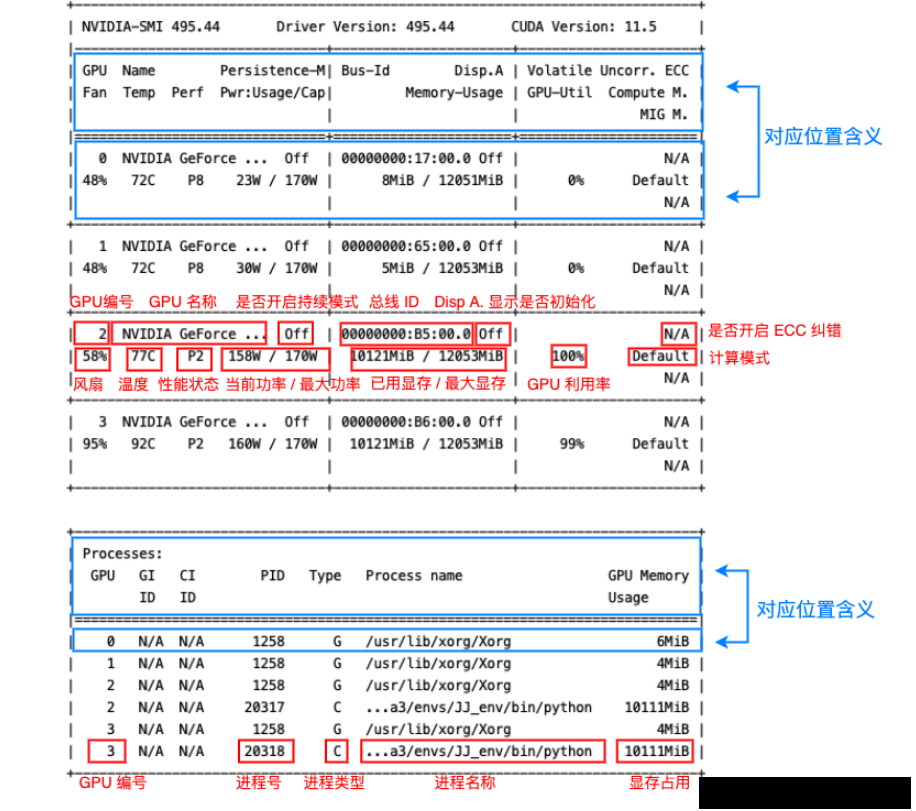
- 第一栏的Fan:N/A是风扇转速,从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能打不到显示的转速。有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低温(比如我们实验室的服务器是常年放在空调房间里的)。
- 第二栏的Temp:是温度,单位摄氏度。
- 第三栏的Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能。
- 第四栏下方的Pwr:是能耗,上方的Persistence-M:是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
- 第五栏的Bus-Id是涉及GPU总线的东西,domain:bus:device.function
- 第六栏的Disp.A是Display Active,表示GPU的显示是否初始化。
- 第五第六栏下方的Memory Usage是显存使用率。
- 第七栏是浮动的GPU利用率。
- 第八栏上方是关于ECC的东西。
- 第八栏下方Compute M是计算模式。
nvidia-smi 命令的其他参数
除了直接运行 nvidia-smi 命令之外,还可以加一些参数,来查看一些本机 Nvidia GPU 的其他一些状态。下面笔者简单介绍几个常用的参数,其他的有需要可以去手册中查找:man nvidia-smi。
-L 参数显示连接到系统的 GPU 列表。
nvidia-smi -L
# 输出:
GPU 0: NVIDIA GeForce RTX 3060 (UUID: GPU-55275dff-****-****-****-6408855fced9)
GPU 1: NVIDIA GeForce RTX 3060 (UUID: GPU-0a1e7f37-****-****-****-df9a8bce6d6b)
GPU 2: NVIDIA GeForce RTX 3060 (UUID: GPU-38e2771e-****-****-****-d5cbb85c58d8)
GPU 3: NVIDIA GeForce RTX 3060 (UUID: GPU-8b45b004-****-****-****-46c05975a9f0)
GPU UUID:此值是GPU的全球唯一不可变字母数字标识符。它与主板上的物理标签无关。
-i 参数指定某个 GPU,多用于查看 GPU 信息时指定其中一个 GPU。
-q 参数查看 GPU 的全部信息。可通过 -i 参数指定查看某个 GPU 的参数。
如:
nvidia-smi -i 0 -qtopo
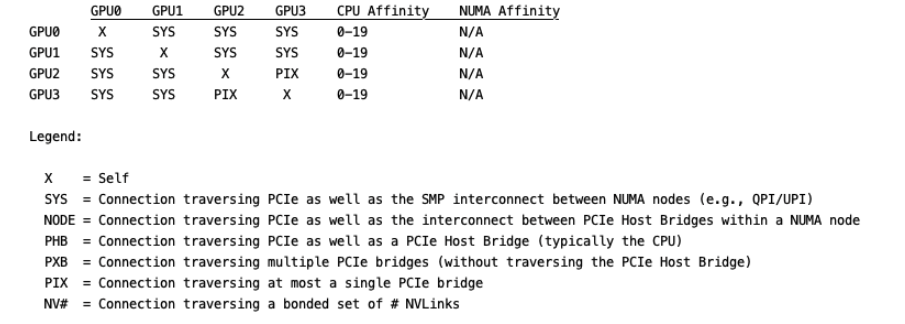
topo 展示多GPU系统的拓扑连接信息,通常配合 -m 参数即 nvidia-smi topo -m,其他参数可自行查阅。
输出如下,这里用代码块没法对齐,就直接贴图了: