高频题(一)
文章目录
一、反转链表(206)
题目描述:

注意:更准确的表达应该是,反转的结果为1 ⬅2 ⬅ 3 ⬅ 4 ⬅ 5,也就是说不能单纯的改变节点值
1. 双指针迭代
思路:
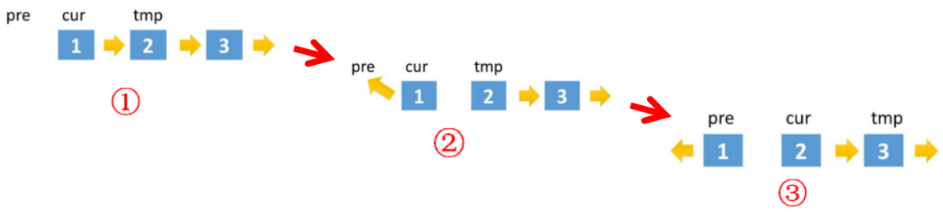
创建两个指针pre和cur,pre最初指向null,cur最初指向head (pre始终是cur的前一个节点),两个指针不断的向后遍历链表,每次迭代中cur指向pre,然后pre与cur同时向后移动一位。
注意:
将cur指向pre之前需要将cur.next保存在temp变量中,以保证可以访问到cur原本的下一个节点 (用来向后移动)。图解如下:
代码实现:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
ListNode temp = null;
while(cur!=null) {
//记录当前节点的下一个节点
temp = cur.next;
//将当前节点指向pre
cur.next = pre;
//pre和cur节点都后移一位
pre = cur;
cur = temp;
}
return pre;
}
}
时间复杂度O(n)
空间复杂度O(1)
2. 递归
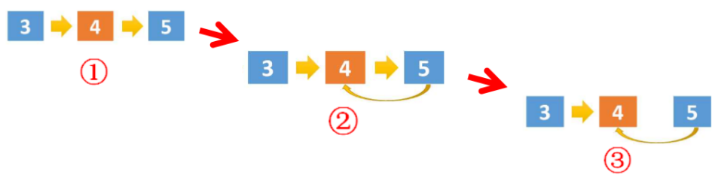
思路:
从第一个节点一直递归到最后一个节点,使用cur记录下最后一个节点 (最终结果从cur返回),遍历到最后一个节点时递归结束,开始回溯,倒数第二个节点.next.next = 倒数第二个节点 (将倒数第二个节点的后一个节点的指向修改为倒数第二个节点),持续反向指向直到第一个节点,返回cur。图解如下:
代码实现:
class Solution {
public ListNode reverseList(ListNode head) {
//第一个条件防止链表为空,第二个条件将递归进行到最后一个节点
if(head==null || head.next==null) {
return head;
}
//cur是最后一个节点,cur的值不再改变
//head是倒数第二个节点时最后一次递归返回的就是最后一个节点
ListNode cur = reverseList(head.next);
//4.next.next = 4;代表5指向4
head.next.next = head;
//防止5与4构成循环,不需要让4指向5
head.next = null;
//每层递归都返回不变的cur值,也就是最后一个节点
return cur;
}
}
时间复杂度O(n)
空间复杂度O(n),递归使用栈空间
二、无重复字符的最长字串(3)
题目描述:
给定一个字符串,请你找出其中不含有重复字符的最长子串的长度。

思路:滑动窗口

观察上述过程可以发现,假设选择字符串中的第 left 个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 right,即 right + 1位置发生了重复, 那么就需要重新选择第 left + 1 个字符作为起始位置,这时从 left + 1到 right 的字符显然是不重复的,由于少了原本的第 left 个字符(第 left 个字符也会从无重复子串中删除),那么就可以继续扩大 right 直到右侧出现了重复字符为止。
左边界和右边界只会向右扩大,不会缩小或重置。
代码实现:
注意:注意HashSet的两个方法名:contains、add
class Solution {
public int lengthOfLongestSubstring(String s) {
HashSet<Character> hashSet = new HashSet<>();
int right = 0;
int maxLen = 0; //记录最长无重复子串的长度
//每执行一次for循环,表示某次的left判断完毕,需要判断left+1位置
for (int left = 0; left < s.length(); left++) {
//每一轮都需要将上一轮的left从子串中移除
if (left != 0) {
hashSet.remove(s.charAt(left - 1));
}
//向右移动right,直到出现了重复字符
while (right < s.length() && !hashSet.contains(s.charAt(right))) {
hashSet.add(s.charAt(right));
right++;
}
//right值不会重置,只会变大
maxLen = Math.max(maxLen, right - left);
//由于执行right++,故right最终会来到第一个重复字符的位置
}
return maxLen;
}
}

三、LRU缓存机制(146)
1. 题目描述
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制
实现 LRUmap 类:
- LRUmap(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1
- void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限capacity时,应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间
2. LRU算法的介绍
-
全称为最近最少使用,是一种缓存淘汰策略,也就是说认为最近使用过的数据应该是有用的,很久都没使用过的数据应该是无用的,内存满了就优先删除那些很久没有使用过的数据
-
对应到数据结构表述的就是最常使用的元素将其移动至头部或尾部,这就会导致很久没有使用过的元素会被动的移动至另一边,最先删除的元素是最久没有被使用过的元素(注意不是使用次数最少的元素,这是LFU算法)
- get一个元素时算是访问该元素,需要将此元素移动至头部或尾部,表示最近使用过
- put一个元素时算是访问该元素,需要将此元素插入到头部或尾部,表示最近使用过
3. 数据结构的选择
3.1 为什么不使用数组?
数组查找一个元素的时间复杂度为O(1),但其删除元素后将元素整体移动的时间复杂度为O(n),不满足题意
3.2 为什么不使用单向链表?
链表 添加 / 删除 元素的时间复杂度为O(1),如果删除的是头节点则满足题意
但如果删除的是链表的中间节点,需要保存待删除节点的前一个节点,且遍历到待删除节点的时间复杂度为O(n),不满足题意
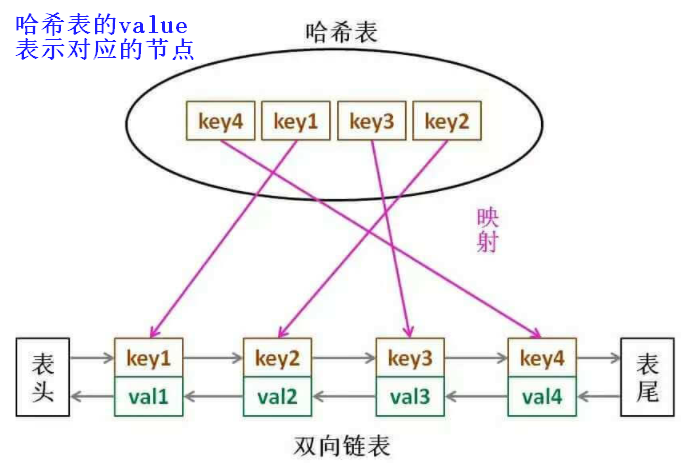
3.3 为什么使用HashMap + 双向链表?
HashMap寻找待删除节点只需要O(1)的时间复杂度
双向链表删除节点不需要遍历找到待删除结点的前一个节点,故删除任意位置的元素时间复杂度都是O(1)
综上所述:使用HashMap寻找节点,使用双向链表 删除 / 移动 节点,可满足时间复杂度为O(1)的要求
整体结构如下图所示:
4. 代码实现
将刚刚使用过的元素移动到头部,很久没有使用过的元素移动到尾部
public class LRUCache {
//双向链表的节点
class DLinkedNode {
//注意内部类的class首字母小写
int key; //key与Map的key内容一致
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {
}
public DLinkedNode(int _key, int _value) {
key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> map = new HashMap<Integer, DLinkedNode>();
private int size; //实际元素个数
private int capacity; //容量
private DLinkedNode head, tail;
//构造器
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
//使用伪头部、伪尾部节点
head = new DLinkedNode(); //伪头部节点是第一个节点的前一个节点
tail = new DLinkedNode(); //伪尾部节点是最后一个节点的后一个节点
//初始化时伪首尾节点要连在一起
head.next = tail;
tail.prev = head;
}
//get方法
public int get(int key) {
DLinkedNode node = map.get(key);
if (node == null) {
return -1;
}
//如果key存在,先通过HashMap定位,再移到头部
moveToHead(node);
return node.value;
}
//put方法
public void put(int key, int value) {
DLinkedNode node = map.get(key);
if (node == null) {
//如果key不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
//添加进哈希表
map.put(key, newNode);
//添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
//如果元素个数超出容量,删除双向链表的尾节点
DLinkedNode tail = removeTail();
//删除哈希表中对应的项
map.remove(tail.key);
--size;
}
}
else {
//如果key存在,先通过HashMap定位,再修改value并移到头部
node.value = value;
moveToHead(node);
}
}
//将节点移动至头部
private void moveToHead(DLinkedNode node) {
removeNode(node); //将此节点从链表断开
addToHead(node); //将断开的节点移动至头部
}
//将节点从链表断开
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
//将节点移动至头部(修改四个指针)
//先修改插入节点的两个指针
private void addToHead(DLinkedNode node) {
node.prev = head; //伪头部节点成为此节点的前一个节点
node.next = head.next; //原来的第一个节点成为此节点的后一个节点
head.next.prev = node; //原来的第一个节点向前的指针指向此节点
head.next = node; //此节点成为伪头部节点的后一个节点
}
//删除链表的尾节点
//尾节点仅此处使用
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev; //删除的其实是伪尾部的前一个节点
removeNode(res);
return res;
}
}
四、数组中的第k个最大元素(215)
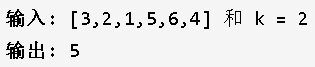
题目描述:
在未排序的数组中找到第 k 个最大的元素。注意,需要找的是数组第 k 个最大的元素的值,而不是第k个元素
1. 快排变形
思路:
采用快排的方法,经过交换后判断基准数的位置,如果基准数的索引经过划分并交换之后为m,判断m是否等于 arr.length - k ,如果等于则直接返回m位置的元素,如果小于,递归右子区间,否则递归左子区间
代码实现:
class Solution {
public int findKthLargest(int[] arr, int k) {
//递归的划分数组(小于/大于区域再划分),最终确定最小的k个数
return partitionArray(arr, 0, arr.length - 1, arr.length - k);
}
int partitionArray(int[] arr, int lo, int hi, int k) {
//可以使用随机快排
//调用partition方法,进行一次划分,返回值是基准数的索引位置
int m = partition(arr, lo, hi);
//如果等于则直接返回m位置的元素,如果小于,递归右子区间,否则递归左子区间
if (m == k) {
return arr[m];
} else {
return m < k ? partitionArray(arr, m + 1, hi, k) : partitionArray(arr, lo, m - 1, k);
}
}
//返回值是基准数的索引位置
int partition(int[] arr, int l, int r) {
int less = l - 1;
int more = r;
while (l < more) {
if (arr[l] < arr[r]) {
swap(arr, ++less, l++);
} else if (arr[l] > arr[r]) {
swap(arr, --more, l);
} else {
l++;
}
}
swap(arr, r, more);
return more;
}
void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
-
时间复杂度:O(n)(使用了随机快排之后)
-
空间复杂度:O(logn),递归使用栈空间的空间代价的期望为 O(logn)
2. 大顶堆
**思路:**采用堆排序的思路,构造一个大顶堆,做 k - 1 次堆顶元素和最后一个元素的交换操作(并把堆长度减一),然后返回堆顶元素即可。
代码实现:
class Solution {
public int findKthLargest(int[] nums, int k) {
for (int i = 0; i < nums.length; i++) {
heapInsert(nums, i);
}
int size = nums.length;
//此处不能进行交换
//循环条件是k-1次
for (int i = 0; i < k - 1; i++) {
//交换的时候减减,调整的时候要把size传进去
swap(nums, 0, --size);
heapify(nums, 0, size);
}
return nums[0];
}
public void heapInsert(int[] arr, int i) {
while (arr[i] > arr[(i - 1) / 2]) {
swap(arr, i, (i - 1) / 2);
i = (i - 1) / 2;
}
}
public void heapify(int[] arr, int i, int size) {
int left = i * 2 + 1;
while (left < size) {
int largest = left + 1 < size && arr[left + 1] > arr[left] ? left + 1 : left;
largest = arr[largest] > arr[i] ? largest : i;
if (arr[largest] == arr[i]) {
break;
}
swap(arr, i, largest);
i = largest;
left = i * 2 + 1;
}
}
public void swap(int[] arr, int l, int r) {
int temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
}
}
- 时间复杂度:O(nlogn),建堆的时间代价是 O(n),删除的总代价是 O(klogn),因为 k<n,故渐进时间复杂为 O(n+klogn)=O(nlogn)。
- 空间复杂度:O(logn),即递归使用栈空间的空间代价。
五、K个一组翻转链表(25)
题目描述:
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
进阶:
你可以设计一个只使用常数额外空间的算法来解决此问题吗?
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例:
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
输入:head = [1,2,3,4,5], k = 1
输出:[1,2,3,4,5]
解法:
需要把链表节点按照 k 个一组分组,所以可以使用一个指针 head 依次指向每组的头节点。这个指针每次向前移动 k 步,直至链表结尾。对于每个分组,我们先判断它的长度是否大于等于 k。若是,我们就翻转这部分链表,否则不需要翻转。反转链表的思路和方法与之前的一致。
对于一个子链表,除了翻转其本身之外,还需要将反转后的子链表的头部与上一个子链表连接,以及子链表的尾部与下一个子链表连接,如下图所示:

因此,在翻转子链表的时候,我们不仅需要子链表头节点 head,还需要有 head 的上一个节点 pre,以便翻转完后把子链表再接回 pre,同理还需要一个节点来保存待反转链表的后一个节点,以便反转之后将子链表接回原链表。
但是对于第一个子链表,它的头节点 head 前面是没有节点 pre 的。所以新建一个节点 hair,把它接到链表的头部,让 hair 作为 pre 的初始值,这样 head 前面就有了一个节点。
反复移动指针 head 与 pre,对 head 所指向的子链表进行翻转,直到结尾。
对于最终的返回结果,定义的hair一开始被连接到了头节点的前面,而无论之后链表有没有翻转,hair 的 next 指针都会指向正确的头节点。故只要返回hair的下一个节点即可。
图解全思路:
假设k==2


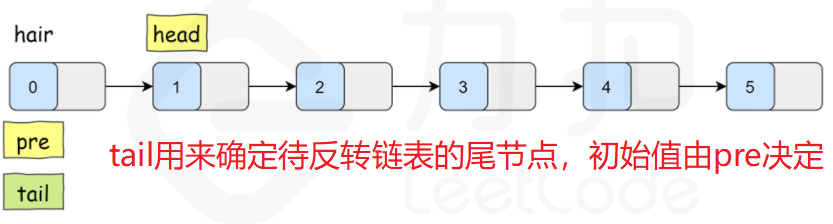
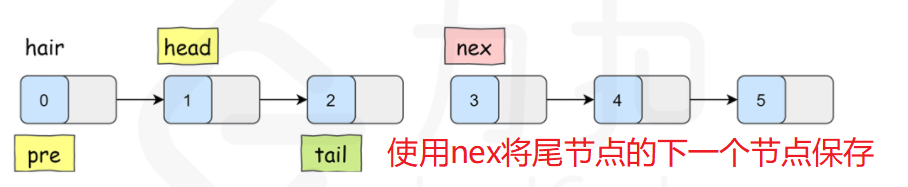

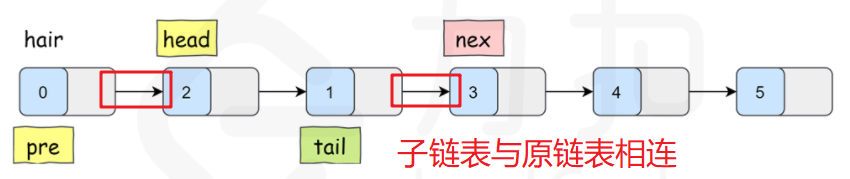
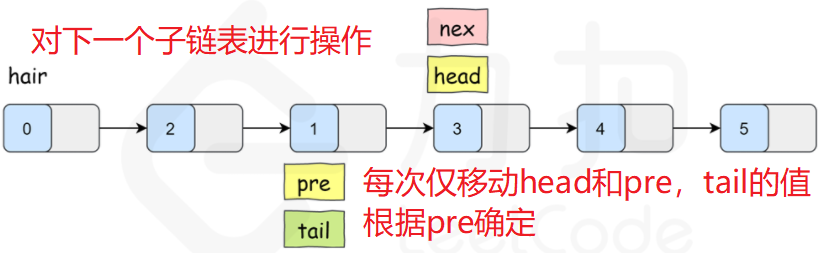
注意:tail的值是根据pre来确定的,pre在每次交换之后确定,然后才能确定tail。
代码实现:
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode hair = new ListNode(); //创建虚拟头节点
hair.next = head;
ListNode pre = hair; //pre成为head的前一个节点
//刚开始只确定了pre
while (head != null) {
ListNode tail = pre; //tail表示待反转链表的尾节点,一开始为head的前一个节点
//查看以head为头节点的剩余部分长度是否大于等于k
//并且移动tail至待反转链表的尾节点
for (int i = 0; i < k; ++i) {
tail = tail.next;
//tail会成为待反转链表的尾节点,所以根据tail确定长度
if (tail == null) {
return hair.next;
}
}
//要求一开始tail必须是head的前一个节点,只有这样,移动k次tail才会成为待反转链表的尾节点,如果一开始tail==head,移动k次之后,tail会成为待反转链表的尾节点的后一个节点
ListNode nex = tail.next; //保留待反转链表的尾节点的后一个节点,防止断开
//接下来开始反转head→tail的链表,调用之前的反转链表的方法
//反转方法的返回值成为head,而反转后的tail是未反转时的head
//所以将未反转时的head保存起来
ListNode temp = head;
head = reverseList(head, tail); //反转以后的头节点是head
tail = temp; //反转后的tail是未反转时的head
//把子链表重新接回原链表
pre.next = head;
tail.next = nex;
//将pre和head移至下一组待反转的链表
pre = tail;
head = nex;
}
return hair.next;
}
//反转方法
//第二个参数的唯一作用是确定最后一个节点的临界值,思路仍与之前一致
public ListNode reverseList(ListNode head, ListNode tail) {
//将递归进行到最后一个节点
if(head == tail) {
return head;
}
//cur是最后一个节点,cur的值不再改变
//head是倒数第二个节点时最后一次递归返回的就是最后一个节点
ListNode cur = reverseList(head.next, tail);
//4.next.next = 4;代表5指向4
head.next.next = head;
//防止5与4构成循环,不需要让4指向5
head.next = null;
//每层递归都返回不变的cur值,也就是最后一个节点
return cur;
}
}
时间复杂度:O(n)(尾节点会将链表所有节点走一次),空间复杂度O(1)
六、两数之和(1)
题目描述:
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标。如:

1. 一遍哈希表
思路:
创建一个哈希表,存放数组的元素值及对应的索引值,遍历数组,将数组元素及对应的索引值放入哈希表中,一旦发现 target - nums[i] 在哈希表中存在,停止遍历,得到结果
HashMap中需要了解的方法:
boolean containsKey(key); 判断哈希表中是否存在此键所构成的映射关系
Object get(key); 返回此key对应的value值
put(key, value); 向哈希表中存放键值对
代码实现:
public class Solution {
public int[] twoSum(int[] numbers, int target) {
int[] result = new int[2];
HashMap<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < numbers.length; i++) {
if(map.containsKey(target - numbers[i])) {
result[1] = i;
result[0] = map.get(target - numbers[i]);
return result;
}
map.put(numbers[i], i);
}
return result;
}
}
时间复杂度O(n),只遍历了包含有n个元素的列表一次,在表中进行的每次查找只花费 O(1) 的时间
空间复杂度O(n),所需的额外空间取决于哈希表中存储的元素数量,该表最多需要存储n个元素
2. 两遍哈希表
思路:
创建一个哈希表,第一遍遍历数组将数组中的所有元素放入哈希表,第二遍遍历数组在哈希表中找是否存在target - nums[i]值,注意:由于第一遍会把所有值均放入哈希表,若target值为8,则4+4=8,但需要两个元素的值为4,而不是一个4本身加两次,故哈希表中取出的值不能是本身
代码实现:
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
map.put(nums[i], i);
}
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement) && map.get(complement) != i) {
return new int[] {
i, map.get(complement) };
}
}
throw new IllegalArgumentException("No two sum solution");
}
}
时间复杂度O(n),把包含有n个元素的列表遍历两次,由于哈希表将查找时间缩短到 O(1) ,所以时间复杂度为O(n)
空间复杂度O(n),所需的额外空间取决于哈希表中存储的元素数量,该表中存储了n个元素
七、三数之和(15)
题目描述:
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组,如下图所示:

思路:
首先将给定的数组排序,然后在数组中从头开始固定一个数,利用双指针遍历数组中除此数之外的其余数,在其中找其余两个满足条件的数。
具体过程:
(1) 调用Arrays.sort对数组排序
(2) 在for循环遍历数组中固定数nums[i],使用左右指针指向nums[i]后面数的左右两端,分别为nums[L] 和 nums[R],判断三个数和是否为0,满足则添加到结果集
(3) 如果nums[i] > 0,则三数之和必然大于0 (nums[i]之后的数一定比他大),结束循环
(4) 如果nums[i] == nums[i - 1],会出现重复情况,应该跳过(遍历到末尾时如果比较i与i+1,会导致越界,故比较i - 1)
(5) 如果三数之和sum == 0时,nums[L] == nums[L + 1],会导致结果重复,L++
(6) 如果三数之和sum == 0时,nums[R] == nums[R - 1],会导致结果重复,R–
注意:一旦sum == 0就会L++及R-- (在5、6步的基础上执行,可以跳过重复项)
nums[i]有两种情况需讨论,sum == 0时有两种情况需讨论
代码实现:
class Solution {
public static List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> result = new ArrayList()<>;
//特殊条件判断
int len = nums.length;
if(nums == null || len < 3) return result;
Arrays.sort(nums); // 一定要记得对数组排序
for (int i = 0; i < len ; i++) {
// 先判断nums[i],如果不满足,则无需创建L和R指针
if(nums[i] > 0) break; // 当前数字大于0,结束循环
if(i > 0 && nums[i] == nums[i-1]) continue; // 去重,必须要求i > 0,否则i - 1越界
//定义剩余元素的左右指针
int L = i+1;
int R = len-1;
while(L < R){
int sum = nums[i] + nums[L] + nums[R];
if(sum == 0){
result.add(Arrays.asList(nums[i],nums[L],nums[R]));
while (L<R && nums[L] == nums[L+1]) L++; // 去重
while (L<R && nums[R] == nums[R-1]) R--; // 去重
L++;
R--;
}
else if (sum < 0) L++; // 不要忘记这两种判断
else if (sum > 0) R--;
}
}
return result;
}
}

八、环形链表II(142)
题目描述:
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
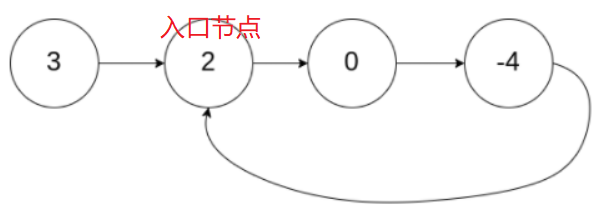
1. 哈希表
思路:
遍历节点时使用哈希表记录节点的地址,如果地址没有重复的说明链表中没有环,如果哈希表中的地址有重复的,说明有环,把重复元素返回即可
代码实现:
class Solution {
public ListNode detectCycle(ListNode head) {
Set<ListNode> nodesSeen = new HashSet<>();
while (head != null) {
if (nodesSeen.contains(head)) {
return head;
} else {
nodesSeen.add(head);
}
head = head.next;
}
return null; //如果没有环,则一定会跳出while循环
}
}
- 时间复杂度:O(N)
- 空间复杂度:O(N)
2. 快慢指针
思路:
使用两个指针,fast 与 slow。它们起始都位于链表的头部。随后,slow 指针每次向后移动一个位置,而 fast 指针向后移动两个位置。如果链表中存在环,则 fast 指针最终将再次与指针在环中相遇。一旦 fast == null,说明链表中没有环,返回null即可。
如下图所示,设链表中环外部分的长度为 a。slow 指针进入环后,又走了 b 的距离与 fast 相遇。假设此时,fast 指针已经走完了环的 n 圈,因此它走过的总距离为 a + n(b+c) + b → a + (n+1)b +nc。
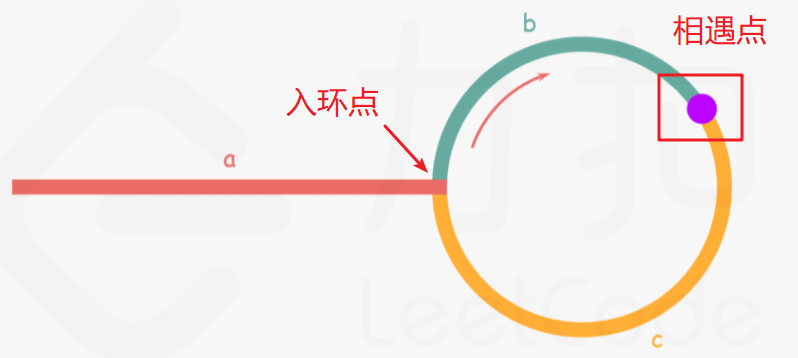
根据题意,任意时刻,fast 指针走过的距离都为 slow 指针的 2 倍。因此,可以得到如下的推导过程:
a + (n+1)b + nc = 2(a+b) ⟹ a = c + (n−1)(b+c)。(slow指针无需在环中循环,第一圈就会与fast指针相遇)
有了上述的的等量关系,可以发现:从相遇点到入环点的距离加上 n−1 圈的环长,恰好等于从链表头部到入环点的距离,因此,当发现 slow 与 fast 相遇时,再额外使用一个指针 ptr。
起始,ptr指向链表头部;随后,它和 slow 每次向后移动一个位置,那么 slow 走了 c 的距离之后,ptr 到环入口的距离只剩整 n - 1 圈的距离了,而且此时慢指针也刚好走到入口处了,这时,只要二者一起走完 n - 1 圈的距离之后就会相遇(无法确定n的大小,只要通过循环不停的让二者向后移动一个位置,一定会相遇),而且相遇点正好是入口,返回 ptr 指向的节点即可。
代码实现:
public class Solution {
public ListNode detectCycle(ListNode head) {
if (head == null) {
return null;
}
ListNode slow = head, fast = head;
while (fast != null) {
//如果fast == null,一定没有环
slow = slow.next;
if (fast.next != null) {
//防止空指针异常
fast = fast.next.next;
} else {
//fast的下一个节点 == null,一定没有环
return null;
}
//快慢指针相遇,定义ptr指针
if (fast == slow) {
ListNode ptr = head;
//ptr和慢指针一起向后移动一个位置
while (ptr != slow) {
ptr = ptr.next;
slow = slow.next;
}
//ptr与慢指针相遇,返回ptr即可
return ptr;
}
}
return null;
}
}

九、环形链表(141)
题目描述:
给定一个链表,判断链表中是否有环,如下图所示:
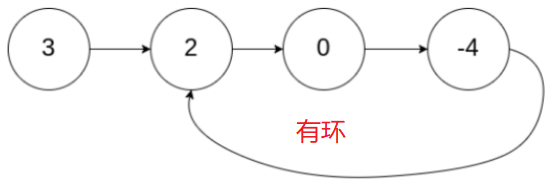
1. 哈希表
思路:
思路与 “链表中环的入口节点” 题目一致,仅返回值不同,不再赘述
代码实现:
class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> nodesSeen = new HashSet<>();
while (head != null) {
if (nodesSeen.contains(head)) {
return true;
} else {
nodesSeen.add(head);
}
head = head.next;
}
return false; //如果没有环,则一定会跳出while循环
}
}
2. 快慢指针
思路及代码实现见题目 “链表中环的入口节点”,仅返回值不同,不再赘述。
注意:快慢指针相遇后即可返回true,无需再去定义一个新的节点随慢指针移动。
public class Solution {
public boolean hasCycle(ListNode head) {
if (head == null) {
return false;
}
ListNode slow = head, fast = head;
while (fast != null) {
//fast == null,一定没有环
slow = slow.next;
if (fast.next != null) {
//防止空指针异常
fast = fast.next.next;
} else {
//fast的下一个节点 == null,一定没有环
return false;
}
//快慢指针相遇,说明有环
if (fast == slow) {
return true;
}
}
return false;
}
}
十、合并两个有序链表(21)
题目描述:
将两个升序链表合并为一个新的升序链表并返回,新链表是通过拼接给定的两个链表的所有节点组成的

1. 递归
思路:
从两个链表的头节点开始,依次比较大小,较小节点要指向其余节点,持续直到有一方的next为空时,将另一个链表的此时指向的节点返回(这些剩余的节点一定是最大的),继续依次返回,直到所有节点都返回成功
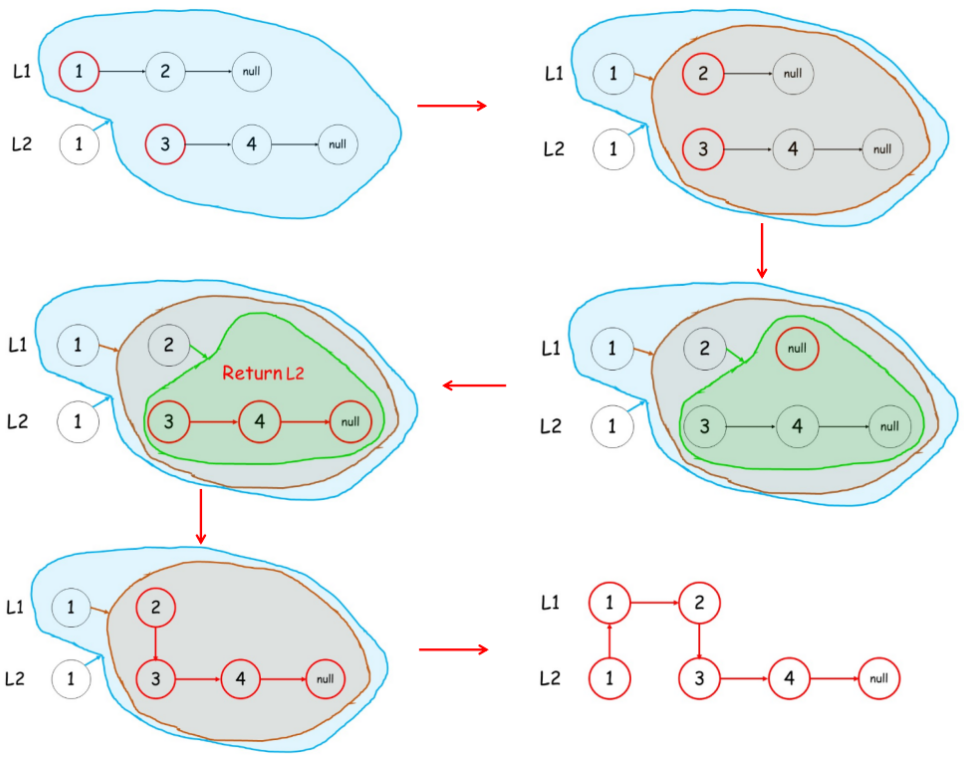
代码实现:
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if (l1 == null) {
return l2;
}
else if (l2 == null) {
return l1;
}
else if (l1.val < l2.val) {
//不能先判断l1.val,如果l1==null,会出现空指针异常
l1.next = mergeTwoLists(l1.next, l2);
return l1;
}
else {
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
}
}

2. 迭代
思路:
创建一个新链表(头节点是prehead,辅助节点是prev),当l1和l2都不是空链表时,判断哪一个链表的头节点的值更小,将较小值的节点添加到prev的后面并将prev后移一位(由于链表无法直接定位到一个节点,所以必须使用一个指针指向待操作节点),当一个节点被添加到新链表之后,将对应链表中的节点向后移一位,且无论哪一个元素接在了prev后面,都需要将prev后移一位,循环终止时,两个链表中至多有一个是非空的,且剩余的元素一定是最大的,接在prev之后即可。
代码实现:
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode prehead = new ListNode();
ListNode prev = prehead;
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
prev.next = l1;
l1 = l1.next;
} else {
prev.next = l2;
l2 = l2.next;
}
prev = prev.next;
}
prev.next = l1 == null ? l2 : l1; // 一定要记得将剩余元素添加到prev之后
return prehead.next;
}
