引言
本篇博客本来是没有发的必要,由于这个东西用的人应该不多,大多数还是nvidia,事实上生态圈确实如此,国内几个厂商大多都是去适配nvidia原来的生态,比如说tensorflow、pytorch等等。不过atlas好像没有这样做,就目前来讲,感觉还是有非常大的优化空间,单说体验,这东西的适配时间抵得上我适配其它的几倍有余,就也不是难,官网资料有些乱,能帮助的也很少,基本上像在做一个全新的未知领域,只有不断把时间浪费进去才有戏,过程中遇到过非常多问题,我前面有几篇博客是把比较通用的问题抽出来单独写了几篇,这里也仅仅针对一个docker问题提出疑问,有待解决,另外也分享一些运维过程的笔记。
docker安装
首先安装所需依赖:
apt install -y gcc g++ make cmake zlib1g zlib1g-dev libsqlite3-dev openssl libssl-dev libffi-dev unzip pciutils net-tools
apt install dkms
然后在官网找到对应驱动,进行安装:
# 赋权限
chmod +x ./A300-3010-npu-driver_20.2.0_ubuntu18.04-x86_64.run
# 执行安装
./A300-3010-npu-driver_20.2.0_ubuntu18.04-x86_64.run --full
然后安装docker,如果是系统自带有一定要查看docker版本是否为2019年之前的版本,如果是,应该卸载重装,我也是找很久卸载完发现能跑了才发现,然后还是官网找软件包,安装AscendDocker:
sudo dpkg -i ascend-docker-runtime_{
version}_{
arch}.deb
确保没问题,就可以继续在官网找支持加速推理的镜像,但官网对于镜像的介绍,看看就好,emmm,因为我感觉那镜像应该dockerfile做的,而且语句很简单没有实验过,C++不知道,至少python的话我整个环境能卸载的都重新装,别问我是怎么知道的,都是bug多了就从零开始了。最好是在镜像里再装一套驱动,因为如果要跑aclnet或者sdk关联东西非常多,与其让它find宿主机,不如路径直接写死镜像里,当然,这只是我的步骤和建议。
上述没问题,拉下来的镜像普通启动更新完所有自己需要的环境以及依赖后,就可以加入宿主机路径启动,docker的启动方式为:
docker run -d --restart=always -v /home/program/folder:/home/program/folder --name nvidia -dit --ipc=host --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /usr/local/Ascend/driver:/usr/local/Ascend/driver submarineas/atlas:v2.0 /bin/bash
davinci0 到 devinci7对应于有多少个映射npu,在宿主机装好驱动后,可以npu-smi info查看,或者ls /dev/ | grep davinci*,然后加了一个我的映射目录,devmm_svm与manager还有hdc应该是管理的,也需要一并映射进去。
在容器里后可以通过ls /dev/ | grep davinci*查看加载情况,然后info那个好像不能用了,我也不知道为啥,然后创建相关用户:
# 查看使用的 davinci 设备
ls /dev/ | grep davinci*
# 创建 HwHiAiUser 用户
groupadd -g gid HwHiAiUser && useradd -g HwHiAiUser -d /home/HwHiAiUser -m HwHiAiUser && echo ok
至此,device环境基本部署完成,至于容器内能不能跑起项目,这已经与宿主机一样,前面没先用脚本实验过的,该咋样就咋样,另外还有个sdk的安装,就只需要再镜像里安装就行:
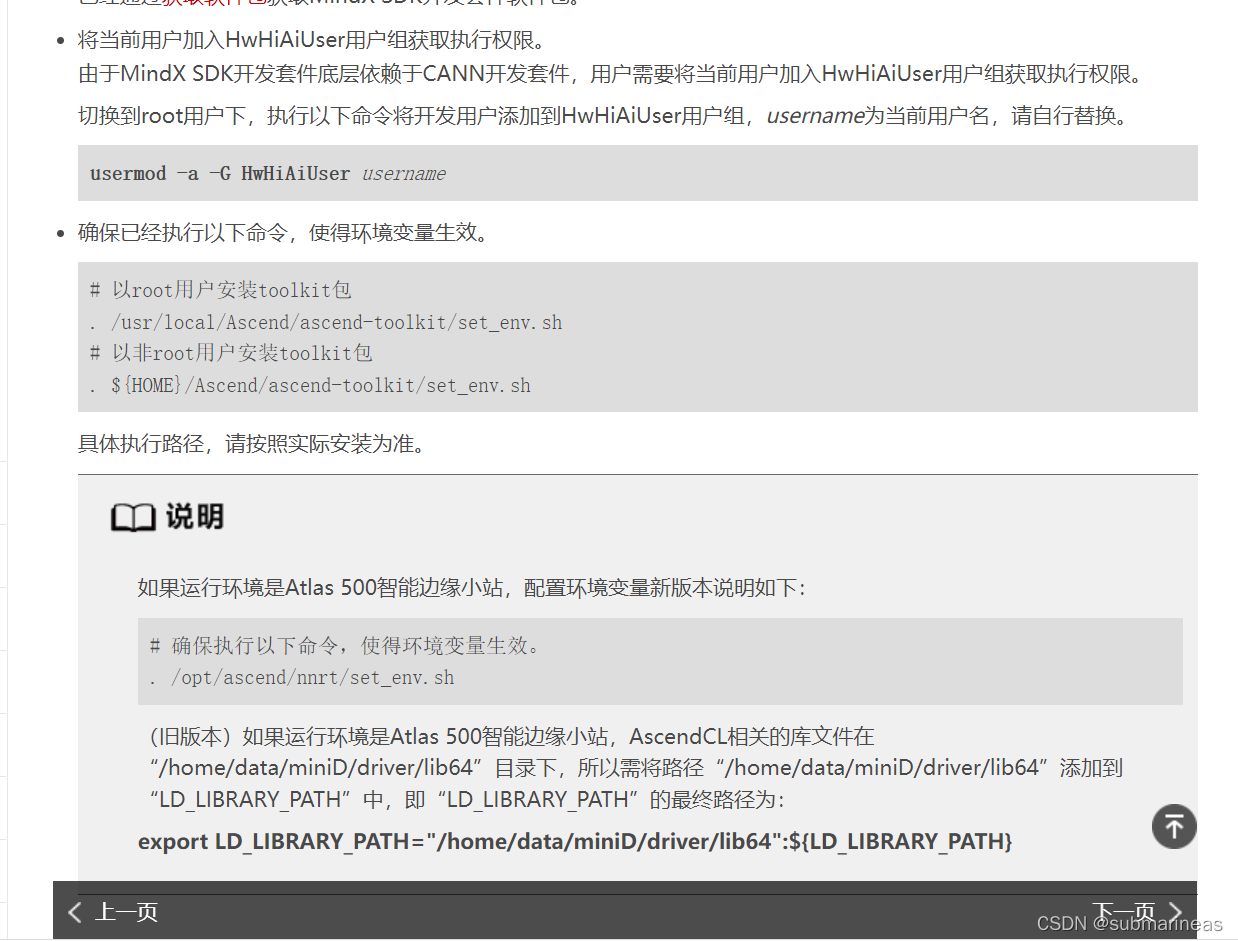
docker-compose问题
这里的docker compose问题在于我无法控制镜像里的sdk进行正确的初始化,test.yml为:
version: '3.3'
services:
nvidia:
#container_name: nvidia_test
image: submarineas/atlas:v2.0
network_mode: host
privileged: true
volumes:
- /home/program/folder:/home/program/folder
- /home/program/xxxx_new:/home/program/xxxx_new
- /usr/share/zoneinfo:/usr/share/zoneinfo
devices:
- "/dev/davinci_manager:/dev/davinci_manager"
- "/dev/devmm_svm:/dev/devmm_svm"
- "/dev/hisi_hdc:/dev/hisi_hdc"
- "/dev/davinci0:/dev/davinci0"
- "/dev/davinci1:/dev/davinci1"
- "/dev/davinci2:/dev/davinci2"
- "/dev/davinci3:/dev/davinci3"
- "/dev/davinci4:/dev/davinci4"
- "/dev/davinci5:/dev/davinci5"
- "/dev/davinci6:/dev/davinci6"
- "/dev/davinci7:/dev/davinci7"
- "/dev/davinci8:/dev/davinci8"
environment:
TZ: "Asia/Shanghai"
LD_LIBRARY_PATH: /usr/local/Ascend/ascend-toolkit/5.0.3.1/arm64-linux/aarch64-linux/devlib/:/usr/local/Ascend/driver/lib64/:/usr/local/Ascend/ascend-toolkit/5.0.3.1/arm64-linux/runtime/lib64/stub/:/usr/local/ffmpeg/lib
restart: always
entrypoint:
- /home/program/xxxx_new/start.sh
logging:
driver: "json-file"
options:
max-size: "1g"
这里基本跟上面docker的启动方式一致,不一样的地方在于我加了个entrypoint的start.sh,也就是启动脚本,以及sdk对应的动态库路径,因为不知道它调用原理是啥,所以能找到的全加进去了。结果前面都没问题,就是宿主机去启动镜像服务报初始化的错误,具体如下:
nvidia | E0307 17:55:19.859671 756 DeviceManager.cpp:54] Failed to initialize all devices: The denominator must not be equal to 0.
nvidia | E0307 17:55:19.860208 756 MxStreamManager.cpp:128] Initialize devices failed.
这个问题,我之前用IDE远程连接修改启动的时候就有出现,当时也搞了一下午没搞出来,当时想着是不是自己IDE配的有问题,结果compose又搞了一天,加上各种环境问题,前前后后搞了一个多月,如果不是花了那么多时间,我也懒得看了。所以之后,如果有大佬出现同样问题,用其余方式能解决的话,可以麻烦私信我或者评论,我也将很乐意讨论和请教。