1 初始准备
清理环境做准备
clean up
rm(list=ls())
# load package arules to find rules
library(arules)
2 读取文件
读取文件,查看文件内容,发现需求给予的3 张表分别为,交易信息表,商品列表,商品订单表,
按照PA字段将交易信息表和商品订单表连接到一起
read purchase data on items level
trans <- read.csv('purchase.csv',header = TRUE,stringsAsFactors = FALSE )
RA_desc <- read.csv('RA_desc.csv',header = TRUE,stringsAsFactors = FALSE )
PA_desc <- read.csv('PA_desc.csv',header = TRUE,stringsAsFactors = FALSE )
dim(trans)
head(trans)
head(PA_desc)
names(trans) <- c("card","transaction_place","transaction_time","pos_id","transaction_number","invo_num","amt_aft","amt_bft","quantity","PA","RA","product_code")
# merge with descriptions
trans2 <- merge(trans,PA_desc, by="PA", all.x=TRUE)


#write trans_is and items
trans2$trans_id = paste(trans2$card, trans2$transaction_place, trans2$transaction_time,
trans2$pos_id, trans2$transaction_number, sep='_')
View(head(trans2))
write.csv(subset(trans2,select=c("trans_id","PA_desc")), file = 'purchase2.csv', row.names = F)
trans3 = read.transactions('purchase2.csv', format = "single", sep = ",",
cols = c("trans_id", "PA_desc"), rm.duplicates=TRUE,header = TRUE)
最后将信息整理为订单编号和购物商品明细

trans3 = read.transactions(‘purchase2.csv’, format = “single”, sep = “,”,
cols = c(“trans_id”, “PA_desc”), rm.duplicates=TRUE,header = TRUE)
这步是将数据转化为交易订单格式,方便算法处理
3 Apriori算法生成规则
find rules with low confidence level
rules.all = apriori(trans3,
parameter = list(minlen=2,
supp=0.008,
conf=0.5,
target = "rules"))
inspect(rules.all)
# find rules with reasonable confidence level
rules = apriori(trans3,
parameter = list(minlen=2,
supp=0.005,
conf=0.05,
target = "rules"))
inspect(rules)
write(rules,"rules.csv",row.names=FALSE,sep="|")
前面一次关联算法规则处理过可能存在冗余规则于是对规则进行剪枝
adjust the format of results
quality(rules.all) <- round(quality(rules.all), digits=3)
rules.sorted <- sort(rules.all, by ='lift')
inspect(rules.sorted)
reules.pruned = rules.sorted
inspect(reules.pruned[1])
target:
a character string indicating the type of association mined. One of
“frequent itemsets”
“maximally frequent itemsets”
“closed frequent itemsets”
“rules” (only available for Apriori; use ruleInduction for eclat.)
“hyper edge sets” (only available for Apriori; see references for the definition of association hyperedgesets)
4 关联规则绘图
scatter plots
# plot rules.all
png(file="rules_all.png", bg="white", width=1200, height=900)
plot(rules.all)
dev.off()
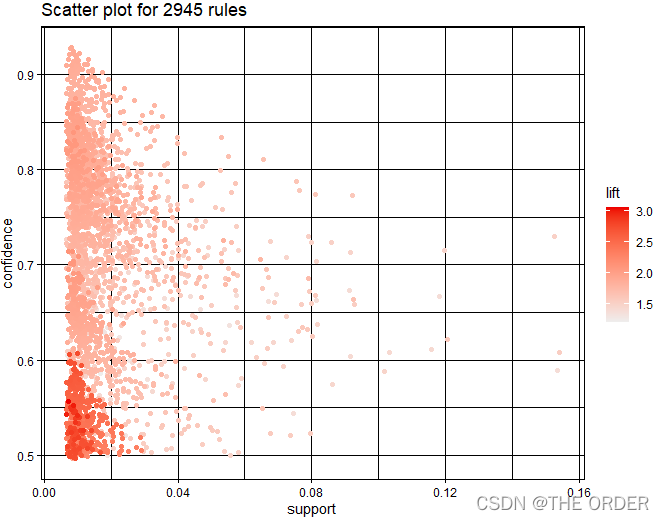
多种规则画图
plot(reules.pruned)
plot(reules.pruned, measure=c("support", "lift"), shading="confidence")
plot(reules.pruned, shading="order", control=list(main = "Two-key plot"))
inspect(reules.pruned)
其它绘图
# sel <- plot(rules, measure=c("support", "lift"), shading="confidence", interactive=TRUE)
### matrix plots
plot(reules.pruned, method="matrix", measure="lift")
plot(reules.pruned, method="matrix", measure="lift", control=list(reorder=TRUE))
plot(reules.pruned, method="matrix", measure=c("lift", "confidence"))
plot(reules.pruned, method="matrix", measure=c("lift", "confidence"),control=list(reorder=TRUE))
### grouped matrix plots
# sel <- plot(reules.pruned, method="white", interactive=TRUE)
png(file="grouped_matrix.png", bg="transparent", width=1200, height=900)
plot(reules.pruned, method='grouped')
dev.off()
plot(reules.pruned, method='grouped',control=list(k=25))
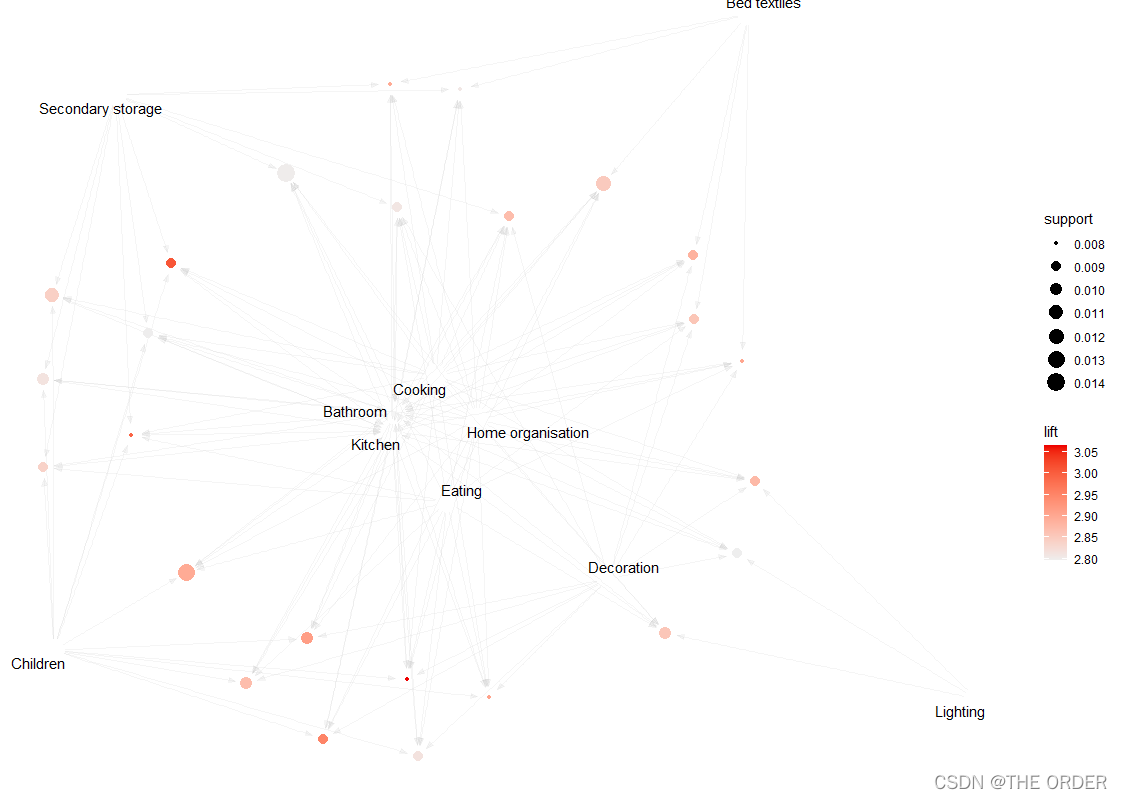
### graph plots
subrules2 <- head(sort(reules.pruned, by="lift"), 25)
inspect(subrules2)
plot(subrules2, method="graph")
plot(subrules2, method="graph", control=list(type="items"))
plot(subrules2, method='graph', control = list(type="itemsets"))
parallel coordinates
plot(subrules2, method=‘paracoord’, control = list(reorder=T))
subrules3 <- head(sort(reules.pruned, by=“lift”), 3)
plot(subrules3, method=‘paracoord’, control = list(reorder=T))
inspect(subrules3)