原文标题:Deep Reinforcement Adversarial Learning against Botnet Evasion Attacks
0x01 太长不看版
有监督学习得到的网络流量classifier容易被规避,并且无法面对新颖的攻击。
为了让classifier更鲁棒,使用了DRL来自动生成逼真的攻击样本,然后用这些样本会扔到数据集里强化classifier。此时,我们甚至可以面对以前没出现过的攻击。
0x02 intro
针对基于ML检测器的对抗攻击希望生成能够骗过检测器的对抗样本,即真正的攻击样本被识别为无害的。
这些对抗样本可以在训练的时候引入,也可以在做分类的时候引入。我们考虑在做分类的时候引入对抗样本的情形。这种事情在图像和语音领域中已经被做烂了。
我们考虑的场景如下图所示:企业网络。内含许多主机,至少一个成为了bot。网络通信被NIDS监视。这是一个灰箱模型,因为攻击者把内网配置包括检测配置知道了个遍也不太现实。
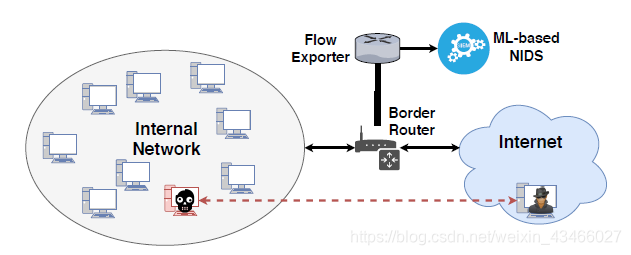
攻击者不知道IDS用啥来训练的,但是攻击者可以猜IDS用的是具有啥特征的数据来训练。
事实上,攻防双方考虑的特征确实有很大的重合。
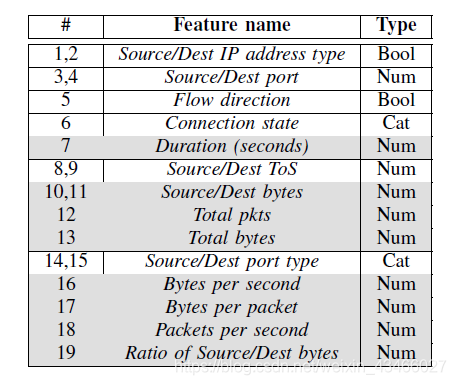
例如,灰色的属性就是攻击者使用的属性。攻击者试图稍微修改botnet属性来逃避检测。这些修改会稍微更改原始流量特征,但是不改变botnet的属性,例如,加点通信延迟或者扔点垃圾包就行了,只需要稍稍改变botnet的控制逻辑。
0x03 解决方案
原文用DRL来生成现实的对抗样本,使得恶意性保留,但是不会被检测。
这个解决方案分成三个阶段。
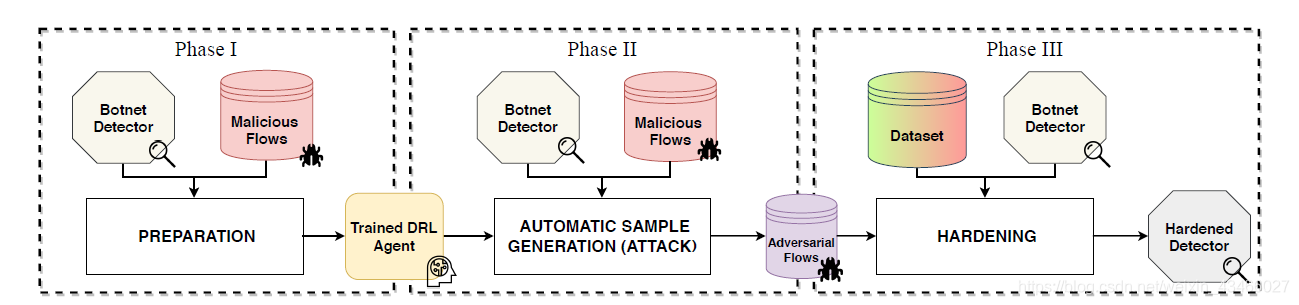
阶段一:准备
创造一个DRL agent,可以根据botnet的网络流来生成对抗性样本。
我们认为,botnet软件的底层逻辑不会别改变,而且攻击者探测检测模型所提交的sample数量也受限。
agent将会学习如何提交尽量多的逃逸攻击样本。
环境包括两个部分:
- 状态生成器,将输入流翻译成可以被agent识别的状态s;
- botnet检测器,用来做入侵检测的。
reward就是对生成的样本判断对错。Agent会持续修改样本,直到生成样本可以逃脱检测或者一直失败。
action是对数据流的微小改动。agent会改动下面的几个特征:持续时间,已发送字节,已接收字节,已发送数据包(即表中灰色的特征)。
使用DDQN主要是为了防止高估。DDQN会产生和初始变体明显不同的样本。
使用SARSA是为了尽力避免被检测出。
总之,阶段一的输出是DRL agent A(b),其中b是botnet。这个agent被用来生成恶意对抗样本。
阶段二:自动生成样本
A(b)用来生成恶意样本。步骤如下:
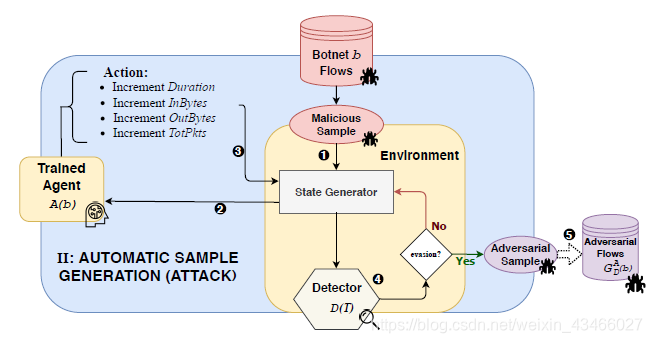
- 系统接收b的恶意流作为输入,送给状态生成器生成状态;
- 状态送给agent A(b);
- agent把最佳action传送给生成器,进而生成修改后的样本;
- 把修改后的样本交给检测器判断,
- 如果成功骗过检测器,则这个数据被detector用来进行学习;否则把状态回传给生成器并重复2-4,进一步修改数据包。
这个过程中agent没有得到任何收益。
这个过程中会得到恶意流,它们是b的恶意流的魔改版。
阶段三:增强
使用増广训练集训练detector。其分类阈值是増广数据集中恶意样本的比率。