1、爬虫说明
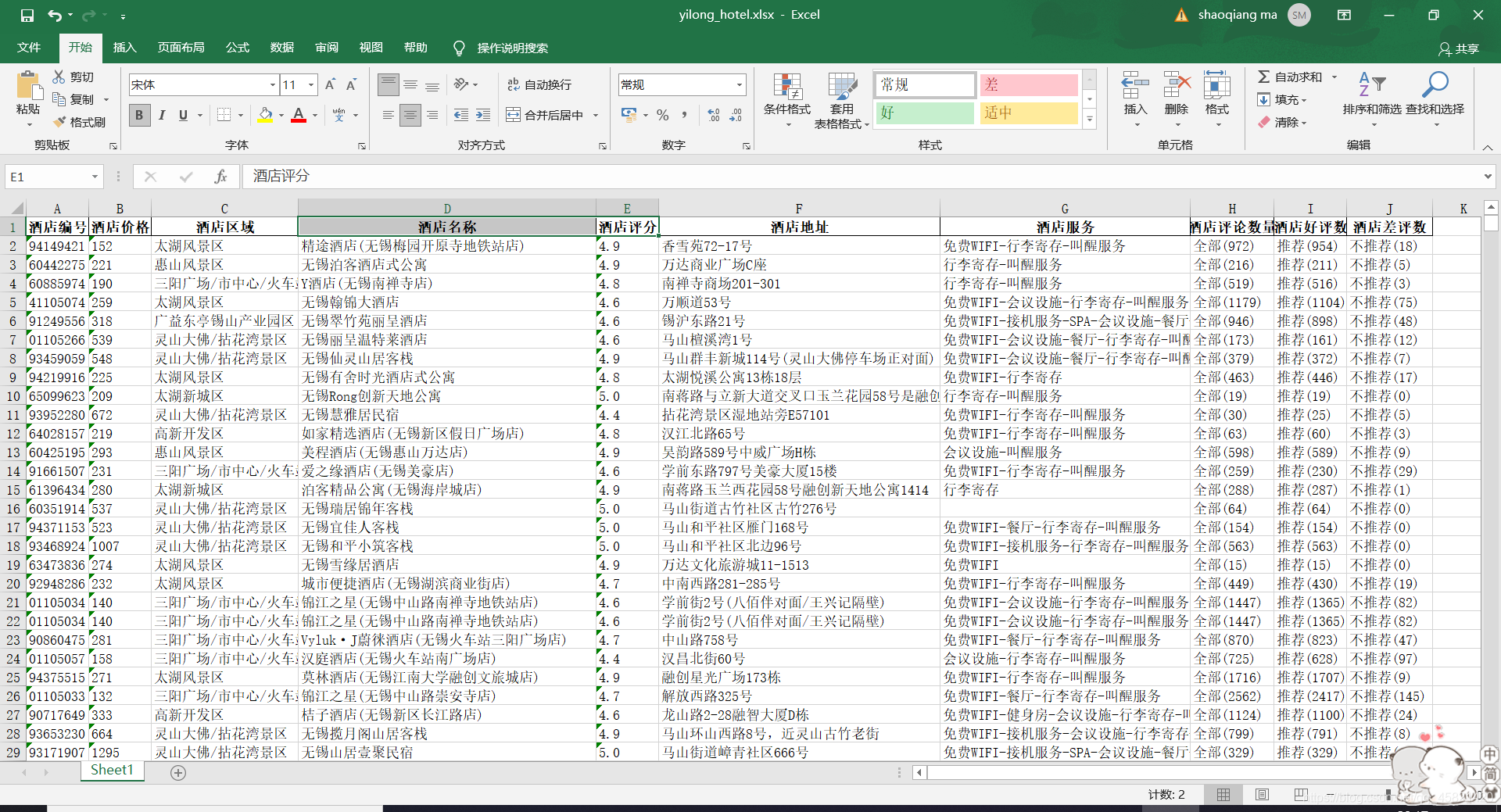
同城艺龙的反爬做的是非常好的,本博主在与同城艺龙进行了一整天的殊死搏斗才将其完全的爬下来,本博主是以无锡为例,将无锡的所有酒店的相关信息都爬了下来,共3399条酒店数据,当然其他城市也是可以的,只需要修改指定字段即可。本博主是先将数据存储到MongoDB中然后再将数据转存到exlce中,以下是我爬取的数据截图
2、爬虫分析
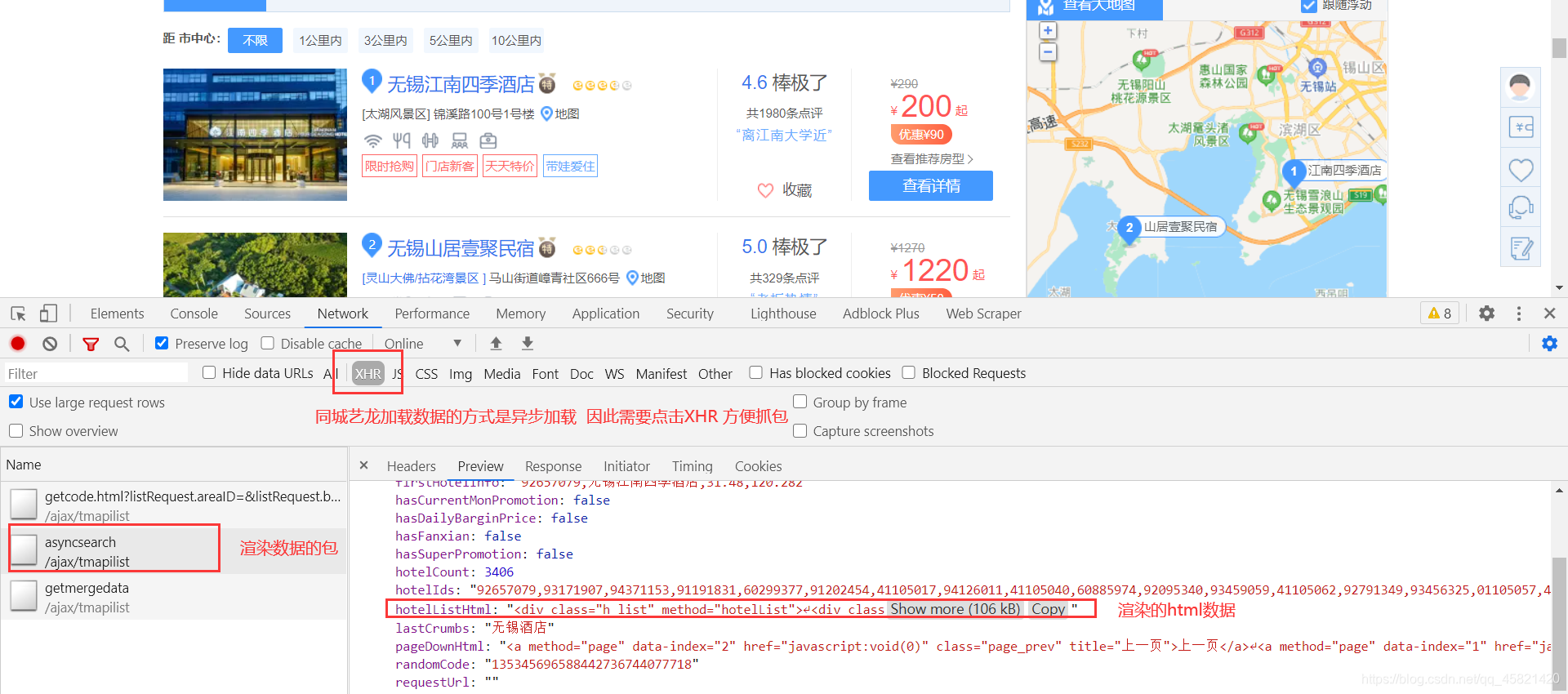
- 找到渲染数据的数据包
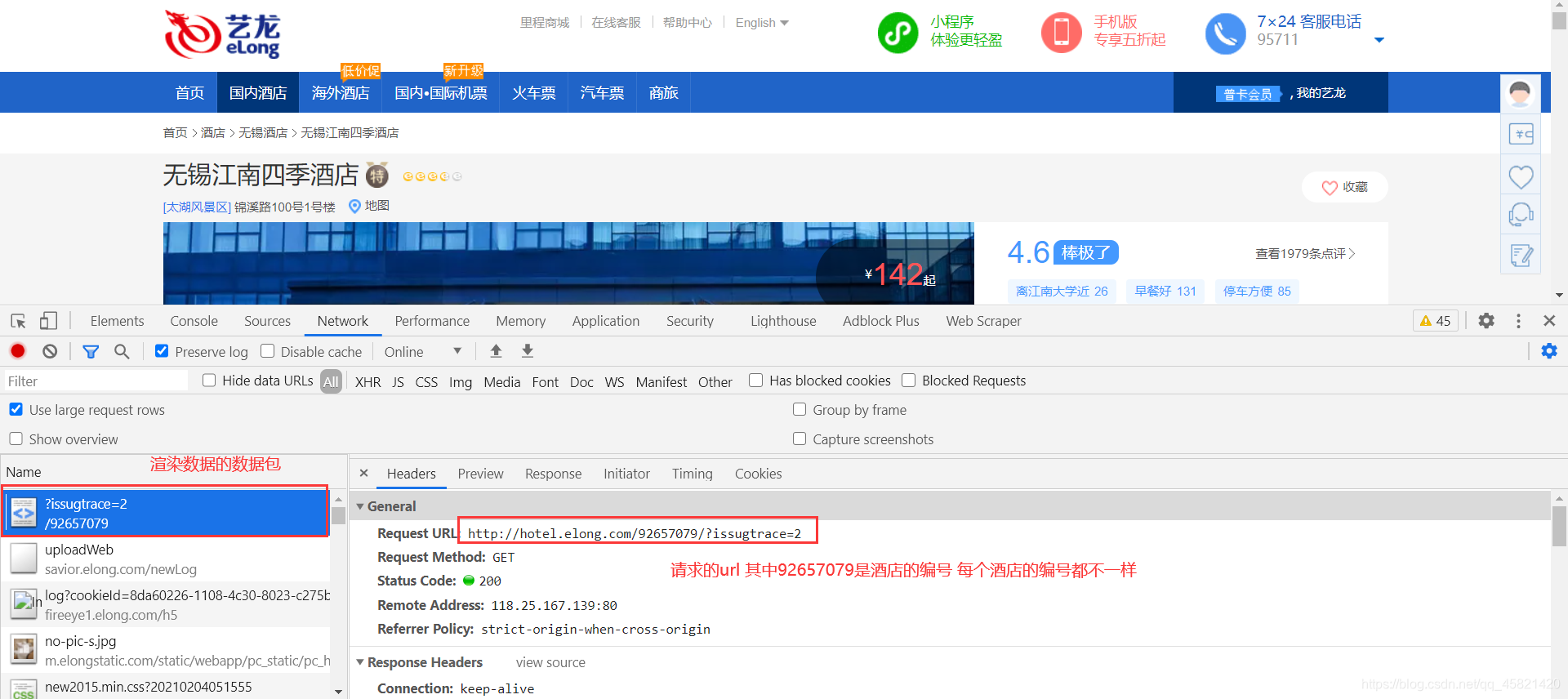
- 分析请求

- 分析请求参数(只截取部分 需要修改的参数部分爬虫代码注释已指明)

- 详情页面信息(通过xpath解析即可获取数据)
3、代码实操
注:代码有大量注释 注释中有本博主在爬取数据以及对数据的相关处理手段
- 爬虫代码:
import json
import time
from lxml import html
import requests
import re
from pymongo import MongoClient
class YiLongSpider(object):
def __init__(self):
# 列表页url
self.list_url_temp = 'http://hotel.elong.com/ajax/tmapilist/asyncsearch'
# 详情页url
self.detail_url_temp = 'http://hotel.elong.com/{}/?issugtrace=2'
# 酒店价格url
self.price_url_temp = 'http://hotel.elong.com/ajax/tmapidetail/gethotelroomsetjvajson'
# 构造请求列表页响应体
self.list_dat = {
"code":"8013851",
"listRequest.areaID":"",
"listRequest.bedLargeTypes":"",
"listRequest.bookingChannel":"1",
"listRequest.breakfasts":"0",
"listRequest.cancelFree":"false",
"listRequest.cardNo":"240000001103487989", # 此参数要与detail_dat的cardNo参数保持一致
"listRequest.checkInDate":"2021-02-11 00:00:00", # 参数需要替换成当天日期
"listRequest.checkOutDate":"2021-02-12 00:00:00", # 参数需要替换成当天日期的后一天
"listRequest.cityID":"1105",
"listRequest.cityName":"无锡",
"listRequest.crawledFlag":"0",
"listRequest.customLevel":"11",
"listRequest.discountIds":"",
"listRequest.distance":"20000",
"listRequest.endLat":"0",
"listRequest.endLng":"0",
"listRequest.epcCreateOrderGuideVersion":"Z",
"listRequest.facilityIds":"",
"listRequest.guokaoFlag":"false",
"listRequest.highPrice":"0",
"listRequest.hotelBrandIDs":"",
"listRequest.hotelIDs":"",
"listRequest.interceptAction":"0",
"listRequest.isAdvanceSave":"false",
"listRequest.isAfterCouponPrice":"true",
"listRequest.isCoupon":"false",
"listRequest.isDebug":"false",
"listRequest.isLimitTime":"false",
"listRequest.isLogin":"false",
"listRequest.isMobileOnly":"true",
"listRequest.isNeed5Discount":"true",
"listRequest.isNeedNotContractedHotel":"false",
"listRequest.isNeedSimilarPrice":"false",
"listRequest.isReturnNoRoomHotel":"true",
"listRequest.isStaySave":"false",
"listRequest.isTrace":"false",
"listRequest.isUnionSite":"false",
"listRequest.isnstantConfirm":"false",
"listRequest.keywords":"",
"listRequest.keywordsType":"0",
"listRequest.language":"cn",
"listRequest.lat":"31.497648",
"listRequest.listType":"0",
"listRequest.lng":"120.316954",
"listRequest.lowPrice":"0",
"listRequest.orderFromID":"1003",
"listRequest.pageIndex":"1",
"listRequest.pageSize":"20",
"listRequest.payMethod":"0",
"listRequest.personOfRoom":"0",
"listRequest.poiId":"0",
"listRequest.poiName":"",
"listRequest.productTypes":"1, 6, 26",
"listRequest.promotionChannelCode":"0000",
"listRequest.promotionSwitch":"-1",
"listRequest.proxyID":"ZD",
"listRequest.rankType":"0",
"listRequest.returnFilterItem":"true",
"listRequest.sectionId":"",
"listRequest.sellChannel":"1",
"listRequest.seoHotelStar":"0",
"listRequest.sortDirection":"1",
"listRequest.sortMethod":"1",
"listRequest.standBack":"-1",
"listRequest.starLevels":"",
"listRequest.startLat":"0",
"listRequest.startLng":"0",
"listRequest.sug_act_info":"",
"listRequest.taRecommend":"false",
"listRequest.themeIds":"",
"listRequest.traceId":" de063359-ec4e-4c9a-b6e4-381e38079a4d",
"listRequest.wordId":"",
"listRequest.wordType":"-1",
"listRequest.elongToken": "8340df84-1a62-4c32-8655-0d9f55894610",
"listRequest.trace_token":"|*|cityId:1105|*|qId:41b5a7eb-3c68-4222-b17b-ae94b94c5b17|*|st:city|*|sId:1105|*|",
}
# 构造请求详情页响应体 hotelIDs为每一个酒店的编号
self.detail_dat = {
"bookingChannel": "1",
"cardNo": "240000001103487989", # 此参数要与list_dat的cardNo参数保持一致
"cheapestPriceFlag": "false",
"checkInDate": "2021-02-11", # 参数需要替换成当天日期
"checkOutDate": "2021-02-12", # 参数需要替换成当天日期的后一天
"crawledFlag": "0",
"customerLevel": "11",
"hotelIDs": "01105111",
"interceptAction": "0",
"isAfterCouponPrice": "true",
"isDebug": "false",
"isLogin": "false",
"isMobileOnly": "false",
"isNeed5Discount": "false",
"isTrace": "false",
"language": "cn",
"needDataFromCache": "true",
"needPromotion": "true",
"orderFromID": "1003",
"payMethod": "0",
"productType": "0",
"promotionChannelCode": "0000",
"proxyID": "ZD",
"sellChannel": "1",
"settlementType": "0",
"updateOrder": "false",
"elongToken": "8340df84-1a62-4c32-8655-0d9f55894610",
"code": "8965113",
}
# 由于列表页url请求头和详情页面url请求头不同 因此需要分别构造请求头
# 构造列表响应头
self.list_headers = {
# Cookie更换成自己的Cookie值
'Cookie': 'CookieGuid=8340df84-1a62-4c32-8655-0d9f55894610; H5CookieId=8da60226-1108-4c30-8023-c275b40d9b1b; firsttime=1612921642621; CitySearchHistory=0101%23%E5%8C%97%E4%BA%AC%23beijing%23%401105%23%E6%97%A0%E9%94%A1%23wuxi%23; _fid=8340df84-1a62-4c32-8655-0d9f55894610; SHBrowseHotel=cn=94074245%2C%2C%2C%2C%2C%2C%3B41105032%2C%2C%2C%2C%2C%2C%3B01105111%2C%2C%2C%2C%2C%2C%3B93952280%2C%2C%2C%2C%2C%2C%3B93030245%2C%2C%2C%2C%2C%2C%3B&; SessionGuid=c84db62e-22b2-43eb-9ea3-fcae7710478d; Esid=d4899e3e-c273-4a9c-a2d8-a0a67bfe2a64; com.eLong.CommonService.OrderFromCookieInfo=Orderfromtype=5&Parentid=1500&Status=1&Cookiesdays=30&Coefficient=0.0&Pkid=1003&Priority=9001&Isusefparam=0&Makecomefrom=1&Savecookies=0; fv=pcweb; ext_param=bns%3D4%26ct%3D3; s_cc=true; s_visit=1; __tctma=20377580.1612921545984895.1612921545736.1612942042962.1613021168874.3; __tctmc=20377580.26050747; __tctrack=0; __tctmu=20377580.0.0; __tctmz=20377580.1613021168874.3.1.utmccn=(organic)|utmcmd=organic|utmEsl=utf-8|utmcsr=baidu|utmctr=%e5%90%8c%e5%9f%8e%e8%89%ba%e9%be%99; longKey=1612921545984895; H5SessionId=3F4F4F55BB91AD9A6E6BA459D77ED4F0; H5Channel=mnoreferseo%2CSEO; _tcudid_v2=s6-KLlePnKSY5k_e6c8afJ2siIdL6JckHCbGJGn8gZA; SessionToken=84bf644c-c0e0-40ab-9bfb-2e3399638e1a622; Lgid=LRpRtrsC3gsExwGXhEk%2FlpaR3waA7McUH7SGryL5%2FSFy7cgKYHvIl7%2BU1ESQ4xjsnKNiBZUvDBjyD47c0BiVo%2BXmTwHlATGgovz4PU04xC8ATdAK4QXdw1ep8TF%2FiKzVyBWhvVjW%2FtZZDQjF7yOBLQ%3D%3D; tcUser=%7B%22AccessToken%22%3A%22C9B2CD22F9D2F4EB07D6A7EF98A6A971%22%2C%22MemberId%22%3A%221e70de0b8ccf9bf972cb961495a4a42a%22%7D; __tctmd=20377580.737325; __tctmb=20377580.1983279497417116.1613021168874.1613021220438.2; s_sq=%5B%5BB%5D%5D; User-Ref-SessionId=2efe-4f4e-b64e-4b7f-1fea-3649; businessLine=hotel; anti_token=27513B19-FAE2-42B3-A54E-02D845BBBD37; __tctmb=0.2350751285017907.1613021224930.1613021224930.1; __tccgd=0.0; __tctmc=0.6528555; __tctmd=0.252662736; ShHotel=InDate=2021-02-11&CityID=1105&CityNameEN=wuxi&CityNameCN=%E6%97%A0%E9%94%A1&OutDate=2021-02-12&CityName=%E6%97%A0%E9%94%A1; trace_extend={"deviceid":"8340df84-1a62-4c32-8655-0d9f55894610","appid":"6","userid":"240000001103487989","orderfromid":1003,"sessionid":"2efe-4f4e-b64e-4b7f-1fea-3649","pvid":"59adeb5b"}; JSESSIONID=FD9391A57926778C3467896D8DED5039; lasttime=1613021257330',
"Accept": "application/json, text/javascript, */*; q=0.01",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
# 构造详情响应头
self.detail_headers = {
# Cookie更换成自己的Cookie值
'Cookie': 'CookieGuid=8340df84-1a62-4c32-8655-0d9f55894610; H5CookieId=8da60226-1108-4c30-8023-c275b40d9b1b; firsttime=1612921642621; CitySearchHistory=0101%23%E5%8C%97%E4%BA%AC%23beijing%23%401105%23%E6%97%A0%E9%94%A1%23wuxi%23; _fid=8340df84-1a62-4c32-8655-0d9f55894610; SHBrowseHotel=cn=94074245%2C%2C%2C%2C%2C%2C%3B41105032%2C%2C%2C%2C%2C%2C%3B01105111%2C%2C%2C%2C%2C%2C%3B93952280%2C%2C%2C%2C%2C%2C%3B93030245%2C%2C%2C%2C%2C%2C%3B&; SessionGuid=c84db62e-22b2-43eb-9ea3-fcae7710478d; Esid=d4899e3e-c273-4a9c-a2d8-a0a67bfe2a64; com.eLong.CommonService.OrderFromCookieInfo=Orderfromtype=5&Parentid=1500&Status=1&Cookiesdays=30&Coefficient=0.0&Pkid=1003&Priority=9001&Isusefparam=0&Makecomefrom=1&Savecookies=0; fv=pcweb; ext_param=bns%3D4%26ct%3D3; s_cc=true; s_visit=1; __tctma=20377580.1612921545984895.1612921545736.1612942042962.1613021168874.3; __tctmc=20377580.26050747; __tctrack=0; __tctmu=20377580.0.0; __tctmz=20377580.1613021168874.3.1.utmccn=(organic)|utmcmd=organic|utmEsl=utf-8|utmcsr=baidu|utmctr=%e5%90%8c%e5%9f%8e%e8%89%ba%e9%be%99; longKey=1612921545984895; H5SessionId=3F4F4F55BB91AD9A6E6BA459D77ED4F0; H5Channel=mnoreferseo%2CSEO; _tcudid_v2=s6-KLlePnKSY5k_e6c8afJ2siIdL6JckHCbGJGn8gZA; SessionToken=84bf644c-c0e0-40ab-9bfb-2e3399638e1a622; Lgid=LRpRtrsC3gsExwGXhEk%2FlpaR3waA7McUH7SGryL5%2FSFy7cgKYHvIl7%2BU1ESQ4xjsnKNiBZUvDBjyD47c0BiVo%2BXmTwHlATGgovz4PU04xC8ATdAK4QXdw1ep8TF%2FiKzVyBWhvVjW%2FtZZDQjF7yOBLQ%3D%3D; tcUser=%7B%22AccessToken%22%3A%22C9B2CD22F9D2F4EB07D6A7EF98A6A971%22%2C%22MemberId%22%3A%221e70de0b8ccf9bf972cb961495a4a42a%22%7D; __tctmd=20377580.737325; __tctmb=20377580.1983279497417116.1613021168874.1613021220438.2; s_sq=%5B%5BB%5D%5D; User-Ref-SessionId=2efe-4f4e-b64e-4b7f-1fea-3649; businessLine=hotel; anti_token=27513B19-FAE2-42B3-A54E-02D845BBBD37; __tctmb=0.2350751285017907.1613021224930.1613021224930.1; __tccgd=0.0; __tctmc=0.6528555; __tctmd=0.252662736; ShHotel=InDate=2021-02-11&CityID=1105&CityNameEN=wuxi&CityNameCN=%E6%97%A0%E9%94%A1&OutDate=2021-02-12&CityName=%E6%97%A0%E9%94%A1; trace_extend={"deviceid":"8340df84-1a62-4c32-8655-0d9f55894610","appid":"6","userid":"240000001103487989","orderfromid":1003,"sessionid":"2efe-4f4e-b64e-4b7f-1fea-3649","pvid":"59adeb5b"}; JSESSIONID=FD9391A57926778C3467896D8DED5039; lasttime=1613021257330',
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Host": "hotel.elong.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"
}
# 初始化MongoDB数据库
self.client = MongoClient()
self.collection = self.client['test']['yilong_hotel']
# 获取总页码数
def getPageIndex(self,count):
# 已知每页共有20条酒店信息
page_num = count//20+1 if count%20>0 else count//20
return [i for i in range(1,page_num+1)]
# 发送url请求
def parse(self,page_index):
time.sleep(0.5)
self.list_dat['listRequest.pageIndex']=page_index
resp = requests.post(self.list_url_temp,data=self.list_dat,headers=self.list_headers)
return resp.content.decode()
# 解析并获取数据
def get_content_list(self,str_html):
json_html = json.loads(str_html)
# 通过正则表达式获取酒店的编号
hotel_content = json_html['value']['hotelListHtml']
hotel_code_list = re.findall(r'data-link=\"/(\d+)/\"',hotel_content)[::2]
hotel_price = re.findall(r'\"h_pri_num.*\">(\d+)<',hotel_content)
hotel_price_len = len(hotel_price)
print(hotel_price_len)
# 遍历编号
for i in range(len(hotel_code_list)):
item = {
}
item['hotel_code'] = hotel_code_list[i]
# 由于在用正则匹配的时候会出现 数量不对应的情况 一下是对酒店价格数据的不对应进行处理
# 当酒店价格数据的长度不足20的时候 就用20-酒店价格数据的长度
# 通过for循环在数组末尾追加0 直到酒店价格数据的长度达到20位置
# 如果都不满足 则直接填充0即可
if hotel_price_len==20:
item['hotel_price'] = hotel_price[i]
elif hotel_price_len<20 and hotel_price_len>0:
for j in range(20-hotel_price_len):
hotel_price.append('0')
item['hotel_price'] = hotel_price[i]
else:
item['hotel_price'] = '0'
# item = self.get_price(item['hotel_code'],item)
self.parse_detail(item['hotel_code'],item)
# 解析详情页数据
def parse_detail(self,hotel_code,item):
time.sleep(0.2)
resp = requests.get(self.detail_url_temp.format(hotel_code),headers = self.detail_headers)
str_html = html.etree.HTML(resp.content.decode())
# 获取酒店的名称、评分、评论数、好评数以及差评数
# 以下多采用三元运算 提高代码健壮性 就算没有获取到数据 也不会报错
hotel_name = str_html.xpath('//div[contains(@class,"hdetail_main")]//h1/text()')
item['hotel_name'] = hotel_name[0] if len(hotel_name)>0 else None
hotel_rate = str_html.xpath('//span[@class="comt_nmb"]/text()')
item['hotel_rate'] = hotel_rate[0] if len(hotel_rate) > 0 else None
hotel_area = str_html.xpath('//span[@data-downtownname]/@data-downtownname')
item['hotel_area'] = hotel_area[0] if len(hotel_area) > 0 else None
hotel_addr = str_html.xpath('//span[@data-downtownname]/text()')
item['hotel_addr'] = hotel_addr if len(hotel_addr) > 0 else None
# 由于同程艺龙的详情页展示会发生变化 因此需要对酒店的服务信息进行两种书写方式
hotel_service_list = str_html.xpath('//span[contains(@class,"icon_faci")]/@title')
item['hotel_service_list'] = hotel_service_list if len(hotel_service_list) > 0 else str_html.xpath('//div[@class="facilities"]/ul/li[not(@class="grey")]/span/text()')
hotel_comment_num = str_html.xpath('//ul[@class="nav_lst"]/li[1]/text()')
item['comment_num'] = hotel_comment_num[0].strip() if len(hotel_comment_num) > 0 else None
hotel_good_comment_num = str_html.xpath('//ul[@class="nav_lst"]/li[2]/text()')
item['good_comment_num'] = hotel_good_comment_num[0].strip() if len(hotel_good_comment_num) > 0 else None
hotel_bad_comment_num = str_html.xpath('//ul[@class="nav_lst"]/li[3]/text()')
item['bad_comment_num'] = hotel_bad_comment_num[0].strip() if len(hotel_bad_comment_num) > 0 else None
print(item)
self.save(item)
# 保存数据
def save(self,item):
self.collection.insert(item)
# 主函数
def run(self):
# 首先请求一次获取总的酒店数量
resp = requests.post(self.list_url_temp,data=self.list_dat,headers = self.list_headers)
json_html = json.loads(resp.content.decode())
# 获取总页数
hotel_count = json_html['value']['hotelCount']
# 调用getPageIndex获取总页码数
page_list = self.getPageIndex(hotel_count)
for i in page_list:
str_html = self.parse(i)
self.get_content_list(str_html)
if __name__ == '__main__':
yilong = YiLongSpider()
yilong.run()
- MongoDB数据转存excle文件代码:
import pandas as pd
from pymongo import MongoClient
import numpy as np
def export_excel(export):
# 将字典列表转换为DataFrame
df = pd.DataFrame(list(export))
# 指定字段顺序
order = ['hotel_code','hotel_price','hotel_area','hotel_name',
'hotel_rate','hotel_addr','hotel_service_list','comment_num','good_comment_num','bad_comment_num']
df = df[order]
# 由于hotel_service_list字段数据为列表数据 通过'-'来连接成字符串数据方便后期数据分析处理
df['hotel_service_list'] = df['hotel_service_list'].apply(lambda x:'-'.join(x) if x is not None else x)
# 将列名替换为中文
columns_map = {
'hotel_code':'酒店编号',
'hotel_price':'酒店价格',
'hotel_area':'酒店区域',
'hotel_name':'酒店名称',
'hotel_rate':'酒店评分',
'hotel_addr':'酒店地址',
'hotel_service_list':'酒店服务',
'comment_num':'酒店评论数量',
'good_comment_num':'酒店好评数',
'bad_comment_num':'酒店差评数',
}
df.rename(columns=columns_map, inplace=True)
# 指定生成的Excel表格名称
file_path = pd.ExcelWriter('yilong_hotel.xlsx')
# 替换空单元格
df.fillna(np.nan, inplace=True)
# 输出
df.to_excel(file_path, encoding='utf-8', index=False)
# 保存表格
file_path.save()
if __name__ == '__main__':
client = MongoClient()
connection = client['test']['yilong_hotel']
ret = connection.find({
}, {
'_id': 0})
data_list = list(ret)
export_excel(data_list)
提醒:
- 爬虫部分的cookies信息一定要替换成自己的cookie信息
- 爬取的数据部分是不完整的,需要做进一步处理
- 如果想爬取其他城市酒店数据 最好先按照博主的爬取思路 抓取到列表页渲染的包 将请求参数复制下来 然后修改指定参数即可 本博主已经将需要修改的部分进行注释代码标注
- 爬取的速度可能比较慢 因为博主没有使用IP代理 因此需要通过睡眠来控制爬取数据的速度 防止IP被封
以上就是本博主在爬取同城艺龙的全过程啦!
如有疑问,下方评论。