编辑丨极市平台
M5Product Dataset
论文地址:https://arxiv.org/abs/2109.04275
数据集地址:https://xiaodongsuper.github.io/M5Product_dataset/index.html
M5Product 数据集是一个大规模的多模态预训练数据集,具有针对电子产品的粗粒度和细粒度注释。
600 万个多模态样本、5k个属性和2400 万个值
5 种模式-图像 文本 表 视频 音频
600 万个类别注释,包含6k个类别
广泛的数据源(100 万商户提供)

Ego4D
论文地址:https://arxiv.org/abs/2110.07058
数据集地址:https://ego4d-data.org/
在全球 74 个地点和 9 个国家/地区收集的大规模、以自我为中心的数据集和基准套件,包含超过 3,670 小时的日常生活活动视频。使用七种不同的现成头戴式摄像机捕获数据:GoPro、Vuzix Blade、Pupil Labs、ZShades、OR-DRO EP6、iVue Rincon 1080 和 Weeview。除了视频,部分 Ego4D 还提供其他数据模式:3D 扫描、音频、凝视、立体、多个同步的可穿戴相机和文本叙述。

Daily Multi-Spectral Satellite Dataset
论文链接:https://arxiv.org/pdf/2203.12560.pdf
数据集地址:https://mediatum.ub.tum.de/1650201
DynamicEarthNet 数据集包含每日 Planet Fusion 图像,以及两年内全球 75 个地区的每月土地覆盖类别。七个土地覆盖类别以时间一致的方式手动注释。还提供了 Sentinel 2 图像。该数据集是第一个大规模的多类和多时态变化检测基准,我们希望它能促进地球观测和计算机视觉领域的多时态研究新浪潮。

VCSL (Video Copy Segment Localization) dataset
论文地址:https://arxiv.org/abs/2203.02654
数据集地址:https://github.com/alipay/VCSL/tree/main/data
与现有的受视频级标注或小规模限制的复制检测数据集相比,VCSL 不仅具有两个数量级的片段级标记数据,16 万个真实视频副本对包含超过 28 万个本地复制片段对,而且涵盖各种视频类别和广泛的视频时长。每个收集的视频对中的所有复制片段都是手动提取的,并附有精确注释的开始和结束时间戳。

Rope3D
论文地址:https://arxiv.org/abs/2203.13608
数据集地址:https://thudair.baai.ac.cn/rope
Rope3D目标检测数据集是首个同时具有图像和点云3D联合标注的大规模、多视角的路侧数据集,共50009帧图像数据以及对应的2D&3D标注结果。基于该数据集,可以进行路端单目3D检测任务的研究。

EDS 数据集
数据集地址:https://github.com/DIG-Beihang/PSN
EDS 数据集针对由机器硬件参数引起的难以察觉的域间偏移问题研究,包含了来自 3 台不同 X 光机器的 14219 张图片, 其中 10 类物品, 共计 31655 个目标实例,均由专业标注人员进行标注。
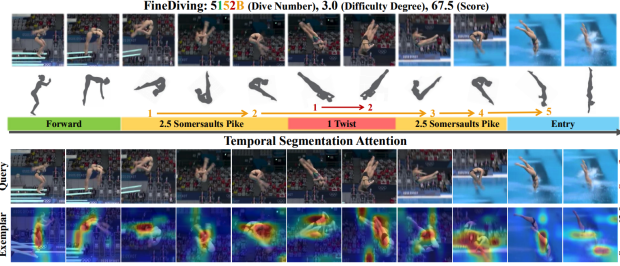
FineDiving
论文地址:https://arxiv.org/pdf/2204.03646.pdf
数据集地址:https://github.com/xujinglin/FineDiving
本数据集收集了奥运会、世界杯、世锦赛以及欧锦赛的跳水项目比赛视频。每个比赛视频都提供了丰富的内容,包括所有运动员的跳水记录、不同视角的慢速回放等。
我们构建了一个由语义和时间结构组织的细粒度视频数据集,其中每个结构都包含两级注释。
对于语义结构,动作级标签描述了运动员的动作类型,步骤级标签描述了过程中连续步骤的子动作类型,其中每个动作过程中的相邻步骤属于不同的子动作类型。子动作类型的组合产生动作类型。在时间结构中,动作级标签定位运动员执行的完整动作实例的时间边界。在此注释过程中,我们丢弃所有不完整的动作实例并过滤掉慢速播放。步骤级标签是动作过程中连续步骤的起始帧。
PIAA 数据库
论文地址:https://arxiv.org/abs/2203.16754
数据集地址:https://cv-datasets.institutecv.com/#/data-sets
个性化图像美学评估 (PIAA) 由于其高度主观性而具有挑战性。人们的审美取决于多种因素,包括形象特征和主体性格。现有的 PIAA 数据库在注释多样性方面,特别是在学科方面受到限制,已不能满足日益增长的 PIAA 研究需求。为了解决这一难题,我们对个性化图像美学进行了迄今为止最全面的主观研究,并引入了一个新的具有丰富属性的个性化图像美学数据库(PARA),该数据库由 438 个主题的 31,220 张带有注释的图像组成。PARA 具有丰富的标注,包括 9 个面向图像的客观属性和 4 个面向人的主观属性。

本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~