Lucene将索引文档的过程设计成两个阶段,写入内存阶段和写入硬盘阶段。在写入内存阶段,Lucene通过IndexChain把document分解并把相关信息存储到内存中,等到满足flush条件(内存容量或者文档个数积累到临界值),就通过IndexChain把内存中的数据写入硬盘。IndexChain是Lucene索引文档很重要的一部分,那么IndexChain是什么呢
Lucene形成索引的过程其实就是对document进行分解的过程。通过对document的分解,得到词典、倒排表等信息。IndexChain就是分解document的对象集合,或者说架构。索引链的结构如下图所示
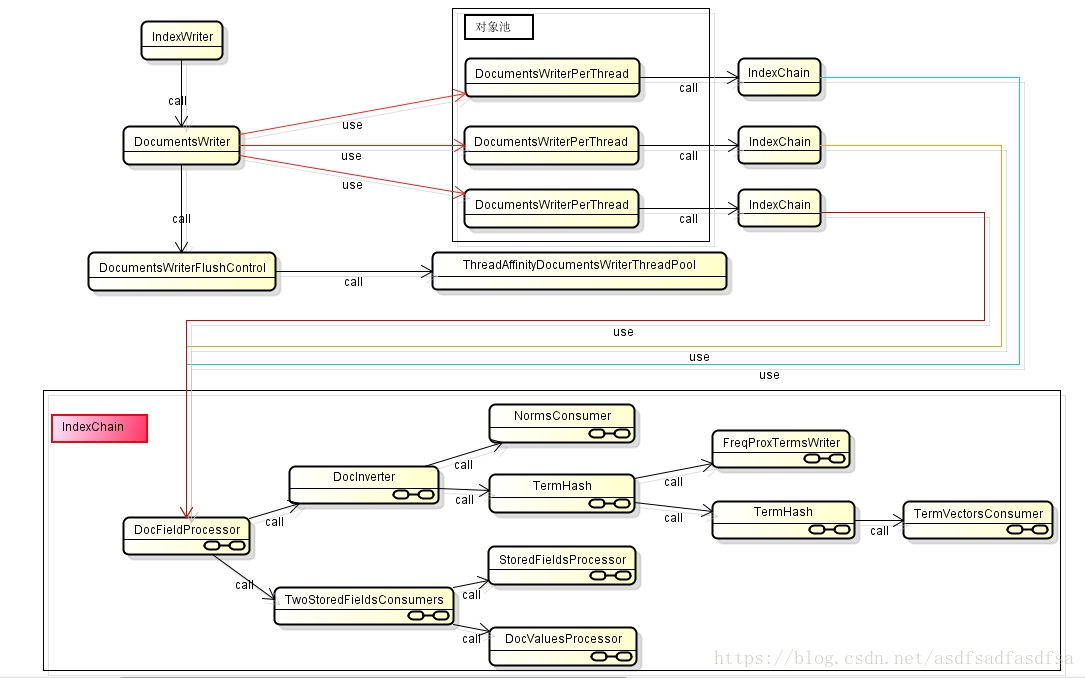
上图中IndexChain的起点是DocFieldProcessor,它会分别调用DocInverter(倒排信息处理)和TowStoredFieldsConsumer(正向信息处理)。 反向信息有四种:
信息种类 |
作用 |
处理组件 |
norm信息 |
用来消除长文本和短文本之间的差距 |
NormsConsumer |
Freq信息 |
文档排序时的重要因子 |
FreqProxTermsWriter |
Pos信息 |
位置信息,在PhraseQuery时会有用 |
FreqProxTermsWriter |
TermVector |
高亮处理需要记录的信息 |
TermVectorsConsumer |
正向信息有两种:
信息种类 |
作用 |
处理组件 |
Fields |
形成完整的一个doc |
StoredFieldsProcessor |
docValues |
排序因子 |
DocValuesProcessor |