day12.30瓜子二手车供应链(一面)
- 自我介绍
- 问了三个项目
- 操作系统间的通信方式
- 管道通信:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。具有进程的亲缘关系通常是具有父子进程间的关系。
2.命名管道FIFO:命名管道也是一种半双工的通信方式,但他允许无亲缘关系进程间的通信。
3.消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递量少、管道只能承载无格式字符流以及缓冲区大小受限等缺点。
4 . 共享存储ShareMemeory:共享存储就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的IPC方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
5 . 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常做为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
6 . 套接字(Socket):套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
7 . 信号(sinal):信号是一种比较复杂的通信方式,用于通知接收进程某个时间已经发生。
- 数据库的索引是怎么实现的
什么是索引:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构就是索引。
数据库的索引其实就是为了使查询数据效率快。索引可以大大提高MySQL的检索速度。
-
目前大部分数据库及其文件系统都采用B-Tree或其变种B+Tree作为索引结构。
-
MySQL 中索引的实现:
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。 -
MyISAM索引实现:MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
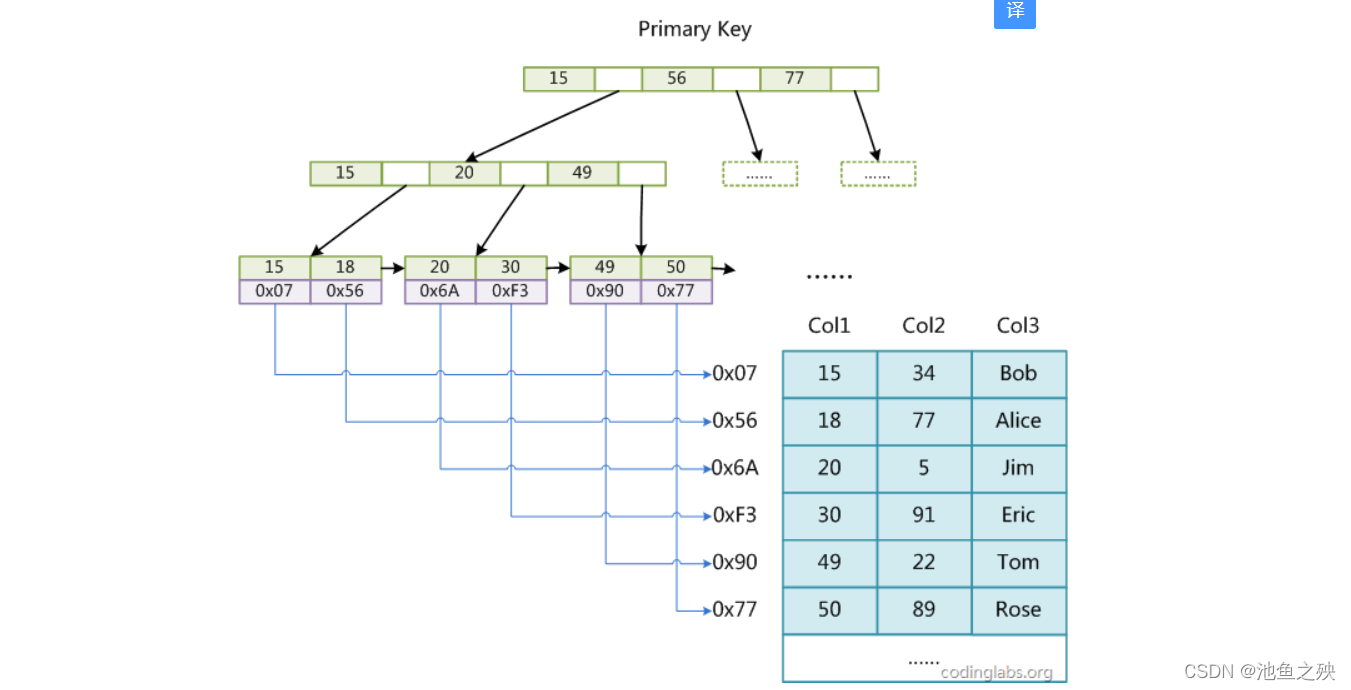 MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。 -
InnoDB索引实现:
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
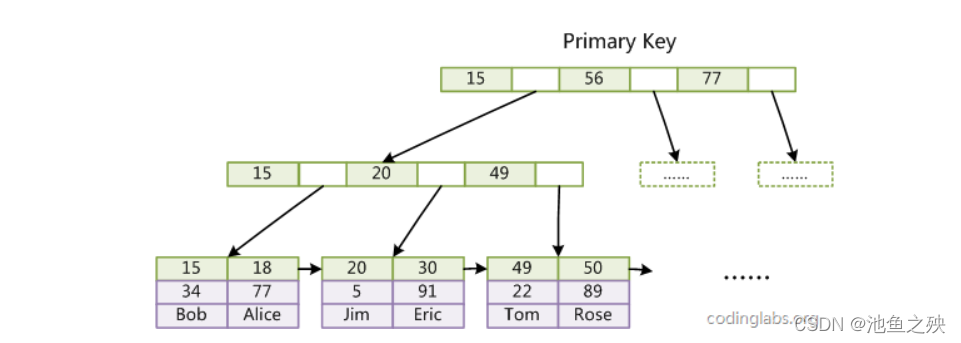
如图可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
更加详细的内容可以看这篇文章https://blog.codinglabs.org/articles/theory-of-mysql-index.html
5. 聚簇索引和非聚簇索引的区别
相同点:都是B+树的数据结构
- 聚簇索引:将数据存储和索引放在一起,并且是按照一定的顺序组织的,找到了索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻的放在磁盘上的。
- 非聚簇索引::叶子节点不存储数据,存储的是数据行地址,也就是说根据索引查找到数据行的位置再去磁盘查找数据,这就有点类似一本书的目录,比如要找到第三章第一节,那就现在目录里面查找,找到对应的页码后再去对应的页码看文章。
- Java保证线程间同步的办法
1.synchronized关键字,修饰方法,保证此方法只会有一个对象访问。修饰代码块。被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。
1.synchronized关键字,修饰方法,保证此方法只会有一个对象访问。修饰代码块。被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。
2.wait()与notify
wait():使一个对象处于等待状态,并且释放所持有对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
ALLnotify():唤醒所有初入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们去竞争。
3.使用特殊域变量(volatile)实现线程同步
1.volatile关键字为域变量的访问提供了一种免锁机制
2.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新。
3.因此每次使用该域就要重新计算,而不是使用寄存器中的值。
4.volatile不会提供任何原子操作,他也不能用来修饰final类型的变量。
5.使用方法:在互斥变量前加上volatile关键字修饰即可。
- 什么是AOP
- AOP(Aspect-OrientedProgramming,面向切面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善。
它面向一种横切的技术,剖解开封装的对象内部,并将那些影响了多个类的公共性为封装到一个可重用的模块,并将其名为“Aspect”,即方面。简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP代表的是一个横向的关系,如果说“对象”是一个空心的圆柱体,其中封装的是对象的属性和行为;那么面向方面编程的方法,就仿佛一把利刃,将这些空心圆柱体剖开,以获得其内部的消息。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹。
-
DI
DI(Dependency Injection )依赖注入
DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
好处:实现了模块间的解耦。 -
IOC
IOC(Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。)
对象由原来程序本身创建,变为了程序接收对象。
程序员主要精力集中于业务实现。
实现了service和dao的解耦工作,Service层和dao层实现了分离。没有直接依赖关系。
如果dao的实现发生改变,应用程序本身不用改变。
控制的内容:指谁来控制对象的创建:传统的应用程序对象的创建是由程序本身控制的。使用spring后,是由spring来创建的。
反转:正转是指由程序来创建对象,反转指程序本身不去创建对象,而是变为被动接收的对象。
总结:以前对象是由程序本身来创建,使用spring后,程序变为被动的接收spring创建好的对象。
Ioc–是一种编程思想。由主动编程变为被动接收;
Ioc的实现是通过ioc容器来实现的。Ioc容器–BeanFactory
- 代理模式(动态代理or静态代理)
代理模式(Proxy),为其他对象提供一种代理以控制对这个对象的访问。
思想:主体想实现的功能,需要一个代理类替我去实现。实现方式:实现相同的接口
例如:小白想追求小红,追求方法有送花,送玫瑰。但小白却害羞不敢主动,他拜托小黄去替他追。所以就让小黄替他去送花,送玫瑰。所以代理类和主体要实现的方法是一样的。 - 工厂模式
简单工厂模式:实现一个基类,然后把每个操作封装成一个具体的类然后继承自这个类。这样以后每增加一个方法就只需要新增一个类即可。
工厂方法模式:在工厂方法模式中,工厂父类负责定义创建产品对象的公共接口,而工厂子类则负责生成具体的产品对象,这样做的目的是将产品类的实例化操作延迟到工厂子类中完成,即通过工厂子类来确定究竟应该实例化哪一个具体产品类。
抽象工厂模式创建的是对象家族,也就是很多对象而不是一个对象,并且这些对象是相关的,也就是说必须一起创建出来。而工厂方法模式只是用于创建一个对象,这和抽象工厂模式有很大不同。 - 什么是脏读
- 事务
- SQL语句
- 反转链表
LinkList reverseLink(LinkList head)
{
LinkList newhead=(LNode*)malloc(sizeof(LNode));
newhead->next=NULL;
newhead=newhead->next;
LinkList node;
while(head!=NULL)
{
node=head;
head=head->next;
node->next=newhead;
newhead=node;
}
return newhead;
}
day 1.4(经纬恒润实习)
-
Java中创建对象的几种方式
- 使用new关键字
Employee emp1 = new Employee(); - 使用Class类的newInstance方法
Employee emp2 = (Employee) Class.forName("org.programming.mitra.exercises.Employee").newInstance(); - 使用Constructor类的newInstance方法
Constructor<Employee> constructor = Employee.class.getConstructor(); Employee emp3 = constructor.newInstance(); - 使用clone方法
Employee emp4 = (Employee) emp3.clone(); - 使用反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.obj")); Employee emp5 = (Employee) in.readObject();
- 使用new关键字
-
对反射有了解吗
反射就是把Java类中的各种成分映射成一个个的Java对象。
传送门:https://blog.csdn.net/sinat_38259539/article/details/71799078?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
3. final 和finally有什么区别
final:
- final修饰的类是不能被继承的,因为其是一个最终类;
- final修饰的变量是一个常量,只能被赋值一次;
- final修饰的方法也不能重写,但能被重载;
- final可以修饰类、方法、变量;
- 内部类只能访问被final修饰的局部变量。
finally: - finally块通常放在try、catch的后面,有时可以直接放在try 的后面,但有时会不能放。
- finally中的语句是正常执行或者处理异常之后必须执行的语句,finally块一般是用来关闭(释放)物理资源(数据库连接,网络连接,磁盘文件等)。无论是否发生异常,资源都必须进行关闭。
- 当没有必要资源需要释放时,可以不用定义finally块。
- finally块中的代码总能执行,这就说明无论try、catch块中执行怎样的代码,是否发生异常,还是正常运行,finally块一定会被执行,如果想要finally块不执行,除非在try、catch块中调用退出虚拟机的方法,否则finally块无论怎么样还是会被执行,如下图所示:
-
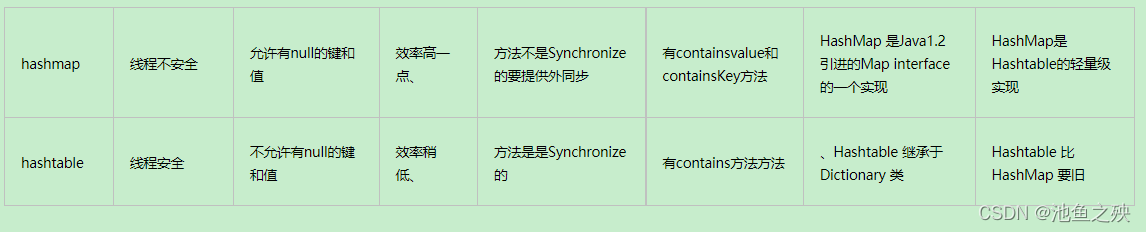
HashMap和hashtable的区别
HashMap不是线程安全的:HashMap是map接口的子类,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
HashTable:HashTable是线程安全的,HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。Hashtable不允许有null的键和值。
-
重写(Override)与重载(Overload)
重写:重写是子类对父类的允许访问的方法的实现过程进行重新编写,返回值和形参都不能改变。即外壳不变,核心重写!
当需要在子类中调用父类的被重写方法时,要使用super关键字。
重载:重载是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
day1.5北京东方国信(一面)(已offer)
- 设计模式:
单例模式: - mybatis中#{}和${}的区别
- 图的遍历方式
深度优先搜索,广度优先搜索 - 二叉树的遍历方式
- 创建线程的方式
继承thread类,实现runnable接口,通过Callable和Future创建线程 - 依赖注入的三种方式
构造方法注入,setter注入,注解注入。 - 左连接右连接内连接
day1.6龙盈(已offer)
1 . tcp三次握手
2 . 1*0.3两个类型相乘都是0.3
- 数据库设计的三范式
第一范式(确保每列保持原子性)
第二范式(确保表中的每列都和主键相关)
第三范式(却表每列都和主键列直接相关,而不是间接相关)