Kubernetes存储和选型
基础知识
- 容器的 Volume,其实就是将一个宿主机上的目录,跟一个容器里的目录绑定挂载在了一起。
- 所谓的“持久化 Volume”,指的就是这个宿主机上的目录,具备“持久性”。即:这个目录里面的内容,既不会因为容器的删除而被清理掉,也不会跟当前的宿主机绑定。这样,当容器被重启或者在其他节点上重建出来之后,它仍然能够通过挂载这个 Volume,访问到这些内容。
- 使用的 hostPath 和 emptyDir 类型的 Volume 并不具备这个特征:它们既有可能被 kubelet 清理掉,也不能被“迁移”到其他节点上
- 大多数情况下,持久化 Volume 的实现,往往依赖于一个远程存储服务,比如:远程文件存储(比如,NFS、GlusterFS)、**远程块存储(比如,公有云提供的远程磁盘)**等等。
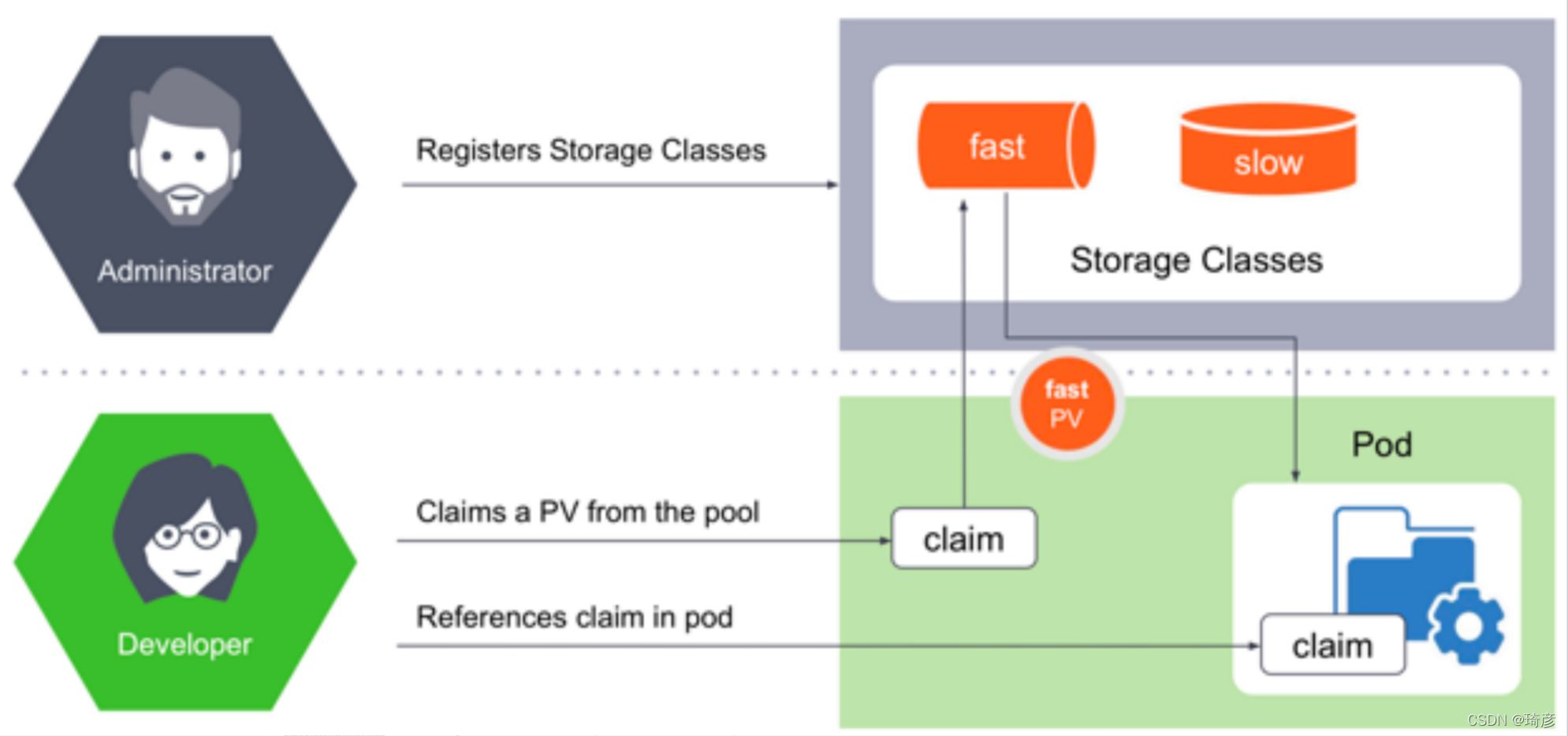
PVC , PV和 StorageClass的关系
- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
简而言之:
StorageClass (SC):存储类,类似存储池的概念,包括了存储池的一些信息;
PersistenVolume (PV):持久卷,独立的存储资源对象,其生命周期与Pod无关;
PersistenVolumeClaim (PVC): 声明,代表计算任务对存储资源的需求。
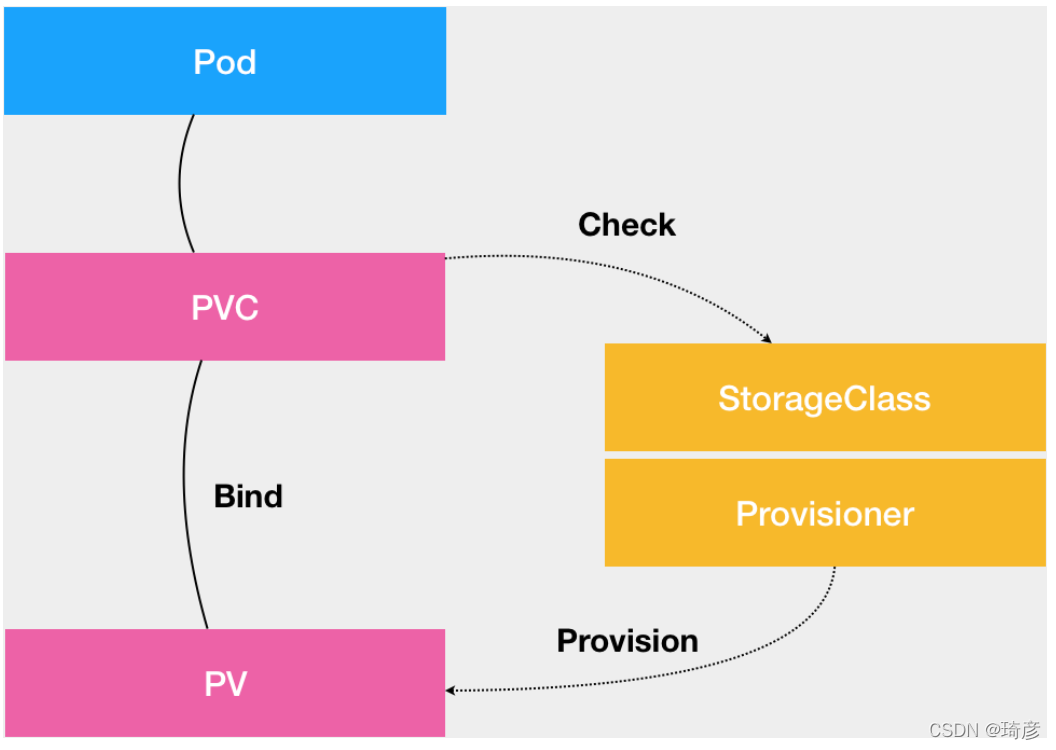
当然,StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果你的存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动为你创建 PV 了。
新创建的PV,还只是一个API 对象,需要经过**“两阶段处理”**,变成宿主机上的“持久化 Volume”才真正有用:
- 第一阶段:由运行在master上的AttachDetachController负责,为这个PV完成 Attach 操作,为宿主机挂载远程磁盘;
- 第二阶段:是运行在每个节点上kubelet组件的内部,把第一步attach的远程磁盘 mount 到宿主机目录。这个控制循环叫VolumeManagerReconciler,运行在独立的Goroutine,不会阻塞kubelet主循环。Mount 阶段完成后,这个 Volume 的宿主机目录就是一个“持久化”的目录了,容器在它里面写入的内容,会保存在远程磁盘(例如Google Cloud )中。
完成这两步,PV对应的“持久化 Volume”就准备好了,POD可以正常启动,将“持久化 Volume”挂载在容器内指定的路径。
你的 Volume 类型是远程文件存储(比如 NFS)的话,kubelet 的处理过程就会更简单一些。
因为在这种情况下,kubelet 可以跳过“第一阶段”(Attach)的操作,这是因为一般来说,远程文件存储并没有一个“存储设备”需要挂载在宿主机上。
解决了什么问题
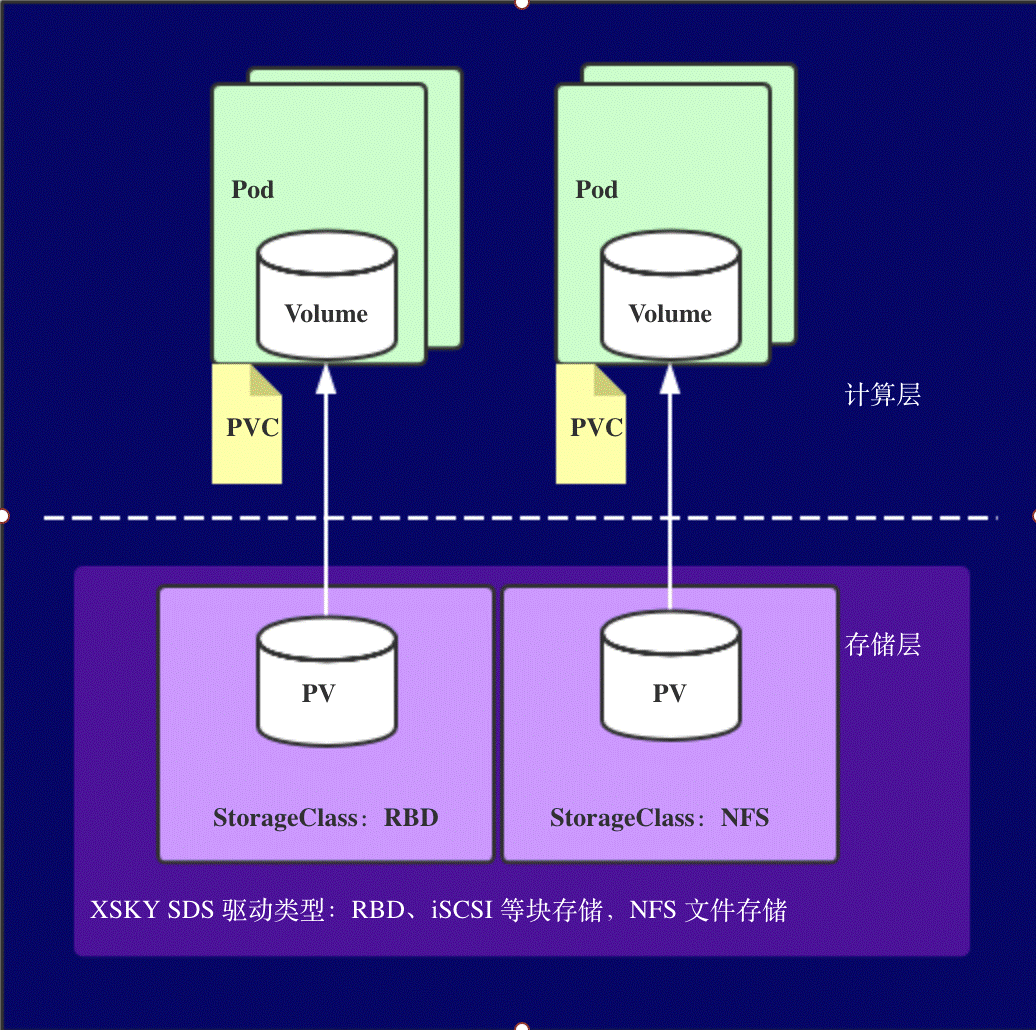
这种存储结构是为了解决
- 有状态的容器实例需要持久化卷;
- 容器实例动态提供新卷;
- 不同类型的应用需要不同访问模式的存储卷;
- 解耦计算资源和存储资源。
Kubernetes 存储体系架构
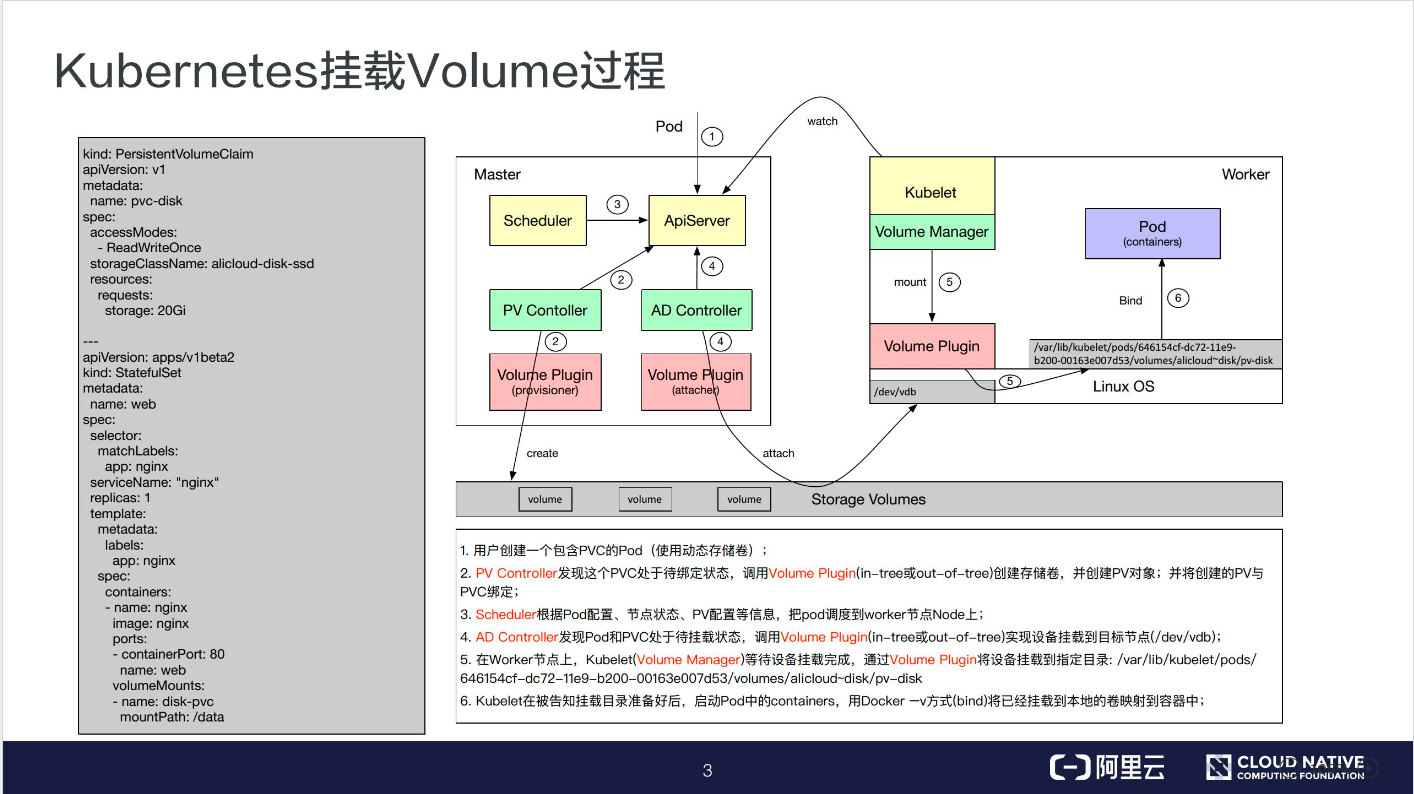
在 Kubernetes 中挂载一个 Volume
首先以一个 Volume 的挂载例子来作为引入。
如下图所示,左边的 YAML 模板定义了一个 StatefulSet 的一个应用,其中定义了一个名为 disk-pvc 的 volume,挂载到 Pod 内部的目录是 /data。
disk-pvc 是一个 PVC 类型的数据卷,其中定义了一个 storageClassName。
因此这个模板是一个典型的动态存储的模板。右图是数据卷挂载的过程,主要分为 6 步:
-
第一步:用户创建一个包含 PVC的 Pod;
-
第二步:PV Controller 会不断观察 ApiServer,如果它发现一个 PVC 已经创建完毕但仍然是未绑定的状态,它就会试图把一个 PV 和 PVC 绑定;
PV Controller 首先会在集群内部找到一个适合的 PV 进行绑定,如果未找到相应的 PV,就调用 Volume Plugin 去做 Provision。Provision 就是从远端上一个具体的存储介质创建一个 Volume,并且在集群中创建一个 PV 对象,然后将此 PV 和 PVC 进行绑定;
-
第三步:通过 Scheduler 完成一个调度功能。
我们知道,当一个 Pod 运行的时候,需要选择一个 Node,这个节点的选择就是由 Scheduler 来完成的。Scheduler 进行调度的时候会有多个参考量,比如 Pod 内部所定义的 nodeSelector、nodeAffinity 这些定义以及 Volume 中所定义的一些标签等。
我们可以在数据卷中添加一些标准,这样使用这个 pv 的 Pod 就会由于标签的限制,被调度器调度到期望的节点上。
-
第四步:如果有一个 Pod 调度到某个节点之后,它所定义的 PV 还没有被挂载(Attach),此时 AD Controller 就会调用 VolumePlugin,把远端的 Volume 挂载到目标节点中的设备上(如:/dev/vdb);
-
**第五步:**当 Volum Manager 发现一个 Pod 调度到自己的节点上并且 Volume 已经完成了挂载,它就会执行 mount 操作,将本地设备(也就是刚才得到的 /dev/vdb)挂载到 Pod 在节点上的一个子目录中。同时它也可能会做一些像格式化、是否挂载到 GlobalPath 等这样的附加操作。
-
第六步就:绑定操作,就是将已经挂载到本地的 Volume 映射到容器中。
简化来说
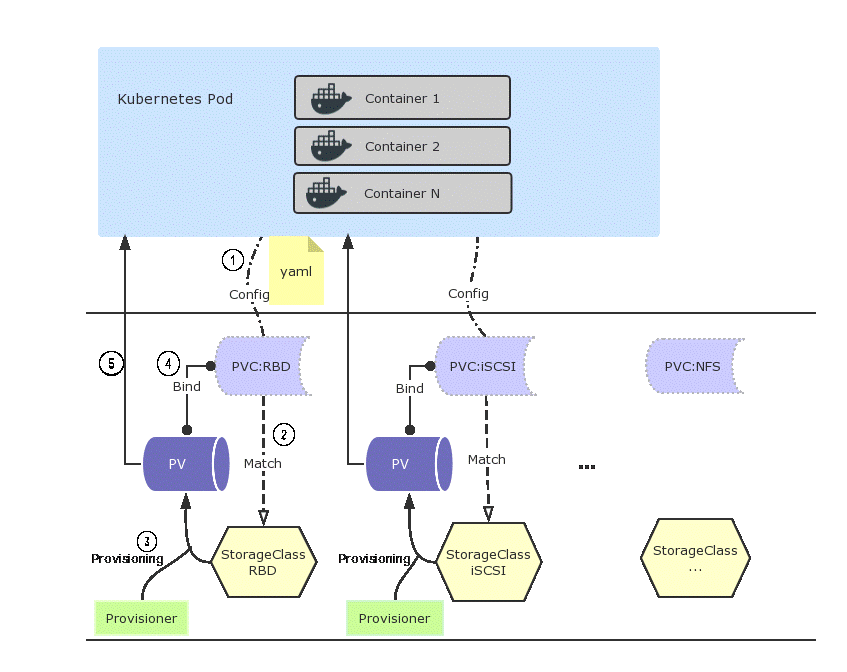
详细流程分析如下:
(1)Pod加载存储卷,请求PVC
(2)PVC根据存储类型(此处为rbd)找到存储类StorageClass
(3)Provisioner根据StorageClass动态生成一个持久卷PV
(4)持久卷PV和PVC最终形成绑定关系
(5)持久卷PV开始提供给Pod使用
简单总结下,如果在Kubernetes中运行有状态服务,比如数据库MySQL,MongoDB或者中间件Redis,RabbitMQ等,那么就需要用持久卷(PV),从而不用担心随着Pod的终止而丢失数据(相对于使用了普通Volume)。
Kubernetes 的存储架构
接下来,我们一起看一下 Kubernetes 的存储架构。
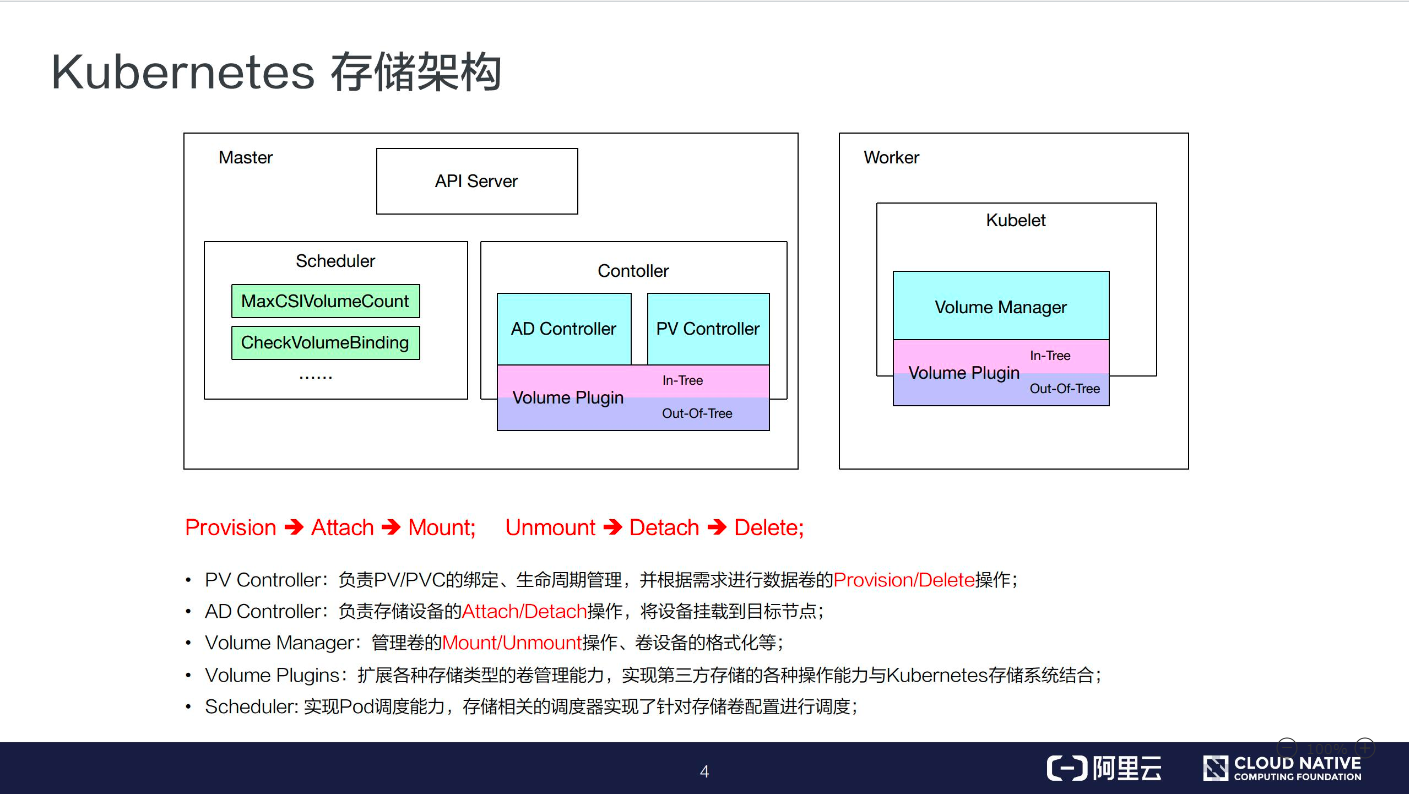
-
PV Controller: 负责 PV/PVC 的绑定、生命周期管理,并根据需求进行数据卷的 Provision/Delete 操作;
-
AD Controller: 负责存储设备的 Attach/Detach 操作,将设备挂载到目标节点;
-
Volume Manager: 管理卷的 Mount/Unmount 操作、卷设备的格式化以及挂载到一些公用目录上的操作;
-
Volume Plugins:它主要是对上面所有挂载功能的实现。
PV Controller、AD Controller、Volume Manager 主要是进行操作的调用,而具体操作则是由 Volume Plugins 实现的。
-
Scheduler: 实现对 Pod 的调度能力,会根据一些存储相关的的定义去做一些存储相关的调度。
存储插件
可以分为很多种。In-Tree 中就包含了 几十种常见的存储实现,但一些公司的自己定义私有类型,有自己的 API 和参数,公共存储插件是无法支持的,这时就需要 Out-of-Tree 类的存储实现,比如 CSI、FlexVolume。
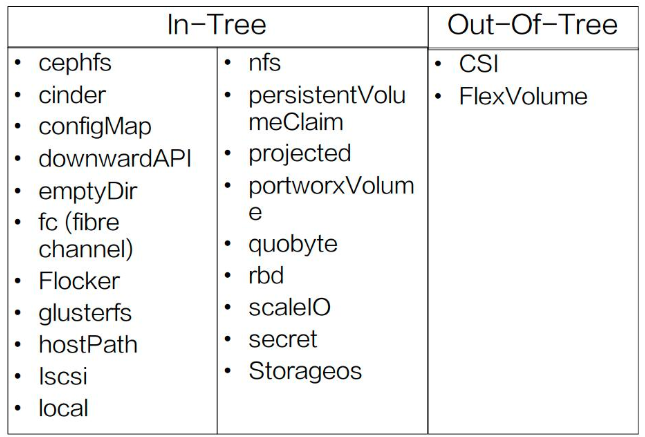
默认支持 Dynamic Provisioning 的内置存储插件。
而对于不在文档里的插件,或者其他非内置存储插件,你其实可以通过kubernetes-incubator/external-storage这个库来自己编写一个外部插件完成这个工作。
CSI 插件体系的设计思想
CSI 的设计思想,把插件的职责从“两阶段处理”,扩展成了 Provision、Attach 和 Mount 三个阶段。
其中,
- Provision 等价于“创建磁盘”,
- Attach 等价于“挂载磁盘到虚拟机”,
- Mount 等价于“将该磁盘格式化后,挂载在 Volume 的宿主机目录上”。
一直以来,存储插件的测试、维护等事宜都由Kubernetes社区来完成,即使有贡献者提供协作也不容易合并到主分支发布。另外,存储插件需要随Kubernetes一同发布,如果存储插件存在问题有可能会影响Kubernetes其他组件的正常运行。
鉴于此,Kubernetes和CNCF决定把容器存储进行抽象,通过标准接口的形式把存储部分移到容器编排系统外部去。CSI的设计目的是定义一个行业标准,该标准将使存储供应商能够自己实现,维护和部署他们的存储插件。这些存储插件会以Sidecar Container形式运行在Kubernetes上并为容器平台提供稳定的存储服务。
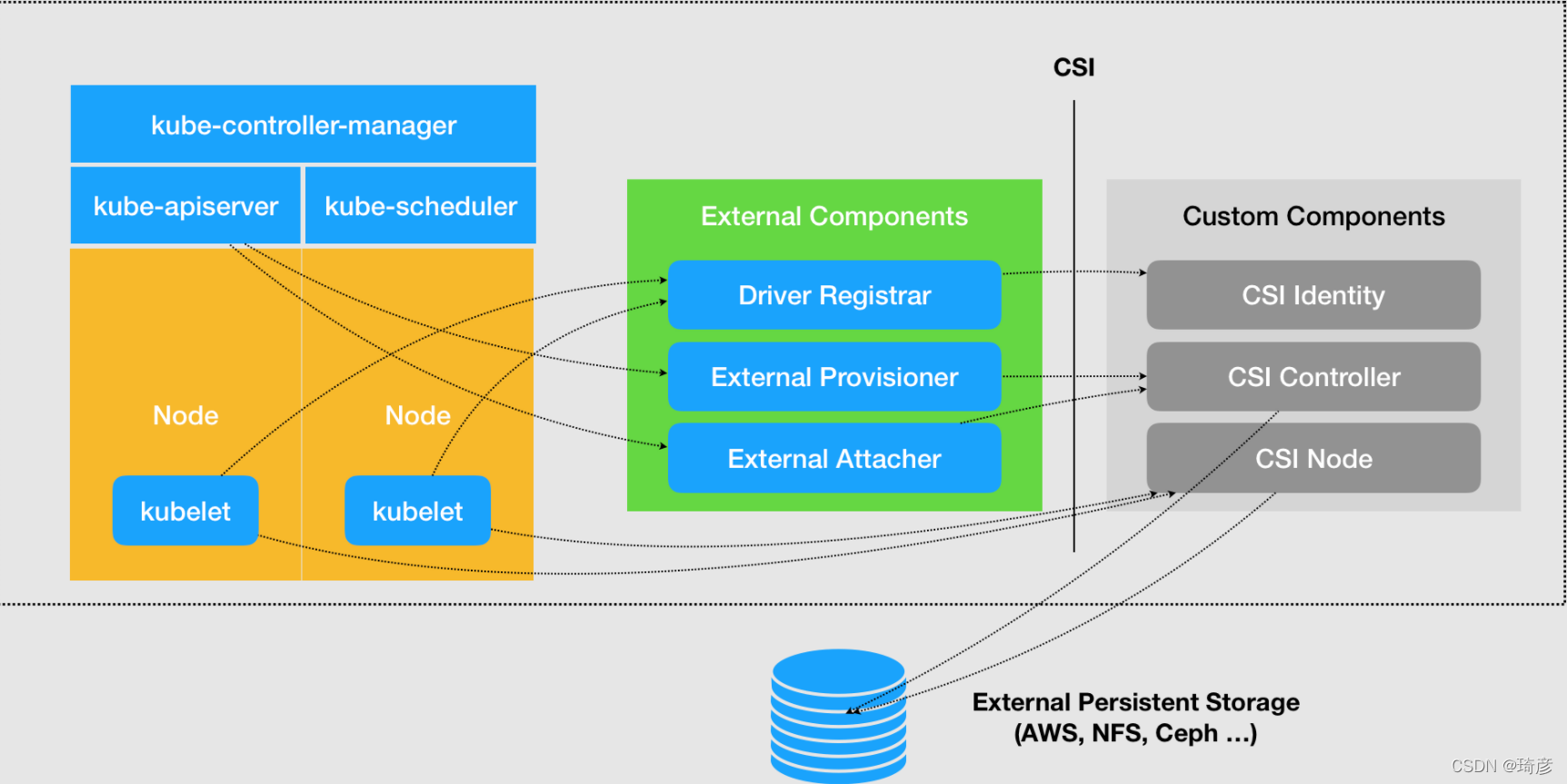
如上CSI设计图:绿色表示从Kubernetes社区中抽离出来且可复用的组件,负责连接CSI插件(右侧灰色)以及和Kubernetes集群交互:
-
Driver-registrar: 负责将插件注册到 kubelet 里面(这可以类比为,将可执行文件放在插件目录下)。而在具体实现上,Driver Registrar 需要请求 CSI 插件的 Identity 服务来获取插件信息。; -
External-provisioner: 负责的正是 Provision 阶段。在具体实现上,External Provisioner 监听(Watch)了 APIServer 里的 PVC 对象。当一个 PVC 被创建时,它就会调用 CSI Controller 的 CreateVolume 方法,为你创建对应 PV。此外,如果你使用的存储是公有云提供的磁盘(或者块设备)的话,这一步就需要调用公有云(或者块设备服务)的 API 来创建这个 PV 所描述的磁盘(或者块设备)了。
不过,由于 CSI 插件是独立于 Kubernetes 之外的,所以在 CSI 的 API 里不会直接使用 Kubernetes 定义的 PV 类型,而是会自己定义一个单独的 Volume 类型。
-
External-attacher: 负责的正是“Attach 阶段”。在具体实现上,它监听了 APIServer 里 VolumeAttachment 对象的变化。VolumeAttachment 对象是 Kubernetes 确认一个 Volume 可以进入“Attach 阶段”的重要标志。一旦出现了 VolumeAttachment 对象,External Attacher 就会调用 CSI Controller 服务的 ControllerPublish 方法,完成它所对应的 Volume 的 Attach 阶段。
而 Volume 的“Mount 阶段”,并不属于 External Components 的职责。当 kubelet 的 VolumeManagerReconciler 控制循环检查到它需要执行 Mount 操作的时候,会通过 pkg/volume/csi 包,直接调用 CSI Node 服务完成 Volume 的“Mount 阶段”。
需要注意的是,External Components 虽然是外部组件,但依然由 Kubernetes 社区来开发和维护。
在实际使用 CSI 插件的时候,我们会将这三个 External Components 作为 sidecar 容器和 CSI 插件放置在同一个 Pod 中。
由于 External Components 对 CSI 插件的调用非常频繁,所以这种 sidecar 的部署方式非常高效。
右侧灰色表示需要用户编码实现的存储插件驱动,分别有三个服务(以 gRPC 的方式对外提供):
-
CSI identify: 负责对外暴露这个插件本身的信息,标志插件服务,并维持插件健康状态; -
CSI Controller: 定义的则是对 CSI Volume(对应 Kubernetes 里的 PV)的管理接口,比如:创建和删除 CSI Volume、对 CSI Volume 进行 Attach/Dettach(在 CSI 里,这个操作被叫作 Publish/Unpublish),以及对 CSI Volume 进行 Snapshot 等;需要注意的是,正如我在前面提到的那样,CSI Controller 服务的实际调用者,并不是 Kubernetes(即:通过 pkg/volume/csi 发起 CSI 请求),而是 External Provisioner 和 External Attacher。
这两个 External Components,分别通过监听 PVC 和 VolumeAttachement 对象,来跟 Kubernetes 进行协作。
-
CSI Node: 负责CSI Volume 需要在宿主机上执行的操作mount、umount。需要注意的是,“Mount 阶段”在 CSI Node 里的接口,是由 NodeStageVolume 和 NodePublishVolume 两个接口共同实现的。
如何选择Kubernetes持久化存储方案
从产品定义角度,存储分为**本地存储(DAS),网络存储(NAS),存储局域网(SAN)和软件定义存储(SDS)**四大类。
- DAS就是本地盘,直接插到服务器上
- NAS是指提供NFS协议的NAS设备,通常采用磁盘阵列+协议网关的方式
- SAN跟NAS类似,提供SCSI/iSCSI协议,后端是磁盘阵列
- SDS是一种泛指,包括分布式NAS(并行文件系统),ServerSAN等
从应用场景角度,存储分为**文件存储(Posix/MPI),块存储(iSCSI/Qemu)和对象存储(S3/Swift)**三大类。
Kubernetes是如何给存储定义和分类呢?Kubernetes中跟存储相关的概念有PersistentVolume (PV)和PersistentVolumeClaim(PVC),PV又分为静态PV和动态PV。静态PV方式如下:
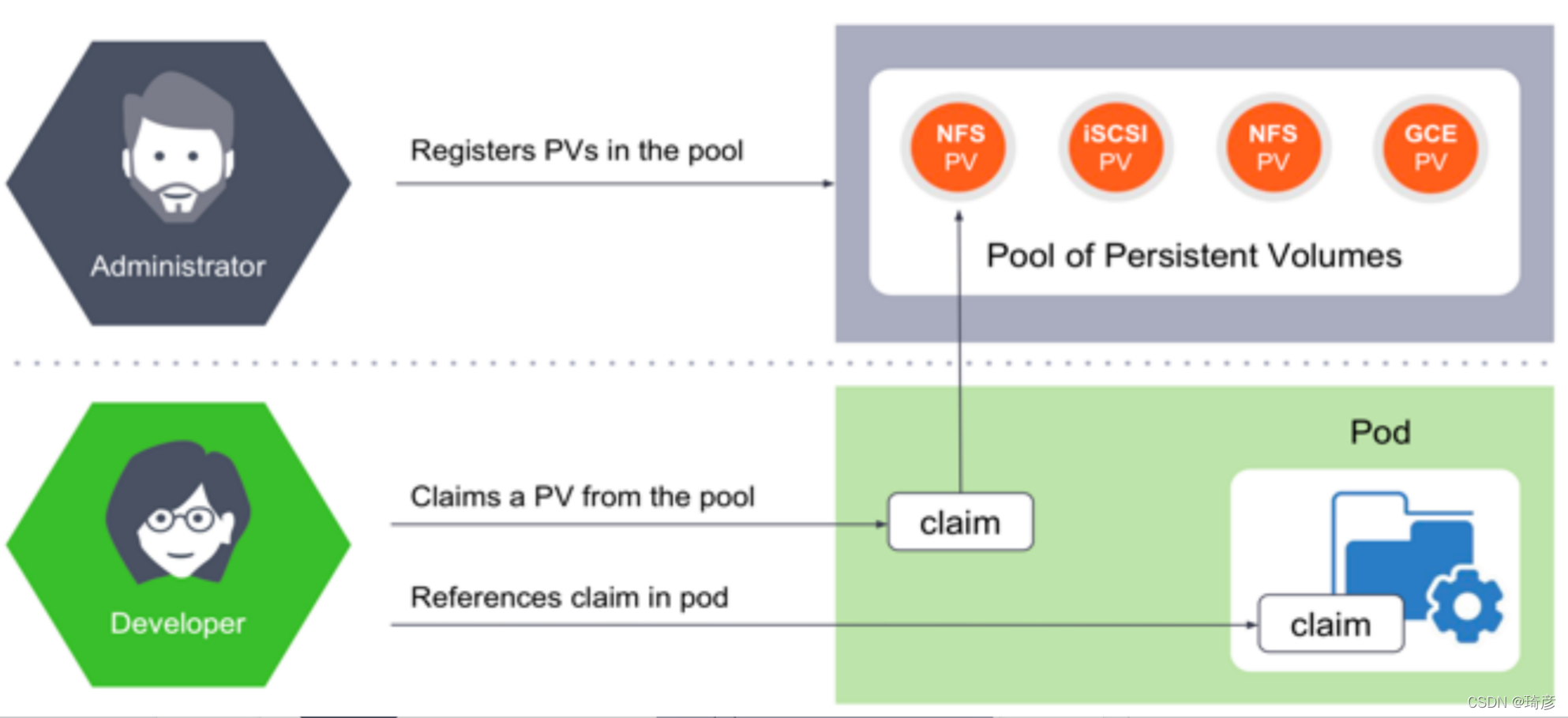
动态PV需要引入StorageClass的概念,使用方式如下:
社区列举出PersistentVolume的in-tree Plugin,如下图所示。从图中可以看到,Kubernetes通过访问模式给存储分为三大类,RWO/ROX/RWX。这种分类将原有的存储概念混淆,其中包含存储协议,存储开源产品,存储商业产品,公有云存储产品等等。

如何将Kubernetes中的分类和熟知的存储概念对应起来呢?本文选择将其和应用场景进行类比。
- 块存储通常只支持RWO,比如AWSElasticBlockStore,AzureDisk,有些产品能做到支持ROX,比如GCEPersistentDisk,RBD,ScaleIO等
- **文件存储(分布式文件系统)**支持RWO/ROX/RWX三种模式,比如CephFS,GlusterFS和AzureFile
- 对象存储不需要PV/PVC来做资源抽象,应用可以直接访问和使用
CSI将会是Kubernetes的主流,做了完整的存储抽象层。
形形色色的存储产品
市面上的存储产品种类繁多,但是对于容器场景,主要集中在4种方案:分布式文件存储,分布式块存储,Local-Disk和传统NAS。
分布式块存储包括开源社区的Ceph,Sheepdog,商业产品中EMC的Scale IO,Vmware的vSAN等。分布式块存储不适合容器场景,关键问题是缺失RWX的特性。
分布式文件存储包括开源社区的Glusterfs,Cephfs,Lustre,Moosefs,Lizardfs,商业产品中EMC的isilon,IBM的GPFS等。分布式文件存储适合容器场景,但是性能问题比较突出,主要集中在GlusterFS,CephFS,MooseFS/LizardFS。
分门别类的评估策略
存储的核心需求是稳定,可靠,可用。无论是开源的存储项目还是商业的存储产品,评估方法具有普适性,本文会介绍常见的评估项和评估方法。
数据可靠性
数据可靠性是指数据不丢失的概率。通常情况下,存储产品会给出几个9的数据可靠性,或者给出最多允许故障盘/节点个数。评估方式就是暴力拔盘,比如说存储提供3副本策略,拔任意2块盘,只要数据不损坏,说明可靠性没问题。存储采用不同的数据冗余策略,提供的可靠性是不一样的。
数据可用性
数据可用性和数据可靠性很容易被混淆,可用性指的是数据是否在线。比如存储集群断电,这段时间数据是不在线,但是数据没有丢失,集群恢复正常后,数据可以正常访问。评估可用性的主要方式是拔服务器电源,再有查看存储的部署组件是否有单点故障的可能。
数据一致性
数据一致性是最难评估的一项,因为大部分场景用户不知道程序写了哪些数据,写到了哪里。该如何评估数据一致性呢?普通的测试工具可以采用fio开启crc校验选项,最好的测试工具就是数据库。如果发生了数据不一致的情况,数据库要么起不来,要么表数据不对。具体的测试用例还要细细斟酌。
存储性能
存储的性能测试很有讲究,块存储和文件存储的侧重点也不一样。
- 块存储
fio/iozone是两个典型的测试工具,重点测试IOPS,延迟和带宽。以fio为例,测试命令如下:
fio -filename=/dev/sdc -iodepth=${
iodepth} -direct=1 -bs=${
bs} -size=100% --rw=${
iotype} -thread -time_based -runtime=600 -ioengine=${
ioengine} -group_reporting -name=fioTest
关注几个主要参数:iodepth,bs,rw和ioengine。
测试IOPS,iodepth=32/64/128,bs=4k/8k,rw=randread/randwrite,ioengine=libaio
测试延迟,iodepth=1,bs=4k/8k,rw=randread/randwrite,ioengine=sync
测试带宽,iodepth=32/64/128,bs=512k/1m,rw=read/write,ioengine=libaio
- 文件存储
fio/vdbench/mdtest是测试文件系统常用的工具,fio/vdbench用来评估IOPS,延迟和带宽,mdtest评估文件系统元数据性能。以fio和mdtest为例,测试命令如下:
fio -filename=/mnt/yrfs/fio.test -iodepth=1 -direct=1 -bs=${
bs} -size=500G --rw=${
iotype} -numjobs=${
numjobs} -time_based -runtime=600 -ioengine=sync -group_reporting -name=fioTest
与块存储的测试参数有一个很大区别,就是ioengine都是用的sync,用numjobs替换iodepth。
测试IOPS,bs=4k/8k,rw=randread/randwrite,numjobs=32/64
测试延迟,bs=4k/8k,rw=randread/randwrite,numjobs=1
测试带宽,bs=512k/1m,rw=read/write,numjobs=32/64
mdtest是专门针对文件系统元数据性能的测试工具,主要测试指标是creation和stat,需要采用mpirun并发测试:
mpirun --allow-run-as-root -mca btl_openib_allow_ib 1 -host yanrong-node0:${
slots},yanrong-node1:${
slots},yanrong-node2:${
slots} -np ${
num_procs} mdtest -C -T -d /mnt/yrfs/mdtest -i 1 -I ${
files_per_dir} -z 2 -b 8 -L -F -r -u
存储性能测试不仅仅测试集群正常场景下的指标,还要包含其他场景:
- 存储容量在70%以上或者文件数量上亿的性能指标
- 节点/磁盘故障后的性能指标
- 扩容过程时的性能指标
容器存储功能
除了存储的核心功能(高可靠/高可用/高性能),对于容器存储,还需要几个额外的功能保证生产环境的稳定可用。
- Flexvolume/CSI接口的支持,动态/静态PV的支持
- 存储配额。对于Kubernetes的管理员来说,存储的配额是必须的,否则存储的使用空间会处于不可控状态
- 服务质量(QoS)。如果没有QoS,存储管理员只能期望存储提供其他监控指标,以保证在集群超负荷时,找出罪魁祸首