目录
我们只是fork了,创建了子进程,但是子进程对应的代码和数据呢?
进程的概念
什么叫做进程
把一个程序加载到内存就变成进程!!!(这是大多数教科书上面的定义,但是不是全面的定义)
如何管理进程?
先引出6个字:先描述,再组织。
操作系统在形成任何进程之时都要为之创建PCB(进程控制块)

为什么要有PCB?
因为要描述进程,就要描述相关的属性信息,而属性信息又存放在结构体中,所以采用PCB来描述进程。
到底什么是PCB?
①站在操作系统的角度上:PCB就是进程控制块
②站在语言的角度上:就是一个结构体
在Linux系统中,PCB就具体成为了task_struct{ },名叫任务结构体,里面包含进程的所有属性
task_struct内容分类
①标示符: 描述本进程的唯一标示符(PID),用来区别其他进程。
我们可以通过getpid来获取进程的pid值,首先查看man getpid查看函数相关信息
| 函数名称 | getpid |
| 函数功能 | 获取当前进程的pid |
| 头文件 | #include<unistd.h> |
| 函数原型 | pid_t getpid(); |
| 参数 | 无 |
| 返回值 | >0:成功(返回进程号) =-1:失败 |
getppid与getpid功能类似,只不过它返回的是父进程的pid。
我们首先写一段小代码:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>//后面两个是系统级别的头文件
int main()
{
while (1) {
printf("hello pid:%d,ppid:%d\n", getpid(), getppid());
sleep(1);
}
return 0;
}
运行起来我们可以看到PID和PPID:

PID可以类比生活中的人的身份证号码,PPID就可以类比父亲的身份证号码
我们来进一步查看此进程的父进程的PID

发现他就是我们的bash命令行解释器
得出结论:我们在命令行上运行的命令,基本上父进程都是bash
②状态: 任务状态,退出代码,退出信号等。
可以举例:我们平时的main函数return 0,0就是一个退出码,它先返回给我们的父进程,然后再返回给操作系统,表示进程正确执行然后退出
可以通过echo命令查看退出码
[sjj@VM-20-15-centos 2022_3_21]$ echo $?
130
echo $? 输出的是最近一次进程的退出码,即上一条命令,130就是我们的退出码了
③优先级: 相对于其他进程的优先级。
对比学习:优先级VS权限问题
1、优先级是已经拥有做某事的权利了,只是顺序的问题
2、而权限是能不能做某事的权利
④程序计数器: 程序中即将被执行的下一条指令的地址。
CPU里面的寄存器指针,指向即将被执行的下一条指令,执行完后自动加加
⑤内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
通过task_struct里面的内存指针,找到相应进程的代码和数据
⑥上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。

时间片:规定了每个进程的运行时间(比如10ms),这样对每个进程来说相对公平,这就保证了在单CPU下,多个进程同时被执行,它的本质是通过CPU的快速切换实现的!!!
例如:当task_struct1运行一个时间片之后,让其尾插到队列的尾部,让其余进程都可以被执行一下,第二次运行task_struct1怎么找到上下文数据,让其继续上次的未完进程继续运行呢?原来寄存器把里面存放的上下文临时数据传给了task_struct1(核心部分的数据),保留了上下文信息在自己进程的PCB中,下一次运行时把信息再次传回给寄存器,就能找到上次未运行完的数据,继续运行了!这样就保证了,虽然寄存器只有一套,但是寄存器里每次运行的数据都是对应的进程的数据
所以通过上下文,我们能更加清楚的感受到进程是被切换的
⑦I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
⑧记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
操作系统内部有个调度模块,较为均衡的调度每个进程,让进程合理的获得CPU资源,最后被执行
⑨其他信息
查看进程?
方法一:通过/proc系统文件夹查看
[sjj@VM-20-15-centos 2022_3_20]$ ls /proc
进一步查看当前进程我们可以看到exe和cwd文件
cwd:current working directory 当前工作目录
为什么有时候我们并没有指定文件的创建路径,他却可以自动创建在当前路径下?原因就是这个cwd文件,它里面默认包含了当前的工作目录,所以进程就拿着cwd找到了当前路径
exe:可执行程序

同样可以类比Linux中查看进程和我们在Windows中可以打开任务管理器查看电脑中的进程

方法二:ps指令+选项查看
我们首先要写一个进程将其运行起来:
#include<stdio.h>
#include<unistd.h>
int main()
{
while (1) {
printf("hello\n");
sleep(1);
}
return 0;
}
在Linux下我们通过ps(process)指令可以查看
[sjj@VM-20-15-centos 2022_3_20]$ ps axj | grep "myproc"我们可以看到有两个进程

下面那个进程就是命令行的进程,我们不必太关心,上面那个进程就是我们写的程序
我们可以更进一步的把属性名字给打出来:
[sjj@VM-20-15-centos 2022_3_20]$ ps axj | head -1 && ps axj | grep "myproc"
曾经我们的所有的启动程序的过程,本质都是在系统上创建进程!
对比学习:进程VS程序

所以:进程=程序文件内容+与进程相关的数据结构, 在Linux下就是task_struct,它是由操作系统帮我们创建的,然后由于每个结构体都有进程的所有属性数据,就可以用双链表来将各个进程组织起来,这样一来操作系统就不用关心加载到内存中的代码和数据了,只需要关心PCB里面的属性信息就可以了,最核心的就是拿到双链表的头指针,就可以访问到所有的PCB结点,对于进程的管理也就可以变成对于链表数据结构的增删查改了!!!

例如:刚刚打开一个程序,创建了一个进程,将该程序加载到内存之中,操作系统就会为之创建相应的PCB,先描述了PCB,再将这个PCB结点尾插到双链表中,组织起来。当一个进程结束时,操作系统同样通过头指针找到该结点将其从双链表中删除,并保持原双链表结构不变
我们往上提升一个角度,站在CPU的角度来看待内存+OS,由于进程要运行起来,必需要CPU资源,操作系统将要运行的进程进行排队,组织成了一个运行队列,只需要将进程的核心PCB(Linux中是task_struct)不断的尾插到队列中,但task_struct里面有指针依旧指向该进程的代码和数据,所以只需要排队,CPU就能找到该进程的所有属性,最后CPU就能完成进程!

总结:有了进程控制块PCB,所有的进程管理任务与进程对应的程序代码数据毫无关系!而是与进程对应的内核(操作系统)创建的该进程的PCB强相关!
通过系统调用创建进程——fork
先来段代码观察现象:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
fork();
printf("hello\n");
sleep(1);
return 0;
}执行效果:

ps:在vim中不退出查看man手册
先Esc进入命令模式,再shift+:进入底行模式,输入 !man fork就可以了

打开man手册:

再来看一段小代码:
#include<iostream>
#include<unistd.h>
using namespace std;
int main()
{
fork();
cout << "hello proc:" << getpid() << " " << "hello parent:" << getppid() << endl;
sleep(1);
return 0;
}我们可以看到有行结果:

其中的3086就是上一命令行的PID,就是./myproc的进程
通过命令我们查询验证一下3086是谁
[sjj@VM-20-15-centos 2022_3_24]$ ps axj | head -1 && ps axj | grep 3086
bash创建了子进程,子进程又创建了子进程如此往复
为什么会有两行打印的原因就是:

很显然这在C/C++中是不存在这种现象的,它既然能跑两行,就证明了它是两个进程,这从打印的结果也可以看出来
那么如何理解fork创建子进程呢?
1、我们一般创建进程都是命令行上敲 ./程序或者run command,fork:在操作系统上面而言,上面的创建进程没有差别!
2、fork创建了一个进程,本质就是系统里面多了一个进程(进程就是与代码相关的数据结构PCB+代码和数据)
3、这里的数据结构就是task_struct,那么代码和数据呢?
我们只是fork了,创建了子进程,但是子进程对应的代码和数据呢?
答案:就是子进程在默认情况下,会继承父进程的代码和数据结构,新创建的子进程的内核数据结构task_struct也会以父进程为模板,去初始化子进程的task_struct
4、fork之后,子进程和父进程的代码和数据是共享的
5、代码是不可以被修改的,所以父子代码只有一份
6、对于数据来说,默认情况也是共享的,不过需要考虑修改的情况!
数据是通过写时拷贝,来完成进程数据的独立性
写时拷贝
写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程地址空间,而是让父进程和子进程共享同一个拷贝。
只有在需要写入的时候,数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。
如果父子进程创建时拷贝两份数据,那么fork函数的效率就会大打折扣,而且并不是所有的数据都要写入修改的
7、进程是具有独立性的!(类比Windows中各个进程打开都可以使用,而且互不影响)
代码共享和写时拷贝都是为了保证进程的独立性!
我们创建的子进程,就是为了和父进程干一样的事情?
一般是没有意义的!!!我们还是要让父进程和子进程做不一样的事情!!!
怎么让父进程和子进程做不一样的事情?
我们是通过fork的返回值来实现的


如何理解有两个返回值?

返回值也是数据,return的时候也会被写入,发生写时拷贝!
如何理解有两个返回值的设置?
一般来说父进程只有一个,而子进程有n个,父:子=1:n,父进程想要找到子进程,必须要拿到该子进程的pid(唯一表示符),从而达到控制子进程的目的,而子进程不需要找到父亲,因为父进程只有一个(可以利用getppid函数获取父进程的pid),直接返回0
我们可以通过if else分流来让父子做不一样的事情
#include<iostream>
#include<unistd.h>
#include<sys/types.h>
using namespace std;
int main()
{
pid_t id = fork();//当做int
if (id == 0) {
//child
while (1) {
cout << "I am child pid:" << getpid() << " ppid: " << getppid() << endl;
sleep(1);
}
}
else if (id > 0) {
//father
while (1) {
cout << "I am father pid:" << getpid() << " ppid: " << getppid() << endl;
sleep(2);
}
}
else {
//error
}
sleep(1);
return 0;
}结果展示:

注意:父子进程并不是交替出现的!使用fork之后,先后运行次序由CPU中的调度器决定
进程状态
进程状态信息在哪里呢?
答案:task_struct(PCB)里面
进程状态的意义?
方便操作系统快速判断进程,完成特定的功能,比如调度。
具体状态:
①R运行状态(running):运行状态是不一定要占用CPU的,也是可以在运行队列里面的!

②S睡眠状态(sleeping): 意味着进程在等待事件完成,这里的睡眠有时候也叫做可中断睡眠 。(浅度睡眠)
③D磁盘休眠状态(Disk sleep):在这个状态的进程通常会等待IO的结束,有时候也叫不可中断睡眠状态。(深度睡眠)
注意:进程如果处于D状态,不可被杀掉!
S和D状态都是当我们要完成某任务,条件不具备,需要进程进行某种等待

注意:千万不要认为进程只会等待CPU资源,当进程在等待CPU资源的时候就会在等等待队列中排队,当进程需要其他资源时候,就会在等待队列里面排队!
动态演示:如何在等待队列和运行队列间切换
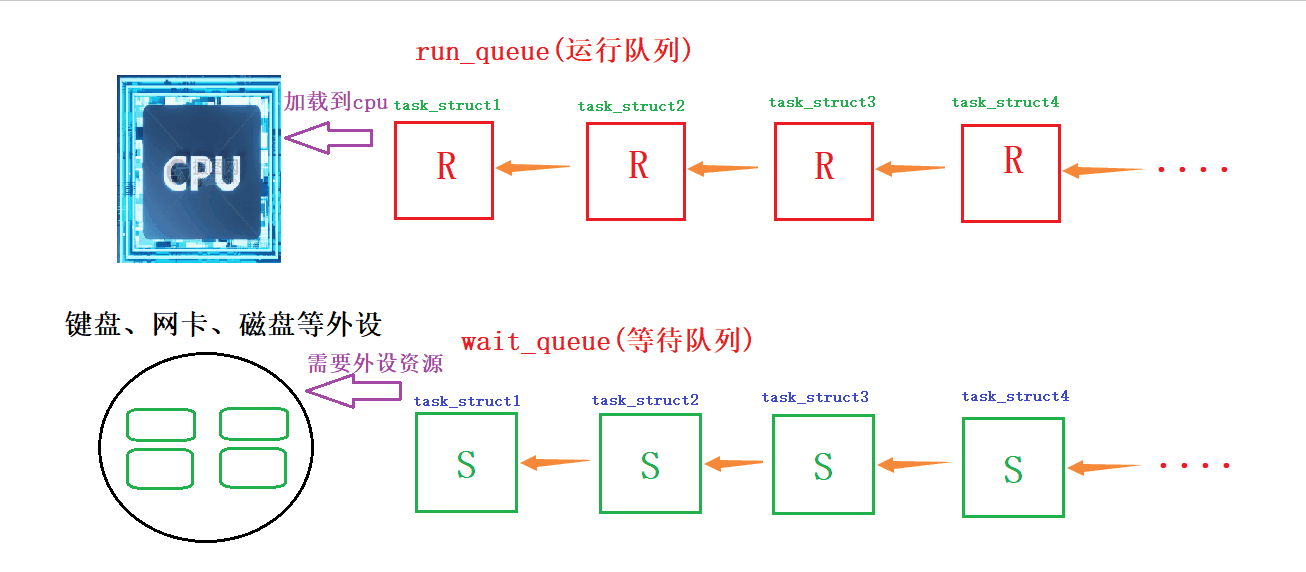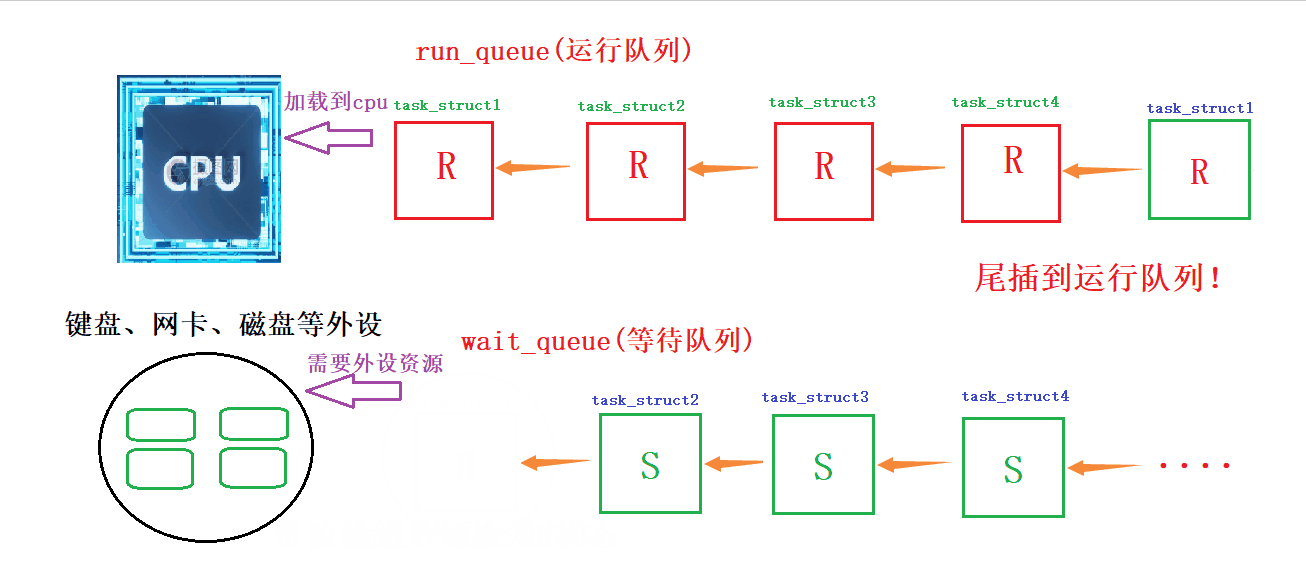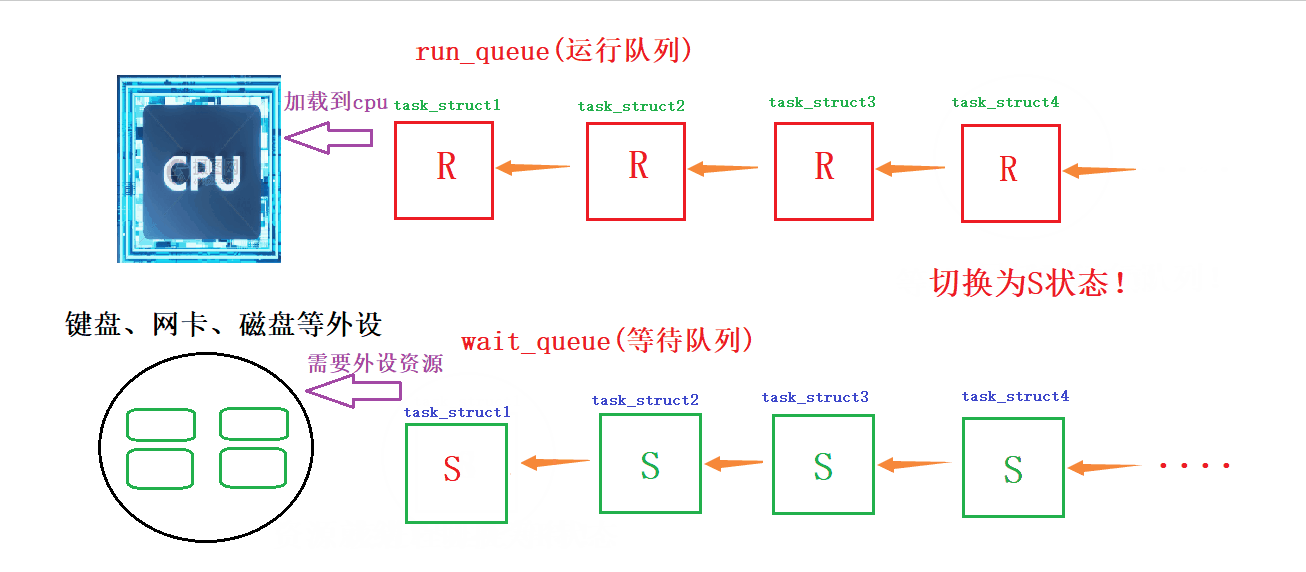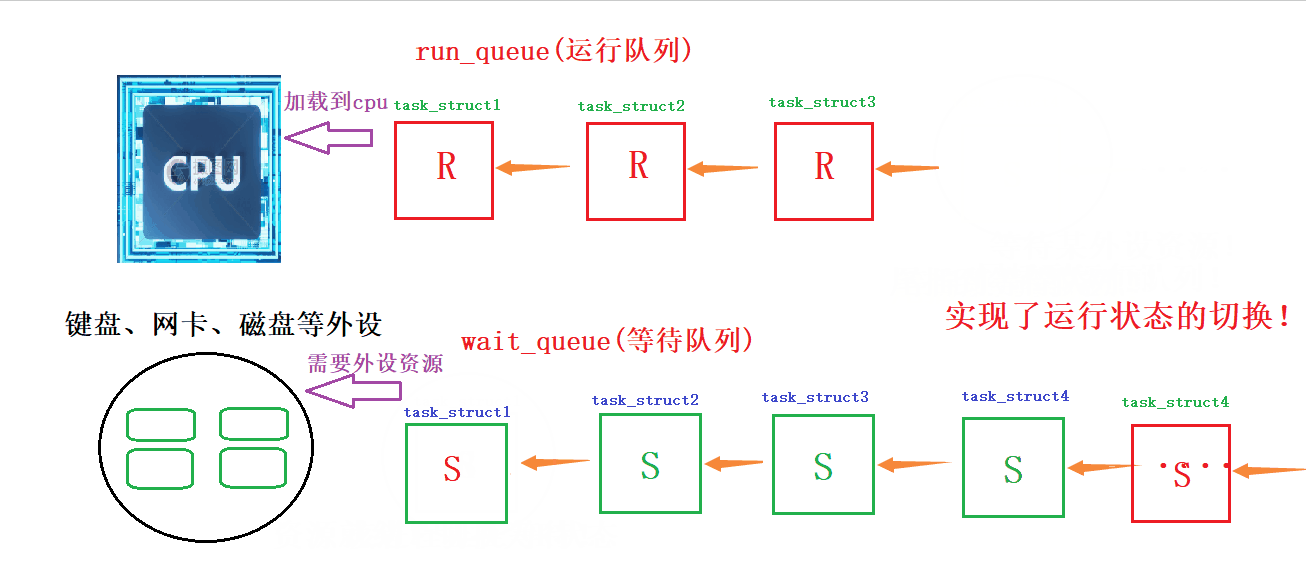 详细解读:当它所需要的的资源(外设)空闲时,操作系统就会把它的S状态或者D状态设置为R状态,然后从等待队列里面挑选出来,尾插到运行队列里面,等待CPU资源,等CPU资源就绪后,他就可以通过CPU调用该进程所需要的其他资源;当某一进程在运行队列中等待某种资源,CPU就会修改其状态,从R状态修改为S,并将该进程的PCB尾插到等待队列中进行等待
详细解读:当它所需要的的资源(外设)空闲时,操作系统就会把它的S状态或者D状态设置为R状态,然后从等待队列里面挑选出来,尾插到运行队列里面,等待CPU资源,等CPU资源就绪后,他就可以通过CPU调用该进程所需要的其他资源;当某一进程在运行队列中等待某种资源,CPU就会修改其状态,从R状态修改为S,并将该进程的PCB尾插到等待队列中进行等待
所谓的进程,在运行的时候,有可能因为运行的需要,可以在不同的队列里面!!在不同的队列里,所处的状态是不一样的!
另外我们把运行队列放到等待队列中就叫做挂起,从上层看就是阻塞状态!从等待队列放到运行队列就叫做唤醒!
④T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
⑤X死亡状态(dead):X状态是回收资源,就是进程相关的数据结构+该进程的代码和数据,X状态一般很难看到
⑥僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程(使用wait()系统调用,后面讲)没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。
所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态
为什么会有僵尸状态?
答案:为了辨别退出死亡的原因!(进程退出的信息是数据,就存储在PCB里面)
验证这些状态
写一个死循环
#include<iostream>
using namespace std;
int main()
{
while (1);
return 0;
}增加一个命令窗口,查看进程:
[sjj@VM-20-15-centos 2022_3_25]$ ps axj | head -1 && ps axj | grep -v grep | grep myproc
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
23368 24691 24691 23368 pts/0 24691 R+ 1001 0:56 ./myproc确实我们可以看到R+的状态!
补充:
带个 + 表示在前台运行,什么都不带就是后台进程,后台进程的特点就是可以在正在跑的命令行上敲击指令,也是可以运行的,而前台运行敲击指令不会运行
我们可以加个&,让程序在后台运行,例如:
[sjj@VM-20-15-centos 2022_3_25]$ ./myproc &fg 命令可以把后台命令提到前台,方便你ctrl+c将其关掉
我们再来看一个奇怪的现象:
#include<iostream>
using namespace std;
int main()
{
while (1)
{
cout << "hello" << endl;
}
return 0;
}为什么大多数都是S+状态呢?偶尔出现R+状态?

原因:我们进行打印的时候,是往显示器上打印,显示器是外设,IO等待外设就绪是要花时间的,而CPU切换运行是非常快的(远远超过人肉眼能看到的),所以我们看到大部分是S状态。
我们可以用kill命令来杀掉进程,先用-l选项来查看有哪些信号:
[sjj@VM-20-15-centos 2022_3_25]$ kill -l
标记出了一些常用信号选项。
用19号信号杀掉进程!

我们再次查看进程就可以看到T状态的进程了!

我们此时让用18号信号让进程继续运行:
[sjj@VM-20-15-centos 2022_3_25]$ kill -18 28587再次查看进程:

我们发现是S状态了,不是S+状态了,再次kill - 19 杀不掉了,此时要用kill -9 来终止进程
僵尸进程
如果没有人来检测或者回收父进程,那么该子进程就进入僵尸状态
如何查看?来一段简单的代码
#include<iostream>
#include<unistd.h>
#include<sys/types.h>
using namespace std;
int main()
{
pid_t id = fork();
if (id == 0)
{
//child
while (1) {
cout << "I am child running!" << endl;
sleep(2);
}
}
else
{
//father
cout << "father do nothing" << endl;
sleep(50);//在50秒内手动杀掉子进程,观察现象
}
return 0;
}再来个监控命令行脚本:
while :; do ps axj |head -1 && ps axj | grep myproc | grep -v grep; sleep 1; echo "###############"; done
我们运行起来就可以观察啦

孤儿进程
父进程提前退出(exit),子进程就被称为孤儿进程,孤儿进程会被1号进程init(操作系统)领养,当然要有init进程回收
我们再来小改一下代码:
#include<iostream>
#include<unistd.h>
#include<sys/types.h>
#include<stdlib.h>
using namespace std;
int main()
{
pid_t id = fork();
if (id == 0)
{
//child
while (1) {
cout << "I am child running!" << endl;
sleep(2);
}
}
else
{
//father
cout << "father do nothing" << endl;
sleep(10);
exit(1);//将父进程给退出
}
return 0;
}
结果展示:
进程优先级
基本概念
为什么会有优先级?
答案:资源太少!本质是分配资源的一种方式!
查看优先级的指令:ps -l
我们先写一段小小的进程代码:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
while(1)
{
printf("I am a process! pid:%d ppid:%d\n",getpid(),getppid());
sleep(1);
}
return 0;
}查看结果:
 我们很容易注意到几个重要的信息:
我们很容易注意到几个重要的信息:
①UID : 代表执行者的身份
②PID : 代表这个进程的代号
③PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
④PRI :代表这个进程可被执行的优先级,其值越小越早被执行
⑤NI :代表这个进程的nice值
PRI 和 NI
①PRI就是进程的优先级,通俗点就是被CPU执行的先后顺序,此值越小,进程的优先级又高
②NI就是nice值,叫做优先级的修正数据
③计算公式:PRI(new)=PRI(old)+nice
④调整进程优先级,在Linux下就是调整nice值
⑤nice值取值-20到19,共40个级别
PRI 对比 NI
①需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
②可以理解nice值是进程优先级的修正修正数据
调整优先级
第一种方法:系统提供的调整优先级的接口(一般用的非常少——百度)
第二种方法:renice命令调整(不推荐)
第三种:top命令调整(常用)
先按top,进入top后,按r,输入进程PID,再输入nice值
修改结果:

注意:
1、当你修改的nice值超过规定范围,系统默认为最大值或者最小值
2、有可能你修改的太过于频繁了之后,系统不要你修改了,我们需要提升临时权限,输入sudo top再次进行修改
3、我们多次修改nice值,但是每次PRI(old)都是从80开始的,无论你怎么改nice值为什么是一个相对比较小的范围呢?
答案:优先级设置只是一个相对的的优先级,没有绝对的优先级,否则会出现很严重的进程“饥饿问题”(就是某个进程长时间得不到资源),我们的调度器:是尽可能均衡的让每个进程都能享受到CPU资源的
其他概念
①竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
②独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
③并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行(某一时刻)
④并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发(某一时间段)
环境变量
环境变量的基本概念
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
说的简单点:
语言上面定义变量本质是在内存中开辟空间(有名字),不要去质疑OS开辟空间的能力!
环境变量本质是OS在内存/磁盘文件中开辟的空间,用来保存系统相关的数据! !

常见的环境变量
PATH : 指定命令的搜索路径
HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
SHELL : 当前Shell,它的值通常是/bin/bash。
问题引出:我们敲的命令,工具,程序等本质都是一个可执行程序。那么为什么我自己写的程序要加上点斜杠 .\ 才能运行起来,而系统默认的一些命令(ls,pwd,cd等),直接敲击便可以执行?

./点斜杠的实质是在帮系统确认文件在当前目录,或者说找到该文件的存放路径!
为什么系统的命令不用带路径呢?
因为有环境变量的存在!!!
查看环境变量的方法
echo $NAME//NAME:你的环境变量名例如:
[sjj@VM-20-15-centos 2022_3_30]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/sjj/.local/bin:/home/sjj/bin这就是为什么系统不带路径就能找到文件的原因了,因为有了环境变量,以冒号为分割,从前往后找,系统依次搜索文件所在路径,如果在当前找到了,就不用往后面的路径再寻找了。这样也可以说明,我们平时安装软件,也就是把对应的命令添加到系统环境的路径下面!
我们可不可以让自己写的程序也不带点斜杠运行呢?
方法一:把你写的程序路径,拷贝到环境变量中(但是我们强烈不推荐这样做,会污染系统的环境变量)
[sjj@VM-20-15-centos 2022_3_31]$ sudo cp myproc /usr/bin
方法二:使用export命令,将本地变量导成环境变量
格式:export PATH=$PATH:命令所在路径

测试结果:

注意: 当然这样修改只在本次登录有效,你退出登录,下次再次登录就没效了。如果想要永久使用,需要修改系统的配置文件!
我们还可以查看其它的环境变量:

这就是为什么我们每次登陆机器的时候,我们都是直接在用户家目录下,原因就是HOME环境变量的存在,我们每次登陆,系统都会默认打开这个路径。
我们可以查看更多的环境变量:使用 env 命令

总结:系统有这些环境变量,保证系统运行的相关状态信息,能更好的让我们运行、使用程序,每一种环境变量承担着不同的职责!
和环境变量相关的命令
1. echo: 显示某个环境变量值
2. export: 设置一个新的环境变量
3. env: 显示所有环境变量
4. unset: 清除环境变量
5. set: 显示本地定义的shell变量和环境变量
ps:系统上还存在一 种变量,是与本次登陆(session)有关的变量, 只在本次登陆有效 (本地变量)

通过代码获取环境变量
命令行参数问题
一般有这两种形式:
int main(int argc,char *argv[])
int main(int argc,char *argv[],char*envp[])其中的argc是argument count的缩写,表示命令行参数的个数,argv是argument vector的缩写,表示指针数组,是指向每个参数的指针所组成的数组
具体看代码:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main(int argc,char *argv[])
{
for(int i=0;i<argc;i++)
{
printf("argv[%d]:->%s\n",i,argv[i]);
}
}
我们运行程序,随便带上些选项,观察到:

那么我们的命令行参数有什么用呢?
答案:指令有很多选项,用来完成同一个命令的不同子功能,选项底层使用的就是我们的命令行参数! !
那么究竟怎么获取环境变量呢?
方法一:通过第三个参数获取环境变量
main函数中还可以传环境变量作为参数。
我们写一段小小的代码演示一下:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main(int argc,char *argv[],char *env[])
{
int i=0;
while(env[i])
{
printf("%s\n",env[i]);
i++;
}
}
运行起来:


每个程序都会受到一张环境表,环境表是一个字符指针数组,每个指针指向一个以“\0”结尾的环境字符串,而且这个env数组参数个数不受限制,由系统决定。
方法二:通过第三方系统变量environ获取
通过查看man手册我们可以知道environ变量是由系统外部声明的,它是一个二级指针。

main函数可以不带参数,而是调用environ也可以获取系统环境变量
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
//int main(int argc,char *argv[],char *env[])
//ps:main函数中不带参数,也是可以拿到环境变量的
int main()
{
extern char **environ;
int i=0;
for(;environ[i];i++)
{
printf("%s\n",environ[i]);
}
return 0;
}结果演示:

注意: libc中定义的全局变量environ指向环境变量表,environ没有包含在任何头文件中,所以在使用时要用extern进行声明。
实际上前面两种方法在实际中,并不常用!
通过系统调用获取环境变量
通过函数getenv获取环境变量(这个方法才是常用的!)
该函数返回值:非NULL表示成功,NULL表示失败
#include<stdio.h>
#include<stdlib.h>
int main()
{
printf("HOME:%s\n",getenv("HOME"));
printf("PATH:%s\n",getenv("PATH"));
printf("SHELL:%s\n",getenv("SHELL"));
return 0;
}结果展示:

环境变量具有全局属性
根本原因:环境变量可以被子进程继承下去(而bash的是从环境变量从系统中读取来的,而系统又是从配置文件中读取的)
我们在命令行上面启动的进程(子进程),父进程都是我们的bash!(命令行解释器) ,启动方式调用fork函数。export实际上是把本地变量导给了父进程bash!
证明:
我们先设置一个本地变量:my_env_string="AAAAA"
通过它来查看
#include<stdio.h>
#include<stdlib.h>
int main()
{
printf("my_env_string: %s\n",getenv("my_env_string"));
return 0;
}
我们通过在命令行上敲击指令(子进程),确实可以查看到我们人为导入后的环境变量,但是我们的export是导给bash进程的(父进程),原来运行程序失败,现在导入后(意思就是现在父进程多了一个环境变量),再次敲击命令(子进程),结果成功,这就说明了我们的子进程继承到了我们父进程bash的环境变量 ,这就是环境变量具有全局属性!
总结:环境变量可以被继承,就是说可以影响整个“用户”系统!

所以我们在用一些gdb、gcc命令时,不用带那么多选项就能执行,本质就是从bash那里继承了环境变量。
谢谢观看!