内存管理与文件系统、IO
1、物理内存与虚拟内存
为什么会有虚拟内存和物理内存的区别。正在运行的一个进程,他所需的内存是有可能大于内存条容量之和的,比如你的内存条是256M,你的程序却要创建一个2G的数据区,那么不是所有数据都能一起加载到内存(物理内存)中,势必有一部分数据要放到其他介质中(比如硬盘),待进程需要访问那部分数据时,在通过调度进入物理内存。所以,虚拟内存是进程运行时所有内存空间的总和,并且可能有一部分不在物理内存中,而物理内存就是我们平时所了解的内存条。
2、分页与分段
https://www.cnblogs.com/onepeace/p/5066736.html
3、了解的页面置换算法有几种?详述其中一种?
FIFO、LRU、最优页……需要知道常用的几种算法的大致原理,并能详述其中一种
4、常见的Linux文件系统有哪几种?有哪些区别?
ext2、ext3、ext4
5、Linux基本操作
1)、如何在Linux系统下查看CPU、内存、磁盘、IO、网卡情况?
http://blog.csdn.net/joeyon1985/article/details/46682939
top 查看进程活动状态以及一些系统状况
vmstat 查看系统状态、硬件和系统信息等
iostat 查看CPU 负载,硬盘状况
sar 综合工具,查看系统状况
mpstat 查看多处理器状况
netstat 查看网络状况
iptraf 实时网络状况监测
tcpdump 抓取网络数据包,详细分析
tcptrace 数据包分析工具
netperf 网络带宽工具
dstat 综合工具,综合了 vmstat, iostat, ifstat, netstat 等多个信息
2)、如何查看一个进程的详细信息,如何追踪一个进程的执行过程
网络模型
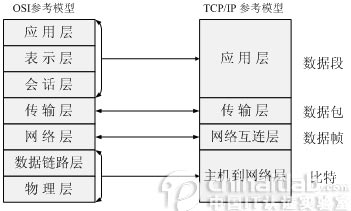
1、OSI七层网络模型和TCP/IP四层模型分别是什么样的?以及每层的数据格式?
http://blog.csdn.net/qq_32528231/article/details/57415350
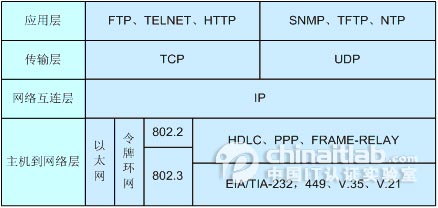
2、常见的网络协议及它们分别属于TCP/IP模型的哪一层
TCP 和UDP的区别:
http://blog.csdn.net/li_ning_/article/details/52117463
https://my.oschina.net/amui/blog/1626549
TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
3、TCP/IP协议
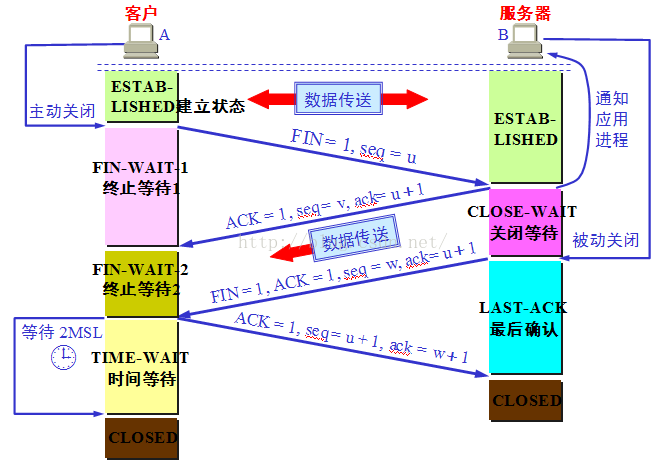
1、TCP建立和关闭连接过程
建立连接的三次握手,关闭连接的四次握手,及为什么要这么做,需要理解清楚。
http://blog.csdn.net/guyuealian/article/details/52535294
三次握手示意图:
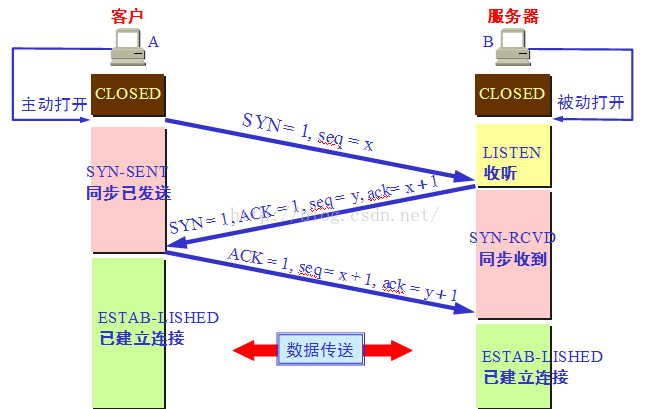
四次挥手示意图:
数据库索引
聚集索引:
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
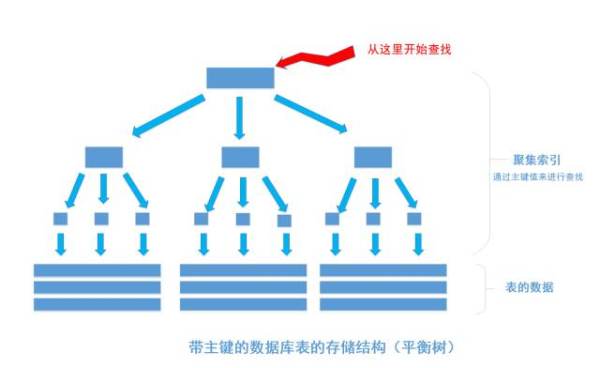
上图就是带有主键的表(聚集索引)的结构图。图画的不是很好, 将就着看。其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
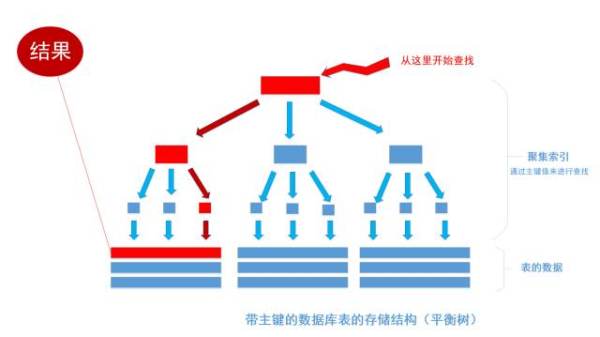
非聚集索引:
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图
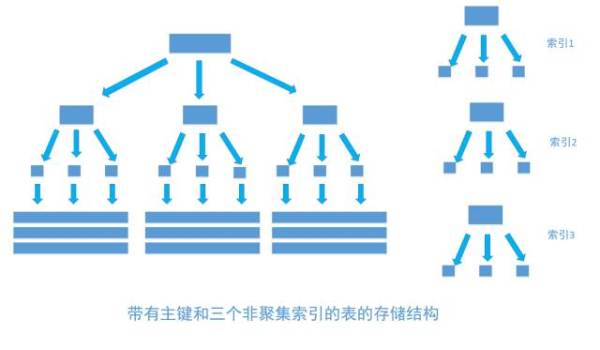
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图
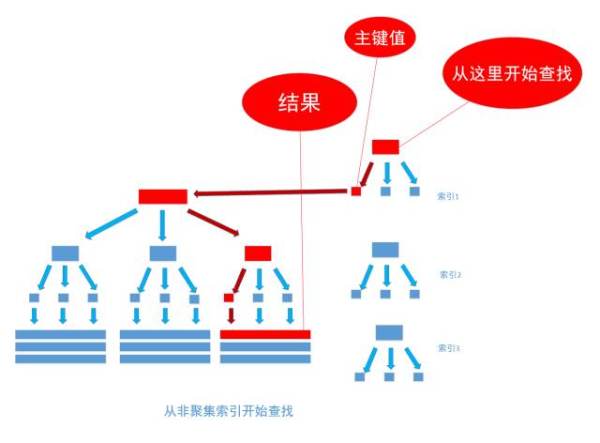
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
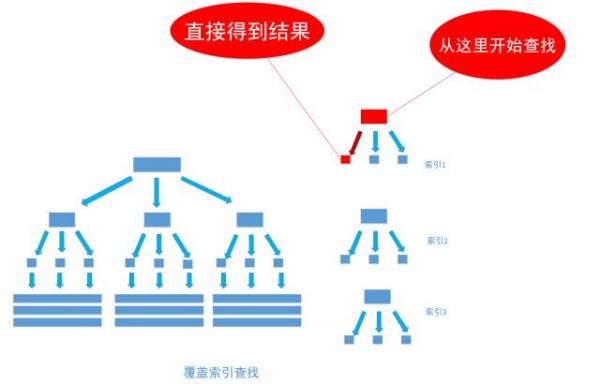
有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引
create index index_birthday on user_info(birthday);
//查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = '1991-11-1'
这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
如果,我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图