文章内容均出自《python爬虫开发》
文章目录
5.1 多线程爬虫
5.1.1 多线程的优势
在掌握了requests与正则表达式以后,就可以开始实战爬取一些简单的网址了。
但是,此时的爬虫只有一个进程、一个线程,因此称为单线程爬虫。单线程爬虫每次只访问一个页面,不能充分利用计算机的网络带宽。一个页面最多也就几百KB,所以爬虫在爬取一个页面的时候,多出来的网速和从发起请求到得到源代码中间的时间都被浪费了。如果可以让爬虫同时访问10个页面,就相当于爬取速度提高了10倍。为了达到这个目的,就需要使用多线程技术了。
Python这门语言,有一个全局解释器锁(Global Interpreter Lock, GIL)。这导致Python的多线程都是伪多线程,即本质上还是一个线程,但是这个线程每个事情只做几毫秒,几毫秒以后就保存现场,换做其他事情,几毫秒后再做其他事情,一轮之后回到第一件事上,恢复现场再做几毫秒,继续换……微观上的单线程,在宏观上就像同时在做几件事。这种机制在I/O(Input/Output,输入/输出)密集型的操作上影响不大,但是在CPU计算密集型的操作上面,由于只能使用CPU的一个核,就会对性能产生非常大的影响。所以涉及计算密集型的程序,就需要使用多进程,Python的多进程不受GIL的影响。爬虫属于I/O密集型的程序,所以使用多线程可以大大提高爬取效率。
5.1.2 多进程库:multiprocessing
multiprocessing本身是Python的多进程库,用来处理与多进程相关的操作。但是由于进程与进程之间不能直接共享内存和堆栈资源,而且启动新的进程开销也比线程大得多,因此使用多线程来爬取比使用多进程有更多的优势。
multiprocessing下面有一个dummy模块,它可以让Python的线程使用multiprocessing的各种方法。
dummy下面有一个Pool类,它用来实现线程池。
这个线程池有一个map()方法,可以让线程池里面的所有线程都“同时”执行一个函数。
例如:
在学习了for循环后
for i in range(10):
print(i*i)
这种写法当然可以得到结果,但是代码是一个数一个数地计算,效率并不高。而如果使用多线程的技术,让代码同时计算很多个数的平方,就需要使用multiprocessing.dummy来实现:
多线程的使用范例:
from multiprocessing.dummy import Pool
def cal_pow(num):
return num*num
pool=Pool(3)
num=[x for x in range(10)]
result=pool.map(cal_pow,num)
print('{}'.format(result))
在上面的代码中,先定义了一个函数用来计算平方,然后初始化了一个有3个线程的线程池。这3个线程负责计算10个数字的平方,谁先计算完手上的这个数,谁就先取下一个数继续计算,直到把所有的数字都计算完成为止。
在这个例子中,线程池的map()方法接收两个参数,第1个参数是函数名,第2个参数是一个列表。注意:第1个参数仅仅是函数的名字,是不能带括号的。第2个参数是一个可迭代的对象,这个可迭代对象里面的每一个元素都会被函数clac_power2()接收来作为参数。除了列表以外,元组、集合或者字典都可以作为map()的第2个参数。
5.1.3 多线程爬虫开发
由于爬虫是I/O密集型的操作,特别是在请求网页源代码的时候,如果使用单线程来开发,会浪费大量的时间来等待网页返回,所以把多线程技术应用到爬虫中,可以大大提高爬虫的运行效率。举一个例子。洗衣机洗完衣服要50min,水壶烧水要15min,背单词要1h。如果先等着洗衣机洗衣服,衣服洗完了再烧水,水烧开了再背单词,一共需要125min。
但是如果换一种方式,从整体上看,3件事情是可以同时运行的,假设你突然分身出另外两个人,其中一个人负责把衣服放进洗衣机并等待洗衣机洗完,另一个人负责烧水并等待水烧开,而你自己只需要背单词就可以了。等到水烧开,负责烧水的分身先消失。等到洗衣机洗完衣服,负责洗衣服的分身再消失。最后你自己本体背完单词。只需要60min就可以同时完成3件事。
当然,大家肯定会发现上面的例子并不是生活中的实际情况。现实中没有人会分身。真实生活中的情况是,人背单词的时候就专心背单词;水烧开后,水壶会发出响声提醒;衣服洗完了,洗衣机会发出“滴滴”的声音。所以到提醒的时候再去做相应的动作就好,没有必要每分钟都去检查。上面的两种差异,其实就是多线程和事件驱动的异步模型的差异。本小节讲到的是多线程操作,后面会讲到使用异步操作的爬虫框架。现在只需要记住,在需要操作的动作数量不大的时候,这两种方式的性能没有什么区别,但是一旦动作的数量大量增长,多线程的效率提升就会下降,甚至比单线程还差。而到那个时候,只有异步操作才是解决问题的办法。
下面通过两段代码来对比单线程爬虫和多线程爬虫爬取bd首页的性能差异:
从运行结果可以看到,一个线程用时约16.2s,5个线程用时约3.5s,时间是单线程的五分之一左右。从时间上也可以看到5个线程“同时运行”的效果。但并不是说线程池设置得越大越好。从上面的结果也可以看到,5个线程运行的时间其实比一个线程运行时间的五分之一要多一点。这多出来的一点其实就是线程切换的时间。这也从侧面反映了Python的多线程在微观上还是串行的。因此,如果线程池设置得过大,线程切换导致的开销可能会抵消多线程带来的性能提升。线程池的大小需要根据实际情况来确定,并没有确切的数据。读者可以在具体的应用场景下设置不同的大小进行测试对比,找到一个最合适的数据。
5.2 爬虫的常见搜索算法
5.2.1 深度优先搜索
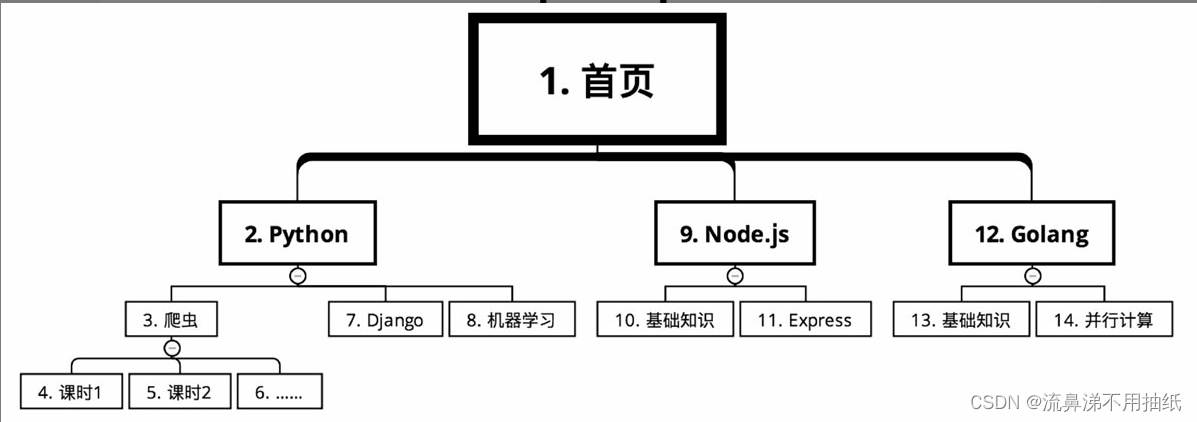
某在线教育网站的课程分类,需要爬取上面的课程信息。从首页开始,课程有几个大的分类,比如根据语言分为Python、Node.js和Golang。每个大分类下面又有很多的课程,比如Python下面有爬虫、Django和机器学习。每个课程又分为很多的课时。
在深度优先搜索的情况下,爬取路线如图所示(序号从小到大)
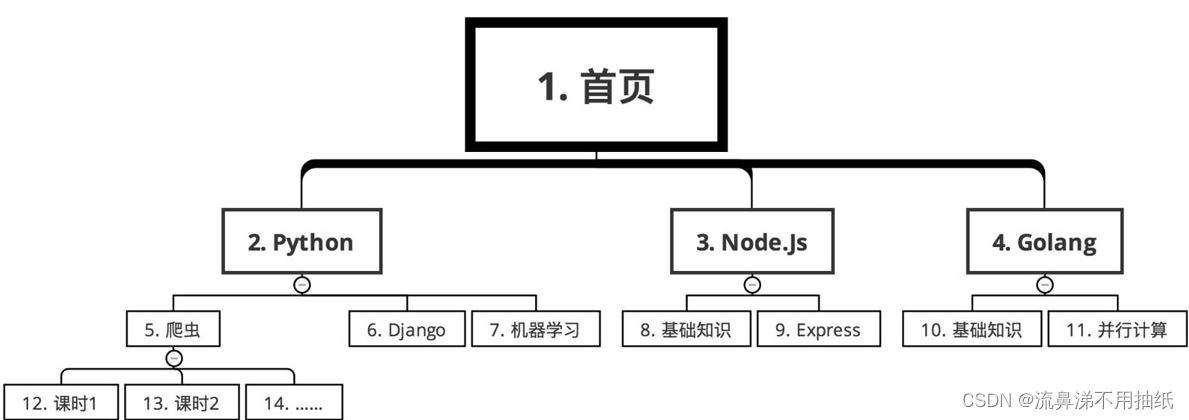
5.2.2 广度优先搜索
先后顺序如下
5.2.3 算法选择
例如要爬取某网站全国所有的餐馆信息和每个餐馆的订单信息。假设使用深度优先算法,那么先从某个链接爬到了餐馆A,再立刻去爬餐馆A的订单信息。由于全国有十几万家餐馆,全部爬完可能需要12小时。这样导致的问题就是,餐馆A的订单量可能是早上8点爬到的,而餐馆B是晚上8点爬到的。它们的订单量差了12小时。而对于热门餐馆来说,12小时就有可能带来几百万的收入差距。这样在做数据分析时,12小时的时间差就会导致难以对比A和B两个餐馆的销售业绩。相对于订单量来说,餐馆的数量变化要小得多。所以如果采用广度优先搜索,先在半夜0点到第二天中午12点把所有的餐馆都爬取一遍,第二天下午14点到20点再集中爬取每个餐馆的订单量。这样做,只用了6个小时就完成了订单爬取任务,缩小了由时间差异致的订单量差异。同时由于店铺隔几天抓一次影响也不大,所以请求量也减小了,使爬虫更难被网站发现。
又例如,要分析实时舆情,需要爬百度贴吧。一个热门的贴吧可能有几万页的帖子,假设最早的帖子可追溯到2010年。如果采用广度优先搜索,则先把这个贴吧所有帖子的标题和网址都获取下来,然后根据这些网址进入每个帖子里面以获取每一层楼的信息。可是,既然是实时舆情,那么7年前的帖子对现在的分析意义不大,更重要的应该是新的帖子才对,所以应该优先抓取新的内容。相对于过往的内容,实时的内容才最为重要。因此,对于贴吧内容的爬取,应该采用深度优先搜索。看到一个帖子就赶紧进去,爬取它的每个楼层信息,一个帖子爬完了再爬下一个帖子。当然,这两种搜索算法并非非此即彼,需要根据实际情况灵活选择,很多时候也能够同时使用。