【公众号:小叶的趣味数模】
A题
人口疏散很简单,就是写一些规则去模拟人群的移动,移动的规则可以参考下面介绍一篇文献,案例程序根据这篇文献编写的,下载链接:
https://pan.baidu.com/s/1JuA5hCeFnLAwTgX-s11Qyw 提取码:0105


场景可以自己设置,门的宽度,座位分布以及通道,比如下面这样的场景

构建场景就用一个0-1矩阵构建就行,比如说座位位置用1表示,其余都是人可以活动的范围用0表示,每个网格只能容下一人,人数可以自己定义,但不能太少,不然行程不了拥挤,其实人口疏散,就好比道路上的车辆通行,速度比较慢,那肯定车流量低,太快也不行,有最大速度限制,还有个就是安全距离,来的车多了,会排队等候过路口,这么来看,不停止的移动和减速-停止等候-加速离开,哪一个要的时间长一点,其实就是减速和加速过程浪费了时间,速度适中,那么形成的排队长度就会比较短,道路就比较通畅,那么基本上不会形成拥堵,速度过快,又有个安全距离,总不可能贴别人脸上吧,回到这道题,一样的道理,那么怎么用模型去描述这一现象呢,还是一个场景的设置,定义发生的重大事件等级,1-5级,不同的时间等级,人们会有不同的焦虑程度,就有不同的初始速度V0,最大速度Vmax,移动肯定是朝着门的方向走的,然后如果周围没人,那么会以速度V<=Vmax这个速度移动,如果旁边有人,就需要求一个相对速度,不可能贴着别人走,那么肯定会放缓速度,如果旁边都是人,那就等着吧。从事件发生开始随时间的推移,人的焦虑程度会增加,怎么用公式去体现,exp函数或者s型函数都行,t=0时速度是v,时间作为横坐标,假设焦虑到了极点,W=1,不同等级的事件,初始的焦虑不一样,比如说发生了一级事件,我的焦虑程度是0.2,我的最大移动速度是5m/s,那么我开始就以1m/s的速度朝门走去,然后每10s我的焦虑程度会上升0.1,那么10s后我的位移速度就是3m/s。然后补充两点,人的移动也有加速和减速,加速度程序中自己设置,疏散过程不均匀,出门的时候,肯定是与门垂直方向的人更容易出去一点,这里自己设置概率谁先过,出门后后面的人补上空位等待移动。当然了,你也可以在空间内设置其他障碍物也可以。如果在设置个插队情况就更好了。
按照上述逻辑去写一些规则条件去描述这个问题就行,不用加寻找最短路,真的有紧急事件发生,没空让你做选择,这里的参数调整主要是事件等级,第一问按这个思路去做就行,第二问找因素,要仿真模拟,肯定会保存过程数据,比如说10s-20s时段人均通行时间,10s-20s人均等待时间,10s-20s出去的人数、10s-20s门口的人群密度等等,这些指标都能说明问题,其实就是看某些时段秩序好不好,不好肯定会造成后面的连锁反应。
第三问两个出口,位置和大小可以直接定下来在做分析,第一种情况两个门大小相等,第二种一个大一个小,每个人都有概率选择从哪一个门出去,第一个原则是距离最近,第二人都是感性的,会去评估从哪个门出去更快,可以简单来做,就看哪个门排队的人比较少就去哪个门,比如说以门为中心点,半径5m内的人数有多少,哪一个门的人更少就去哪个门,如果同样多,那就直接以最近选择。
整体的思路其实就是结合了实际现象,相信大家还有更好的脑洞,只要合理,都可以用模型去进行描述,最后程序实现就行。
B题
文本分析题,首先是json代码文件,可能很多人不清楚,python里import json然后json.loads加载就可以了,之后就是把诗词字段通过re库匹配出来;如果是matlab,loadjson读取,注意会不会乱码,乱码问题网上搜,这里不多说,matlab处理的话这几个函数有点帮助:replace(清洗)、join(拼接)、intersect(返回词库中有的内容)、strcmp(判断字符串是否相等)、findstr(返回短字符串在长字符串中的开始位置)、regexpi(正交匹配)。
其实后面问就是分词然后统计词频做分析,当然了词库很重要,这里给大家分享一些字库,其中就有唐宋诗词的,其他词库用得上就用
https://pan.baidu.com/s/1JuA5hCeFnLAwTgX-s11Qyw 提取码:0105
第二问说的真粗暴,那么这里就有个更粗暴的相关性算法:杰卡德相似系数,分好词后用一个相关性算法就可以了,如果是用的python jieba分词,给大家普及下其中的算法原理,可以适当进行包装,以下内容可以摘抄:
-----------------------------------------------------------------------------
1 有向无环图
基于前缀词典实现高效的词图扫描,根据句子中汉字的成词情况生成trie树,并构建有向无环图 (DAG)。
Trie 字典树/前缀树优点:利用字符串的公共前缀来减少查询时间,从而减少无谓的字符串比较过程,查询效率比哈希树高。主要应用于统计、排序和保存大量的字符串(但不仅限于字符串),常用于搜索引擎系统中对文本词频统计。

有向无环示意图如下所示,算法将遍历每条文本,并基于单字并创建trie树,构建无环图。
2 基于汉字的隐马尔可夫算法
在分词过程中,将单字在词中的位置B、M、E、S、A作为隐藏状态,单字作为观测变量,使用词典文件分别存储字符之间的表象概率矩阵、初始概率向量和转移概率矩阵,然后根据概率再利用viterbi算法对最大可能的隐藏状态进行求解。
HMM即隐马尔科夫模型,是一种基于概率假设的统计模型。之所以为“隐”,是因为相较于马尔科夫过程HMM有着未知的参数,并且与表象有一定的关联关系。
本文通过上述模型对给定的输入X,能够预测出类别Y。通过学习联合概率分布P(X,Y),及贝叶斯定理求解条件概率:

HMM作为模型的有向图PGM,通过联合概率建模:

其中,S、O分别表示状态序列与观测序列。

上式即为HMM解码问题中Viterbi算法的递推式。
Viterbi算法的基本思想是:如果最佳路径经过一个点,那么起始点到这个点的路径一定是最短路径,否则用起始点到这点更短的一条路径代替这段,就会得到更短的路径,这显然是矛盾的;从起始点到结束点的路径,必然要经过第n个时刻,假如第n个时刻有k个状态,那么最终路径一定经过起始点到时刻n中k个状态里最短路径的点。
将时刻t隐藏状态为i所有可能的状态转移路径到的状态最大值记为:
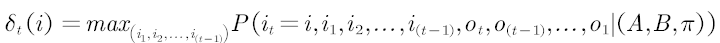
本文可以据此由初始时刻依次向后推出每一个时刻的最大概率隐藏状态。
针对无环图,基于本节模型,对单条文本进行分析时,得到各分支路径及其出现概率以确定组词。
3 动态规划
动态规划所处理的问题是一个多阶段决策问题,一般由初始状态开始,通过对中间阶段决策的选择,达到目标状态。主要有如下几个步骤:初始状态->决策1->决策2->…->决策n->结束状态。

在分词算法中,动态规划目的在于查找最大概率路径,从而找出基于词频的最大切分组合。
①查找待分词句子中已切分好的词语(全模式下的分词list),得出查找该词语出现的频率(次数/总数),如果没有该词,就将词典中出现频率最小的词频作为该词的频率;
②通过动态规划查找最大概率路径,首先对句子从右往左反向计算最大概率(这里反向是因为汉语句子的重心经常落在右边, 因为通常情况下形容词太多, 后面的才是主干。因此,从右往左计算,正确率要高于从左往右计算,这里类似于逆向最大匹配),P(NodeN)=1,P(NodeN-1)=P(NodeN)×Max(P(倒数第一个词)) ,依次类推,最后得到最大概率路径,得到最大概率的切分组合。
-----------------------------------------------------------------------------
接着来说题目,第一问其实就是构建一些风格的词库(不同风格的词库构建的越多越好,这样第四问好做),分词后统计词频,第三问多了个归类,文本的分类不是说用机器学习算法去做,而是依赖于词库,相当于是给诗词贴风格的标签。但是想用算法去包装也不是不行。
第四问,大家可以去看下我这篇主成分推文的理解,其实就是选择出50首诗词,可以尽可能反映出所有诗词的风格,其实就是看看是否覆盖了你构建的风格词库。其实到这里整个逻辑就比较清晰了,首先做词频观察下文本规则,然后其中就可以把高频词汇用于构建词库,自己再补充下,不同词库相当于不同风格的标签,之后就是给这些诗词贴标签,最后第四问,可以构建一个启发式算法,自变量就是随机50个诗词,目标函数是50个诗词中有词汇被包含于所有词库,一般比较理想的情况会出现比较美观的迭代图,就说明你构建的词库比较合理,为什么这么说,第一个需要你的词库涵盖比较全,第二看你的词库是否具有泛化能力。
可能大家不是很理解,这是一种比较有价值的做法,可以做个参考。
C题
以下数据见下载链接
https://pan.baidu.com/s/1JuA5hCeFnLAwTgX-s11Qyw 提取码:0105
这道题的数据定位的是城市,那就简单来做分析就行,上面链接里有美国所有城市的经纬度。

wastewater_surveillance_data文件中有城市人口、废水中当前的病毒水平、最近 15 天内的百分比变化、检测出病毒的废水样本的百分比。
NWSS_Public_SARS-CoV-2_Wastewat文件中有城市人口、检测开始时间-结束时间、最近 15 天内的百分比变化、检测出病毒的废水样本的百分比、废水中当前的病毒水平。
美国城市边界:

美国路网、水路分布、建筑分布下载链接中都有。
第一问污水检测采样点是否合理,既然题目给的网站中的数据只定位到城市,而有数据的城市则是设立了监测站点,那么这个时候我们怎么去评估是否合理,美国一共3000多个县,数据中只有几百个有监测点,构建评价体系肯定是有的,在这之前还需要对无监测站的县的这一个指标(废水中当前的病毒水平)进行拟合补充,其他两个指标可有可无,人口是有的,然后建筑面积、区划内的水路密度、河流面积、路网密度可以通过上述shp文件进行测算(其中路网是给的州的,有县的行政边界,可以通过arcgis软件进行拆分,然后通过matlab、python软件读取数据,去测算这几个指标,通过这几项指标先对无检测站的县的废水中的病毒水平进行拟合,这样才能够很好地去解决新增选址的问题,首先还是看合理性,有了这些指标,根据题目提到的设立站点区域的特点,人口多,那么势必当地的交通发达,尤其是周围有水域水路的城市应当为重点监测地区,那么这里就需要各位首先去量化各指标权重,然后进行评价,推荐结合主观+客观方法,比如层次分析、熵权、秩和比、因子分析、模糊综合、投影寻踪、Topsis、模糊Borda等。
然后整体排名后衡量是否合理,如果出现了排名靠后都有设置监测点的话,那就可以说位于这些县的监测点设置不合理。
有了上述结果,接下来的新增10个采样点其实都一目了然了,不需要做什么寻优。
(这里补充一下选址问题,如果涉及到距离和具体位置,用优化算法去解决没问题,但是这里是定位到城市,那么就需要通过评估各城市的综合情况去进行选址)
第二问,如果想用shp文件来做,可以通过路网连接去衡量各城市之间的紧密程度,也可以评估出每个城市的发展规模水平,大城市爆发疫情肯定是要比小城市传播更强。如果不愿意用也可以有简单的方法,就看人口和城市间的距离(建议用球面公式测算实际距离),然后针对数据中的病毒水平,如果可以衡量出城市间的紧密程度,那么肯定就可以很好地去测算出周边城市被波及的概率。
这道题也可以在考虑人口流动的情况,但是需要爬取机票、火车票、客车等信息,比如说从A城到B城的班次,用于衡量城市间的人口流动情况,这样可以更好地对疫情进行预警。最后给出一些防控建议。
D题
第一问相关性分析,第二问方差分析,完事