1结构体是什么?
如果说数组是具有相同数据类型的集合。那么结构体就是可以同时具有相同数据类型和不同数据类型的集合。
结构体:结构体是一些值的集合,这些值称为成员变量。结构的每个成员变量可以是不同的类型变量。
2结构的声明:
struct tag//struct为结构体关键字。tag为结构体的名称,可以省略
{
Member-list;/*成员列表:具有不同或者相同类型的集合。
在定义出结构体变量后该变量应该包含成员列表的所有成员
,成员与成员之间使用分号分隔*/
}variable-list/*值列表:可以为空,一旦使用则定义出结构体变量*/;
例如:定义一个结构体
方法1:
struct A//结构体名称为A
{
int a;//分号间隔的结构体成员
char b;
double c;
};//结构体变量
int main()
{
struct A obj;//利用结构体名字可以//随时定义变量来使用
return 0;
}
方法2
struct A
{
int a;
char b;
double c;
}obj,*p;
方法3:
//由于该结构体没有名字,所以变量只能在值//列表处定义
struct
{
int a;
char b;
double c;
}obj;
方法4:
//由于没有变量和名称,无法使用
struct
{
int a;
char b;
double c;
};
注意:对于以下情况,编译器会把两个声明当成完全不同的类型。结构体名称和变量不能同时省略,必须至少保留一个。
结构体1
struct
{
int a;
char b;
double c;
}obj,a[10],*p;
结构体2:
struct
{
int a;
char b;
double c;
}x;
int main()
{
p = &x;//错误:不能将 "struct <unnamed> *" 类型的值分配到 "struct <unnamed> *" 类型的实体
return 0; }
说明:结构体1和结构体2都是匿名结构体。
不同的结构体无论其内容如何相似,都是不同的类型。
3 结构体的成员:可以是标量,数组,指针,甚至是其他结构体。
如何访问结构体成员?
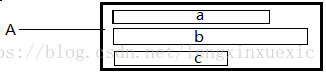
如图所示:结构体A有三个成员a,b,c。大小,类型各不相同。但是每个成员变量都有自己的名字。
4 结构体变量访问成员
1)通过点操作符(.)访问。
点操作符接受两个操作数:结构体变量名.结构体成员名
例如:对于上文中方法2的结构体A。
变量obj要访问A的结构体成员a。
obj . a = 30;
指针p要访问A的结构体成员。
(*p).a = 20;
2)通过指向操作符(->)访问。
例如:对于上文中方法2的结构体A。指针p要访问A的结构体成员。
p->a = 30;
5 结构体的地址
对于下面的结构体A:
struct A{
int a; char b;
double c;
}obj,*p;
int main()
{
printf("%#p\n", &obj);
printf("%#p\n", &obj.a);
printf("%#p\n", &obj.b);
printf("%#p\n", &obj.c);
system("pause");
return 0;
}
执行结果如图所示:
1)结构体变量的地址和首个成员的地址是一致的。
2)结构体成员的地址是依次递增的
虽然结构体的地址和首个成员的地址是一样的,但是含义各不相同。结构体的地址是结构体指针。结构体的首个成员的地址是其类型的指针。例如结构体A的成员a的地址就是整形指针。

6.结构体的自引用
是否可以在一个结构中包含一个类型为该结构体本身的变量成员呢?
方式1
struct A
{
int a;
struct A obj;//错误的引用方式,编译器不能判断出应该开辟多大的内存空间
};
方式2
struct A
{
int a;
struct A *obj;//正确的引用方式,此时obj本质上是一个指针,指向自己。
};//指针obj可以指向自己,也可以指向其他的A类变量(链表)。

说明:结构体内部不可以包含本身的变量,但可以包含本身的结构体指针。
结构体1
typedef struct
{
int a;
Node* next;
}Node;
结构体2
typedef struct Node
{
int a;
struct Node* next;
}Node;
对于上面的两种情况,是否正确?
对于情况一中的自引用,由于在结构体内部结构体本身并未被定义出来,错误。所以第二种情况实现自引用中名字不省略才正确。
7. 结构体的不完全声明
struct B;//声明B
struct A
{
int a;
struct B*b;//在此处使用了还未定义类型B,需要在使用前做出B的声明
};
struct B
{
int b;
struct A* a;//在此处使用了已定义类型A,不需要声明
8. 结构体变量的初始化
struct A
{
int a;
int b;
}p;
struct B
{
int b;
struct A p;
struct B* a;
}obj;
结构体不能整体赋值,但可以整体初始化。
(初始化:int a = 10;//a被创建并且分配初值
赋值:int b; b = 20;//给已有的变量b值)
同样的,初始化结构体A:
struct A num = { 10, 20 };//创建变量num并给每个成员赋值
初始化嵌套的结构体B:结构体B内部的结构体变量用{ }嵌套来初始化
obj = { 10, { 10, 20 }, NULL };
9. 结构体内存对齐
1)结构体内存对齐规则
*结构体的首个成员在结构体变量偏移量为0的地址处。
第一个成员的地址和结构体本身的地址一样,因此首个成员的地址相对于结构体地址偏移量为0.因此第一个成员不需要对齐,默认它是对齐的。但是它具有对齐数。
*其他变量要对齐到对齐数的整数倍的地址处。对齐数=编译器默认的对齐数与该成员大小的较小值。Vs默认为8,linux为4.
例如:在VS下,char类型1字节,1<8,所以char类型对齐数为1,int对齐数4,double对齐数为8.
struct A
{
char a;//a放在偏移量为0处,对齐数为1。
int b;//int对齐数为4,要对齐到对齐数的最小整数倍处,空三个字节,即放在偏移量为4处
char c;//放在偏移量为5处
};
*结构体总大小为最大对齐数(每个成员变量除了第一个成员都有一个对齐数)的整数倍。
对于上面的结构体A,大小为12,最大对齐数4,12/4=3。是整数倍,合理。
如果不是整数倍,则加上一个最小值使对齐数变为最小整数倍
*如果嵌套了结构体的情况,嵌套结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐(含嵌套结构体的对齐数)数的整数倍。
struct B
{
int b;//1
struct A p;//结构体A的最大对齐数4,大小12
char b;//1
}obj;
结构体B的大小是1+3空+12+1+3空=20
1)为什么存在内存对齐?
*平台原因
不是所有的硬件平台都能够访问任意地址的任意数据;某些硬件平台只能在某些地址处取某些特定的数据,否则会出现硬件异常
*性能原因
数据结构应尽可能的在自然边界对齐。为了访问未对齐的内存,处理器需要两次访问内存,对齐的内存访问只需要一次。
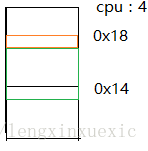
struct A
{
char a;
int b;
}p;
对于上面一段内存,不考虑内存对齐,连续存放数据a,b。假设cpu每次能间隔4个字节访问数据。第一次读取数据从0x18访问,读取一个字节a。第二次读取b要访问int型4个字节,而cpu只能从0x18或者0x14地址处访问,因此cpu需要先从0x18处读取4个字节,再去掉第一个字节,再从0x14处读取4个字节,去掉后三个字节。总共访问两次内存。

如果将a放在0x18,b放在0x14处,则访问a,b都只需要一次。
因此:内存对齐是为了以空间换时间,来提高效率。
10.结构体传参
情况1:
struct A
{
char a;
int b[1024*1024];
char c;
}m;
void fun(struct A a)
{
}
int main()
{
int i = 0;
for (; i < 5000; i++)
{
fun(m);//在调用该函数时需要传入整个结构体,效率极低
}
return 0;
}
情况2:
struct A
{
char a;
int b[1024*1024];
char c;
}m;
void fun(struct A *a)
{
}
int main()
{
int i = 0;
for (; i < 5000; i++)
{
fun(&m);//在调用该函数时只需要传入结构体指针,效率高
}
system("pause");
return 0;
}因此在调用结构体的时候,应该传入结构体指针,而不是结构体变量。